
TL;DR:
- List crawling extracts structured data from repeating page patterns—product grids, job boards, directories—across many pages automatically
- Use BeautifulSoup for static sites when you're learning; Scrapy when you need concurrent requests and built-in pagination handling; Firecrawl when you need clean, schema-validated data without writing CSS selectors or post-processing scripts
- Check
robots.txtand look for an official API before scraping - Identify whether your target uses numbered pagination, "Load more" buttons, or infinite scroll—each requires a different crawling approach
List crawling is a web scraping technique that extracts structured data from repeating patterns on websites. Common examples include product listings on Amazon, job postings on LinkedIn, and apartment rentals on Zillow. Instead of scraping individual pages one by one, list crawling automates collecting data from hundreds or thousands of similar items.
This guide walks through three approaches in order of complexity. BeautifulSoup teaches the fundamentals with minimal abstraction, then Scrapy adds automation when manual loops become tedious. Finally, Firecrawl is a modern solution that handles JavaScript rendering and dynamic content. By the end, you'll know which tools fit your use case and how to build your first list crawler.
What is list crawling?
List crawling extracts data by identifying repeating patterns. On Amazon, each product card has the same structure: image, title, price, rating. List crawling identifies this pattern, extracts the fields from each card, and saves them as structured data.
Manually collecting data from hundreds of web pages is slow and error-prone. You click through pagination, copy fields one by one, paste into spreadsheets, and repeat. List crawling automates this process by recognizing that product cards, job postings, and search results all follow the same structure. Instead of extracting one item at a time, you define the pattern once and let the crawler handle thousands of similar pages.
List crawling differs from general web crawling. General crawlers visit every page to build a site map or index. List crawlers target specific pages with repeating items and extract their data. For a deeper look at this distinction, see our guide on web scraper vs. web crawler.
Here's how they compare:
| Feature | List Crawling | General Web Crawling |
|---|---|---|
| Purpose | Extract structured data from similar items | Discover and index all pages on a site |
| Scope | Specific listing pages | Entire website or domain |
| Output | Structured data (JSON, CSV) | URLs, page content, site map |
| Pattern | Follows repeating item structure | Follows all links |
| Use case | Price monitoring, job aggregation | SEO analysis, site mapping |
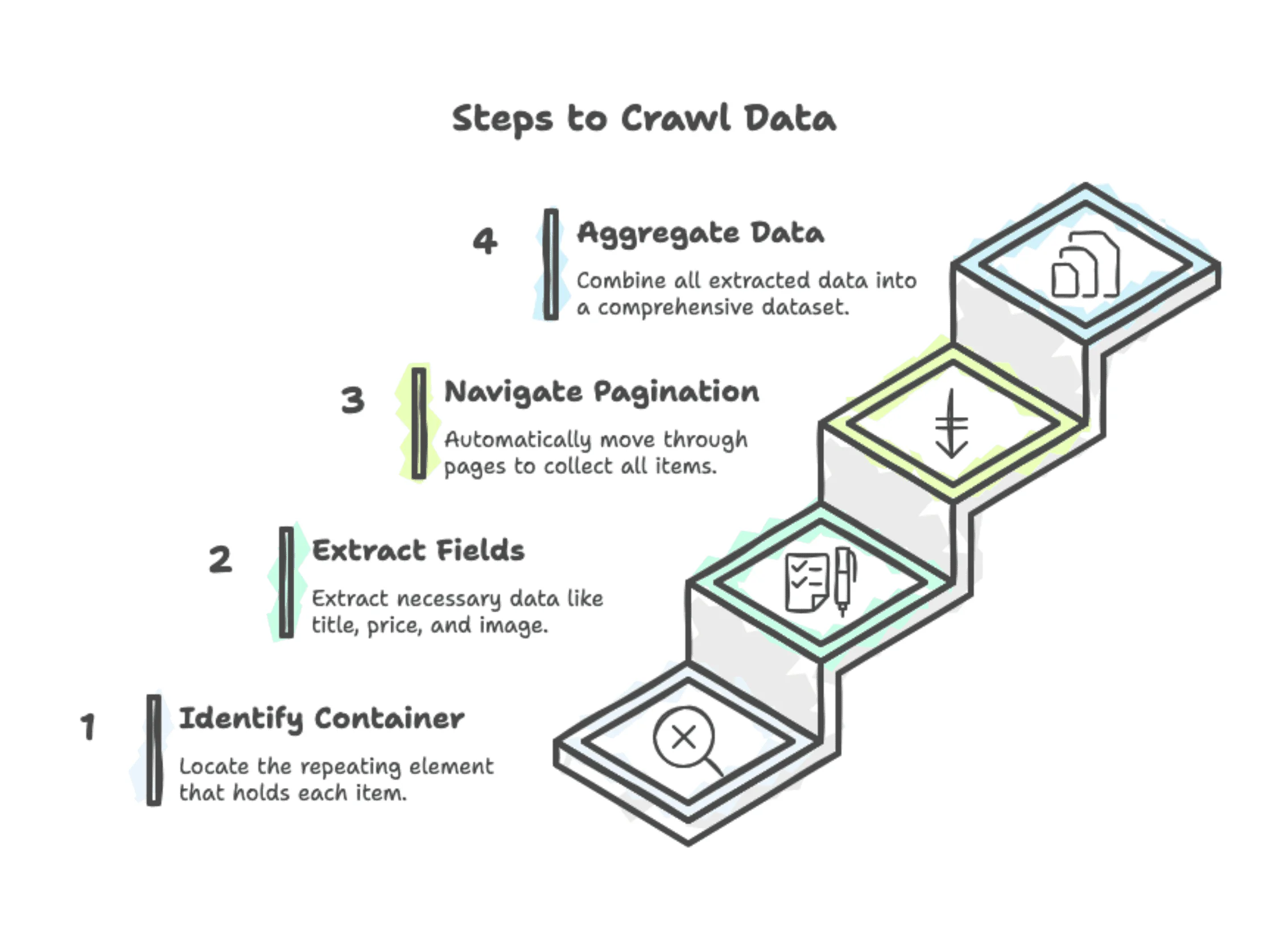
The process follows four steps:
-
Pattern identification: Find the repeating container (typically a CSS class like
.product-cardor.listing-item). -
Field extraction: Extract specific fields from each container: title, price, image URL, product link.
