Context Layer for AI Agents: Can You Automate Context Feeding into Your Agents?
In 1970, Terry Winograd built a program called SHRDLU at MIT. It was amazing. You could ask the program to "Find a block which is taller than the one you are holding and put it into the box," and it would do it.
It understood relative clauses, pronouns, and physics, and everyone thought we had solved AI.
Then people tried to make it talk about anything other than red blocks and blue pyramids, and the program broke. SHRDLU didn't know of anything other than BLOCK X. It was a god in its micro-world and an idiot everywhere else.
SHRDLU handled relative clauses and context (“it,” “the one which…”), creating an illusion of understanding because its world was small and formally defined.
Fifty-six years later, we are still building SHRDLU.
Today’s production AI agents can look brilliant in controlled setups, where the context is clean and the tools behave. But when you drop them into a messy real-world codebase or a live support queue, performance often degrades. Not because they’re “dumb,” but because production adds distribution shift, missing context, flaky tools, and constraints that the agent wasn’t trained or evaluated against.
To build agents that actually function in 2026, you need to pull them out of this box. You need to start thinking about "prompt engineering" along with building a Context Layer.
TL;DR
- Context drift kills production agents - Models fail when training data conflicts with current reality (deprecated APIs, changed policies)
- Large context windows create "lost in the middle" problems - Stuffing 2M tokens into Gemini doesn't help if the model can't find relevant information
- Vector databases lose relationships - Semantic similarity can't capture conditional logic like "Policy A overrides Policy B if condition C is met"
- Context graphs are the future - Explicit entity relationships beat fuzzy embeddings for decision-making
- Separate operational from decision context - Dynamic state goes last (recency bias), static rules go first (prompt caching saves 90% cost)
- Automate context ingestion - Tools like Firecrawl turn messy web sources into structured, self-healing context pipelines
Why is a context layer important when building AI agents?
There is a prevalent myth in our industry that the solution to a confused model is a larger context window.
"Just dump the whole repo in," they say. "Gemini has 2 million tokens."
This is lazy engineering. It's also shockingly expensive. And it doesn't work.
When you stuff a context window with massive amounts of data, you trigger the "Lost in the Middle" phenomenon (confirmed by Stanford research). You are simply giving the agent more noise.
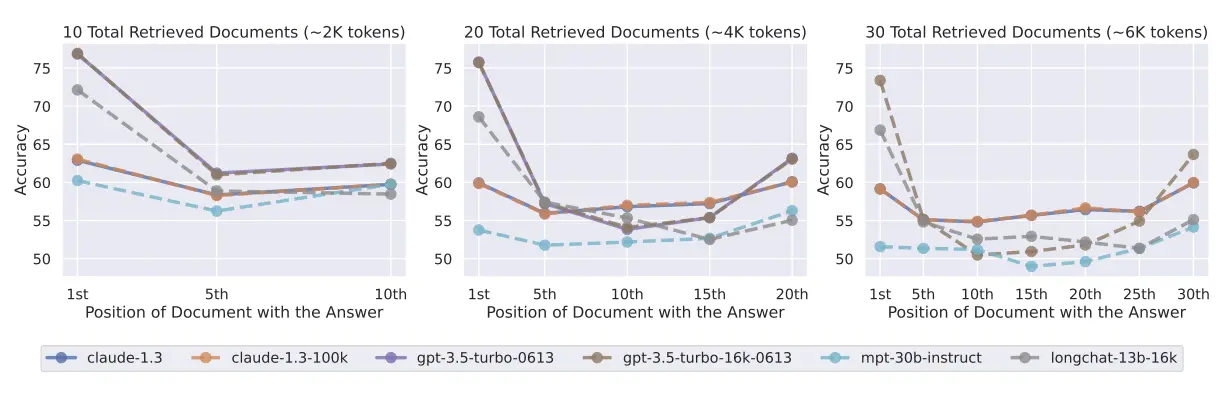
Researchers discovered that AI language models struggle with what's called the "lost in the middle" problem. When given multiple documents to answer a question, these models perform best when the relevant information appears at the very beginning or end of the input. Performance drops significantly when the answer is buried in the middle. Even though the model processes all the documents, the position of key information dramatically affects whether it can use that information correctly.
A Context Layer shifts the burden of "paying attention" from the model to the architecture.
A context layer prevents context drift
The core issue is what models know is often subtly wrong for the specific moment in time they are operating in. We call this Context Drift.
Context Drift happens when the model's training data (the past) conflicts with the current environment (the present). It is a temporal mismatch that no amount of prompt engineering can fix - you need capabilities like change tracking to detect these semantic shifts.
For a structured breakdown of when agents should rely on training data, a retrieval index, or live web data — and how each choice shapes accuracy and freshness — see the dedicated guide.
Here is a real example from my terminal yesterday. I was trying to get an agent to update some scraping logic:
> agent run --task "update the scraping logic to run asynchronously"
[AGENT] Reading docs...
[AGENT] Using `firecrawl.scrape_async()` to initiate job...
[ERROR] AttributeError: module 'firecrawl' has no attribute 'scrape_async'It failed because rather than identifying the correct method, the agent fabricated one based on my request.
A functioning context layer would've forced the model to prioritize current data over the training knowledge. Claude Skills work similarly by pulling context only when necessary so your chat context doesn't get bloated.
P.S: Check out how we built a Claude Skills generator with Firecrawl's Agent endpoint.
Vector stores are no longer enough
A counter-argument is that a Vector Database solves this.
"Just embed the documentation."
When you embed a document, you squash its meaning into a fixed-dimensional vector. You lose the relationships between entities. For instance, in a vector database:
- Vector search sees: "Refund policy" is semantically similar to "Cancellation policy."
- Relationship logic sees: "Refunds are blocked if the contract type is 'Enterprise Legacy', unless the 'Manager Override' flag is set."
A vector search will happily retrieve the "Refund Policy" chunk. It will likely miss the "Enterprise Legacy" exception because that clause sits in a different document and the model, lacking the connection, grants the refund.
This is exactly why we showcase how we built the DeepSeek RAG Documentation Assistant. Rather than just fuzzy-searching, it pulls structured, grounded answers to prevent inaccurate actions.
And then there’s the discussion on “Context Graphs”
The smartest people in AI capital are rapidly converging on the context graph architecture.
Jaya Gupta at Foundation Capital recently argued that the enterprise stack currently has two pillars:
- Systems of Record: Databases (Postgres, Snowflake) that store what happened.
- Systems of Engagement: Interfaces (Salesforce, Zendesk) that manage human interaction.
And then there’s Systems of Reasoning, a missing third pillar that captures the why.
We need this pillar to understand why we approved a refund or merged a PR without a test. This contextual knowledge cannot be compiled in official docs because it lives in the graph of relationships between your company policies, past decisions by you or your team members, and your current state.
HubSpot CTO Dharmesh Shah calls this idea "intellectually compelling" but warns that it's a massive lift. He's right: building a graph is hard. It requires structuring data and maintaining graph integrity.
But I think it’s going to be a necessary evil. If you want autonomous agents that don't burn your house down, you don't have a choice. You can handle the complexity of the graph during build time, or you can handle the complexity of the cleanup during runtime. I prefer the former.
| Use Case | "No context" failure | Context layer fix |
|---|---|---|
| Coding | Agent uses a deprecated API method because it "remembered" it from training data. | Agent sees the exact version constraints and changelogs for the current repo. |
| Support | Agent refunds a customer who is on a "no refunds" legacy contract. | The agent reads the customer's specific contract terms before taking action. |
| Data Ops | Agent deletes "duplicate" rows that were actually intentional audit logs. | Agent understands the semantic meaning of the data via live schema extraction. |
(Check out more use cases to see how context layers help in different industries.)
