
In this comprehensive tutorial, you'll learn how to build a powerful startup idea validator using LangGraph's agent framework. We'll create an interactive system that analyzes market potential, community sentiment, and technical feasibility, all with a user-friendly Streamlit interface.
What Is LangGraph?
Over the past two years, so many agent building frameworks have come out and I tested almost all of them. Among them, LangGraph is easily in my top three choices due to its simple syntax to build complex agents:
from langgraph.prebuilt import create_react_agent
from langgraph.checkpoint.memory import InMemorySaver
def my_tool1(input: str) -> str:
"""A python function as a tool #1"""
def my_tool2(input: str) -> str:
"""A python function as a tool #2"""
agent = create_react_agent(
model="openai:o3",
tools=[my_tool1, my_tool2],
checkpoint_saver=InMemorySaver(),
prompt="This is your system prompt."
)
response = agent.invoke({
"messages": [
{
"role": "user",
"content": "What is LangGraph?"
}
]
})In just a few lines of code, you can build a ReAct (reasoning + acting) agent with access to tools and conversation memory.
Multi-agent systems with complex coordination patterns and built-in state management is also straightforward:
from langgraph_supervisor import create_supervisor
# Define your agents with tools
agent1 = create_react_agent(...)
agent2 = create_react_agent(...)
agent3 = create_react_agent(...)
supervisor = create_supervisor(
model="openai:o3-pro",
agents=[agent1, agent2, agent3],
prompt="A system prompt that defines how agents should work together.",
checkpoint_saver=InMemorySaver(),
)
response = supervisor.invoke({"messages": [{"role": "user", "content": "What is LangGraph?"}]})Define your agents and pass them to a supervisor agent with a detailed prompt and you get a sophisticated multi-agent system.
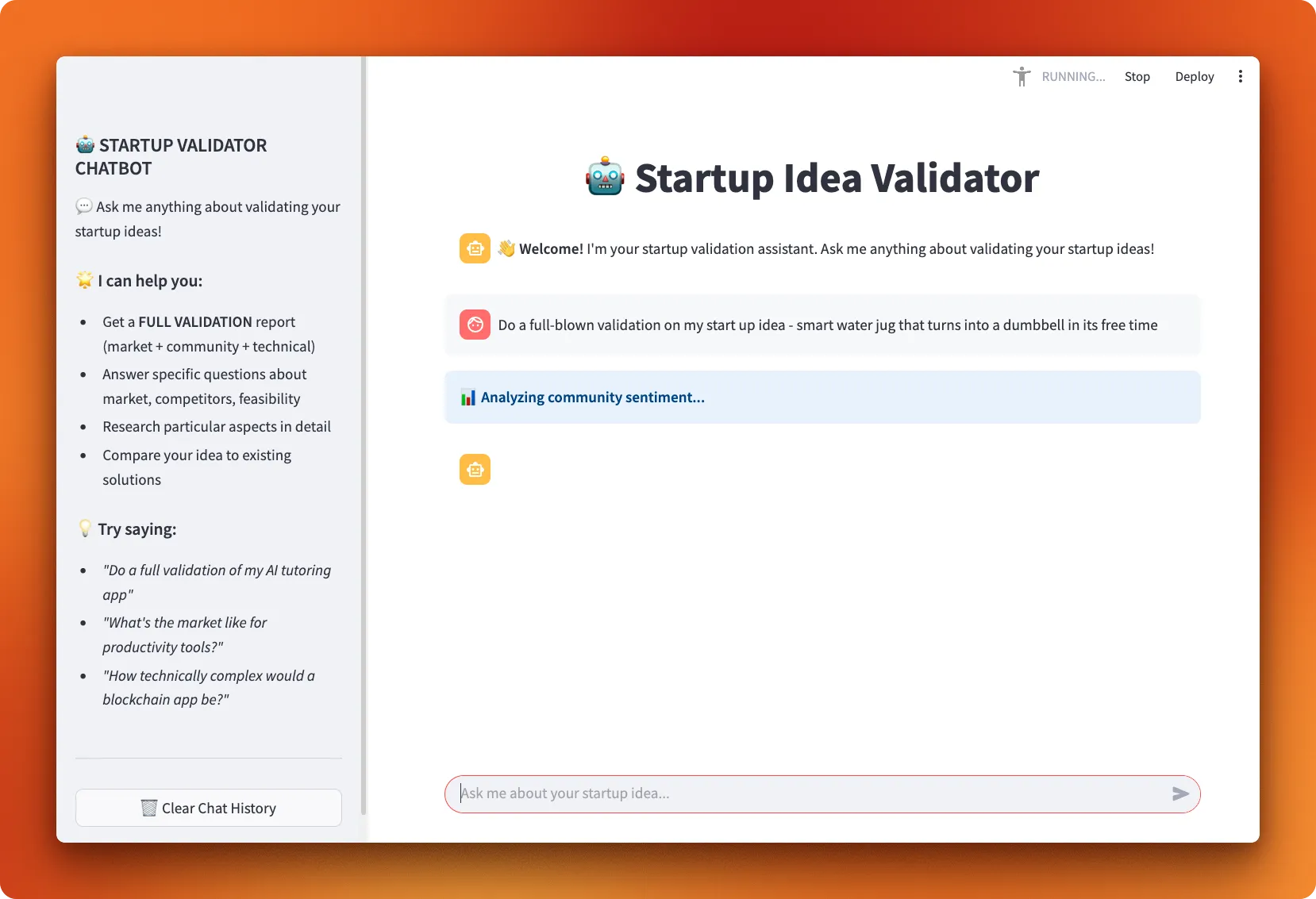
In this tutorial, we'll build a startup idea validator that combines web search with Firecrawl, market research, and LangGraph's ReAct agent pattern to evaluate business concepts. The final application will have a clean Streamlit interface for users to hash out their start up ideas with the help of our agent. Let's get started!
LangChain vs. LangGraph
Before we start building the project, let's clarify when to choose LangChain versus LangGraph for your AI applications.