-
Pagination handling: Navigate to the next page and repeat. Most sites use "Next" buttons or page numbers.
-
Data aggregation: Combine everything into one dataset (e.g., 500 products across 20 pages in a CSV file).
Common use cases and suitable websites
Common applications include:
- E-commerce arbitrage: Automated price trackers scan multiple retailers to find resale opportunities or monitor Minimum Advertised Price (MAP) violations across retailer networks. See our automated price tracking tutorial for a full end-to-end implementation.
- Academic research: Scraping research paper metadata from arXiv, PubMed, or IEEE to track citation trends, publication patterns, or emerging research topics.
- Event aggregation: Collecting concert listings, conference schedules, or meetup events from multiple venue websites to build unified calendars.
- Government procurement: Monitoring public bid opportunities, contract awards, and permit applications from government portals for business development.
- Job market intelligence: Scraping job boards to track hiring trends, salary ranges, and in-demand skills across industries. Our guide on scraping job boards with Firecrawl and OpenAI walks through a full pipeline.
- Product intelligence: Tracking Product Hunt daily rankings, GitHub trending repositories, or App Store new releases for competitive analysis and market research.
The best candidates for list crawling share three characteristics:
- Consistent HTML structure: Each item follows the same pattern with identical CSS classes and element hierarchy.
- Predictable patterns: Data appears consistently (e.g., price in
span.price, title inh3). - Clear pagination: Pages use numbered links or "Next" buttons. Infinite scroll and JavaScript pagination require advanced handling.
Product grids, search results, and directory listings work well. If you can click through pages of similar items, it's probably crawlable.
Types of list crawling
Not all list pages reveal more items the same way. The mechanism that loads the next batch determines which crawling technique you need.
Paginated list crawling
Pagination splits results across multiple pages. The page number usually appears in the URL as ?page=2 or /page/2/, or the site uses an offset or start parameter. Your crawler loops through pages until the Next link disappears, the page returns zero items, or the index stops advancing.
This is the most common and easiest to handle. Cheese.com, which we use throughout this guide, is a textbook paginated list.
Load more list crawling
Some sites keep the same URL but append items when you click a button. You can handle this two ways: automate the button click with a headless browser (Playwright or Selenium), or open DevTools, click the button, and capture the background network request—then replay it directly, often much faster. The request usually accepts an offset or cursor parameter.
Infinite scroll list crawling
Infinite scroll loads new items automatically as you scroll to the bottom. It's common on social feeds and modern e-commerce. In a browser-based crawler, you scroll, wait for new items, track the count, and stop when the count stops increasing. If the items load from a background endpoint, you can also capture that request in DevTools and iterate until it returns empty.
Table-based list crawling
Tables and CSS-grid "tables" present one record per row. Target the repeating row element and map each cell to a field name based on position or column headers. Many modern sites render tables with <div> elements styled to look like rows, so the reliable approach is still to identify the repeating container and extract fields from consistent child elements.
Search result list crawling
Internal search pages add an extra variable: results depend on the query, filters, and sort order. Each combination can produce a different list. A crawler here tracks query parameters explicitly, then paginates through results for each combination, using the same stop conditions as paginated or infinite scroll lists.
How to tell if a website's lists are crawlable
Before writing any code, run a quick five-minute assessment to decide whether a site will cooperate with automated extraction.
1. Inspect the page source. Right-click any list item and choose "View Page Source." Search for the text of one item. If you can find it in the raw HTML, the data is server-rendered and a simple HTTP client will work. If you see empty <div> placeholders or loading spinners in the source but the data appears in the browser's Elements panel, the list is generated by JavaScript and you'll need a headless browser.
2. Check the URL pattern. Click through two or three pages and watch the URL bar. Crawlable lists use predictable URL patterns like ?page=2 progressing logically to ?page=3. Red flags include URLs that don't change at all between pages, or URLs with long encrypted tokens that are different every session.
3. Test navigation behavior. Confirm that the browser back button works properly and page numbers load immediately. Broken pagination or complex loading sequences mean your crawler will need extra configuration to handle those edge cases.
4. Look for a robots.txt and API. Visit sitename.com/robots.txt before scraping. Many sites explicitly list which paths automated tools may or may not access. Also check whether the site has a public API—if it does, use it instead of scraping. APIs return clean, structured data without maintenance overhead.
Now that you understand the concept, let's see list crawling in action. We'll build a complete crawler from scratch, starting with the simplest tool and progressing to more sophisticated approaches.
Understanding our target: cheese.com types
Cheese.com is a cheese encyclopedia with over 2,000 varieties from around the world. We'll scrape their types directory at https://www.cheese.com/by_type/. This page lists all cheeses alphabetically with links to individual cheese pages.
This list crawling task has the classic pattern: a directory page with repeating items spread across many pages. Each cheese card follows the same structure, making it perfect for extracting structured data at scale.
What the page looks like
Open https://www.cheese.com/by_type/ in your browser. You'll see a grid of cheese cards. Each card shows a cheese photo, name, and brief description. At the bottom, there's numbered pagination: 1, 2, 3... and an ellipsis leading to pages 100, 101, 102, 103.