Also, check out our Contradiction Agent post if you want to see what happens when you build a system specifically designed to find and fight these inconsistencies in the graph. It’s pretty wild.
What are the types of context that are important for AI agents in 2026?
Most teams we speak to create one massive system prompt and stuff every piece of information into it. But as I mentioned earlier, it fails due to the sheer amount of noise in the prompt. In our production systems, and when using MCP servers, we rigorously separate context into two distinct categories.
1. Operational context (dynamic)
This is the state of the world right now. It is high-velocity, ephemeral, and crucial for "grounding."
- "The user is authenticated as admin."
- "The current error log shows a TimeoutException on line 42."
- "We have scraped 3 of 5 URLs."
- "The user's credit balance is $4.50."
Characteristics:
- Volatility: High. Changes every turn or every second.
- Source: APIs, Databases, Logs.
- Injection: Immediate.
Placement: This context should be injected at the end of your prompt. LLMs suffer from recency bias (the "lost in the middle" phenomenon). By placing the immediate state last, you ensure the model attends to it most strongly. You could end your prompt with: "Given all the rules above, here is where we are right now."
2. Decision context (static)
This is the "physics" of your agent's universe. It is the stable set of rules and knowledge that defines valid behavior.
- "We write TypeScript in strict mode."
- "Refunding a transaction >$50 requires manager approval."
- "Here is the OpenAPI spec for the Stripe API."
- "Our brand voice is cynical but helpful."
Characteristics:
- Volatility: Low. Changes typically on deployment or policy updates.
- Source: Documentation, Wikis, Codebases.
- Injection: Cached.
Placement Strategy: This context belongs at the very beginning of your system prompt. There are two reasons for this:
- First, it sets the boundary conditions for all subsequent reasoning. It frames the "physics" of the conversation.
- Second, and more importantly, it’s cheaper because of prompt caching.
OpenAI clearly states in their documentation that prompt caching can save up to 90% of the token cost while also reducing latency.

If you structure your context layer correctly, your massive Decision Context (your entire API spec, your 50-page brand guide, your database schema) lives in this cached prefix. You pay to load it once (cache write), and then you pay pennies to access it (cache read) for every subsequent turn.
Can you automate context feeding into your AI agents?
The short answer is yes. We built Firecrawl just for that. But before you think roll your eyes because it’s a [Sales Pitch]...
You cannot build a sustainable agent if you’re still manually copying over documents into a markdown file for your RAG pipeline. The web changes too fast, and you don’t want to provide customers with inaccurate responses just because someone “missed updating the RAG docs.”
Firecrawl serves as the Ingestion Module for your Context Layer. We didn't build it because we love scraping. We built it because existing tools were built for a human-centric web, not an agent-centric one.
Think of the modern web. It is a hostile environment for a simple GET request.
- Client-side rendering: The content you need (the API docs, the pricing table) isn't in the HTML. It's injected by React 700ms after load.
- Access controls: Some sites restrict automated access.
- Navigation traps: Infinite scroll, shadow DOMs, iframe injections.
If you try to build your own ingestion pipeline using beautifulsoup and requests, you will spend 80% of your engineering time maintaining scrapers and 20% building your agent.
Firecrawl abstracts this chaos. It turns the messy, adversarial web into clean structured fields for AI search and RAG for your Context Graph. We've seen this pattern work for everything from Deep Research agents to integrations like the Replit Agent and many other use cases across the industry. If you're new to Firecrawl's endpoints, Firecrawl 101 covers the core web data API — scrape, search, crawl, and interact — with working examples for each.
The "self-healing" context pipeline
Here's how we create robust self-healing context for our internal use. Instead of just scraping the page once and storing it for later retrieval, we treat external documentation as a live dependency.
We define a Schema for the decision context we need to create a structured signal for our usecase.
