
TL;DR
- Web scraping automates data collection from public websites: price monitoring, lead generation, research, and feeding AI pipelines all rely on it.
- For static sites,
requestsand BeautifulSoup are all you need: free, no setup, works for most beginner projects. - For JavaScript-heavy sites, plain HTTP requests return empty results. Firecrawl handles JS rendering in the cloud and returns clean data via a simple API.
- Pydantic schemas let you define exactly what structured data you want instead of writing fragile CSS selector code.
- Scaling from one page to an entire site takes a single
app.crawl()call with Firecrawl. No URL queue management, no recursive logic to maintain. - Save your data as CSV for spreadsheet analysis, JSON for web apps, or SQLite for anything that needs queries over time.
What is web scraping and why should you care?
Web scraping is a powerful automation technique that lets you use code to pull data from websites automatically. You write programs that visit web pages, read their content, and collect the information you need. This takes minutes instead of hours of manual copying.
Companies everywhere use this. Online stores track competitor prices on thousands of products. Job hunters set up alerts for new openings. Researchers study social media posts and government data. Real estate investors watch property listings for trends. And Airbnb got started by scraping Craigslist listings.
How does this apply to you? Web scraping connects you to any public data online. Whether you're tracking prices on stuff you're thinking about buying, building datasets for projects, or researching market opportunities, scraping gives you access to information at scale. Much public data you find online is available for scraping, although some websites may have restrictions (check a site's robots.txt and terms of service before scraping those sites).
This beginner's guide starts from zero. You'll build real projects that solve actual problems. By the end, you'll be comfortable collecting data from most websites and handling your own scraping challenges.
What can you do with web scraping?
The short answer: anything that requires collecting public data at scale. Here are the most common use cases:
- Price and product monitoring. Track competitor prices across thousands of products. Monitor MAP (minimum advertised price) compliance from distributors. Set alerts when an item drops below a target price.
- Market research and competitive intelligence. Track competitor messaging, feature launches, and job postings. Build datasets from review sites and forums. Monitor how pricing and positioning shifts over time.
- Lead generation. Collect company names, contacts, and locations from directories, job boards, and review platforms for sales and marketing outreach.
- News and content monitoring. Track mentions of specific companies, topics, or keywords across news sites and blogs. Useful for PR teams, investors, and researchers.
- Real estate. Pull listing data, rental yields, and vacancy rates from property sites to inform investment decisions or appraisals.
- AI and machine learning data. In 2026, a growing share of scraping feeds directly into LLMs, RAG pipelines, and AI agents. Clean, structured web data is the raw material for training datasets, grounding systems, and real-time agent context.
Most of the projects in this guide touch on one or more of these. The technical skills transfer across all of them.
Understanding how websites work
Before you scrape data from websites, you need to understand what you're actually scraping.
Let's start with a simple test: open any website in your browser, right-click anywhere on the page, and select "View Page Source." You'll see a wall of text that looks like code. This is HTML, the language that describes how web pages are built. HTML might look scary at first, but it's just a way of organizing information using tags. You only need to understand a few basic concepts to start scraping.

HTML works with containers called tags. Each tag has a specific job: <title> contains the page title, <p> holds paragraphs of text, <div> creates sections, and <a> makes links. These tags often have attributes that give additional information. For example, <a href="https://example.com"> tells the browser where a link should go. When you scrape a website, you tell your program to find specific tags and pull out the text inside them. You give your code directions: "Go to the page, find the tag labeled 'price,' and tell me what's inside."
Your browser's developer tools make this process much easier than staring at raw HTML. Press F12 or right-click and select "Inspect Element" to open these tools. Now you can hover over any part of the webpage and see exactly which HTML tag creates that content. This is your scraping superpower. Instead of guessing which tag contains the data you want, you can point and click to find it instantly. The developer tools show you the structure of any webpage in real time.
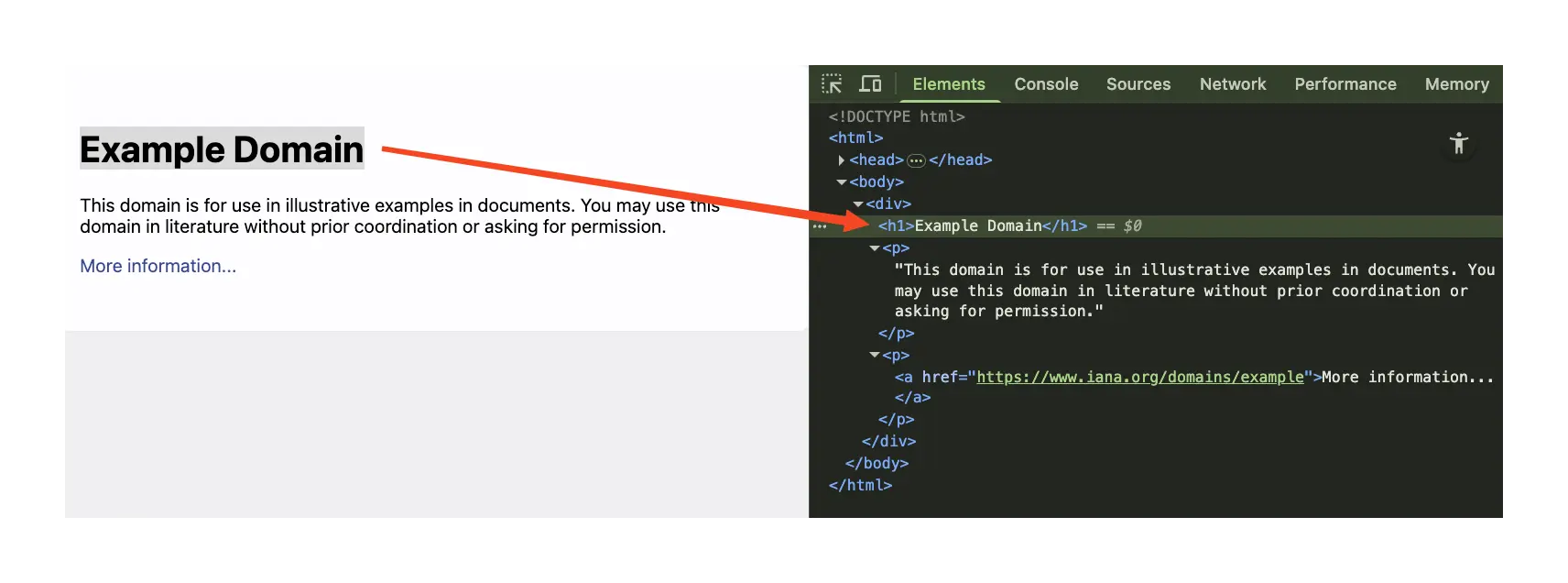
Let's practice with a real example. Go to books.toscrape.com and find any book listing. Right-click on the book title and select "Inspect Element." You'll see it's contained in an <a> tag. Do the same for the price (look for a <p> tag with class "price_color") and the star rating (search for "star-rating" in the class attribute). This detective work is exactly what you'll automate in the next section when we write our first scraping script. The only difference is that instead of clicking around manually, you'll teach Python to find these patterns for you.