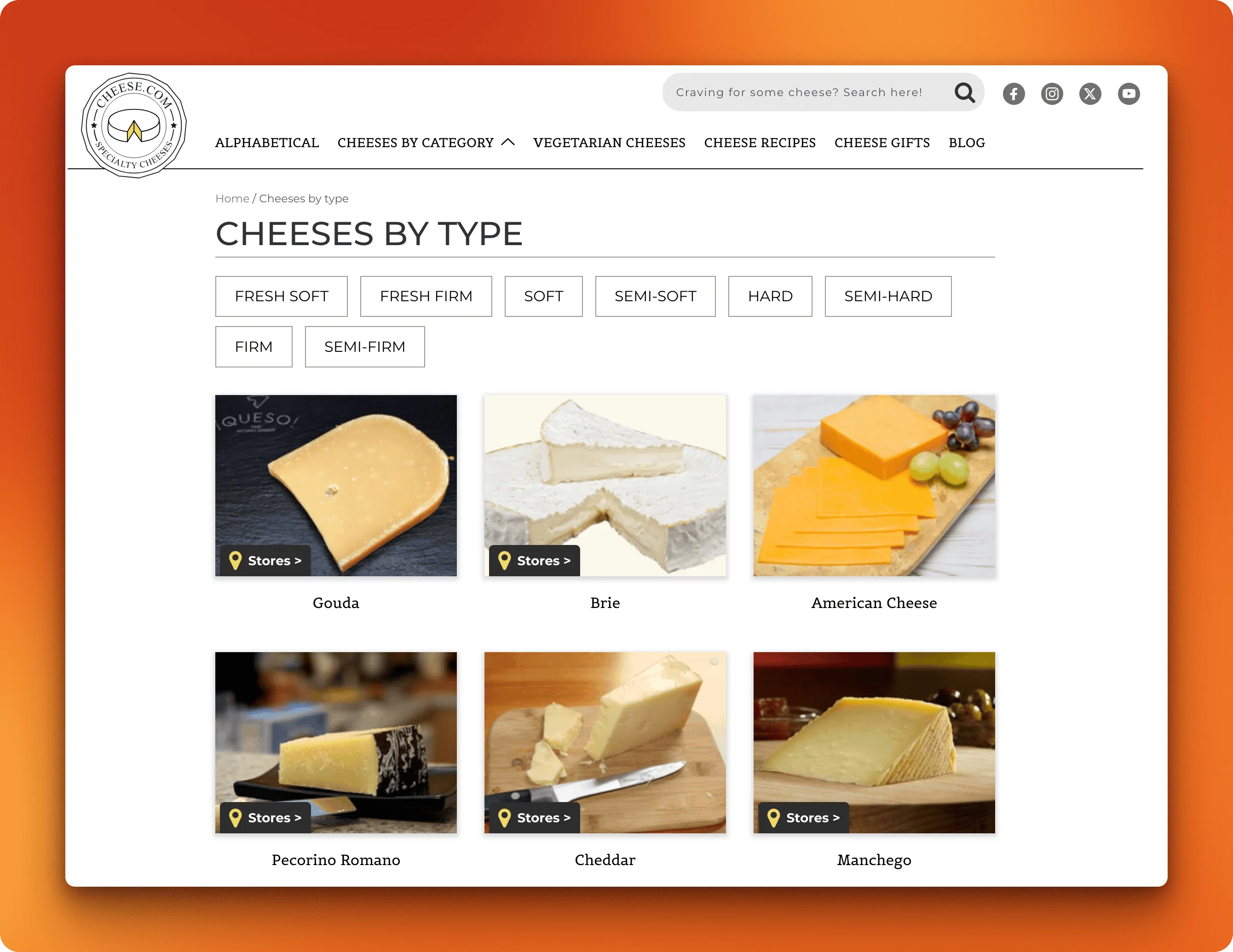
This is a typical list crawling scenario: hundreds of similar items organized across multiple pages. You need to visit each page, extract the repeating pattern, and combine everything into one dataset.
Click through a few pages. The URL pattern changes:
- Page 1:
https://www.cheese.com/by_type/ - Page 2:
https://www.cheese.com/by_type/?page=2 - Page 3:
https://www.cheese.com/by_type/?page=3
This is standard query parameter pagination. By default, each page shows 20 cheeses. With 103 pages, that's 2,060 total cheeses. But look at the top of the page. There's a dropdown: "Per page: 20, 40, 60, 80, 100." Change it to 100 and the URL becomes https://www.cheese.com/by_type/?page=1&per_page=100. Now you only need 21 pages to get all the data instead of 103.
This parameter is a gift for scraping. It cuts your request count by 80%. Fewer requests means faster list crawling and less load on the server.
Inspecting the HTML structure
Press F12 to open Chrome DevTools. Right-click any cheese card and select "Inspect." You'll see something like this:
<div class="product-item">
<a href="/gouda/">
<img src="..." alt="A slice of Gouda cheese displayed on a black marble surface" />
<h3>Gouda</h3>
</a>
<p class="description">...</p>
</div>The structure shows the repeating pattern that makes list crawling possible:
- Container: Each cheese lives in a
<div class="product-item"> - Link: The
<a>tag contains the URL to the cheese page - Name: Could be in the
<h3>tag, or in the imagealtattribute, or in the link text - URL: In the
hrefattribute (relative path like/gouda/)
The name appears in multiple places with some variation. Sometimes it's in the <h3>. Sometimes only in the image alt text. This is normal for real-world sites. Your list crawler needs to handle these variations.
What we'll extract
Our goal: list crawl all 2,046 cheeses efficiently using the per_page=100 parameter (21 pages instead of 103).
For each cheese, we need:
- Name: The cheese name
- URL: The full URL to the cheese page
The output format:
[
{"name": "Gouda", "url": "https://www.cheese.com/gouda/"},
{"name": "Brie", "url": "https://www.cheese.com/brie/"},
...