LangChain excels at building straightforward LLM applications with its rich ecosystem of integrations and pre-built components. You can quickly connect chat models, vector stores, and retrieval systems using its standard interfaces. LangChain works well for RAG applications, simple chatbots, and workflows where you need to chain together different LLM operations in a linear fashion.
LangGraph takes a different approach by focusing on stateful, multi-actor agent systems. Where LangChain provides building blocks, LangGraph gives you the orchestration layer to create complex agent workflows with branching logic, human-in-the-loop approvals, and persistent conversation state.
The key differences come down to:
- LangChain: Linear workflows, predictable chains, rich integrations for standard LLM tasks
- LangGraph: Adaptive agents, dynamic decision-making, stateful conversations with real-time streaming
- Control: LangChain follows set paths, LangGraph agents choose their next actions based on context
For our startup validator project, LangGraph's ReAct (reasoning + acting) pattern makes perfect sense. The agent needs to dynamically choose between web search, market analysis, and competitor research based on the startup idea being evaluated. This kind of adaptive behavior would require complex routing logic in LangChain, but comes naturally with LangGraph's agent architecture.
Building a LangGraph ReAct Agent to Validate Startups
In this section, you'll build a complete startup validation system using LangGraph's ReAct agent pattern. You'll create an agent that combines web scraping, community sentiment analysis, and technical research to provide comprehensive business idea assessment. Your agent will use three specialized tools to gather market intelligence, analyze the data through conversation, and deliver actionable recommendations through a clean Streamlit interface.
You can find the complete project on GitHub, and I recommend opening it alongside this guide since we'll focus on the most important code patterns and architectural decisions rather than going through every line. Each step builds on the previous one, so by the end you'll have a production-ready agent that shows off real-world LangGraph capabilities.
