
TL;DR
- AI models are not agents. AI agents are composed of models and a variety of other components, such as tools, memory, and knowledge bases.
- AI agent architecture consists of an AI model and an agent harness. The model is the intelligent part of the agent. The harness consists of everything else.
- Anthropic has released a paper outlining potential AI agent architectures. While these proposed designs seem novel at first glance, they're actually grounded in programming principles that have existed for decades.
- AI agent knowledge needs to be grounded in reality and real-time data. Without real-time data, AI agent knowledge is limited to memory stores and training data.
- Most AI agent architectures need some type of stable web access tool. Built-in fetch tools offered by companies like OpenAI and Anthropic offer only limited web access.
- Firecrawl provides AI agents with comprehensive web access tools so they can search, scrape, and interact with the web reliably.
Developers everywhere are rethinking their designs with AI agent architecture at the center. In fact, OpenAI just designed and built the Jalapeño Chip specifically to power their AI models.
Architecture isn't limited to hardware either. The line between AI model and AI agent often gets blurred. An AI model is a central component of an AI agent. The model is not the agent itself. With truly agentic systems, you can swap models without impacting the agent workflow. Outputs might change, but the workflow itself remains intact.
To turn an AI model into an AI agent, you need architecture.
What is AI agent architecture?
AI agent architecture is the structure of an agentic AI system. It borrows heavily from traditional software architecture. We try to abstract them away, but AI agents are still just software. Architecturally, a parsing agent isn't all that different from a hardcoded, deterministic parser.
AI agent architecture consists of two main parts: The model and the harness.
- Model: If you've used a chatbot or built an AI agent, you've already used a model and probably know what it is. The model takes input and then generates predictive output based on the context of the input it received.
- Harness: The harness contains the model alongside its tools, memory, and everything else.
What is an agent harness?
According to LangChain,
If you're not the model, you're the harness.
The agent harness is made up of everything built around the model, from tools and storage down to the execution environment holding the model.
Agent harness = hardcoded, deterministic, if/else-type software built around the model.
Without a harness, you have a model that can reason and read input, but it can't act. It has no tools to call. It has no RAG system, no persistent memory. It doesn't even have an environment to operate inside of. Without an agent harness, you've got a generic LLM.
When developers speak of building agents, we're usually talking about building the harness. Most of us aren't building LLMs from scratch.
What are the core components of an AI agent?
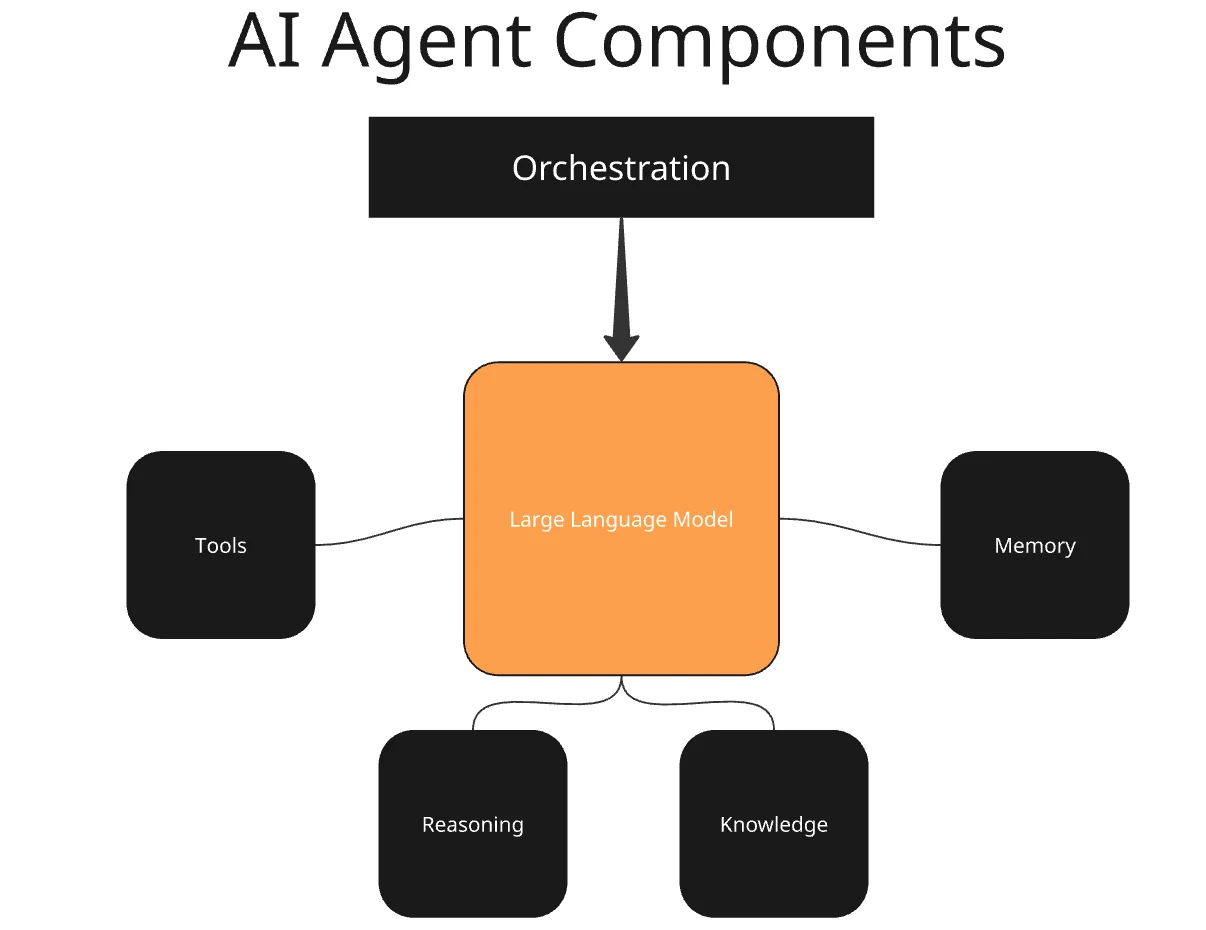
- Orchestration: Something needs to tell the agent what to do and to keep it on task. The orchestration layer provides essential guardrails keeping agents on task and properly performing their tasks. Orchestration can be hardcoded using tools like LangGraph. It can also be handled using GUI tools such as Cursor Automations.
- LLM: Large Language Models (LLMs) are central to agentic AI. The model takes input, calls tools, performs RAG operations, and then generates output.
- Reasoning: In older systems, reasoning needed to be added in by the developer. In frontier models like GPT-5.5, Claude Sonnet 4.6, Gemini 3.5 Flash, and Grok 4, reasoning comes with the model. Give a model a prompt. It evaluates the prompt and uses reasoning to plan out its next actions before generating output.
- Tools: AI agents call tools to complete specific operations. If you tell your agent to solve a math problem, it should call a calculator tool that outputs the actual result. AI models are predictive. Tools are deterministic for consistent accuracy. AI agents use MCP, CLI tools, and other specialized frameworks like LangChain to access tools.
- Memory: Memory is essential to any long-running AI system. All AI models operate on a finite context window. A model with a context window of 200,000 tokens will reset when it hits 200,000 tokens. After the reset, the context needs to be rebuilt using memory.
- Knowledge: This often gets lumped in with memory for simple AI agents. However, "knowledge" is a very large scope. My personal assistant knows that my name is Jacob. This is stored knowledge. When I want the weather, it runs an external search, and then:
The current weather in Detroit, Michigan is 73 degrees Fahrenheit.
What are the architecture patterns for AI agents?

As of 2026, there's still no current industry standard when it comes to agentic design patterns. Anthropic has released a paper outlining potential design patterns. It covers four basic system types.
- Single Agents: A single AI agent hooked into tools. It takes a system prompt and accomplishes its task. Single agents are best for customer service, documentation, and other tightly-scoped short-running workflows.
- Sequential Workflows: This is often thought of as an extension of the single agent system. However, it can incorporate additional agents. We can think of sequential agents as a successor to synchronous linear programming. If our system needs to read a form submission, transform the data, and then analyze it, we've got a sequential workflow.
- Parallel Workflows: A group of AI agents performs tasks asynchronously and simultaneously. The concept is similar to multithreading in traditional computing. Your system receives multiple requests at the same time. A set of parallel agents processes them all at the same time. Imagine you're crawling 10,000 webpages daily. You don't need to crawl them one at a time. Five years ago, you'd write and deploy a concurrent scraper. Today, you'd deploy concurrent agents.
- Evaluator-optimizer: Two agentic systems run in iterative cycles. On the first cycle, Group A performs the work, and Group B evaluates. For jobs that require intense reasoning, like AI-powered coding systems, the underlying architecture begins with Group A writing code. Group B evaluates and improves the code. Then, like old-fashioned pair programming, the process repeats.
The patterns listed above help greatly when thinking about systems as a whole. To get a more granular picture of design patterns, we can go back to the creational patterns outlined by the Gang of Four. When we think of an individual agent as an object, the pieces to build the systems above snap together with much more clarity.
- Singleton: A class with only a single point of access. A single agent system is the singleton design, whether the agent gets manually prompted by a user or if it gets initiated by a trigger.
- Factory: When it comes to AI, this might seem like science fiction. It's not. Almost every major AI platform lets you chat with a builder agent to deploy your own custom AI agent. The agent builder is using a factory pattern to help you deploy the agent.
- Abstract Factory: This is a looser version of the factory pattern without a concrete class. Imagine your system has three separate agents: one to scrape products, one to scrape reviews, and one to scrape product news. The abstract factory creates the templates that become these agents.
- Builder: A builder agent might construct other agents. It could also build websites, databases, and other things you need in your software. A builder agent can assemble factory agents. If you want a scraping agent, the builder creates it. If you want a monitoring agent, the builder creates it.
- Prototype: Build new objects by cloning an existing instance. With a scraping agent, simply create another one based on the existing one. No need to rewrite the system prompt, change tooling permissions, or build a new memory system.
Each of these basic types can still be used to power the AI agent architecture of today.
Anthropic recently posted on X that Claude is accelerating their development process. They specifically cite recursive self-improvement and AI models autonomously building other AI systems. The principles behind Factory and Abstract Factory are already heavily powering the industry today.
The web context layer of AI agent architecture
What's the problem with stock AI models?
For AI agents to be effective, they need clean, reliable web access. When an agent's knowledge is limited to its training data or stored memories, it has almost zero grounding in current reality. We've all prompted a model and gotten a response similar to the one below.
My knowledge doesn't go past 2025. For additional information, you can visit:
- some random website
- another random website
...My AI assistant already has web access. How do these tools change anything?
The built-in web access behind models like Claude and ChatGPT is not always reliable. I've had many cases where neither of the aforementioned models was even able to fetch a simple GitHub repository. This is where tools like Firecrawl make a concrete difference.
Why should I add web access to my AI agent architecture?
The web is the closest thing we have to a real-time record of human knowledge. Firecrawl CEO Caleb Peffer frames the underlying problem well:
This knowledge is trapped, scattered across millions of domains, locked behind JavaScript, and constantly changing. AI needs this data to be useful, to answer questions accurately, to take actions confidently, and to understand the world as it exists right now.
For effective grounding and RAG, AI agents need reliable web access. Built-in fetch features provide only a limited portion of that. When developers take web access seriously, they tend to prioritize three major features.
- Web search: AI models can't just randomly follow links like we did in 1995. When search engines solved this problem, it saved the world. In an AI agent architecture, it saves token context and computing resources. Search helps AI agents discover information and identify web pages.
- Site fetching: Your browser doesn't do much good if you can't view the sites that show up on a Google search. AI models need this same ability. Search results can't be verified without site fetching.
- Browser rendering: This is where AI agents differ architecturally from humans. Humans need a browser just to do searches and fetch sites. AI agents, like other software, only need a browser to perform page interactions and to load dynamic content.
There's a hard cost argument underneath all three. Purpose-built web access tooling strips noise out before it ever reaches the context window, and at agent volume the savings compound fast.
- Most of a webpage is noise: A full webpage is usually about 80 percent boilerplate, including navigation, footers, sidebars, ads, and cookie banners. Feeding all of that into a model wastes tokens.
- Clean extraction cuts the bill: Firecrawl returns 94 percent fewer input tokens than fetching raw HTML, roughly 2,788 tokens of clean Markdown on a typical page instead of 38,381 tokens of raw HTML.
- It adds up at scale: This is why search has already become 10 to 30 percent of monthly variable COGS at AI-agent startups.
Mastra CEO Sam Bhagwat captures the principle in his book Principles of Building AI Agents:
Agents are only as powerful as the tools you give them.
And the stakes are high when the web access tool is weak. Prateek Joshi, a VC at Moxxie Ventures, puts it plainly:
If the search step fails, agent answers degrade or hallucinate.
Firecrawl packages those three capabilities into three endpoints:
/search: Perform live web searches using AI-friendly data. Instead of chewing through tokens on raw HTML, your AI agent can run a search and read the results in a clean format that saves on token usage and reasoning steps./scrape: Fetch any site and output it as structured data, clean Markdown, or standard HTML. AI agents can read the web without burning up their context window./interact: Open a real browser and interact with the page by clicking buttons, filling forms, and performing complex site navigations. This is essential for accessing data from dynamic web pages.
There are some other common problems with web extraction as well. These existed before AI agents, and they'll continue to exist. The difference now is that AI agents are required to manage them.
- Parsing: Before 2024, most developers wrote parsers manually. Once AI models became more reliable, the industry largely switched over to intelligent parsing. This cut development time drastically, but also involves feeding large, complex pages into an AI model.
- Data discovery: Crawlers used to run using deterministic programming. If a link is found on a site, store the link. Classify the site into a rigid category that may or may not actually fit the site's content. Humans needed to manually review enormous website caches to identify patterns and trends.
- Limited technical resources: Teams who weren't familiar with tools like Python Requests and BeautifulSoup simply couldn't harvest web data.
For me particularly, building parsers was the most important part of my job. As the industry has continued to shift, deterministic scrapers (including the parsers I used to write) as a whole are going extinct fast. Firecrawl also offers endpoints for parsing, mapping, crawling, and agent-based web extraction.
MCP and CLI tools make it easy to add these features to your AI agent architecture.
An AI model isn't an agent without architecture
Without a harness, without AI agent architecture, you're stuck with an AI model that isn't good for anything beyond a text chat. Arguably, even a chat UI itself contains pieces of AI agent architecture. To build proper AI agents, your architecture needs to reflect this. AI agent architectures need models, reasoning, memories, tools, orchestration, and a knowledge base to keep the model grounded. When it comes to the knowledge base, most AI agents need reliable web access to perform even the most mundane tasks.
Frequently Asked Questions
What is AI agent architecture?
AI agent architecture is the system built around an LLM that powers your AI agent. AI agent architectures consist of a model plugged into a memory store, tools, a knowledge base, and an orchestration layer.
Is agent architecture more important than prompt engineering?
Prompt engineering is mostly a short-term fix. A better prompt can improve a single response, but it can't give an agent tools, memory, state management, or orchestration. Those come from architecture. A well-architected agent with a plain prompt will usually outperform a poorly architected one with a heavily tuned prompt, because the harness is what lets the agent actually act.
Why do AI agents work in demos but break in production?
The most common cause is scope creep. A broad, do-everything agent is easy to demo and hard to ship. Production agents tend to hold up because they have a narrow scope, deep domain context, and disciplined context management that keeps the agent on task. Tightening the harness around a specific job is usually more reliable than widening the model's responsibilities.
When should I use multiple agents in a workflow?
Multi-agent workflows are ideal in several scenarios. Parallel agent architectures are highly beneficial for workflows requiring concurrency. The evaluator-optimizer architecture is best for operations requiring iterative reasoning and optimization like coding agents.
How do you manage memory in a long-running AI agent?
Long-running agents eventually fill their context window and lose track of earlier steps. Common techniques include summarizing previous activity into a short brief, using a sliding window that keeps only recent turns, and semantic retrieval that pulls relevant past context on demand. Hierarchical state, where memory is partitioned by task complexity, also helps keep the active context small and focused.
Why is web access important for AI agent architecture?
Web access gives AI models access to fresh data. This helps models address the knowledge cutoff and make decisions that are grounded in reality.
What is Firecrawl?
Firecrawl provides web access APIs such as search, scrape, and interact. Using Firecrawl, AI agents gain stable web access for tasks requiring research and fresh data.
How do tools like Firecrawl differ from built-in fetch tools?
Model providers offer built-in fetch tools. However, these tools are meant for minor knowledge-fetching tasks. Built-in tools run into limitations quickly when doing real research. External web access tools also bring modularity into the system. Users can swap ChatGPT for Claude, Grok, or Gemini without a change in tool performance.
