
TL;DR;
- One call to
/scrapereturns any URL as clean markdown, HTML, links, screenshots, summaries, images, structured JSON, brand profiles, or extracted audio. - The basics: 1 credit per scrape, +4 for JSON extraction, +4 for enhanced proxy, +4 for audio, +1 per PDF page. Cached results still cost 1.
- Pull structured data either by prompt alone (fast, field names drift) or by passing a Pydantic schema (locked field names, parseable downstream). The article walks through both against Hacker News.
- Specialised formats covered end-to-end: brand profile extraction, audio extraction from YouTube via REST, screenshots with
fullPage, and PDF parsing. - Scale up with
batch_scrape()(sync) orstart_batch_scrape()(async) when you have hundreds or thousands of URLs. - Drive interactive pages with
actions: click, type, wait, screenshot. Worked example logs into a test site and grabs the post-login screenshot inline. - Reach
/scrapefrom the Python or Node SDK, the REST API, the CLI, or an MCP client like Claude Desktop or Cursor.
How do you get started with modern web scraping?
Web scraping has gotten harder. Pages render through JavaScript, throttle automated traffic, and serve different markup depending on the user's region. Even when you do get the HTML, it's rarely the shape you wanted, which means most projects bolt on a cleanup pipeline to reach clean text, a structured record, a transcript, or a screenshot. AI scraping tools have started collapsing those steps into a single API call, and Firecrawl is one of them — a complete web data API built for agents and AI developers, covering search, scrape, crawl, and browser interaction in one platform.
Firecrawl's /scrape endpoint takes a URL and returns whatever shape you ask for: markdown, HTML, schema-guided JSON, a brand profile, audio extracted from a YouTube link, a screenshot. Same call, different formats. Rendering and proxy rotation happen on the server side.
This article works through the endpoint end to end: formats, parameters, costs, structured extraction with prompts and schemas against real Hacker News pages, batch operations, and actions for interactive pages.
What is Firecrawl's /scrape endpoint?
Turn any URL into clean data with Firecrawl's /scrape endpoint. It converts pages into LLM-ready markdown while handling the hard parts like proxies, caching, rate limits, and JavaScript-rendered content. It renders the page in a real browser, runs whatever the formats specify, and returns the result in one response. That's the whole interface.
Two things make that interface useful. The fetch happens in a real browser, so anything a normal user's browser would handle (JavaScript-rendered content, redirects, login flows) is already taken care of by the time you get a response. And the response itself is shaped by your formats argument, so the same scrape can give you clean markdown for an LLM, a screenshot of the rendered page, a JSON record extracted by a model, or an MP3 ripped from a video link.
The rest of the article walks through the endpoint parameter by parameter, with code you can run as you read.
Ways to use Firecrawl scrape
You don't need to write a Python script to scrape a page. The same /scrape endpoint has four different ways to call it, so you can pick whichever one fits your context.
The most direct option is the REST API. Call it from any HTTP client and you get back the same JSON the SDKs return internally. That makes it a good fit for ad-hoc tests, languages without a Firecrawl SDK, and shell scripts. Audio extraction is currently REST-only.
curl -X POST https://api.firecrawl.dev/v2/scrape \
-H "Authorization: Bearer $FIRECRAWL_API_KEY" \
-H "Content-Type: application/json" \
-d '{"url": "https://example.com", "formats": ["markdown"]}'For application code, the Python and Node SDKs wrap that same call with typed responses and helpers for the format objects. The rest of this article uses the Python SDK because it reads cleanly in tutorials.
pip install firecrawl-py
# or
npm install firecrawlIf you live inside an MCP-compatible client like Claude Desktop or Cursor, you can plug in the Firecrawl MCP server and let the model call firecrawl_scrape directly from a chat. No code on your end. See the Firecrawl MCP docs.
The fourth option is the Firecrawl CLI, which is handy for quick captures, shell scripting, or dropping a scrape into a CI step. See the CLI docs.
npm install -g firecrawl-cli
firecrawl scrape https://example.comIf you want a quick CLI walkthrough, watch this:
The rest of this article focuses on the Python SDK, but the parameters and response shapes are the same across all four entry points.
Prerequisites: setting up Firecrawl
Firecrawl's scraping engine is exposed as a REST API, so you can use command-line tools like cURL to use it. However, for a more comfortable experience, better flexibility and control, I recommend using one of its SDKs for Python, Node, Rust or Go. This tutorial will focus on the Python version. If you're interested in building complete AI applications with scraped data, check out our guide on building full-stack AI web apps.
To get started, please make sure to:
- Sign up at firecrawl.dev.
- Choose a plan (the free one will work fine for this tutorial).
Once you sign up, you'll get an API token. Copy it from your dashboard and save it in a .env file:
touch .env
echo "FIRECRAWL_API_KEY='YOUR_API_KEY'" >> .envNow, let's install Firecrawl Python SDK, python-dotenv to read .env files, and Pandas for data analysis later:
pip install firecrawl-py python-dotenv pandasHow much does Firecrawl scrape costs
Before we dive into the code and make actual scrape calls, it is important to understand pricing of the endpoint. Every scrape starts at 1 credit. A few options increase it:
| Feature | Credit cost |
|---|---|
| Base scrape (any single format) | 1 |
JSON mode ({"type": "json", ...}) | +4 (5 total) |
Enhanced proxy (proxy="enhanced") | +4 (5 total) when actually used |
Auto proxy (proxy="auto") | 1 if basic succeeds, 5 if it falls back |
PDF parsing (parsers=["pdf"]) | +1 per PDF page |
Audio extraction (formats=["audio"], REST only) | +4 (5 total) |
ZDR (zeroDataRetention=True, Enterprise) | +1 per page |
Cached result (cache_state: "hit") | 1 (caching saves time, not credits) |
A few notes from running this in practice. Cached scrapes still cost the full 1 credit per page. Caching reduces latency, not the bill. Enhanced proxy only charges the +4 surcharge when Firecrawl actually invokes the enhanced backend. On simpler sites it falls back to basic and costs 1, and the proxy_used field in result.metadata reports which backend ran.