Step 1: Setting up the environment
You'll want to start with a solid environment setup for your LangGraph application. I recommend using uv, Python's fastest package installer, because it resolves dependencies quickly and creates reproducible environments that work reliably across different machines.
Start your project with uv init, which creates the basic structure. After initialization, you'll need to create the project directories and files manually:
uv init startup-idea-validator
cd startup-idea-validator
mkdir src
touch src/{__init__.py,tools.py,validator.py,app.py}
touch .env.exampleThese commands set up your project foundation with proper Python package structure. The src directory will hold your core application logic, while the root directory contains configuration files.
Next, install the required libraries using uv add without version constraints to get the latest compatible versions:
uv add firecrawl-py langchain langchain-openai langgraph
uv add langgraph-supervisor streamlit python-dotenvEach library serves a specific purpose in your agent architecture. The firecrawl-py package handles web scraping and search functionality, giving your agent access to real-time market data. The langchain and langchain-openai libraries provide the foundation for LLM interactions and message handling. LangGraph acts as the core framework that orchestrates your ReAct agent and manages conversation state. Streamlit creates the interactive web interface where users chat with your agent, while python-dotenv manages environment variables securely, keeping API keys separate from code.
Your codebase follows a clean separation of concerns with this structure:
startup-idea-validator/
├── main.py # Application entry point
├── src/
│ ├── tools.py # External API integrations
│ ├── validator.py # Agent definition and configuration
│ └── app.py # Streamlit user interface
├── .env # API keys and secrets
└── pyproject.toml # Dependencies and project metadataThis structure isolates different responsibilities because mixing agent logic with UI code creates maintenance headaches as your project grows. Each file has a single, clear purpose that makes the codebase easier to understand and modify.
The .env file stores three API keys that power your agent's capabilities:
OPENAI_API_KEY=your-openai-key-here
FIRECRAWL_API_KEY=your-firecrawl-key-here
GITHUB_TOKEN=your-github-token-here- The OpenAI API key powers the reasoning capabilities of your agent (get yours here)
- The Firecrawl API key provides web scraping for market research (sign up here)
- The GitHub token accesses repository data for technical feasibility assessment (create here)
When you separate credentials from code, you prevent accidental exposure and make deployment across different environments smooth.
Step 2: Creating tools
Tools are the hands and eyes of your agent - they determine what your agent can actually do in the real world. You'll find that tool development often eats up a huge chunk of your project time because each tool needs solid error handling, proper data formatting, and reliable API integration.
Your tools.py file contains three specialized functions that give the agent different research capabilities. The file starts with the necessary imports:
from dotenv import load_dotenv
import os
import requests
from firecrawl import FirecrawlApp, ScrapeOptions
from langgraph.config import get_stream_writer
load_dotenv()These imports give you environment variable access, HTTP requests, Firecrawl integration, and LangGraph's streaming capabilities. The load_dotenv() call loads your API keys from the .env file into the environment.
Your first tool, research_market_landscape, uses Firecrawl's search endpoint to gather competitive intelligence:
def research_market_landscape(startup_idea: str) -> str:
api_key = os.getenv("FIRECRAWL_API_KEY")
if not api_key:
return "❌ Error: FIRECRAWL_API_KEY environment variable is required"
app = FirecrawlApp(api_key=api_key)
writer = get_stream_writer()
writer(f"TOOL USE: Researching market data for {startup_idea}...")Firecrawl's search endpoint works perfectly for this task because it crawls multiple sources at once and returns structured data, so you don't need to scrape individual websites manually. The search query combines the startup idea with market research keywords:
search_result = app.search(
f"{startup_idea} market size competitors industry analysis",
limit=5,
scrape_options=ScrapeOptions(formats=["markdown"])
)This approach gives your agent comprehensive market context from multiple sources in a single API call.