Take a look at this code snippet:
from firecrawl import FirecrawlApp
app = FirecrawlApp(api_key="fc-YOUR_KEY")
# 1. Define schema
schema = {
"type": "object",
"properties": {
"changes": {
"type": "array",
"items": {
"type": "object",
"properties": {
"date": {"type": "string"},
"product": {"type": "string"},
"description": {"type": "string"},
},
"required": ["date", "product", "description"],
},
}
},
"required": ["changes"],
}
# 2. Extract
response = app.extract(
["https://stripe.com/blog/changelog"],
schema=schema,
prompt="Extract the 3 most recent updates.",
)
print(response)
Output:
{
"changes": [
{
"date": "Dec 2025",
"product": "Connect",
"description": "The Accounts v2 API is now generally available for new Connect users to represent both their connected accounts and customers across Stripe."
},
{
"date": "Dec 2025",
"product": "Payments",
"description": "Businesses in Australia can now offer PayTo direct debits."
},
{
"date": "Oct 2025",
"product": "Payments",
"description": "You can now use the Payment Records API to track and keep a unified history of your payments."
}
]
}If you set up this script as a cron job, your specific Context Layer becomes self-healing because Firecrawl is now fetching the latest information at regular intervals. If Stripe releases a new version that renames Charge.create to PaymentIntent.create:
- Without Firecrawl: Your agent uses the old method (training data). The code crashes. You spend 4 hours debugging.
- With Firecrawl: The cron job runs at midnight. It detects the changelog update. It extracts the breaking change. It updates the Decision Context. When you ask the agent to write code at 9 AM, it sees the node: Stripe v100: Charge.create is DEPRECATED. It generates the correct code on the first try.
This is basically plumbing. Boring, unsexy plumbing that saves you when you need it most.
What’s my take?
We are entering the era of Context Engineering. For the last two years, we have been obsessed with models. "Is GPT-5 better than Claude 3.5?" "What is the MMLU score?"
Now, all the models are good enough. The differences between them are marginal compared to the difference between "an agent with the right context" and "an agent without it."
So, if you are building agents in 2026, you are a data engineer, an architect of context. Stop obsessing over the model weights, which you cannot control, and begin obsessing over your data pipeline, which you can.
Build the ingestion layer. Structure the mess. Respect the attention budget. And please, strictly separate your static and dynamic context. Your CFO (and your users) will thank you.
Try Firecrawl in your agent building workflow today and make it your team's superpower.
Frequently Asked Questions
What is the difference between operational and decision context?
Operational context is the high-velocity, ephemeral state of the specific task at hand (e.g., "User ID 123", "Error 500"). Decision context is the stable, low-velocity codified knowledge required to make judgments (e.g., "Refund Policy", "API Schema"). Separating them allows you to leverage prompt caching for the decision context while keeping the operational context fresh.
How does a context graph differ from a vector database?
A vector database stores "chunks" of text based on semantic similarity (embeddings). It is good for fuzzy matching. A Context Graph stores "entities" and their explicit relationships (edges). It allows for logical traversal. For example, a context graph can tell you that "Policy A *overrides* Policy B if condition C is met," which is a relationship often lost in vector space.
Can Firecrawl handle dynamic websites for context ingestion?
Yes. Firecrawl is designed to handle modern, complex web architectures. It manages JavaScript rendering, infinite scrolling, authentication (in some cases), and dynamic DOM updates. It essentially turns any dynamic website into a static, structured API response for your context layer.
Why not just use a larger context window?
Larger context windows (like Gemini's 2M tokens) are powerful but dangerous. They suffer from the "Lost in the Middle" phenomenon, where the model's ability to retrieve information degrades as the context grows. They are also significantly slower and more expensive. A curated Context Layer ensures you are feeding the model high-signal data relevant to the *immediate* decision, rather than hoping it finds a needle in a massive haystack.