The cache is opt-in per call through the max_age parameter, in milliseconds. Pass it on a scrape and Firecrawl returns a cached copy if one was captured within that window. Otherwise it scrapes fresh and stores the new copy. The default is around two days. Common values: 0 forces a fresh scrape, 3600000 is a one-hour window for frequently-updated pages, 86400000 is a day. Whatever value you pass, result.metadata.cache_state reports back "hit" or "miss":
data = app.scrape("https://arxiv.org", formats=["markdown"], max_age=3600000)
print(data.metadata.cache_state)For security-sensitive workflows, Firecrawl also supports Lockdown Mode on /scrape. Pass lockdown=True to force cache-only behavior: Firecrawl serves from its existing index and does not fall back to a live fetch. If the URL is not in cache, the request returns a cache-miss error instead of scraping fresh content. This is useful when you need strict outbound-request controls and deterministic replay from indexed snapshots.
Basic scraping setup
Scraping with Firecrawl starts by creating an instance of the Firecrawl class:
from firecrawl import Firecrawl
from dotenv import load_dotenv
load_dotenv()
app = Firecrawl()When you use the load_dotenv() function, the app can automatically use your loaded API key to establish a connection with the scraping engine. Then, you can scrape any URL with the scrape() method:
url = "https://arxiv.org"
data = app.scrape(url, formats=["markdown"])Let's take a look at the response format returned by scrape method:
data.metadata{
"title": "arXiv.org e-Print archive",
"language": "en",
"source_url": "<https://arxiv.org>",
"url": "<https://arxiv.org/>",
"status_code": 200,
"content_type": "text/html; charset=utf-8",
"cache_state": "hit",
"credits_used": 1
}The response metadata includes comprehensive information like the page title, content type, cache status, and status code.
Now, let's look at the scraped contents, which is converted into markdown by default:
from IPython.display import Markdown
Markdown(data.markdown[:500])
arXiv is a free distribution service and an open-access archive for nearly 2.4 million
scholarly articles in the fields of physics, mathematics, computer science, quantitative biology, quantitative finance, statistics, electrical engineering and systems science, and economics.
Materials on this site are not peer-reviewed by arXiv.
Subject search and browse:
Physics
Mathematics
Quantitative Biology
Computer Science
Quantitative Finance
Statistics
Electrical Engineering and Systems SciencThe response can include several other formats that we can request when scraping a URL. Let's try requesting multiple formats at once to see what additional data we can get back:
data = app.scrape(
url,
formats=[
'html',
'rawHtml',
'links',
'screenshot',
'summary',
'images',
]
)Each format serves different purposes:
markdown: Clean Markdown of the main page content. Returned by default and ideal for LLM web scraping and RAG pipelines.html: Cleaned HTML with scripts and styles stripped, ready for DOM parsing.rawHtml: The unmodified HTML as received from the server, useful for archival and diffs.links: A flat list of every hyperlink on the page, good for SEO audits and crawl seeding.screenshot: A signed PNG URL of the rendered page. Accepts options likefullPage,quality, andviewport.summary: A short, AI-generated summary of the page (1 to 3 paragraphs), distinct from the full markdown.images: All image URLs found on the page, returned as a list of strings.json: Structured data extracted by an LLM from the page, driven by a prompt and an optional schema. Covered in its own section below.branding: A brand profile of the page (colors, fonts, button styles, personality). Covered in its own section below.audio: Extracts an MP3 from a supported video URL like YouTube. REST-only, covered in its own section below.question: Answers a specific question from the page content directly, returning a precise answer instead of the full document. Reduces token consumption by up to 100x compared to passing the full markdown. See the question and highlights format launch for benchmarks and implementation details.highlights: Returns the most relevant passages from the page for a given query, rather than the entire content. Useful for surfacing key evidence without processing the full document.
Choose rawHtml for archival or comparison tasks, links for SEO analysis, screenshot for visual documentation, summary when you only need a short overview, and images when you're cataloguing visual assets.
Passing more than one scraping format adds additional attributes to the response. The response is a Pydantic model, so dir() returns a long list with model internals mixed in. Filtering to the data-bearing attributes makes it readable:
# Filter out pydantic internals to see only the data attributes
PYDANTIC_NOISE = (
"_", "model_", "parse_", "schema", "validate",
"from_", "construct", "copy", "dict", "update_", "warning",
)
[a for a in dir(data) if not a.startswith(PYDANTIC_NOISE)]['actions', 'branding', 'change_tracking', 'html', 'images', 'json',
'links', 'markdown', 'metadata', 'metadata_dict', 'metadata_typed',
'raw_html', 'screenshot', 'summary']The attributes that actually hold scraped content are the ones whose names match the formats you requested. The rest (actions, branding, json) stay None until you ask for them, and metadata, metadata_dict, metadata_typed are always present alongside the page itself.
Two of those formats produce content the page doesn't carry as raw text: summary and screenshot. The summary format runs an LLM over the page and returns 1 to 3 paragraphs distilled from the body. Useful when you only need a quick overview:
data = app.scrape("https://techcrunch.com", formats=["markdown", "summary"])
print(f"Full markdown: {len(data.markdown)} chars")
print(f"Summary: {len(data.summary)} chars")
print()
print(data.summary)Full markdown: 39022 chars
Summary: 1127 chars
The TechCrunch page features several articles and updates in technology and business. Notable highlights include chatbot design choices that contribute to misconceptions about AI capabilities, coverage of a security flaw in TheTruthSpy that exposed sensitive user data, and analysis of current venture capital and startup funding patterns.Roughly a 35x reduction with the main signals preserved. Useful for content monitoring or news aggregation, where downstream processing pays per token.
Let's display the screenshot Firecrawl took of arXiv.org:
from IPython.display import Image
Image(data.screenshot)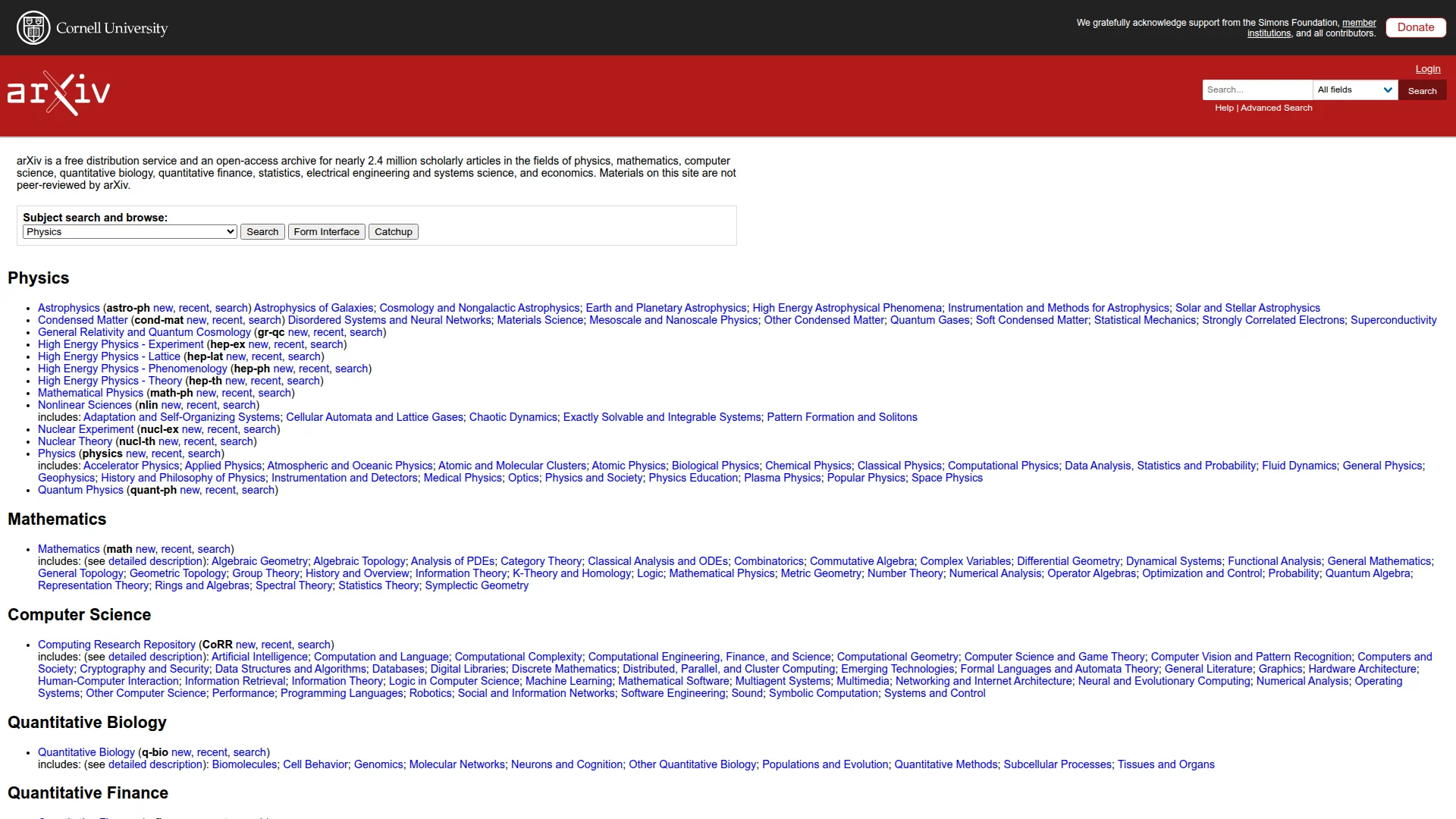
Notice how the screenshot is cropped to fit a certain viewport. For most pages, it's better to capture the entire screen by using the full page screenshot option:
data = app.scrape(
url,
formats=[
{"type": "screenshot", "fullPage": True},
]
)
Image(data.screenshot)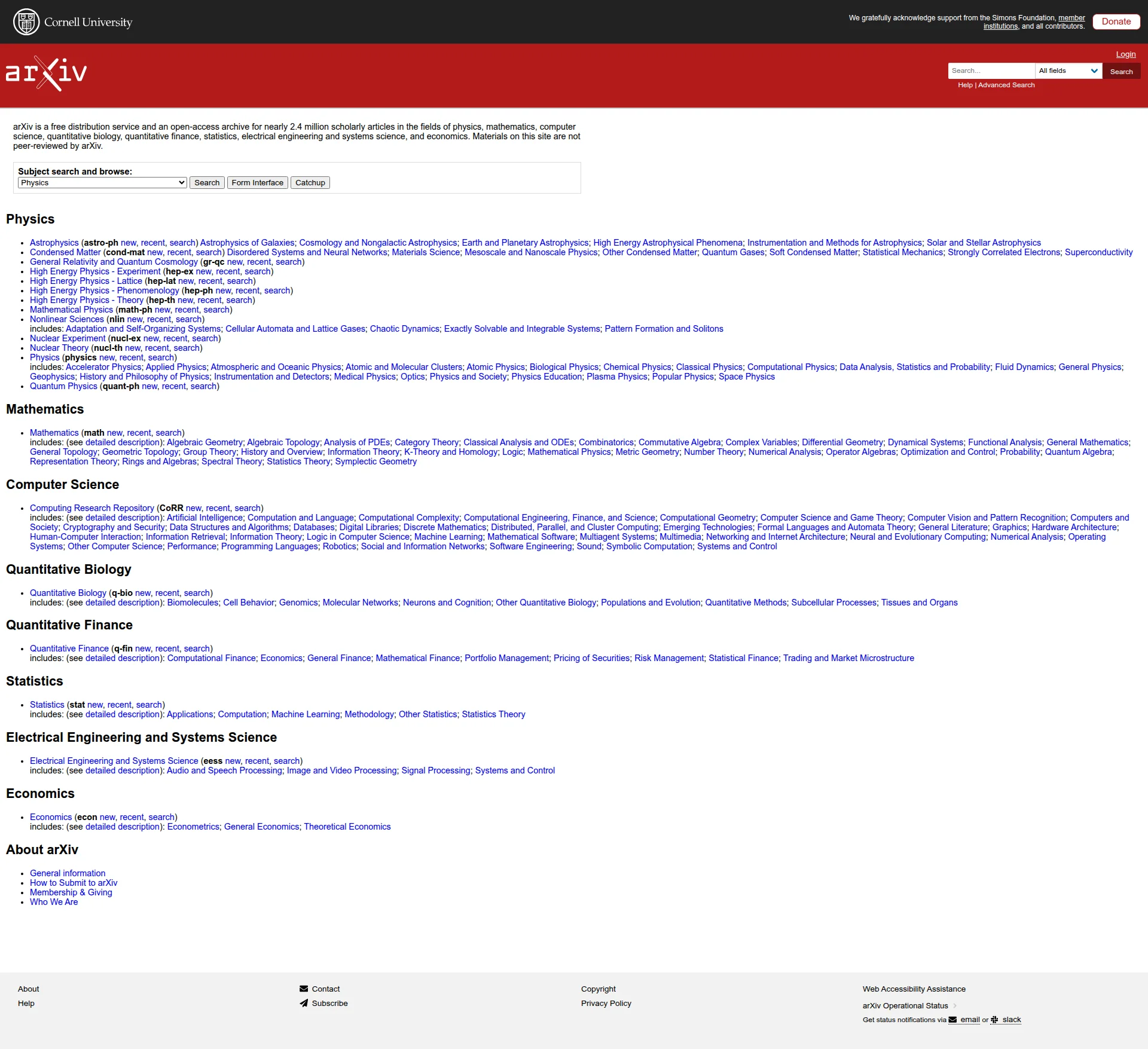
As a bonus, the /scrape endpoint can handle PDF parsing as well:
pdf_link = "https://arxiv.org/pdf/2411.09833.pdf"
data = app.scrape(pdf_link, formats=["markdown"], parsers=["pdf"])
Markdown(data.markdown[:500])arXiv:2411.09833v1 \[math.DG\] 14 Nov 2024
EINSTEIN METRICS ON THE FULL FLAG F(N).
MIKHAIL R. GUZMAN
Abstract.LetM=G/Kbe a full flag manifold. In this work, we investigate theG-
stability of Einstein metrics onMand analyze their stability types, including coindices,
for several cases. We specifically focus onF(n) = SU(n)/T, emphasizingn= 5, where
we identify four new Einstein metrics in addition to known ones. Stability data, including
coindex and Hessian spectrum, confirms that these metrics onOther scrape parameters
By default, scrape() converts everything it sees on a webpage to one of the specified formats. A handful of extra parameters change what gets scraped and how:
only_main_contentexcludes navigation, footers, and headers. On by default.include_tagsandexclude_tagswhitelist or blacklist HTML elements by tag,#id, or.class-name.proxypicks the proxy backend Firecrawl uses to fetch the page.locationmakes the request appear to originate from a chosen country.lockdownenforces cache-only scraping for sensitive workloads.
The first three are the ones you'll reach for most often. Here's include_tags and exclude_tags in action against arXiv, keeping only paragraph elements and dropping spans:
url = "https://arxiv.org"
data = app.scrape(url, formats=["markdown"], include_tags=["p"], exclude_tags=["span"])
Markdown(data.markdown[:1000])[Help](https://info.arxiv.org/help) \| [Advanced Search](https://arxiv.org/search/advanced)
arXiv is a free distribution service and an open-access archive for nearly 2.4 million
scholarly articles in the fields of physics, mathematics, computer science, quantitative biology, quantitative finance, statistics, electrical engineering and systems science, and economics.
Materials on this site are not peer-reviewed by arXiv.
[arXiv Operational Status](https://status.arxiv.org)
Get status notifications via
[email](https://subscribe.sorryapp.com/24846f03/email/new)
or [slack](https://subscribe.sorryapp.com/24846f03/slack/new)only_main_content and the tag filters are about narrowing what comes back from a page that loaded fine. The next two parameters address pages that don't load fine in the first place.
The proxy parameter has three modes. basic (default) is the cheapest and works on most sites. enhanced is a stronger backend for harder-to-reach sites. auto runs basic first and falls back to enhanced only if that fails. You only pay the upgrade cost when you actually need it. Credit costs for each are in the table near the top of the article.
data = app.scrape("https://www.g2.com/products/notion/reviews", proxy="auto")
print(data.metadata.proxy_used)The proxy_used field on data.metadata reports which backend ended up running, which matters with auto because that's where the credit count comes from.
The location parameter controls request geography. Pass a country code (and optionally a language list) and Firecrawl routes the request through that region. A search results page or a localised landing page then returns the version a user there would see.
data = app.scrape(
"https://www.google.com/search?q=pizza+delivery",
location={"country": "DE", "languages": ["de"]},
)The same URL scraped without location would return a US-localised result set. With Germany set, you get the German one. Use it for monitoring regional search results, checking geo-targeted pricing, or testing localisation.
Structured data extraction with the JSON format
The json format runs an LLM over the page and returns a structured dict. The examples below assume you already have a URL. If you need to find relevant pages first — by keyword, topic, or question — Firecrawl's /search endpoint returns full page content alongside search results, so you can search and extract in one step rather than two. There are two ways to call the json format:
- Prompt only. Pass a
promptand let the LLM choose the JSON shape. Fastest to write, output structure can drift between runs. - Prompt with schema. Pass a Pydantic model alongside the prompt. The output is guaranteed to match your model's field names and types.
Both forms cost the same: 5 credits per scrape (1 base + 4 for JSON mode). The difference is determinism, not price. Use the prompt-only form for prototyping and one-off pulls. Reach for a schema as soon as you need to parse the output programmatically.
Prompt-only (no schema)
To illustrate natural language scraping, let's pull the top stories off the Hacker News front page:
url = "https://news.ycombinator.com"
data = app.scrape(
url,
formats=[
"markdown",
"screenshot",
{
"type": "json",
"prompt": "Extract the top 3 stories on the page. For each story, include its title, the URL it links to, the points score, and the author who submitted it.",
},
],
)To turn on JSON extraction, you include an object in the formats array with type: "json" and a prompt that describes what to pull out.
Once scraping finishes, the response will include a new json attribute:
data.json{
"stories": [
{
"title": "BYOMesh – New LoRa mesh radio offers 100x the bandwidth",
"url": "https://partyon.xyz/@nullagent/116499715071759135",
"points": 209,
"author": "nullagent"
},
{
"title": "DeepClaude – Claude Code agent loop with DeepSeek V4 Pro, 17x cheaper",
"url": "https://github.com/aattaran/deepclaude",
"points": 25,
"author": "alattaran"
},
{
"title": "Southwest Headquarters Tour",
"url": "https://katherinemichel.github.io/blog/travel/southwest-headquarters-tour-2026.html",
"points": 163,
"author": "KatiMichel"
}
]
}The LLM picked the field names on its own. We asked for "title, URL, points, author" and it wrapped the entries in a stories list with those exact keys. That's the appeal of prompt-only mode: it's fast and you don't have to define anything upfront.
The cost of that convenience is determinism. Field names and the wrapping structure can drift between runs. The next call might give you top_stories instead of stories, or link instead of url, and the data extraction in your pipeline will quietly break. Prompt-only is fine for exploring. As soon as anything downstream parses these keys, you want a schema.
Prompt with schema
Prompt-only is fine for exploration, but production code needs an output you can parse with confidence. Two runs of the same prompt can return {"title": ...} one time and {"main_title": ...} the next, which breaks anything downstream.
The fix is to pass a Pydantic model along with your prompt. Firecrawl will guide the LLM to fill in your model's fields exactly, so field names and types stay stable across runs.
Sticking with Hacker News, let's say we want each story back as a richer "article" record with title, subtitle, URL, author, date, an estimated read duration, and a topic list. A schema declares those fields up front so every run produces the same shape:
from pydantic import BaseModel, Field
class IndividualArticle(BaseModel):
title: str = Field(description="The title of the news article")
subtitle: str = Field(description="The subtitle of the news article")
url: str = Field(description="The URL of the news article")
author: str = Field(description="The author of the news article")
date: str = Field(description="The date the news article was published")
read_duration: int = Field(description="The estimated time it takes to read the news article")
topics: list[str] = Field(description="A list of topics the news article is about")
class NewsArticlesSchema(BaseModel):
news_articles: list[IndividualArticle] = Field(
description="A list of news articles extracted from the page"
)Two models, one nested in the other. IndividualArticle defines the shape of a single record. NewsArticlesSchema wraps a list of them. The wrapper matters: without a list field, Firecrawl returns only the first match it finds. The Field(description=...) strings aren't decorative either, they're prompts the LLM reads while filling each field.
The next step is passing this schema to the formats parameter of scrape():
url = "https://news.ycombinator.com"
structured_data = app.scrape(
url,
formats=[
"screenshot",
{
"type": "json",
"schema": NewsArticlesSchema,
"prompt": "Extract the top 5 stories on the Hacker News front page as news articles. For author, use the submitting username. For date, use the relative time string shown on the page. For read_duration, estimate based on title complexity (default to 1 if unsure). For topics, infer 1-3 short tags from the title.",
}
]
)The schema goes through as the model class directly, no JSON dict conversion needed. The prompt then steers the LLM on how to fill the fields the schema describes. Here's the output:
structured_data.json{
"news_articles": [
{
"title": "BYOMesh – New LoRa mesh radio offers 100x the bandwidth",
"subtitle": "partyon.xyz",
"url": "https://partyon.xyz/@nullagent/116499715071759135",
"author": "nullagent",
"date": "5 hours ago",
"read_duration": 1,
"topics": ["LoRa", "Technology", "Bandwidth"]
},
{
"title": "DeepClaude – Claude Code agent loop with DeepSeek V4 Pro, 17x cheaper",
"subtitle": "github.com/aattaran",
"url": "https://github.com/aattaran/deepclaude",
"author": "alattaran",
"date": "1 hour ago",
"read_duration": 1,
"topics": ["DeepLearning", "CodeAgent", "CostReduction"]
},
{
"title": "Southwest Headquarters Tour",
"subtitle": "katherinemichel.github.io",
"url": "https://katherinemichel.github.io/blog/travel/southwest-headquarters-tour-2026.html",
"author": "KatiMichel",
"date": "6 hours ago",
"read_duration": 1,
"topics": ["Travel", "Tourism", "Southwest"]
},
{
"title": "US–Indian space mission maps extreme subsidence in Mexico City",
"subtitle": "phys.org",
"url": "https://phys.org/news/2026-04-usindian-space-mission-extreme-subsidence.html",
"author": "leopoldj",
"date": "5 hours ago",
"read_duration": 1,
"topics": ["Space", "Geography", "Mexico"]
},
{
"title": "OpenAI's o1 correctly diagnosed 67% of ER patients vs. 50-55% by triage doctors",
"subtitle": "theguardian.com",
"url": "https://www.theguardian.com/technology/2026/apr/30/ai-outperforms-doctors-in-harvard-trial-of-emergency-triage-diagnoses",
"author": "donsupreme",
"date": "8 hours ago",
"read_duration": 1,
"topics": ["OpenAI", "Healthcare", "AI"]
}
]
}The shape matches the schema exactly. Every entry has the seven fields we declared, in the order we declared them, and the wrapping news_articles key is the one we asked for. Run it again tomorrow and the stories will be different, but the keys and types stay identical, which is what you need for parsing downstream.
A few of the values are inferred rather than read from the page. Hacker News stories don't carry subtitles, so the LLM filled subtitle with the source domain. There's no real read duration on a link aggregator either, so we told it to default to 1. Schema-locked extraction guarantees the output shape. The prompt's job is to ground each field, and decide which ones to fake when the page doesn't have the data.
Brand profile extraction with the branding format
The branding format treats a webpage as a design artifact. One scrape returns the site's color palette, font stacks, button styles, spacing tokens, and a few notes on its visual personality. It costs 1 credit, the same as a basic scrape.
result = app.scrape("https://firecrawl.dev", formats=["branding"])
b = result.brandingThe result.branding attribute is a BrandingProfile Pydantic model. Here is what comes back for firecrawl.dev, trimmed for readability:
{
"color_scheme": "light",
"fonts": [
{"family": "Suisse", "role": "body"}
],
"colors": {
"primary": "#FF4C00",
"secondary": "#E56565",
"accent": "#FF4C00",
"background": "#F9F9F9",
"textPrimary": "#262626",
"link": "#FF4D00"
},
"typography": {
"fontFamilies": {"primary": "Suisse", "heading": "Suisse"},
"fontSizes": {"h1": "60px", "h2": "52px", "body": "16px"}
},
"spacing": {"baseUnit": 4, "borderRadius": "4px"},
"components": {
"buttonPrimary": {
"background": "#FF4C00",
"textColor": "#FFFFFF",
"borderRadius": "10px"
},
"buttonSecondary": {
"background": "#EFEFEF",
"textColor": "#262626",
"borderRadius": "10px"
}
},
"images": {
"logo": "data:image/svg+xml;utf8,...",
"favicon": "https://www.firecrawl.dev/favicon.png",
"ogImage": "https://www.firecrawl.dev/og.png"
},
"personality": {
"tone": "modern",
"energy": "high",
"targetAudience": "developers and tech-savvy users"
}
}Access fields like any other Pydantic model:
print(b.colors["primary"]) # "#FF4C00"
print(b.typography["fontSizes"]["h1"]) # "60px"
print(b.personality["tone"]) # "modern"One implementation note: images.logo is returned as an inline SVG data URI, not a remote URL. favicon and ogImage are regular URLs.
A few practical use cases for this format:
- Design system extraction. Pull a competitor's color palette and type scale, drop them into a Tailwind config, and you have a starting design system in minutes.
- Brand monitoring. Re-run the scrape on a schedule and diff the JSON to catch rebrands, color updates, or logo swaps before anyone announces them.
- Competitive design analysis. Scrape every site in a market segment in one batch, then aggregate the results into a single sheet of palettes, fonts, and personalities.
Audio extraction with the audio format
The audio format pulls an MP3 from a supported video URL like YouTube. It is the cheapest entry point to a transcription pipeline: one HTTP call returns a downloadable audio file you can pipe into Whisper, Deepgram, or any other speech-to-text service.
Use it the same way as any other format — pass "audio" in the formats list and read doc.audio from the response:
from firecrawl import Firecrawl
app = Firecrawl()
doc = app.scrape("https://www.youtube.com/watch?v=dQw4w9WgXcQ", formats=["audio"])
print(doc.audio)The doc.audio attribute is a signed Google Cloud Storage URL pointing to an MP3:
https://storage.googleapis.com/firecrawl-av-content/youtube-dQw4w9WgXcQ.mp3?
X-Goog-Algorithm=GOOG4-RSA-SHA256
&X-Goog-Expires=3600
&X-Goog-Signature=...Two things to remember about that URL:
- It expires in 1 hour. The
X-Goog-Expires=3600query parameter is non-negotiable. Download the MP3 to your own storage as soon as you have the URL if you need it longer. - Audio costs 5 credits. That is 1 credit for the base scrape plus 4 for the audio extraction.
A typical end-to-end flow: scrape the YouTube URL with formats=["audio"], save the returned MP3 to S3 or local disk before the URL expires, then hand the file off to a transcription model. From there, the markdown transcript can feed a summary, a search index, or a downstream agent.
Large-scale scraping with batch operations
Up to this point, we have been focusing on scraping pages one URL at a time. In reality, you will work with multiple, perhaps, thousands of URLs that need to be scraped in parallel. This is where batch operations become essential for efficient web scraping at scale. Batch operations allow you to process multiple URLs simultaneously, significantly reducing the overall time needed to collect data from multiple web pages. If your goal is scraping thousands of pages to clean markdown for a training dataset or knowledge base, this is the right approach.
Batch scraping with batch_scrape
The batch_scrape method lets you scrape multiple URLs at once.
Let's scrape multiple URLs using batch operations.
# Use example URLs for demonstration
article_links = ["https://example.com", "https://httpbin.org/html"]
class ArticleSummary(BaseModel):
title: str = Field(description="The title of the news article")
summary: str = Field(description="A short summary of the news article")
batch_data = app.batch_scrape(article_links, formats=[
{
"type": "json",
"schema": ArticleSummary,
"prompt": "Extract the title of the news article and generate its brief summary"
}
])Here is what is happening in the codeblock above:
- We define a list of example URLs to demonstrate batch processing
- We create an
ArticleSummarymodel with title and summary fields to structure our output - We use
batch_scrape()to process all URLs in parallel, configuring it to:- Extract data in structured format
- Use our
ArticleSummaryschema - Generate titles and summaries based on the page content
The response from batch_scrape() is a bit different:
# Check the batch response attributes
dir(batch_data)['completed', 'credits_used', 'data', 'expires_at', 'next', 'status', 'total']It contains the following key fields:
status: Current status of the batch job ('completed','scraping','failed', etc.)completed: Number of URLs processed so fartotal: Total number of URLs in the batchcredits_used: Number of API credits consumedexpires_at: A timestamp 24 hours from submission. After this point, Firecrawl drops the cached results and you'll need to re-run the batch.data: The extracted data for each URLnext: URL for pagination if more results are available
Let's focus on the data attribute where the actual content is stored:
len(batch_data.data)
2The batch processing completed successfully with 2 documents. Let's examine the structure of the first document:
# Check the first document's type and content
first_doc = batch_data.data[0]
print(f"Document type: {type(first_doc)}")
print(f"Has JSON: {hasattr(first_doc, 'json')}")Document type: <class 'firecrawl.v2.types.Document'>
Has JSON: TrueThe response format here matches what we get from individual scrape() calls.
Let's print the generated JSON:
print(batch_data.data[0].json){'title': 'Example Domain', 'summary': 'This domain, example.com, is designated for use in documentation examples and can be utilized in literature without requiring prior permission.'}The scraping was performed according to our specifications, extracting the metadata, the title and generating a brief summary.
Asynchronous batch scraping with start_batch_scrape
Scraping a small batch synchronously takes a few seconds. A batch of thousands takes minutes, and blocking the calling process for that long is rarely workable. For larger workloads, Firecrawl provides an asynchronous batch API: submit the job, get an ID back immediately, then check status or stream results later. The async pattern fits automated workflows and long URL lists where the calling code can't sit and wait.
This feature is available through the start_batch_scrape method and it works a bit differently:
batch_scrape_job = app.start_batch_scrape(
article_links,
formats=[
{
"type": "json",
"schema": ArticleSummary,
"prompt": "Extract the title of the article and generate its brief summary"
}
]
)When using start_batch_scrape instead of the synchronous version, the response comes back immediately rather than waiting for all URLs to be scraped. The program can continue executing while the scraping happens in the background.
batch_scrape_jobBatchScrapeResponse(
id='7c2f553a-4888-46c3-b19a-412d581b63c9',
url='https://api.firecrawl.dev/v2/batch/scrape/7c2f553a-4888-46c3-b19a-412d581b63c9',
invalid_urls=None
)The response contains the ID of the background job that's now processing the URLs.
You can use this ID later to check the job's status with get_batch_scrape_status method:
batch_scrape_job_status = app.get_batch_scrape_status(batch_scrape_job.id)
dir(batch_scrape_job_status)['completed', 'credits_used', 'data', 'expires_at', 'next', 'status', 'total']Note that get_batch_scrape_status() returns a BatchScrapeJob Pydantic model, so access its fields as attributes (status.status, status.completed) rather than dict keys.
If the job finished scraping all URLs, its status will be set to completed:
batch_scrape_job_status.status'completed'Let's look at how many pages were scraped:
batch_scrape_job_status.total2The response always includes the data attribute, whether the job is complete or not, with the content scraped up to that point. It has error and next attributes to indicate if any errors occurred during scraping and whether there are more results to fetch.
Interacting with pages
Most modern sites are dynamic. Firecrawl gives you two tools depending on when you need to interact:
actions— run before the scrape. You pass a list of steps (click, type, wait), Firecrawl drives a browser through them, and the scrape captures the resulting page state. One call, no session to manage./interact— run after the scrape. The scrape returns ascrapeId; you callinteract()on it with a prompt or code to keep driving the browser. The session stays alive across calls, so you can chain steps and extract from pages that evolve over multiple interactions.
Using actions to prepare a page before scraping
See the actions docs for the full parameter reference.
actions belong in the scrape() call itself. Firecrawl executes them in order inside a real browser, then scrapes the page at whatever state it's in at the end. The action vocabulary covers the most common pre-scrape setup steps:
| Action | Required | Optional | What it does |
|---|---|---|---|
wait | (none) | milliseconds, selector | Pause for a fixed time, or wait until an element appears |
click | selector | (none) | Click a CSS selector |
write | text | (none) | Type text at the current focus point |
press | key | (none) | Send a keyboard key like "Enter" or "Tab" |
scroll | direction | selector | Scroll the page or a specific element |
screenshot | (none) | full_page, quality, viewport | Capture the screen mid-flow |
scrape | (none) | (none) | Snapshot the current DOM state (saved to result.actions["scrapes"]) |
executeJavascript | script | (none) | Run arbitrary JS; the return value lands in result.actions["javascriptReturns"] |
pdf | (none) | format, landscape, scale | Generate a PDF of the current page |
A practical rule of thumb: pair every click and write with a wait either before, after, or both. Pages that look instant in your browser still need a few hundred milliseconds for animations, focus shifts, or async data to settle.
Here's a login flow against a public test site — the actions run first, then the scrape captures the post-login page:
actions = [
{"type": "wait", "milliseconds": 1000},
{"type": "click", "selector": "#username"},
{"type": "write", "text": "tomsmith"},
{"type": "click", "selector": "#password"},
{"type": "write", "text": "SuperSecretPassword!"},
{"type": "press", "key": "Enter"},
{"type": "wait", "milliseconds": 2000},
{"type": "screenshot"},
]
result = app.scrape(
"https://the-internet.herokuapp.com/login",
formats=["markdown", "screenshot"],
actions=actions,
)Once all actions complete, Firecrawl scrapes the page at that state. result.markdown confirms the login worked:
You logged into a secure area!
## Secure Area
#### Welcome to the Secure Area. When you are done click logout below.
[Logout](https://the-internet.herokuapp.com/logout)The mid-flow screenshot sits in result.actions["screenshots"]:
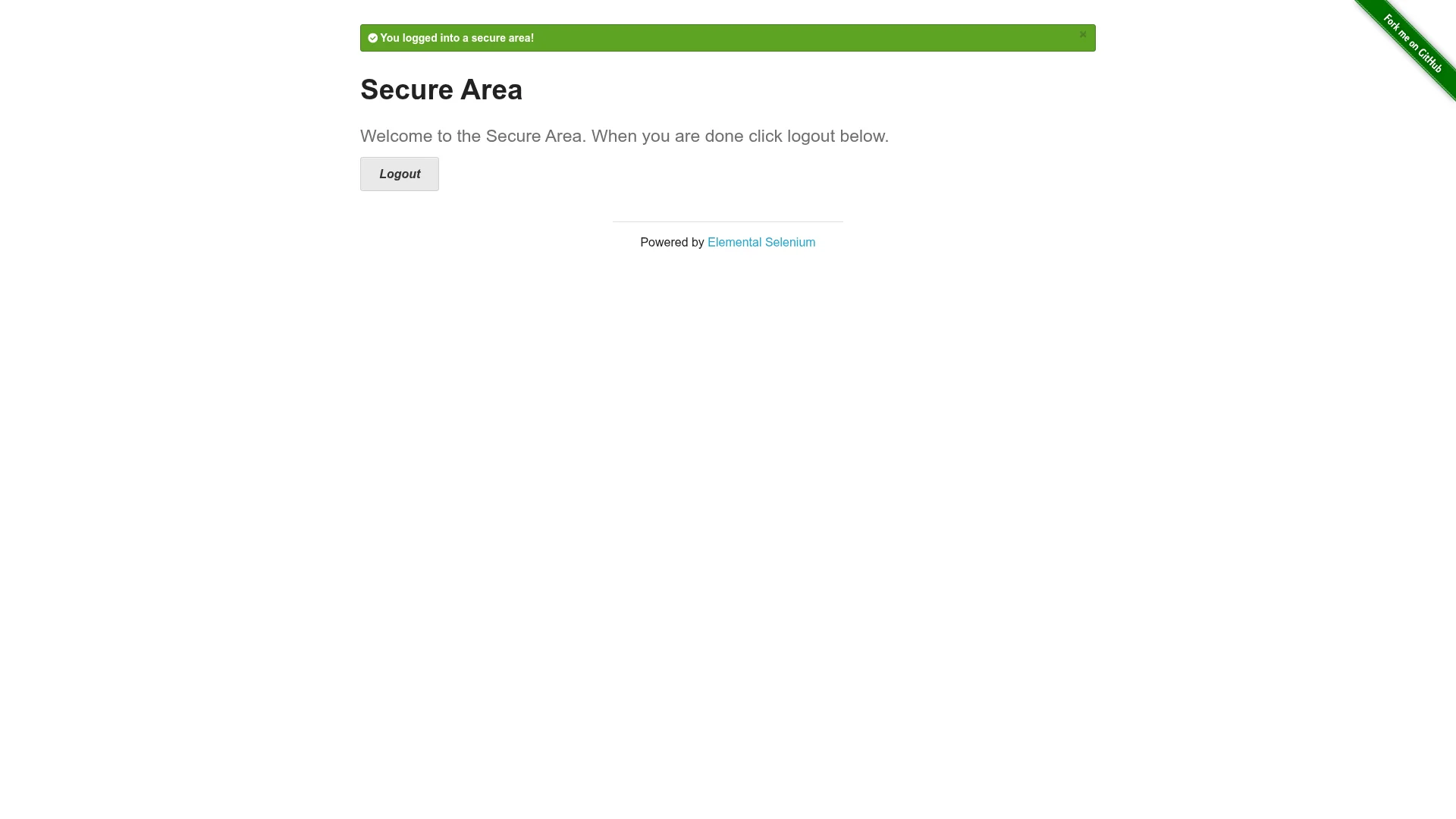
Note that result.actions is a plain dict, not a Pydantic model. The keys are "screenshots", "scrapes", "javascriptReturns", and "pdfs". Screenshot URLs expire after 24 hours, so download what you want to keep.
The actions flow is stateless: each scrape() call re-runs the entire sequence from scratch. That's the right model for one-shot page setup, but not for multi-step workflows where you need to inspect results between steps or react to what the page shows.
Using /interact to continue after scraping
When you need to keep driving a page after the scrape — following links, paginating results, reacting to what you extracted — use /interact. The scrape returns a scrapeId; subsequent interact() calls reuse the same live browser session, so state (cookies, DOM, navigation history) carries over between them.
The pattern is three steps:
from firecrawl import Firecrawl
app = Firecrawl()
# 1. Scrape the page
result = app.scrape("https://www.amazon.com", formats=["markdown"])
scrape_id = result.metadata.scrape_id
# 2. Interact — chain as many calls as needed, session stays alive
app.interact(scrape_id, prompt="Search for iPhone 16 Pro Max")
response = app.interact(scrape_id, prompt="Click on the first result and return the price")
print(response.output)
# 3. Stop the session when done
app.stop_interaction(scrape_id)interact() accepts either a natural language prompt or executable code (Node.js Playwright, Python Playwright, or Bash). Use prompts for flexible exploratory flows and code when you need deterministic steps:
response = app.interact(scrape_id, code="""
await page.click('#load-more');
await page.waitForLoadState('networkidle');
const items = await page.$$eval('.result', els => els.map(e => e.textContent));
JSON.stringify(items);
""")
print(response.result)Every interact() response includes a liveViewUrl you can embed as an <iframe> to watch the browser in real time. For workflows that need to persist login state across separate scrapes, pass a profile to scrape() with save_changes=True — cookies and localStorage are saved when you call stop_interaction() and reloaded automatically on the next scrape with the same profile name.
Pricing: /interact is billed by session time — 2 credits per minute for code-only execution, 7 credits per minute when using AI prompts. The initial scrape() is billed separately at the usual per-page rate. Always call stop_interaction() when you're done; credits are prorated by the second.
See the Interact docs for the full API reference.
Where to go from here
That's /scrape covered end to end. The shape of the call rarely changes much: a URL, a formats list, and whatever extra parameters the page in question needs. What changes is the format you ask for, and that choice does most of the work. Markdown feeds LLMs cleanly. Schema-locked JSON gives you parseable records. Branding pulls design tokens. Audio sets up a transcription pipeline. Screenshots produce documentation. actions takes over when the page needs setup before it shows you anything worth scraping, and /interact takes over when you need to keep driving the browser after the scrape.
If you need to walk a whole site rather than scrape a single page, the /crawl endpoint is the next stop. It takes one starting URL, discovers every page from there, and runs /scrape against each one. The parameters you've learned here carry across.
A few related reads if you want to keep going:
- Mastering Firecrawl Search, for when you need to discover URLs before scraping them — search and extract in one call.
- Using Prompt Caching With Anthropic, a complementary cost lever for the LLM side of an extraction pipeline.
- Scraping Job Boards With Firecrawl and OpenAI, applied scraping with a schema, similar to the Hacker News example here.
- Scraping and Analyzing Airbnb Listings in Python Tutorial, a fuller pipeline that pairs
/scrapewith downstream analysis. - Question and highlights formats for
/scrape, for grounded answers and verbatim excerpts from any page — up to 100x fewer tokens than a full scrape, with prompt-injection hardening and a fully managed LLM stack built in.
Frequently Asked Questions
How much does a scrape cost?
Every scrape starts at 1 credit. JSON mode, the enhanced proxy, and audio extraction each add 4 credits, taking those calls to 5 credits per page. PDF parsing adds 1 credit per PDF page, and ZDR (zero data retention, Enterprise only) adds 1 per page. Cached results still cost the full 1 credit per page.
What's the difference between html and rawHtml?
The `html` format returns the cleaned HTML with scripts and styles stripped, ready to parse or hand to a DOM library. The `rawHtml` format returns the unmodified HTML exactly as received from the server, which is the right choice for archival, diffs, or when you want to run your own cleaning pipeline.
How do I scrape a JavaScript-rendered page?
Firecrawl renders JavaScript automatically on every scrape, so most dynamic pages work without any extra configuration. For slow pages where data loads asynchronously after the initial render, pass `wait_for` in milliseconds (for example, `wait_for=3000`) to give the page extra time to settle before scraping.
Can I extract structured data without writing a schema?
Yes. Pass a `prompt` inside the `json` format object without a `schema` field, and the LLM will choose the JSON structure based on your prompt. The trade-off is that field names can drift between runs. Use a Pydantic schema as soon as you need to parse the output programmatically.
What is enhanced mode and when should I use it?
Enhanced mode is a stronger proxy backend for sites that are harder to fetch reliably. Set `proxy="enhanced"` to opt in. Firecrawl only charges the +4 credit surcharge when the enhanced backend is actually invoked. On simpler sites it falls back to basic and costs 1 credit. The other proxy modes (`basic` and `auto`) are covered alongside the rest of the scrape parameters in the body of the article.
Does caching cost extra credits?
No, but caching doesn't save credits either. A cached scrape still costs 1 credit, the same as a fresh one. Caching speeds up the response and reduces load on the target site, but billing is the same. See the [Advanced Caching](#advanced-caching-with-max_age-control-content-freshness) section for `max_age` controls.
What's the difference between `actions` and `/interact`?
`actions` run before the scrape — you pass a list of steps (click, type, wait) and Firecrawl drives a browser through them before capturing the page. Use it for one-shot setup like submitting a form or dismissing a cookie banner. `/interact` runs after the scrape — the scrape gives you a `scrapeId` and you call `interact()` on it to keep driving the same live browser session across multiple steps, reacting to what the page shows as you go.
When should I use `batch_scrape` vs `start_batch_scrape`?
Use `batch_scrape()` (synchronous) when your script can block until all URLs finish — it returns the full results directly. Use `start_batch_scrape()` (asynchronous) for large batches where blocking isn't practical: it returns a job ID immediately and you check status with `get_batch_scrape_status()` later. Batch jobs expire after 24 hours, so retrieve results before then.
How do I scrape content for a specific country or language?
Pass a `location` object with a `country` ISO code and optional `languages` array to `scrape()`. Firecrawl routes the request through that region and emulates the matching timezone and language settings, so geo-targeted pages — search results, localised pricing, region-specific content — return what a user in that country would see.
Can Firecrawl scrape PDFs?
Yes. Pass a PDF URL to `scrape()` with `formats=["markdown"]` and `parsers=["pdf"]`. Firecrawl extracts the text and returns it as markdown. PDF parsing costs 1 additional credit per PDF page on top of the base scrape credit.
What is Zero Data Retention (ZDR) and when do I need it?
ZDR ensures Firecrawl does not persist any page content or extracted data beyond the lifetime of the request. Set `zeroDataRetention=True` in your scrape call. It is an Enterprise-only feature and adds 1 credit per page. Screenshots are not available in ZDR mode because they require uploading to persistent storage.