Your second tool, analyze_community_sentiment, taps into Hacker News discussions to gauge developer and tech community opinions:
def analyze_community_sentiment(startup_idea: str) -> str:
writer = get_stream_writer()
writer(f"TOOL USE: Analyzing community sentiment using Hacker News...")
search_url = "https://hn.algolia.com/api/v1/search"
params = {"query": startup_idea, "tags": "story", "hitsPerPage": 10}
response = requests.get(search_url, params=params)Hacker News gives you valuable insights because it's where technical professionals discuss new technologies, startups, and market trends. The Algolia API gives you free access to search HN's entire archive without authentication.
Your third tool, assess_technical_feasibility, searches GitHub to understand the technical landscape:
def assess_technical_feasibility(startup_idea: str) -> str:
github_token = os.getenv("GITHUB_TOKEN")
search_url = "https://api.github.com/search/repositories"
headers = {"Authorization": f"token {github_token}"}
params = {
"q": startup_idea.replace(" ", "+"),
"sort": "stars", "order": "desc", "per_page": 10
}GitHub search reveals existing implementations, popular libraries, and technical complexity indicators. When you sort by stars, you can identify the most mature and widely-adopted solutions.
Throughout tool execution, you'll use get_stream_writer() to provide real-time feedback to the user interface:
writer = get_stream_writer()
writer(f"TOOL USE: Researching web for market data...")
# ... API call happens ...
writer(f"TOOL OUTPUT: Submitting market data back to agent...")This creates transparency in your user interface, showing exactly what the agent is doing at each moment. Users see "Researching market data..." instead of a simple "Thinking..." message.
The GitHub API requires authentication but gives you rich repository metadata including stars, forks, languages, and update frequency. This data helps your agent assess technical complexity and market saturation. The Hacker News API through Algolia is free and provides discussion metadata like points, comments, and URLs, giving your agent insight into community sentiment and trending topics.
When you're building agent tools, several practices will help you create reliable and usable functions:
-
Single responsibility: Make each tool do one thing well. Your market research tool should only handle market data, not technical analysis.
-
Solid error handling: Always wrap API calls in try-except blocks and return meaningful error messages that help users understand what went wrong.
-
Clear documentation: Tool docstrings directly influence how your agent chooses which tool to use. Be specific about what each tool does and when to use it.
-
Structured output: Return well-formatted data that your agent can easily parse and present to users. Use headers, bullet points, and clear sections.
-
Stream progress updates: Use
get_stream_writer()to keep users informed about long-running operations, so they don't think the system has frozen.
Step 3: Creating an agent with create_react_agent
The validator.py file contains the brain of your application - the agent configuration that determines how your startup validator thinks and behaves. This is where you transform individual tools into a cohesive reasoning system.
You'll create the core agent in a single function that brings together all your components:
from langgraph.prebuilt import create_react_agent
from langgraph.checkpoint.memory import InMemorySaver
from langchain.chat_models import init_chat_model
from .tools import (
research_market_landscape,
analyze_community_sentiment,
assess_technical_feasibility,
)These imports establish your agent's capabilities: the ReAct pattern implementation, memory management, model initialization, and your custom tools. Your model choice directly impacts agent performance:
MODEL_NAME = "openai:o4-mini"
def create_startup_validator_agent():
checkpointer = InMemorySaver()
return create_react_agent(
model=MODEL_NAME,
tools=[research_market_landscape, analyze_community_sentiment,
assess_technical_feasibility],
prompt=CONVERSATIONAL_VALIDATOR_PROMPT,
checkpointer=checkpointer,
)I recommend using o4-mini because it gives you strong reasoning capabilities at lower cost compared to larger models. The InMemorySaver checkpointer provides conversation memory, so your agent can reference previous research across multiple user questions.