Your first scraping project: book prices
Now that you understand how HTML works and can find elements using developer tools, let's automate that process. You'll learn how to scrape a web page in Python by writing a script that visits books.toscrape.com, finds a book's title, price, and rating, and prints them to your screen. This builds directly on the detective work you did in the previous section, but instead of clicking around manually, you'll teach Python to do it for you.
First, you need to set up your Python environment with two libraries. Install them using pip in your terminal or command prompt: pip install requests beautifulsoup4. The requests library fetches web pages, while beautifulsoup4 parses the HTML and lets you search for specific tags. If you're using Anaconda or another Python distribution, these might already be installed.
Let's build the script step by step. Start by creating a new Python file and importing the libraries:
import requests
from bs4 import BeautifulSoupThe requests library handles all the web communication for you. It sends your request to the website and brings back the HTML content. BeautifulSoup takes that raw HTML and turns it into a structure you can search through using Python methods.
Next, fetch the webpage and create your parsing object:
url = "https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html"
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')The requests.get() function visits the URL and downloads the page content. The BeautifulSoup() function takes that content and creates a soup object that represents the entire HTML structure. Think of the soup object as your searchable version of the webpage.
Now comes the fun part. Extract the book's title using the same <h1> tag you found with developer tools:
title = soup.find('h1').textThe find() method searches through the HTML and returns the first <h1> tag it finds. The .text part pulls out just the content inside the tag, without any HTML markup. This gives you the clean book title.
Extract the price using the class you identified earlier:
price = soup.find('p', class_='price_color').textHere you're searching for a <p> tag that has the specific class "price*color". The class*parameter (note the underscore) tells BeautifulSoup to look for that exact CSS class. Again,.text gives you just the price without HTML tags.
The rating needs a slightly different approach since it's stored in the CSS class names:
rating_element = soup.find('p', class_='star-rating')
rating_classes = rating_element.get('class')
rating = rating_classes[1]This finds the paragraph with class "star-rating" and gets all its classes as a list. The rating classes look like ['star-rating', 'Three'], so rating_classes[1] gives you the actual rating value.
Finally, display your results:
print(f"Title: {title}")
print(f"Price: {price}")
print(f"Rating: {rating}")Here's the complete working script that brings all these pieces together:
import requests
from bs4 import BeautifulSoup
url = "https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html"
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
title = soup.find('h1').text
price = soup.find('p', class_='price_color').text
rating_element = soup.find('p', class_='star-rating')
rating_classes = rating_element.get('class')
rating = rating_classes[1]
print(f"Title: {title}")
print(f"Price: {price}")
print(f"Rating: {rating}")When you run this script, you'll see the following output:
Title: A Light in the Attic
Price: £51.77
Rating: ThreeYou've just built your first web scraper in under 20 lines of code. The script does exactly what you did manually with developer tools, but it can run this process in seconds rather than minutes. More importantly, you now understand the basic pattern of web scraping: fetch the page, parse the HTML, find the elements you want, and extract the data. In the next section, you'll learn how to apply this same pattern to scrape multiple books at once.
Handling multiple pages and lists
You've learned how to scrape a web page for a single book, but the real power of web scraping comes from processing multiple items at once. Instead of visiting each book page individually, you can scrape an entire catalog page that lists many books together. This section teaches you how to find multiple elements, loop through them, and collect all the data in one go.
The main page of books.toscrape.com displays 20 books at once, each contained in its own section of HTML. Your job is to find the pattern that repeats for each book and extract the same information (title, price, rating) from all of them. This is where the detective work from Section 2 becomes even more valuable.
Let's start by fetching the main page and finding all the book containers:
import requests
from bs4 import BeautifulSoup
url = "https://books.toscrape.com/"
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')This is the same setup as before, but now you're targeting the main page instead of a specific book. The main page contains multiple books, each wrapped in an <article> tag with class "product_pod".
Find all the book containers using BeautifulSoup's find_all() method:
books = soup.find_all('article', class_='product_pod')The find_all() method returns a list containing every <article> tag that has the class "product_pod". This gives you one element for each book on the page. You can check how many books you found by checking the length of this list.
Now you need somewhere to store the data from all these books:
books_data = []This creates an empty list that will hold information about each book. As you process each book, you'll add a dictionary containing its title, price, and rating to this list. The magic happens with a loop that processes each book container:
for book in books:
title_link = book.find('h3').find('a')
title = title_link.get('title')This loop goes through each book container one by one. For each book, it finds the <h3> tag (which contains the title), then finds the <a> tag inside it. The get('title') method extracts the title attribute from the link, which contains the full book title.
Extract the price using the same method you learned for single books:
price_element = book.find('p', class_='price_color')
price = price_element.text if price_element else 'No price'This finds the paragraph with class "price_color" and extracts its text. The if price_element else 'No price' part is basic error handling. If for some reason a book doesn't have a price element, your script won't crash but will record "No price" instead.
Handle the rating with similar error checking:
rating_element = book.find('p', class_='star-rating')
if rating_element:
rating_classes = rating_element.get('class')
rating = rating_classes[1]
else:
rating = 'No rating'This checks if the rating element exists before trying to extract data from it. If it exists, it gets the class list and takes the second element (the actual rating). If not, it records "No rating". Store each book's data in a dictionary and add it to your list:
book_data = {
'title': title,
'price': price,
'rating': rating
}
books_data.append(book_data)This creates a dictionary for each book with three pieces of information, then adds that dictionary to your books_data list. After the loop finishes, you'll have a list containing data for every book on the page.