]How to list crawl with BeautifulSoup in Python
BeautifulSoup is the simplest way to scrape HTML. It parses the page and lets you search for elements using CSS selectors or tag names. For list crawling, you'll use it to find the repeating pattern and extract data from each item. If you're new to web scraping, our Python scraping tutorial for beginners covers the fundamentals first. For a side-by-side look at how BeautifulSoup stacks up against Scrapy across more scenarios, see our BeautifulSoup vs. Scrapy comparison.
Prerequisites
Install the required libraries:
pip install requests beautifulsoup4You need requests to fetch web pages and beautifulsoup4 to parse HTML. Make sure you have Python 3.7 or later installed.
Step 1: Scrape the first page
Let's start by list crawling just page 1 with 20 cheeses. Here's the complete code:
import requests
from bs4 import BeautifulSoup
url = "https://www.cheese.com/by_type/"
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
# Find all cheese containers
cheese_items = soup.find_all('div', class_='product-item')
cheeses = []
for item in cheese_items:
link = item.find('a', href=True)
if link:
# Try to get name from h3 first
name = None
h3 = link.find('h3')
if h3:
name = h3.text.strip()
# Fallback to image alt text
if not name:
img = link.find('img')
if img and img.get('alt'):
name = img['alt'].strip()
url = 'https://www.cheese.com' + link['href']
cheeses.append({
'name': name,
'url': url
})
print(f"Found {len(cheeses)} cheeses")
for cheese in cheeses[:5]:
print(f"- {cheese['name']}")Run this code. You should see:
Found 20 cheeses
- A slice of Gouda cheese displayed on a black marble surface
- A wheel of Brie cheese, partially sliced, sits on a white surface...
- Blocks and slices of yellow American cheese arranged on a wooden cutting board
- A black plate showcases a piece of Pecorino Romano cheese...
- Cheddar cheese cut into pieces on a wooden cutting board...The code fetches the page, parses it with BeautifulSoup, finds all <div class="product-item"> elements, and extracts the name and URL from each one. This is the core list crawling pattern: find the repeating container, loop through each instance, extract the fields.
Notice the User-Agent header. Some websites block requests without this header because they look like bots. Adding a browser user agent makes your requests look like they're coming from a real browser.
Step 2: Detect total pages automatically
Before we list crawl all pages, we need to know how many pages exist. Hardcoding "103 pages" breaks when the site adds more cheeses. Let's detect it dynamically:
def get_total_pages(per_page=100):
url = f"https://www.cheese.com/by_type/?per_page={per_page}"
response = requests.get(url, headers={'User-Agent': 'Mozilla/5.0'})
soup = BeautifulSoup(response.content, 'html.parser')
# Find all page number links
page_links = soup.find_all('a', class_='page-link')
max_page = 1
for link in page_links:
try:
page_num = int(link.text.strip())
max_page = max(max_page, page_num)
except:
pass # Skip non-numeric links like "..."
return max_page
total_pages = get_total_pages(per_page=100)
print(f"Total pages to scrape: {total_pages}")This finds all pagination links, extracts the numbers, and returns the highest one. With per_page=100, it returns 21 instead of 103. This makes your list crawler adaptive instead of brittle.
Step 3: List crawl all 2,046 cheeses
Now combine everything to scrape all pages:
import time
all_cheeses = []
per_page = 100
total_pages = get_total_pages(per_page)
for page_num in range(1, total_pages + 1):
url = f"https://www.cheese.com/by_type/?page={page_num}&per_page={per_page}"
response = requests.get(url, headers={'User-Agent': 'Mozilla/5.0'})
soup = BeautifulSoup(response.content, 'html.parser')
cheese_items = soup.find_all('div', class_='product-item')
for item in cheese_items:
link = item.find('a', href=True)
if link:
# Extract name (same logic as before)
name = None
h3 = link.find('h3')
if h3:
name = h3.text.strip()
if not name:
img = link.find('img')
if img and img.get('alt'):
name = img['alt'].strip()
cheese_url = 'https://www.cheese.com' + link['href']
all_cheeses.append({'name': name, 'url': cheese_url})
print(f"Page {page_num}/{total_pages}: {len(cheese_items)} cheeses (total: {len(all_cheeses)})")
# Be polite - wait 1 second between requests
if page_num < total_pages:
time.sleep(1)
print(f"\nTotal: {len(all_cheeses)} cheeses scraped")Run this and you'll get all 2,046 cheeses in about 38 seconds (21 pages × 1.8 seconds per page). The time.sleep(1) adds a 1-second delay between requests. This is polite. Don't hammer servers with rapid-fire requests.
The result
You now have 2,046 cheese records in a list. You can save this to JSON, CSV, or load it into a database:
import json
with open('cheeses.json', 'w') as f:
json.dump(all_cheeses, f, indent=2)This BeautifulSoup approach works well for static HTML sites with simple pagination. You get functional list crawling in about 90 lines of code. But notice how much manual work went into building the URL loop, detecting page counts, and handling each request individually. For production list crawling at scale, you want a framework that automates these repetitive tasks. That's where Scrapy comes in.
For more on BeautifulSoup's features and parsing methods, check the official documentation.
Need cleaner data without post-processing? Try Firecrawl's schema-based extraction.
How to list crawl with Scrapy?
Scrapy is a web scraping framework. Where BeautifulSoup gives you parsing tools, Scrapy gives you a complete crawling system with request scheduling, concurrent downloads, automatic delays, and built-in data export. It's the tool you reach for when manual loops and file handling become tedious. If you're new to Python scraping in general, our Python web scraping tutorial covers the full stack from HTTP requests to async patterns.
The spider
First, install Scrapy:
pip install scrapyStart with the spider class and settings:
import scrapy
class CheeseSpider(scrapy.Spider):
name = 'cheese_spider'
# Custom settings for politeness and speed
custom_settings = {
'CONCURRENT_REQUESTS': 4, # Download 4 pages simultaneously
'DOWNLOAD_DELAY': 1, # Wait 1 second between requests
'USER_AGENT': 'Mozilla/5.0 (compatible; CheeseBot/1.0)',
}The custom_settings dictionary configures this spider's behavior. CONCURRENT_REQUESTS: 4 means Scrapy downloads 4 pages at once instead of waiting for each request to finish. DOWNLOAD_DELAY: 1 adds a 1-second pause between requests to the same domain.
Next, generate the page requests:
def start_requests(self):
"""Generate requests for all 21 pages."""
base_url = "https://www.cheese.com/by_type/"
# Page 1
yield scrapy.Request(
url=f"{base_url}?per_page=100",
callback=self.parse
)
# Pages 2-21
for page_num in range(2, 22):
url = f"{base_url}?page={page_num}&per_page=100"
yield scrapy.Request(url=url, callback=self.parse)The start_requests() method creates 21 requests, one for each page. The yield keyword sends each request to Scrapy's scheduler, which manages the download queue. The callback=self.parse tells Scrapy which method should process each response.
Finally, extract the data:
def parse(self, response):
"""Extract cheese data from each page."""
# Find all cheese containers
cheese_items = response.css('div.product-item')
for item in cheese_items:
# Get the link
link = item.css('a::attr(href)').get()
if link:
# Try h3 first, fallback to image alt
name = item.css('a h3::text').get()
if not name or not name.strip():
name = item.css('a img::attr(alt)').get()
if name:
name = name.strip()
# Build full URL
full_url = response.urljoin(link)
# Yield the data
yield {
'name': name,
'url': full_url
}The parse() method runs on each downloaded page. response.css('div.product-item') uses CSS selectors to find elements, similar to BeautifulSoup's .find_all() but with different syntax. The yield at the end sends each cheese dictionary to Scrapy's export system.
Running the spider
Save the code as cheese_spider.py and run:
scrapy runspider cheese_spider.py -o cheeses.jsonThe -o cheeses.json flag tells Scrapy where to write the output. You can also use -o cheeses.csv or -o cheeses.xml. The terminal shows real-time statistics:
2025-11-04 15:31:34 [scrapy.core.engine] INFO: Spider closed (finished)
Crawled 21 pages (at 49 pages/min), scraped 2046 items (at 4749 items/min)
'elapsed_time_seconds': 25.85All 2,046 cheeses in 26 seconds. That's 32% faster than the BeautifulSoup version.
But look at the actual data:
{"name": "Bosworth cheese log showcasing white rind rests on a wooden board", "url": "https://www.cheese.com/bosworth/"},
{"name": "A piece of White Stilton infused with Mango & Ginger cheese, showcasing mango pieces, rests on a grey background.", "url": "https://www.cheese.com/white-stilton-mango-ginger/"}Same verbose image descriptions. Scrapy automated the pagination and sped things up, but the data quality matches BeautifulSoup's output. Both tools extract what's in the HTML, whether that's a clean name or a full sentence from an image alt attribute.
What Scrapy adds
Scrapy's main advantage is automation. You write class methods instead of loops. The framework handles request queuing, automatically retries failed pages, and shows you crawl statistics without extra logging code. The concurrent downloads make it faster for multi-page crawls. The one-line export flag (-o) replaces manual file handling.
For sites like Cheese.com with straightforward HTML and predictable pagination, Scrapy handles everything smoothly. But not all websites are this cooperative.
Learn more about Scrapy's architecture and advanced features in the official documentation.
Want structured data without regex cleanup? Get started with Firecrawl.
When traditional tools hit limits
Both BeautifulSoup and Scrapy extracted the same verbose ALT text: "A slice of Gouda cheese displayed on a black marble surface" instead of just "Gouda." This creates problems in production:
- Databases: Can't use 100-character descriptions as keys or for queries
- APIs: Users expect
{"name": "Gouda"}not full sentences - Analytics: Joins and filtering break on inconsistent text formats
- Integration: Other systems expect clean, structured fields
You could write regex patterns or string manipulation to clean this data, but edge cases multiply quickly. Some ALT text has parentheses, some has commas, some omits the cheese name entirely. Manual cleaning doesn't scale to thousands of items.
Selector brittleness
Both scrapers rely on specific HTML structure. The code assumes div.product-item contains cheese cards and img::attr(alt) has the name. Sites change their HTML when they:
- Roll out redesigns
- Run A/B tests on layouts
- Add seasonal themes
- Launch marketing campaigns
Today's <h3> inside an <a> tag becomes tomorrow's <h2 class="cheese-title"> in a different container. When structure changes, your scraper returns nothing. It breaks silently.
At small scale, you debug and fix selectors. At larger scale with ten or twenty sites, you're constantly updating code because each site changes on different schedules. More CSS selectors mean more breakage points. Our web scraping mistakes guide covers the most common selector failures and how to design around them.
Beyond static HTML
Cheese.com serves static HTML with no JavaScript requirements. Most modern sites don't work this way.
E-commerce sites load products with JavaScript after the initial page loads. BeautifulSoup requests the page and gets <div id="root"></div> with nothing inside. Scrapy sees the same empty container before JavaScript populates it with content. You need browser automation tools like Selenium or Playwright to wait for content to load.
Many sites also employ rate limiting, throttling or blocking IP addresses making many requests. Dynamic content requiring JavaScript execution may need additional infrastructure such as headless browsers, retry logic, and monitoring systems on top of your scraping code.
Production requirements
Production list crawling needs all of these at once:
- Clean, structured data instead of HTML cruft
- Reliable extraction that survives HTML changes
- JavaScript rendering for dynamic sites
The traditional approach means combining multiple tools: Scrapy for crawling, Selenium for JavaScript, a proxy service for IP rotation, and custom scripts for data cleaning. You monitor these systems, update selectors when sites change, and maintain specialized knowledge of browser automation.
So, with all that said, let's consider a modern web scraping API like Firecrawl that solves all these issues.
Modern list crawling with Firecrawl
Firecrawl is the context API to search, scrape, and interact with the web at scale. It offers these capabilities:
- Webpage to markdown conversion for clean, LLM-ready documents from web pages
- Structured data extraction using LLMs to locate and extract specific details from webpages
- List crawling of multiple URLs without managing loops or retry mechanisms
- JavaScript rendering for dynamic sites that would fail BeautifulSoup or Scrapy
For our cheese crawling task, Firecrawl's structured extraction means we can define exactly what data we want (cheese name, country, flavor, etc.) using Pydantic schemas. The service figures out where that data lives in the HTML and extracts it automatically. We'll use this to build a two-phase crawler: first extract cheese names and URLs from listing pages, then extract detailed attributes from individual cheese pages. No CSS selectors to write or maintain.
Getting started with Firecrawl
You can try Firecrawl's endpoints without an API key to start. When you're ready to go further, sign up for a free account at firecrawl.dev and grab a key from the dashboard for higher rate limits and more credits. Install the Python SDK:
pip install firecrawl-py python-dotenvStore your API key in a .env file in your project directory:
FIRECRAWL_API_KEY='fc-your-api-key-here'Now load it in your Python code:
from dotenv import load_dotenv
load_dotenv() # Loads FIRECRAWL_API_KEY from .env fileThe SDK automatically reads the FIRECRAWL_API_KEY environment variable, so you don't need to pass it explicitly when creating the client.
Define your data structure
Here's what schema-based extraction looks like for both phases of our cheese crawling task. Firecrawl uses Pydantic models for data validation and schema definition:
from firecrawl import Firecrawl
from pydantic import BaseModel, Field
from typing import List
import json
app = Firecrawl()
# Phase 1: List extraction schema
class Cheese(BaseModel):
name: str = Field(description="The cheese name")
url: str = Field(description="Full URL to cheese page")
class CheeseList(BaseModel):
cheeses: List[Cheese]
# Phase 2: Detail extraction schema
class CheeseDetails(BaseModel):
name: str
description: str
country_of_origin: str
cheese_type: str
rind: str
colour: str
flavour: str
image_url: strThe schemas tell Firecrawl what data you need. No CSS selectors, no HTML parsing logic, no data cleaning code.
Phase 1: Extract the list
Start by batch scraping 10 listing pages to collect cheese names and URLs. We're using 10 pages here to keep costs manageable while demonstrating the approach. This gets us 1,000 cheeses instead of all 2,046:
# Using 10 pages for demonstration (1,000 cheeses)
# To get all cheeses, change range(1, 11) to range(1, 22)
listing_urls = [f"https://www.cheese.com/by_type/?page={p}&per_page=100"
for p in range(1, 11)]
result = app.batch_scrape(
listing_urls,
formats=[{"type": "json", "schema": CheeseList}]
)
# Collect all cheeses from all pages
all_cheeses = []
for page_data in result.data:
all_cheeses.extend(page_data.json['cheeses'])
print(f"Collected {len(all_cheeses)} cheeses")
# Show first 3 results
for cheese in all_cheeses[:3]:
print(f"- {cheese['name']}: {cheese['url']}")Run this and you'll see:
Collected 1,000 cheeses
- Abbot's Gold: https://www.cheese.com/abbots-gold/
- La Vache Qui Rit cheese: https://www.cheese.com/la-vache-qui-rit/
- Caerphilly: https://www.cheese.com/caerphilly/Now compare the output quality across all three approaches:
| Tool | Output for Gouda |
|---|---|
| BeautifulSoup | "A slice of Gouda cheese displayed on a black marble surface" |
| Scrapy | "A slice of Gouda cheese displayed on a black marble surface" |
| Firecrawl | "Gouda" |
Clean names ready for database storage. No regex cleaning, no string manipulation, no manual post-processing.
Save the list to JSON:
with open('cheeses_firecrawl_list.json', 'w') as f:
json.dump(all_cheeses, f, indent=2)To scale to all 21 pages and get all 2,046 cheeses, just change the range: range(1, 22).
Phase 2: Go deeper
In the BS4 and Scrapy sections, we only scraped the cheese type URLs. Actually visiting each URL and extracting each cheese type's details would require even more code and effort.
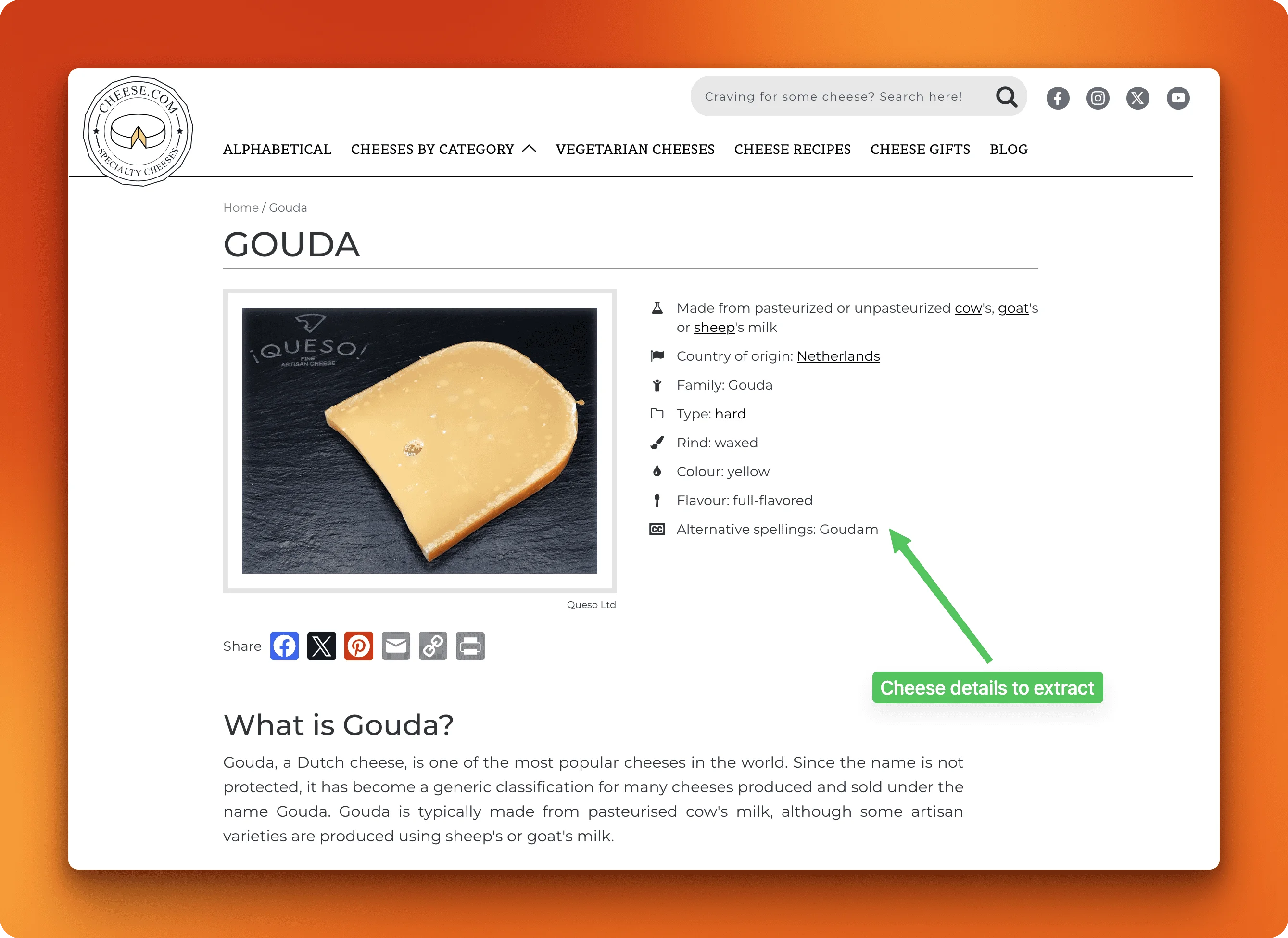
In contrast, Firecrawl can extract these attributes from individual cheese pages in the same workflow. Let's extract details for the first 10 cheese types using the CheeseDetails schema we defined earlier:
# Get URLs for first 10 cheeses
detail_urls = [cheese['url'] for cheese in all_cheeses[:10]]
print(f"Extracting details for {len(detail_urls)} cheeses...")
# Extract detailed attributes using the CheeseDetails schema
result = app.batch_scrape(
detail_urls,
formats=[{"type": "json", "schema": CheeseDetails}]
)
detailed_cheeses = []
for page_data in result.data:
detailed_cheeses.append(page_data.json)
print(f"Extracted {len(detailed_cheeses)} cheese profiles")Run this and you'll see:
Extracting details for 10 cheeses...
Extracted 10 cheese profiles
The schema defines seven attributes. Firecrawl extracts all of them from each cheese page:
{
"name": "Gouda",
"country_of_origin": "Netherlands",
"cheese_type": "hard",
"rind": "waxed",
"colour": "yellow",
"flavour": "full-flavored",
"description": "Gouda, a Dutch cheese, is one of the most popular cheeses in the world...",
"image_url": "https://www.cheese.com/media/img/cheese/gouda.webp"
}Save the detailed results:
with open('cheeses_firecrawl_detailed.json', 'w') as f:
json.dump(detailed_cheeses, f, indent=2)To extract details for all 1,000 cheeses instead of just 10, change all_cheeses[:10] to all_cheeses. For the full 2,046 cheese database, first scrape all 21 listing pages in Phase 1, then extract details for all collected URLs. This pattern — taking a URL list and converting it to clean documents for embeddings — applies directly to RAG pipelines where you start with a known set of pages rather than crawling from a root URL.
The comparison
| Metric | BeautifulSoup | Scrapy | Firecrawl |
|---|---|---|---|
| Code lines | ~90 | ~100 | ~40 |
| Data quality | Verbose ALT text | Verbose ALT text | Clean structured |
| Crawl depth | List page only | List page only | List + Details |
| Attributes | 2 (name, URL) | 2 (name, URL) | 7+ (country, type, rind...) |
| Maintenance | High (selectors break) | High (selectors break) | Low (schema-driven) |
| Best for | Learning, simple sites | Framework features | Production data quality |
The tradeoff is speed versus quality. BeautifulSoup and Scrapy run faster but deliver messy data that needs cleaning. Firecrawl takes longer per request but returns exactly what your database or API needs without any post-processing work. Once you deploy this scraper script, it can run for a long time without maintenance as Firecrawl adapts to website changes.
How do you choose the best tool?
Choosing between these tools depends on what you're building and your constraints.
Start with BeautifulSoup if you're learning web scraping or need a quick prototype. It's simple and perfect for one-off data collection from static sites. You'll write more code, but you'll understand every piece of it.
Move to Scrapy when pagination becomes tedious or you need framework features like pipelines and concurrent requests. It's worth the learning curve if you're scraping multiple sites or handling thousands of pages. The automation saves time, but you're still maintaining CSS selectors and handling data cleanup yourself.
Choose Firecrawl when data quality matters more than execution speed. If you're building production APIs, feeding databases, or integrating with other systems, schema-based extraction eliminates the cleaning phase entirely. You trade slower crawls for zero maintenance overhead and database-ready output.
Most projects don't stay with one tool forever. You might prototype with BeautifulSoup, automate pagination with Scrapy, then switch to Firecrawl when data quality becomes a bottleneck. Pick the tool that solves your current problem.