Your system prompt acts as the agent's instruction manual and has the most impact on behavior:
CONVERSATIONAL_VALIDATOR_PROMPT = (
"You are a startup validation expert chatbot. Help users validate "
"their business ideas through conversation.\n\n"
"CONVERSATION STYLE:\n"
"- Be conversational and helpful, like a knowledgeable consultant\n"
"- Ask clarifying questions when ideas are vague\n"
"- Reference previous research naturally in ongoing conversations\n"
)This opening section establishes your agent's persona and conversational approach. Your agent knows to act like a consultant, not just an information retrieval system. The prompt then guides tool selection:
"TOOL USAGE:\n"
"Use tools thoughtfully based on user questions:\n"
"- research_market_landscape(): Market size, competitors, industry analysis\n"
"- analyze_community_sentiment(): Developer/user sentiment and discussions\n"
"- assess_technical_feasibility(): Implementation complexity, existing solutions\n"Clear tool descriptions help your agent choose the right tool for each user question. Without this guidance, your agent might use tools randomly or inappropriately. For comprehensive analysis, the prompt defines a systematic approach:
"FULL VALIDATION:\n"
"When users ask for 'full validation' or comprehensive analysis:\n"
"1. Use ALL THREE tools methodically\n"
"2. Provide structured report with market, community, and technical insights\n"
"3. End with clear VALIDATE/NEEDS_WORK/REJECT recommendation\n"This ensures consistent, thorough analysis when users request complete startup validation.
These two configurations have the most impact because your model's ability to understand context, choose appropriate tools, and synthesize information determines output quality. A weaker model might miss nuances or make poor tool choices. The prompt is the only way you can communicate expectations to the model - vague prompts lead to inconsistent behavior, while detailed prompts create reliable, predictable responses.
When you're crafting production-ready system prompts, several practices will improve your agent's reliability:
-
Define clear persona: Tell your agent exactly what role to play. "You are a startup validation expert" works better than "You help with startups."
-
Specify tool usage rules: State when and why to use each tool. Include examples of good and bad tool choices.
-
Structure output format: Give your agent templates for responses. "End with VALIDATE/NEEDS_WORK/REJECT" gives users consistent, actionable conclusions.
-
Handle edge cases: Include instructions for unclear requests, missing data, or tool failures. "Ask clarifying questions when ideas are vague" prevents confusion.
-
Maintain conversation context: Tell your agent to reference previous research and build on earlier conversations, creating a natural consulting experience.
Step 4: Creating a user interface for LangGraph agents
Your app.py file transforms your LangGraph agent into an interactive web application using Streamlit. This interface handles real-time streaming, dynamic updates, and conversation state while keeping the user experience smooth.
Your main application flow orchestrates several components that work together to create a smooth chat experience:
import streamlit as st
from langchain_core.messages import ToolMessage, AIMessageChunk, HumanMessage
from .validator import create_startup_validator_agent
def run_streamlit_app():
setup_streamlit_page()
show_welcome_sidebar()
agent = get_startup_validator_agent()This structure separates page configuration, user guidance, and agent initialization, making your code maintainable as features grow. Your application uses Streamlit's session state to maintain conversation history across user interactions, storing two separate lists: messages for UI display and chat_history for LangGraph message objects.
if "messages" not in st.session_state:
st.session_state.messages = []
st.session_state.chat_history = []
welcome_msg = "👋 **Welcome!** I'm your startup validation assistant."
st.session_state.messages.append({"role": "assistant", "content": welcome_msg})This separation prevents UI formatting from interfering with agent processing while preserving conversation context across Streamlit reruns.
Your chat interface uses Streamlit's built-in components to create a familiar messaging experience. The st.chat_message context manager automatically styles messages with appropriate avatars and alignment:
# Display conversation history
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# Handle new user input
user_input = st.chat_input("Ask me about your startup idea...")When a user submits a message, your application processes it through a sophisticated streaming system that gives real-time feedback. The streaming mechanism uses LangGraph's dual-mode streaming capability, which is the key to creating a responsive user experience.