Here's the complete script that brings all these pieces together:
import requests
from bs4 import BeautifulSoup
url = "https://books.toscrape.com/"
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# Find all book containers
books = soup.find_all('article', class_='product_pod')
# Create empty list to store book data
books_data = []
# Loop through each book and extract data
for book in books:
# Extract title from the link's title attribute
title_link = book.find('h3').find('a')
title = title_link.get('title')
# Extract price
price_element = book.find('p', class_='price_color')
price = price_element.text if price_element else 'No price'
# Extract rating
rating_element = book.find('p', class_='star-rating')
if rating_element:
rating_classes = rating_element.get('class')
rating = rating_classes[1]
else:
rating = 'No rating'
# Store the data
book_data = {
'title': title,
'price': price,
'rating': rating
}
books_data.append(book_data)
# Display results
print(f"Found {len(books_data)} books")
print("\nFirst 5 books:")
for i, book in enumerate(books_data[:5]):
print(f"{i+1}. {book['title']} - {book['price']} - {book['rating']} stars")
print(f"\nTotal books scraped: {len(books_data)}")When you run this script, you'll see output like this:
Found 20 books
First 5 books:
1. A Light in the Attic - £51.77 - Three stars
2. Tipping the Velvet - £53.74 - One stars
3. Soumission - £50.10 - One stars
4. Sharp Objects - £47.82 - Four stars
5. Sapiens: A Brief History of Humankind - £54.23 - Five stars
Total books scraped: 20You've now scraped data from 20 books in the same time it took to scrape one book manually. The script handles missing data gracefully and organizes everything in a structured format. This approach scales to any number of items. You've learned the fundamental pattern of list-based scraping that works across most websites. For a deeper look at this technique—including how to handle pagination, infinite scroll, and schema-based extraction—see our guide on list crawling with Python.
When traditional tools hit the wall
You've scraped books from multiple pages using requests and BeautifulSoup. These tools work well for static websites where the content appears in the HTML you download. But modern websites often work differently. They can make your scripts return empty results even when you see data in your browser.
Let's test this with a real example. There are two versions of the same quotes website: one built with traditional HTML and another that loads content using JavaScript. Both look the same when you visit them, but they behave very differently when scraped.
First, test the traditional version using the same approach you've learned:
import requests
from bs4 import BeautifulSoup
# Test the static version
static_url = "http://quotes.toscrape.com/"
response = requests.get(static_url)
soup = BeautifulSoup(response.content, 'html.parser')
quotes = soup.find_all('div', class_='quote')
print(f"Quotes found: {len(quotes)}")Output:
Quotes found: 10This works as expected. The script finds 10 quotes and can extract all the text and author information. You get clean, usable data just like with the books website.
Now try the same code on the JavaScript version:
# Test the JavaScript version
js_url = "http://quotes.toscrape.com/js/"
response = requests.get(js_url)
soup = BeautifulSoup(response.content, 'html.parser')
quotes = soup.find_all('div', class_='quote')
print(f"Quotes found: {len(quotes)}")Output:
Quotes found: 0Zero quotes found. Your script runs without errors, but it finds no data even though both websites show the same quotes when you visit them in your browser.
Here's what happens. When you use requests.get(), you're asking the web server to send you the HTML file directly. For static websites, this HTML file contains all the content you see. For JavaScript-heavy websites, the HTML file is just a skeleton. The actual content gets loaded after by JavaScript code running in your browser. Your script never sees this content because it can't run JavaScript.
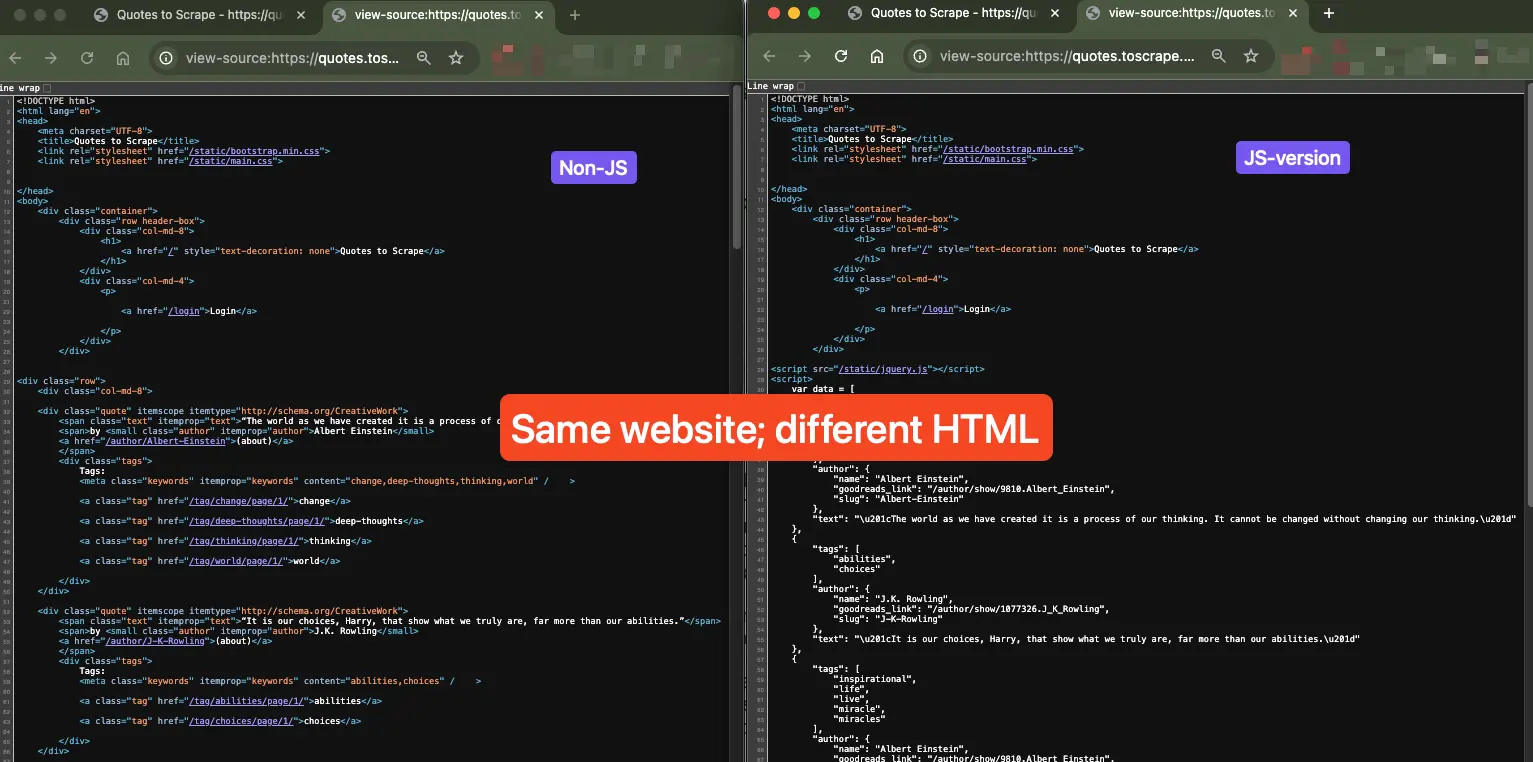 You can check this yourself by comparing "View Page Source" with "Inspect Element" on modern websites. The page source shows what your script gets, while the inspector shows what your browser displays after JavaScript runs. The difference can be huge.
You can check this yourself by comparing "View Page Source" with "Inspect Element" on modern websites. The page source shows what your script gets, while the inspector shows what your browser displays after JavaScript runs. The difference can be huge.
Let's see what the JavaScript version actually contains:
js_url = "http://quotes.toscrape.com/js/"
response = requests.get(js_url)
soup = BeautifulSoup(response.content, 'html.parser')
quotes = soup.find_all('div', class_='quote')
page_text = soup.get_text().strip()
print(f"Quotes found: {len(quotes)}")
print(f"Total content: {len(page_text)} characters")
print(f"Content preview: {page_text}")Output:
Quotes found: 0
Total content: 152 characters
Content preview: Quotes to Scrape
Quotes to Scrape
Login
Next →
Quotes by: GoodReads.com
Made with ❤ by ZyteThe JavaScript version contains almost no content. Your script gets the page title, navigation elements, and footer, but none of the actual quotes. This is the main challenge of modern web scraping: websites use JavaScript to load content dynamically, making traditional HTTP requests fail.
This same pattern appears across the web. E-commerce sites load product listings via JavaScript. News websites use infinite scroll that loads articles as you browse. Social media platforms generate feeds dynamically. Job boards populate listings after the page loads. In all these cases, requests and BeautifulSoup will give you empty or incomplete results.
Other common challenges include pagination across many pages, inconsistent HTML that breaks parsing logic, and content that loads dynamically after the initial page request. These problems led to the development of more advanced scraping tools that can handle JavaScript execution and work with modern websites reliably. In the next section, you'll learn when and how to use these modern solutions.
Modern solutions: when to use scraping APIs
The good news is that this problem sparked the development of better solutions, including web scraping APIs for JavaScript sites. Instead of building complex workarounds yourself, you can choose from several modern approaches that handle these problems for you.
The most common solutions include browser automation tools like Selenium (which controls a real browser), headless browsers like Playwright, and scraping APIs that run in the cloud. Each approach has different trade-offs between complexity, cost, speed, and reliability. Understanding these trade-offs helps you choose the right tool for each project.
Browser automation tools give you complete control but require managing browser installations, handling crashes, and keeping scripts aligned as sites change. They're powerful but complex to set up and maintain. Scraping APIs handle all the technical complexity for you but cost money per request. They're fast to implement but add ongoing costs. The choice depends on your needs: time constraints, budget, technical expertise, and project scale.
Let's try the API scraping approach using Firecrawl, one modern scraping service designed to handle the problems you saw in Section 5. Firecrawl runs browsers in the cloud, executes JavaScript, and returns clean data through a simple API. This means you can scrape JavaScript-heavy sites without managing any browser infrastructure yourself.
You can try Firecrawl's endpoints without an API key to start. When you're ready to go further, sign up for a Firecrawl account at firecrawl.dev for a key with higher rate limits and more credits (the free tier includes 1,000 credits per month). Install the Python SDK and set up your environment:
# Install the Firecrawl SDK
# pip install firecrawl-py
from firecrawl import Firecrawl
import os
# Set your API key (sign up at firecrawl.dev for free)
os.environ["FIRECRAWL_API_KEY"] = "your-api-key-here"
app = Firecrawl(api_key=os.getenv("FIRECRAWL_API_KEY"))The setup is straightforward. You import the library, create a Firecrawl instance with your API key, and you're ready to scrape. No browser management, no JavaScript execution complexity.
Now let's try scraping the same JavaScript quotes site that failed with traditional tools:
# Try the JavaScript site that failed before
url = "http://quotes.toscrape.com/js/"
result = app.scrape(url, formats=["markdown"])
print("Firecrawl Results:")
print(f"Status: Success")
print(f"Content length: {len(result.markdown)} characters")
print(f"First 300 characters:")
print(result.markdown[:300])Output:
Firecrawl Results:
Status: Success
Content length: 1505 characters
First 300 characters:
# [Quotes to Scrape](https://quotes.toscrape.com/)
[Login](https://quotes.toscrape.com/login)
"The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking."by Albert Einstein
Tags: changedeep-thoughtsthinkingworld
"It is our choices, Harry, thThe difference is striking. Firecrawl extracts all the quotes that were invisible to traditional scraping. It handles the JavaScript execution, waits for content to load, and returns clean, readable text in markdown format. Where traditional tools found 0 quotes and 152 characters of content, Firecrawl extracted over 1,500 characters of actual quote data.
If you prefer working from the command line, the Firecrawl CLI lets you scrape without writing any Python code:
# Scrape a page to clean Markdown
firecrawl scrape https://quotes.toscrape.com/js/ --format markdown
# Search and get full page content in one step
firecrawl search "web scraping tutorial python" --scrape --limit 3This approach makes sense when you're dealing with JavaScript-heavy sites, need reliable results without maintenance overhead, or want to focus on data analysis rather than scraping infrastructure. The cost per request is typically small compared to the time saved on development and maintenance. You trade money for time, reliability, and simplicity.
But APIs aren't always the right choice. For simple static sites like the books example from earlier sections, traditional tools work perfectly and cost nothing to run. For learning purposes, understanding both approaches gives you the choice to pick the right tool for each situation. In the next section, you'll learn how to extract structured data using both traditional and modern methods.
Extracting structured data like a pro
You've learned how to extract basic text from web pages, but modern data projects require more than just raw text. You need structured data in formats like JSON that can be stored in databases, processed by other programs, and integrated with different systems. This section shows you how to move beyond simple text extraction to create well-organized, structured datasets.
The problem with traditional scraping is that extracting structured data requires writing complex parsing logic. You need to move through nested HTML elements, handle missing data without crashing, and ensure consistent output formats. As websites become more complex, this parsing logic becomes harder to maintain and breaks easily.
Let's try this with a real-world example using Hacker News, a popular tech news aggregator. We'll extract news stories with their titles, scores, and metadata using both traditional and modern approaches to see the difference in complexity and results.
First, let's try the traditional approach with BeautifulSoup. Extracting structured data requires careful navigation through HTML elements:
import requests
from bs4 import BeautifulSoup
url = "https://news.ycombinator.com"
response = requests.get(url, headers={'User-Agent': 'Mozilla/5.0'})
soup = BeautifulSoup(response.content, 'html.parser')The headers parameter adds a User-Agent string so the server treats your request like a normal browser visit. Some sites return errors or incomplete pages when this header is missing.
Find all the story containers and start building your data structure:
# Find story elements
stories = soup.find_all('tr', class_='athing')
news_data = []
for story in stories[:3]: # First 3 stories
story_data = {}
# Extract title
title_elem = story.find('span', class_='titleline')
if title_elem:
title_link = title_elem.find('a')
if title_link:
story_data['title'] = title_link.text.strip()Each story on Hacker News is contained in a <tr> element with class "athing". The title is nested inside a <span> with class "titleline", which contains an <a> tag with the actual title text. The if statements prevent crashes when elements are missing.
The score information lives in a separate row, making extraction more complex:
# Find score in next row (complex navigation)
next_row = story.find_next_sibling('tr')
if next_row:
score_elem = next_row.find('span', class_='score')
if score_elem:
score_text = score_elem.text # e.g., "58 points"
story_data['score'] = int(score_text.split()[0])
else:
story_data['score'] = 0
news_data.append(story_data)The find_next_sibling('tr') method moves to the next table row, which contains the score information. The score text needs parsing because it comes as "58 points" and you need just the number. The split()[0] takes the first word and int() converts it to a number.
Print your results:
print("Traditional approach results:")
for story in news_data:
print(f"- {story.get('title', 'No title')} ({story.get('score', 0)} points)")Output:
Traditional approach results:
- Grapevine cellulose makes stronger plastic alternative, biodegrades in 17 days (69 points)
- Titania Programming Language (27 points)
- OCSP Service Has Reached End of Life (97 points)This approach works but notice the complexity. You need to understand the HTML structure deeply, move between sibling elements, handle missing data with conditionals, and parse text to extract numbers. The code is fragile and breaks easily when websites change their layout.
Now let's see the modern approach using Firecrawl with Pydantic schemas. Instead of writing parsing logic, you define the data structure you want:
from firecrawl import Firecrawl
from pydantic import BaseModel, Field
from typing import List
class NewsStory(BaseModel):
title: str = Field(description="The title of the news story")
score: int = Field(description="The number of points the story has received")
comments_count: int = Field(description="The number of comments on the story")
author: str = Field(description="The username who submitted the story")
class HackerNewsData(BaseModel):
stories: List[NewsStory] = Field(description="List of news stories")Pydantic models use Python's type hints to define data structures. The BaseModel class provides validation and serialization features. The Field() function adds descriptions that help guide the AI extraction process. The List[NewsStory] syntax means "a list containing NewsStory objects."
The container class HackerNewsData is important because it tells Firecrawl to extract multiple stories. Without it, you'd only get one story back even if many exist on the page.
Now extract the data using this schema:
app = Firecrawl(api_key="your-api-key-here")
result = app.scrape(
url,
formats=[{
"type": "json",
"schema": HackerNewsData,
"prompt": "Extract the top 3 news stories with "
"title, score, comments count, and author"
}]
)The formats parameter accepts a list of format specifications. Here you're requesting JSON output using your schema. The prompt parameter tells Firecrawl what data to look for and helps it understand the context.
Display the results:
print("Modern approach results:")
for story in result.json['stories'][:3]:
title = story['title']
score = story['score']
comments = story['comments_count']
author = story['author']
print(f"- {title} ({score} points, {comments} comments, by {author})")Output:
Modern approach results:
- Grapevine cellulose makes stronger plastic alternative, biodegrades in 17 days (69 points, 45 comments, by westurner)
- Titania Programming Language (27 points, 1 comments, by MaximilianEmel)
- OCSP Service Has Reached End of Life (97 points, 19 comments, by pfexec)The modern approach extracts more complete data (including comments count and author information that the traditional method missed) with much less code. You describe what you want instead of how to get it, making the code easier to maintain and more reliable.
The schema-based approach also handles missing data well. If Firecrawl can't find a particular field, it will leave that field empty or use default values based on your schema definition rather than crashing your script. This makes your scraping more stable for production use.
This approach works best when you need consistent, clean data for databases, APIs, or machine learning pipelines. Instead of writing custom parsing and validation logic for each website, you define your desired data structure once and let the extraction engine handle the complex HTML navigation and data cleaning for you.
Scaling beyond single pages
You've mastered extracting data from individual web pages, but real-world projects often require collecting information from entire websites. Instead of manually finding and scraping each page, you need to automatically discover all relevant pages on a site and process them step by step. This section shows you how to scale from single-page scraping to full-site crawling using both traditional and modern approaches.
The problem with scaling beyond single pages lies in website discovery. Websites don't provide convenient lists of all their pages. You need to start from a homepage, find links to other pages, follow those links, and repeat the process. This means handling pagination, avoiding infinite loops, respecting rate limits, and managing large amounts of data well.
Traditional approaches require building complex crawling logic yourself. You need to extract links from pages, manage a queue of URLs to visit, handle relative and absolute URLs correctly, and implement safeguards against getting stuck in loops. Modern crawling APIs handle all this complexity for you, automatically discovering pages and returning structured results.
Let's build a complete product catalog scraper for books.toscrape.com. We'll start with the traditional approach to understand the problems, then see how modern tools simplify the entire process.
Traditional approach: following links with BeautifulSoup
Building a traditional crawler requires several components working together. You need URL management to track visited pages and discover new ones, content extraction logic for each page type, and error handling for network issues and missing pages.
Start by importing the libraries you'll need and setting up the basic structure:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin, urlparse
import timeThe urllib.parse module helps handle URLs correctly. The urljoin() function combines relative URLs with base URLs to create complete URLs. For example, if you're on https://books.toscrape.com/ and find a link to catalogue/page-2.html, urljoin() creates the complete URL https://books.toscrape.com/catalogue/page-2.html.
Set up your crawling infrastructure with variables to track progress:
base_url = "https://books.toscrape.com/"
visited_urls = set()
all_books = []
max_pages = 3 # Limit for demo purposesThe visited_urls set prevents your crawler from visiting the same page twice, which could cause infinite loops. The all_books list accumulates data from all pages. The max_pages limit prevents the demo from running too long, but real crawlers need better stopping conditions.
Create the main crawling function with recursive logic:
def crawl_page(url, depth=0):
# Stop if we've hit our limit or already visited this page
if depth >= max_pages or url in visited_urls:
return
print(f"Crawling: {url}")
visited_urls.add(url)The depth parameter tracks how many levels deep you've crawled from the starting page. This prevents infinite recursion and helps control the scope of your crawling. The function returns early if you've reached your limits or already processed this URL.
Fetch and parse the page content:
try:
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')Wrap the network request in a try-except block because web requests can fail for many reasons: network timeouts, server errors, or failed responses. Always handle these errors gracefully in production crawlers.
Extract the data you need from the current page:
# Extract books from current page
books = soup.find_all('article', class_='product_pod')
page_books = []
for book in books:
title_elem = book.find('h3')
if title_elem:
title_link = title_elem.find('a')
if title_link:
title = title_link.text.strip()
page_books.append(title)
all_books.extend(page_books)
print(f" Found {len(page_books)} books on this page")This uses the same book extraction logic you learned in Section 4, but now applies it to each page the crawler visits. The extend() method adds all books from the current page to your master list.
The trickiest part is finding the next page to crawl:
# Look for "next" button to find next page
next_link = soup.find('li', class_='next')
if next_link and depth < max_pages - 1:
next_url = next_link.find('a')['href']
full_next_url = urljoin(url, next_url)
time.sleep(1) # Be respectful to the server
crawl_page(full_next_url, depth + 1)The books.toscrape.com site uses pagination with "next" buttons. The find() method looks for the list item with class "next", which contains a link to the next page. The urljoin() function handles the relative URL correctly.
Web servers can only handle so many requests at once, and scraping too quickly can overwhelm them. This example uses time.sleep(1) to add a polite delay, but you may want to use longer ones depending on the site. Watch for signs that you're moving too fast: slower response times, timeout errors, or HTTP 429 "Too Many Requests" responses.
We also want to handle errors that might occur during crawling:
except Exception as e:
print(f" Error crawling {url}: {e}")Broad exception handling makes sure your crawler doesn't crash when it runs into problems. In production, you'd want more specific error handling for different types of failures.
Put it all together and it looks like this:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin, urlparse
import time
base_url = "https://books.toscrape.com/"
visited_urls = set()
all_books = []
max_pages = 3
def crawl_page(url, depth=0):
# Stop if we've hit our limit or already visited this page
if depth >= max_pages or url in visited_urls:
return
print(f"Crawling: {url}")
visited_urls.add(url)
try:
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# Extract books from current page
books = soup.find_all('article', class_='product_pod')
page_books = []
for book in books:
title_elem = book.find('h3')
if title_elem:
title_link = title_elem.find('a')
if title_link:
title = title_link.text.strip()
if title:
page_books.append(title)
all_books.extend(page_books)
print(f" Found {len(page_books)} books on this page")
# Look for "next" button to find next page
next_link = soup.find('li', class_='next')
if next_link and depth < max_pages - 1:
next_url = next_link.find('a')['href']
full_next_url = urljoin(url, next_url)
time.sleep(1) # Be respectful to the server
crawl_page(full_next_url, depth + 1)
except Exception as e:
print(f" Error crawling {url}: {e}")Now, you can run the crawler:
# Start the crawling process
crawl_page(base_url)
print(f"\nTraditional crawling results:")
print(f"Pages visited: {len(visited_urls)}")
print(f"Total books found: {len(all_books)}")
print(f"Sample books:")
for i, book in enumerate(all_books[:3]):
print(f" {i+1}. {book}")When you run this complete crawler, you'll see output like:
Crawling: https://books.toscrape.com/
Found 20 books on this page
Crawling: https://books.toscrape.com/catalogue/page-2.html
Found 20 books on this page
Crawling: https://books.toscrape.com/catalogue/page-3.html
Found 20 books on this page
Traditional crawling results:
Pages visited: 3
Total books found: 60
Sample books:
1. A Light in the Attic
2. Tipping the Velvet
3. SoumissionThis traditional approach works but requires a lot of complexity. You need to understand URL handling, implement recursive logic, manage state across function calls, and handle various edge cases. The code is fragile and breaks easily when websites change their structure.
Modern approach: using Firecrawl's crawl endpoint
Modern crawling APIs eliminate most of this complexity by handling URL discovery, pagination, and content extraction automatically. With Firecrawl, the entire crawling process becomes a single API call.
Set up the modern approach:
from firecrawl import Firecrawl
app = Firecrawl()The setup is identical to what you learned in previous sections. One import, one initialization, and you're ready to crawl entire websites. Crawl the entire website with a single method call:
result = app.crawl(
url="https://books.toscrape.com/",
limit=50,
scrape_options={
"formats": ["markdown"],
"include_tags": ["h3", ".price_color", ".star-rating"]
}
)The crawl() method automatically discovers all pages on the site by analyzing the sitemap, following links, and handling pagination. The limit parameter controls how many pages to process. The scrape_options parameter uses the same configuration you learned in Section 7, but now applies to every page discovered.
Display your results:
print(f"Modern crawling results:")
print(f"Crawled {result.total} pages")
print(f"Found {len(result.data)} documents")
print(f"Sample page titles:")
for i, doc in enumerate(result.data[:3]):
print(f" {i+1}. {doc.metadata.title}")Expected output:
Modern crawling results:
Crawled 50 pages
Found 50 documents
Sample page titles:
1. All products | Books to Scrape - Sandbox
2. Catalogue | Page 2 | Books to Scrape - Sandbox
3. Catalogue | Page 3 | Books to Scrape - SandboxThe results object contains metadata about the crawling process and a data list with content from every discovered page. Each document includes the same structured information you've seen in previous sections: markdown content, metadata, and any other formats you requested.
Building a complete competitor product catalog
Let's put these concepts together in a practical project: building a competitor analysis system that tracks product information across an entire e-commerce site. This example shows how crawling makes large-scale data collection projects possible. Define the data structure for your product catalog:
from pydantic import BaseModel, Field
from typing import List, Optional
class Product(BaseModel):
title: str = Field(description="The product name")
price: str = Field(description="The product price")
rating: Optional[str] = Field(description="The product rating")
availability: Optional[str] = Field(description="Stock status")
url: str = Field(description="The product page URL")
class ProductCatalog(BaseModel):
products: List[Product] = Field(description="List of all products found")
total_pages: int = Field(description="Number of pages crawled")
catalog_date: str = Field(description="When this catalog was created")The Pydantic models define exactly what information you want to extract from each product page. The Optional type hint means some fields might be missing on certain pages, and that's acceptable.
Use Firecrawl to build your complete catalog:
from datetime import datetime
# Crawl the entire site with structured extraction
catalog_result = app.crawl(
url="https://books.toscrape.com/",
limit=100, # Adjust based on site size
scrape_options={
"formats": [
{
"type": "json",
"schema": Product,
"prompt": "Extract product information including title, price, rating, and availability status"
}
]
}
)
# Process the results into a structured catalog
products = []
for doc in catalog_result.data:
if hasattr(doc, 'json') and doc.json:
products.append(doc.json)
# Create the final catalog
catalog = ProductCatalog(
products=products,
total_pages=catalog_result.total,
catalog_date=datetime.now().isoformat()
)
print(f"Catalog complete!")
print(f"Products found: {len(catalog.products)}")
print(f"Pages processed: {catalog.total_pages}")
print(f"Created: {catalog.catalog_date}")This approach scales to websites of any size. Whether you're analyzing 50 products or 50,000, the code remains the same. The crawling engine handles pagination, discovers product pages automatically, and returns structured data ready for analysis.
The modern approach turns website crawling from a complex programming task into a simple data collection job. Instead of building crawling infrastructure, you focus on defining what data you need and how to use it. This shift from "how to crawl" to "what to collect" makes large-scale web data projects accessible to anyone who can write basic Python code.
Organizing and saving your data
You've learned how to scrape data from single pages and entire websites, but that data disappears when your script finishes running. Real projects require saving your scraped data for later analysis, sharing with others, or building applications. This section shows you practical ways to store your scraped data using common formats and tools.
The books data you scraped in Section 8 provides a perfect example. Instead of just printing results to the screen, you'll learn to save them as CSV files for spreadsheet analysis, JSON files for web applications, and databases for more complex queries.
Saving to CSV files
CSV (Comma-Separated Values) files work with any spreadsheet program and are the simplest way to store structured data. Let's save your book collection data:
import csv
from datetime import datetime
# Sample data from your Section 8 crawler
books_data = [
{'title': 'A Light in the Attic', 'price': '£51.77', 'rating': 'Three'},
{'title': 'Tipping the Velvet', 'price': '£53.74', 'rating': 'One'},
{'title': 'Soumission', 'price': '£50.10', 'rating': 'One'}
]
# Save to CSV
filename = f"books_{datetime.now().strftime('%Y%m%d_%H%M%S')}.csv"
with open(filename, 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['title', 'price', 'rating']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for book in books_data:
writer.writerow(book)
print(f"Saved {len(books_data)} books to {filename}")The csv.DictWriter class handles CSV formatting by mapping dictionary keys to column headers. The newline='' parameter prevents extra blank lines on Windows systems, and encoding='utf-8' ensures special characters display correctly across different programs.
Output:
Saved 3 books to books_20241118_143022.csvWorking with JSON files
JSON files preserve data structure better than CSV and work smoothly with web applications:
import json
# Save structured data with metadata
catalog_data = {
'scrape_date': datetime.now().isoformat(),
'total_books': len(books_data),
'source_url': 'https://books.toscrape.com/',
'books': books_data
}
# Save to JSON with pretty formatting
with open('book_catalog.json', 'w', encoding='utf-8') as jsonfile:
json.dump(catalog_data, jsonfile, indent=2, ensure_ascii=False)
print("Saved catalog to book_catalog.json")
# Load it back to verify
with open('book_catalog.json', 'r', encoding='utf-8') as jsonfile:
loaded_data = json.load(jsonfile)
print(f"Loaded catalog with {loaded_data['total_books']} books")The indent=2 parameter makes the JSON human-readable with formatting, while ensure_ascii=False preserves Unicode characters like pound signs rather than converting them to escape sequences.
Output:
Saved catalog to book_catalog.json
Loaded catalog with 3 booksQuick data cleaning with Pandas
Before saving data, you often need to clean it. Pandas makes this straightforward:
import pandas as pd
# Create DataFrame from scraped data
df = pd.DataFrame(books_data)
# Clean price column: remove £ symbol and convert to float
df['price_numeric'] = df['price'].str.replace('£', '').astype(float)
# Convert rating words to numbers
rating_map = {'One': 1, 'Two': 2, 'Three': 3, 'Four': 4, 'Five': 5}
df['rating_numeric'] = df['rating'].map(rating_map)
# Add useful analysis
df['price_category'] = pd.cut(df['price_numeric'],
bins=[0, 30, 50, 100],
labels=['Cheap', 'Medium', 'Expensive'])
print("Cleaned data:")
print(df[['title', 'price_numeric', 'rating_numeric', 'price_category']])
# Save cleaned data
df.to_csv('books_cleaned.csv', index=False)The .str.replace() method works on text columns to remove unwanted characters before converting to numeric types. The pd.cut() function creates categories from numeric data by defining bins and labels, useful for price range analysis. The index=False parameter prevents pandas from writing row numbers to your CSV file.
Output:
Cleaned data:
title price_numeric rating_numeric price_category
0 A Light in the Attic 51.77 3 Expensive
1 Tipping the Velvet 53.74 1 Expensive
2 Soumission 50.10 1 MediumBuilding a simple price tracking database
For projects that track data over time, SQLite provides a lightweight database solution. For a full walkthrough of automated price tracking with Python, including scheduled runs and alerts, see the dedicated tutorial. Start by setting up the database connection and table structure:
import sqlite3
# Create database and table
conn = sqlite3.connect('book_prices.db')
cursor = conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS books (
id INTEGER PRIMARY KEY,
title TEXT NOT NULL,
price REAL,
rating INTEGER,
scraped_date DATE,
url TEXT
)
''')The CREATE TABLE IF NOT EXISTS statement creates your table structure only if it doesn't already exist, preventing errors when you run the script multiple times. The table design includes an auto-incrementing ID, required title field, and date tracking for price history.
Now insert your book data with proper data type conversion:
# Insert book data with current timestamp
for book in books_data:
cursor.execute('''
INSERT INTO books (title, price, rating, scraped_date, url)
VALUES (?, ?, ?, ?, ?)
''', (
book['title'],
float(book['price'].replace('£', '')),
rating_map.get(book['rating'], 0),
datetime.now().date(),
'https://books.toscrape.com/'
))
conn.commit()The parameterized query with ? placeholders prevents SQL injection attacks by safely inserting data. The .get() method provides a default rating of 0 if a rating isn't found in the mapping. The conn.commit() call saves your changes permanently.
Query and display your stored data:
# Query the data
cursor.execute('SELECT title, price, rating FROM books ORDER BY price DESC')
results = cursor.fetchall()
print("Books in database (by price):")
for title, price, rating in results:
print(f"- {title}: £{price:.2f} ({rating} stars)")
conn.close()Output:
Books in database (by price):
- Tipping the Velvet: £53.74 (1 stars)
- A Light in the Attic: £51.77 (3 stars)
- Soumission: £50.10 (1 stars)This database structure lets you track price changes over time, analyze trends, and build more sophisticated applications on top of your scraped data.
These storage methods give you the foundation for any web scraping project. Choose CSV for simple analysis, JSON for web applications, and SQLite for projects requiring queries and relationships. The key is picking the right tool for your specific use case and data requirements.
What's Next?
You've built a complete foundation in web scraping, from your first single-page scraper to full-site crawling systems. You've learned both traditional tools like requests and BeautifulSoup for static sites, and modern APIs like Firecrawl for JavaScript-heavy websites. You can now extract structured data, organize it in databases, and choose the right approach for any scraping project.
Checkout How to Build a Web Scraping Agent With LangGraph and Firecrawl**. If you prefer to work in a different language, we also have dedicated guides for PHP web scraping and JavaScript web scraping.
Your scraping toolkit now includes:
- Basic extraction: HTML parsing, CSS selectors, and data extraction
- Scaling techniques: Multi-page crawling and automated site discovery
- Modern solutions: API-based scraping for complex sites
- Data management: CSV, JSON, and database storage with cleaning workflows
- Structured extraction: Schema-based data collection for consistent results
Web scraping continues developing new challenges and solutions. When you need advanced features like visual site mapping, AI-powered data extraction, or enterprise-scale crawling, explore Firecrawl's additional endpoints and capabilities. For continued learning, join web scraping communities, experiment with different websites, and always scrape responsibly. Whether you build your own tools or use modern APIs, you now have the knowledge to turn most websites into actionable data for your projects.
Frequently Asked Questions
How do you scrape a web page in Python?
For static sites where all content appears in the initial HTML, use the requests library to fetch pages and BeautifulSoup to parse the HTML. For websites that load content with JavaScript, tools like Firecrawl handle the browser automation and wait for dynamic content to load. Start with requests and BeautifulSoup for simple sites, then move to browser-based tools or managed APIs when you encounter pages that appear empty despite showing content in your browser.
What's the difference between web scraping and web crawling?
Web scraping extracts data from individual pages, while web crawling discovers and visits multiple pages across a site. Scraping focuses on collecting specific information from known pages. Crawling focuses on finding all relevant pages by following links automatically. Large projects typically combine both: crawling to discover pages, then scraping to extract data from each one.
What Python libraries do I need to start web scraping?
For most beginner projects, you only need two libraries: requests (to download HTML pages) and BeautifulSoup4 (to parse and search through the HTML). Install them with pip install requests beautifulsoup4. If you need to scrape sites that require JavaScript rendering, consider the Firecrawl Python SDK (pip install firecrawl-py), which handles JS execution in the cloud without any browser setup on your machine.
How do I handle JavaScript-rendered websites?
Many modern websites load content dynamically with JavaScript, so a plain HTTP request returns an empty HTML shell. The options are: use a headless browser like Playwright or Puppeteer to execute the JavaScript locally, or use a managed service like Firecrawl that handles browser automation in the cloud and returns fully rendered, clean content via a simple API call. For most beginners, Firecrawl is the easier path since it requires no browser installation or configuration.
What are CSS selectors and how do I use them for scraping?
CSS selectors are patterns used to identify HTML elements by tag, class, ID, or attributes. For example, div.price targets a div with class 'price', and #main-title targets an element with ID 'main-title'. In BeautifulSoup, you use them with soup.select('div.price') to get a list of matching elements. You can find the right selector by right-clicking an element in your browser's DevTools and inspecting its HTML structure.
What is the best way to store scraped data?
Choose based on how you plan to use the data. CSV is the simplest option for spreadsheet analysis and sharing with non-technical teammates. JSON preserves nested structures and works well for web applications or feeding data into other APIs. SQLite is best for larger datasets where you need to query, filter, and track changes over time. For most beginner projects, start with CSV or JSON using Python's built-in csv and json modules.
What is Firecrawl and when should I use it?
Firecrawl is the context API to search, scrape, and interact with the web at scale, handling JavaScript rendering, browser automation, and large-scale crawling in the cloud. You send it a URL and it returns clean, structured content. Use it when: the site requires JavaScript to render content, you need to crawl an entire website rather than individual pages, or you want to extract structured data using an AI-powered schema instead of writing CSS selectors. It has a free tier and a Python SDK (pip install firecrawl-py).
How do I scrape multiple pages or an entire website?
For a known list of pages, loop through the URLs and scrape each one with a small delay. For discovering all pages on a site, you need a crawler: start from the homepage, find all internal links, and add them to a queue. With Firecrawl, you can crawl an entire site with a single app.crawl_url() call that handles link discovery, queuing, and parallel fetching automatically. With BeautifulSoup, find all anchor tags using soup.find_all('a') and filter for internal links.