Cleaning and preparing scraped list data
Extracting data is only half the job. Raw scraped data almost always needs cleanup before it's usable. Common problems after list crawling include duplicate rows when pagination overlaps, missing values where items didn't fully render, inconsistent formats for prices and dates, and leftover HTML tags or whitespace in text fields.
Here's a minimal Pandas pipeline that handles the most common issues:
import pandas as pd
df = pd.read_csv('scraped_data.csv')
# Remove exact duplicates
df = df.drop_duplicates()
# Normalize price format: "$19.99" and "19.99 USD" → 19.99
df['price'] = df['price'].str.replace(r'[^\d.]', '', regex=True).astype(float)
# Standardize date format
df['date'] = pd.to_datetime(df['date'], errors='coerce')
# Strip leftover HTML and extra whitespace from text fields
df['description'] = df['description'].str.replace(r'<[^>]+>', '', regex=True).str.strip()
# Drop rows with critical fields missing
df = df.dropna(subset=['name', 'price'])
df.to_csv('cleaned_data.csv', index=False)For small datasets, Excel or Google Sheets handles deduplication and format fixes interactively. For inconsistent strings—company names with different capitalizations or abbreviations—OpenRefine clusters similar entries and lets you merge them without writing code.
Pro tip: Schema-based tools like Firecrawl eliminate most of this step because the extraction layer normalizes data before it reaches your code. When you define a Pydantic schema with price: float, the model returns a number, not "$19.99 USD". That's the real productivity gain: not spending an afternoon writing cleanup scripts after every crawl.
List extraction for any use case
List crawling extracts structured data from repeating patterns across web pages. You learned three approaches: BeautifulSoup gives you full control and works for learning, Scrapy automates pagination and scales better for complex crawls, and Firecrawl delivers clean data without selector maintenance. The right tool depends on your needs. BeautifulSoup for understanding fundamentals, Scrapy for automation, Firecrawl for production quality. Start simple and upgrade when you hit limits. Check for official APIs before scraping, respect website policies, and remember that data quality matters more than raw extraction speed when you're building real systems.
Tired of cleaning messy scraped data? Try Firecrawl's schema-based extraction and see the difference between raw HTML and structured output. Start with the free tier and scrape up to 1,000 pages per month.
Resources: Firecrawl documentation, templates, community
Frequently Asked Questions
What's the difference between web scraping and list crawling?
Web scraping is the general practice of extracting data from websites. List crawling is a specific scraping technique that targets pages with repeating patterns like product listings, search results, or directories. Regular scraping might extract one product page or a single article. List crawling extracts dozens or thousands of similar items by identifying the repeating structure and applying the same extraction logic to each instance.
Can I list crawl any website legally?
No. Check the website's Terms of Service first. Many sites explicitly prohibit scraping. Also check robots.txt at the site root, which specifies what automated tools can access. Some sites allow crawling for personal use but prohibit commercial applications. Scraping public data is generally safer than accessing content behind logins. When in doubt, contact the site owner or look for an official API. Legal boundaries vary by country and use case, so consider consulting a lawyer for commercial projects.
Should I use list crawling or a website's API?
Always prefer the official API when one exists. APIs provide clean, structured data with documented endpoints and official support. They won't break when the site redesigns, and you're not risking Terms of Service violations. List crawl only when there's no API, the API is too expensive, or it doesn't provide the data you need.
How do I get clean data instead of HTML cruft?
Traditional scrapers extract whatever HTML contains, which often means verbose ALT text, inconsistent formatting, or missing fields. You can post-process with regex and string manipulation, but this breaks on edge cases. Schema-based extraction tools like Firecrawl let you define what you want using Pydantic models, and the tool figures out where to find it. This produces database-ready output without manual cleaning.
What's the best way to handle pagination?
For simple numbered pages (?page=2, ?page=3), loop through the range and construct URLs manually. For 'Next' button pagination, find the link element and follow it until you reach the last page. Scrapy handles this well with link extractors. Infinite scroll requires browser automation with Selenium or Playwright to trigger scroll events and wait for content to load. Some sites use AJAX pagination where clicking loads data through JavaScript without changing the URL.
How do I tell if a website's lists are crawlable?
Open the page and look for repeating visual patterns: product grids, table rows, search results. Right-click an item and inspect the HTML. If each item uses the same CSS class or element structure, it's crawlable. Check if JavaScript loads the content by disabling JavaScript in browser settings and reloading. If the items disappear, you need browser automation. Look at pagination: numbered links or 'Next' buttons work easily, while infinite scroll requires more effort.
What data format should I export to?
JSON works well for nested data and integrates easily with web applications. CSV is better for tabular data that you'll analyze in Excel or load into databases. Both BeautifulSoup and Scrapy can export to either format. Scrapy offers built-in exporters (-o output.json or -o output.csv). For BeautifulSoup, use Python's json or csv modules. Choose JSON for complex structures with nested objects or arrays. Choose CSV when each item has the same flat fields.
When should I use a paid service vs. building my own?
Build your own scraper when you're learning, working with simple static sites, or have time to maintain code. Use a paid service like Firecrawl, ScraperAPI, or Bright Data when you're hitting technical walls: JavaScript-heavy sites or frequent HTML changes. Also consider paid services when development time costs more than the subscription.
How do I maintain scrapers when sites change?
Sites change HTML structure during redesigns, A/B tests, or updates. Your selectors break and return empty results. Monitor your scrapers with alerts that trigger when data extraction fails or returns unexpected results. Build flexible selectors that don't depend on exact structure. Test scrapers regularly even when they're working. Schema-based tools like Firecrawl adapt automatically because they use AI to understand page structure instead of rigid selectors.
How do I clean and normalize scraped list data?
With traditional scrapers, you'll need to remove duplicates, handle missing fields, normalize price and date formats, and strip leftover HTML from text. With Firecrawl, most of this disappears—it returns clean, structured, LLM-ready output so there's no post-processing step.