Your stream_agent_response function configures streaming with two modes: "messages" and "custom". The "messages" mode gives you token-by-token updates of the agent's response, while "custom" mode captures the messages from get_stream_writer() calls in your tool definitions:
def stream_agent_response(agent, chat_history, response_placeholder, thinking_placeholder):
config = {"configurable": {"thread_id": "startup_session"}}
for stream_mode, chunk in agent.stream(
{"messages": [HumanMessage(content=user_input)]},
config=config,
stream_mode=["messages", "custom"],
):The "custom" stream mode captures tool status updates and displays them as dynamic status messages. When your agent calls a tool, the get_stream_writer() messages flow through this stream mode, so your interface can show exactly what's happening:
if stream_mode == "custom":
if chunk:
chunk_str = str(chunk).lower()
if "market" in chunk_str or "research" in chunk_str:
thinking_placeholder.info("🔍 **Researching market data...**")
elif "community" in chunk_str or "hacker news" in chunk_str:
thinking_placeholder.info("📊 **Analyzing community sentiment...**")Meanwhile, the "messages" stream mode handles the actual agent response content. When your agent generates text, it arrives as AIMessageChunk objects that get accumulated and displayed in real-time:
elif stream_mode == "messages":
if isinstance(chunk[0], AIMessageChunk):
if chunk[0].content:
full_response += chunk[0].content
response_placeholder.markdown(full_response + "▌")Your interface uses Streamlit placeholders to manage dynamic updates without page refreshes. The thinking_placeholder shows tool status updates, while the response_placeholder displays the streaming agent response. The cursor symbol "▌" indicates active typing and disappears when the response is complete.
Error handling ensures a smooth user experience even when tools fail or your agent encounters problems:
try:
# Stream agent response
for stream_mode, chunk in agent.stream(...):
# Process chunks
except Exception as e:
error_msg = f"❌ **Error:** {str(e)}\nPlease try asking your question again."
thinking_placeholder.empty()
response_placeholder.markdown(error_msg)Clear error messages help users understand what went wrong and how to proceed, rather than showing cryptic technical errors.
When building user interfaces for agentic applications, several practices improve the user experience:
-
Show agent progress: Display what your agent is doing in real-time. Users need to know the system is working, during long tool executions.
-
Stream responses immediately: Don't wait for complete responses before showing content. Streaming creates the perception of faster performance.
-
Separate display and logic: Keep UI state separate from agent message objects. This prevents formatting issues from breaking your agent functionality.
-
Handle errors gracefully: Show user-friendly error messages and provide clear next steps when things go wrong.
-
Maintain conversation context: Preserve chat history and allow users to build on previous research, creating a natural consulting experience.
Conclusion And Next Steps
You've built a complete startup validation system that demonstrates LangGraph's power for creating intelligent, stateful agents. Your ReAct agent combines web scraping through Firecrawl, community sentiment analysis, and technical feasibility assessment into a single conversational interface that provides comprehensive business insights. The combination of LangGraph's agent orchestration, custom tools, and Streamlit's interface creates a production-ready application that users can actually rely on for real startup decisions.
This project shows how modern agent frameworks make complex AI applications accessible without requiring deep machine learning expertise. You can extend this foundation by adding more specialized tools, integrating different data sources, or creating multi-agent systems where different agents handle specific aspects of business validation. The patterns you've learned here - tool creation, agent configuration, and streaming interfaces - apply to countless other agent applications across different domains.
Ready to build your own AI agents with web access? Sign up for Firecrawl to give your applications the same market research capabilities you built today. Or explore our focused guide on building a web scraping agent with LangGraph and Firecrawl for a deeper walkthrough on the data extraction and scraping architecture side. You can also explore OpenClaw, a self-hosted personal agent that uses Firecrawl for live web access without building from scratch. You can explore the complete code and experiment with different configurations at the startup validator GitHub repository. Also, check out these documentation links to deepen your understanding of LangGraph:
