
TLDR: Best web search tools for agents
To pick the best search tools for your AI agents, ask yourself this question: do you want the API to handle the processing, or would you rather build the processing pipeline?
| Tool | Type | Latency | Pricing | Best For |
|---|---|---|---|---|
| Firecrawl | Content extraction + search | ~1,335ms | $83/mo (100K credits) | RAG pipelines that need full-page content |
| Brave Search API | Web search | 669ms | $5/1K queries (no free tier) | Privacy-sensitive apps, low latency |
| Exa | Semantic search | Sub-425ms (Exa Fast) | $7/1K searches | Natural-language, intent-driven queries |
| Tavily | AI search + extract | ~998ms | $0.008/credit PAYG basic search | AI search and research workflows, native LangChain |
| Perplexity Sonar | Synthesis | 11+ seconds | Varies by model | Batch research, async pipelines |
| Serper | SERP | Fast | $0.30–$1/1K queries | High volume, you already have a scraper |
Search tools have always been programmatic. You sent a query, got back a list of links, titles, and snippets, and your own code did the rest: fetch each page, strip the junk, and pull out the data you actually wanted. The API handed you raw signal, and the extraction was your problem to solve.
Now, the AI agent is the consumer. It pulls every result straight into its context window and reasons over it, so raw links, half-finished snippets, and raw HTML scrapes become tokens it burns through before reaching anything useful.
That is why a new class of search tools for AI agents exists, and picking the right tool comes down to how much of the extraction the API handles vs your processing pipelines.
What are search tools for AI agents?
Search tools for agents are APIs that query the web, return structured results, and feed them into a context window for reasoning. The output format, ranking, and data shape target a language model as the reader rather than a browser.
Raw HTML, for example, burns context on navigation, ad slots, cookie notices, and footer links before the model reaches a useful sentence.
On a content-heavy page that is thousands of wasted tokens per result, multiplied across every result the agent reads on every turn. An agent reading raw HTML can spend most of its budget on page furniture and run out of room before reaching anything useful.
Cleaner context leaves more of that budget for reasoning.
Types of search tools AI agents
| Category | Output Format | Processing Level | Best For |
|---|---|---|---|
| SERP API | Raw JSON (URLs, titles, snippets) | None | Cheap, high-volume keyword search |
| Web Search API | Ranked snippets, relevance scores | Medium | RAG pipelines, general grounding |
| Semantic Search API | Semantically matched results | Medium-High | Concept-based discovery, research agents |
| Synthesis API | Full cited answer (LLM-generated) | High | When you want a finished answer |
| Content Extraction API | Full-page markdown/JSON | High | Deep context, document analysis |
-
SERP APIs give you the same list a search engine shows a browser, which is just organic results with titles, URLs, and short snippets. From there your agent has to pick which URLs are worth reading, fetch each page, pull out the content, and chunk it before the model can touch any of it, which is four steps your pipeline owns on every turn. Serper sells that raw signal for $0.30 to $1.00 per 1,000 queries, the cheapest option around, and it makes sense when you already run an extraction layer and just want to shave the cost of one more call.
-
Web Search APIs run that extraction for you, so the model gets content it can read right away. Tavily costs $0.008 per credit PAYG basic search and pulls the answer out for you, with
include_raw_contentand/extractavailable when you need raw HTML alongside results. Brave costs $5 per 1,000 requests and serves clean JSON from an index it owns outright, and it came out fastest in AIMultiple's benchmark at 669ms, with Tavily close behind at 998ms. -
Semantic Search APIs go by meaning instead of keyword matching. Exa built its index on neural embeddings, so a question like "companies in San Francisco using assembly language for embedded systems" turns into a vector and comes back with pages that fit the idea, even if those exact words never show up. The same design has a downside. An embeddings index rewards conceptual closeness and gets weaker on freshness, so for breaking news a keyword engine usually wins.
-
Synthesis APIs pull retrieval and reasoning inside the API itself. Perplexity's Sonar runs a live search and hands back a written answer with inline citations, so the agent gets a finished paragraph instead of a stack of documents to read. The price you pay is speed, since Perplexity averaged over 11 seconds per query in the benchmark, which takes it off the table whenever someone is waiting on a response.
-
Content Extraction APIs roll search and full-page scraping into one call. Firecrawl's /search endpoint takes a query and returns the full markdown of each matching page, no separate scraper required. Snippets have a habit of cutting off right before the part you need, so where a snippet might tell you a regulation changed, the full page tells you what changed, when it took effect, and what the old wording said.
The 6 Best Search Tools for Your AI Agents in 2026
AIMultiple benchmarked eight search APIs across 100 real-world AI and LLM queries in 2026, scoring each on relevance, latency, and result quality. Higher agent scores are better.
| Tool | Agent score | Latency | Free tier | Pricing |
|---|---|---|---|---|
| Brave Search API | 14.89 | 669ms | No (removed Feb 2026) | $5/1K queries |
| Firecrawl | 14.58 | ~1,335ms | 1,000 credits/mo | $83/mo (Standard, 100K credits) |
| Exa | 14.39 | Sub-425ms (Exa Fast) | 1,000 req/month | $7/1K searches |
| Parallel | 14.21 | ~13.6s | Limited | Custom |
| Tavily | 13.67 | ~998ms | 1,000 credits/month | $0.008/credit PAYG basic search |
| Perplexity Sonar | Below top tier | 11+ seconds | 100 queries/day | Varies by model |
| SerpAPI / Serper | Below top tier | Fast | 2,500/month (Serper) | $0.30–$1/1K queries |
1. Firecrawl
Firecrawl is the context API to search, scrape, and interact with the web at scale: it runs a web search and gives you back the full, cleaned content of each result in one call. It was designed for RAG pipelines and research agents that need entire documents instead of snippets.
Firecrawl stands out for its /search request. Unlike the other tools here, Firecrawl's search endpoint can return both the ranked results and, if you ask for it, the full markdown of each page in a single call so your search and scraping calls are combined into one step where most tools need two.
Here are some of the features that make Firecrawl a great pick:
Search and extraction in a single call
Firecrawl's search endpoint handles both search and scrape at the same time. If you pass scrapeOptions in testing, the cleaned markdown comes attached to each result, which means fewer calls and simpler code.
Queries that carry context
An agent usually knows far more about what it is searching for. Firecrawl's context parameter lets the agent spell out its actual goal, so the index can rank for intent rather than raw keyword overlap.
Extraction without selectors
You describe what you want in plain English, something like "get the product name, price, stock status, and customer reviews," and the extraction engine pulls exactly that back. There are no CSS selectors or XPath to babysit, and when a site reshuffles its HTML the extraction keeps working because it's the model filtering out the data.
One API across the whole web-data loop
Firecrawl is really a set of surfaces that cover an agent's entire path through the web, not a single endpoint. Alongside search you get scrape for turning any URL into clean markdown, crawl for whole sites without a sitemap, map for laying out a site's structure fast, and a parse step for pulling text out of PDFs and documents.
For the harder jobs there is interact, which automates browser actions like clicking buttons and filling forms, and the agent endpoint, which navigates sites that bury content behind "Load More" buttons or infinite scroll. The agent runs an intelligent waterfall, trying fast retrieval first and only escalating to deeper research when a page actually demands it.
Open source and self-hostable
The core is fully open-source and can be self-hosted, which matters for teams with data-residency rules, security constraints, or cost targets at scale. It also ships as an official Claude plugin and a CLI with a built-in Claude skill, so it drops into terminal and agent workflows without much glue code.
Pros:
- Posted the highest mean relevance score, 4.30 out of 5, and the best deep-retrieval result in the AIMultiple benchmark.
- A flat 1 credit per basic page keeps simple scraping costs predictable.
- Its curated, freshness-monitored index leans on authoritative sources rather than stale pages.
Cons:
- Turning on AI extraction multiplies your credit burn more credits.
- At roughly 1,335ms it is slower than Brave and Exa in the benchmark.
- The firecrawl_search tool on its own returns only titles and descriptions, so you need the scrape and extract tools for the full payload.
Pricing:
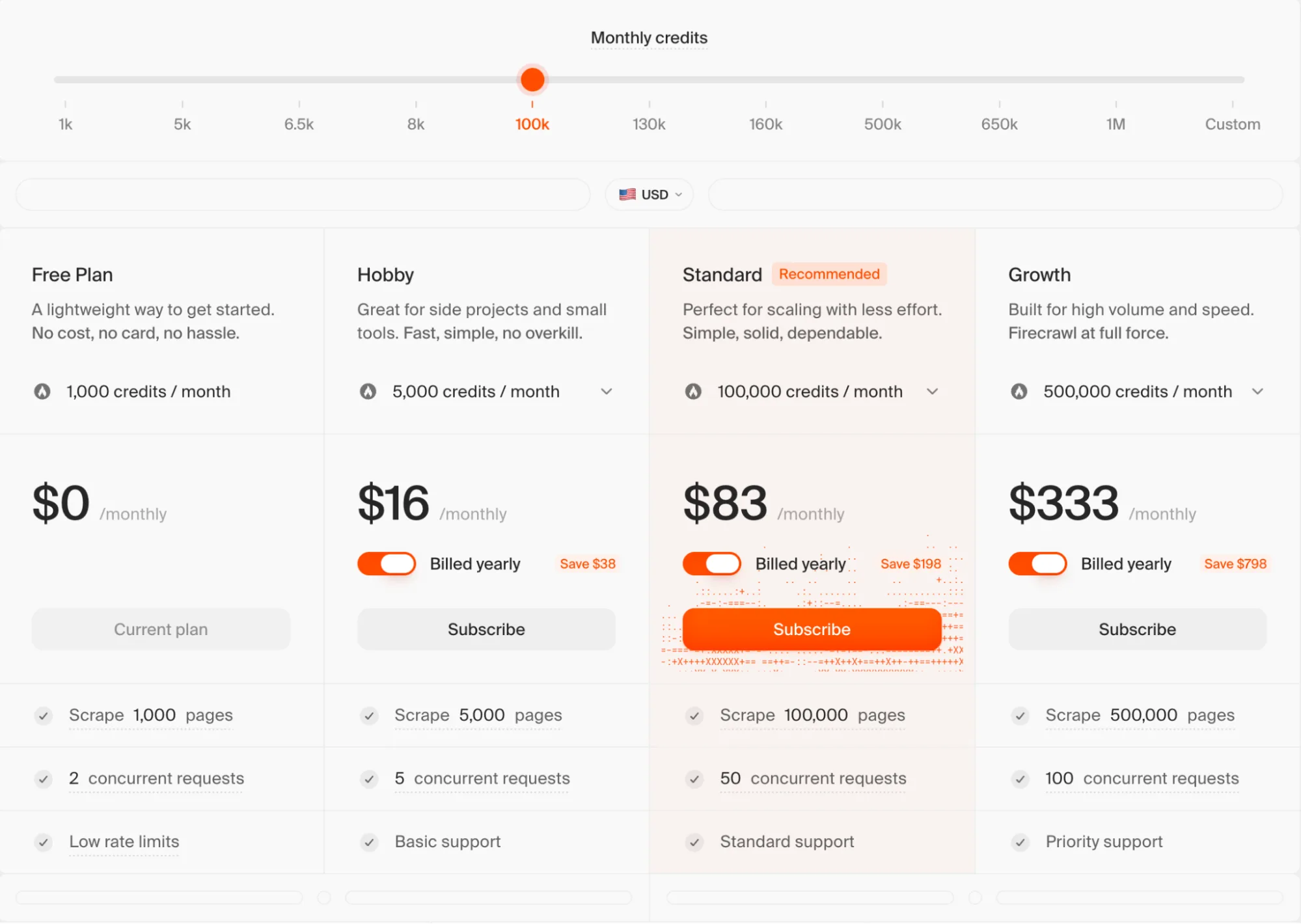
- A free tier of 1,000 credits per month.
- Hobby at $16/month for 5,000 credits.
- Standard at $83/month for 100,000 credits.
- Growth at $333/month for 500,000 credits.
Best for: RAG pipelines that need full-page content, document-heavy research agents, and any job where the snippet keeps cutting off right before the part you actually wanted.
2. Exa
Exa is a semantic search API built on a neural-embeddings index, so it finds results by meaning rather than by counting keywords. It works best for research agents whose queries spell out intent in plain language.
What makes Exa different is that it encodes your whole query as a vector. I ran a few intent-heavy queries through it for this piece, things like "recent criticism of transformer attention mechanisms from a hardware efficiency perspective," and it came back with pages that matched the idea even when none of those exact words showed up on them.
Key features:
- Retrieval modes: Neural, keyword, and auto in one API, so you match by meaning or drop to exact strings like error codes.
- Contents API: Pulls page text, highlights, and AI summaries when a snippet is not enough.
- Domain filters: More than 1,200 of them to scope a search to sources you trust.
- LangChain integration: A ready ExaSearchRetriever through langchain-exa.
Pros:
- Turns up semantically relevant pages that keyword search misses completely.
- It is one of the fastest providers that run their own index, since the ones wrapping Google bottom out near 1,000ms.
- Auto mode quietly falls back to keyword matching for exact strings like error codes or function names.
Cons:
- A smaller index than Google's means recent or niche pages can be thin or missing, so a story published this morning might not show up yet.
- It returns links and snippets, so full content takes separate Contents calls.
- Usage-based pricing climbs fast on high-volume workloads.
Pricing:
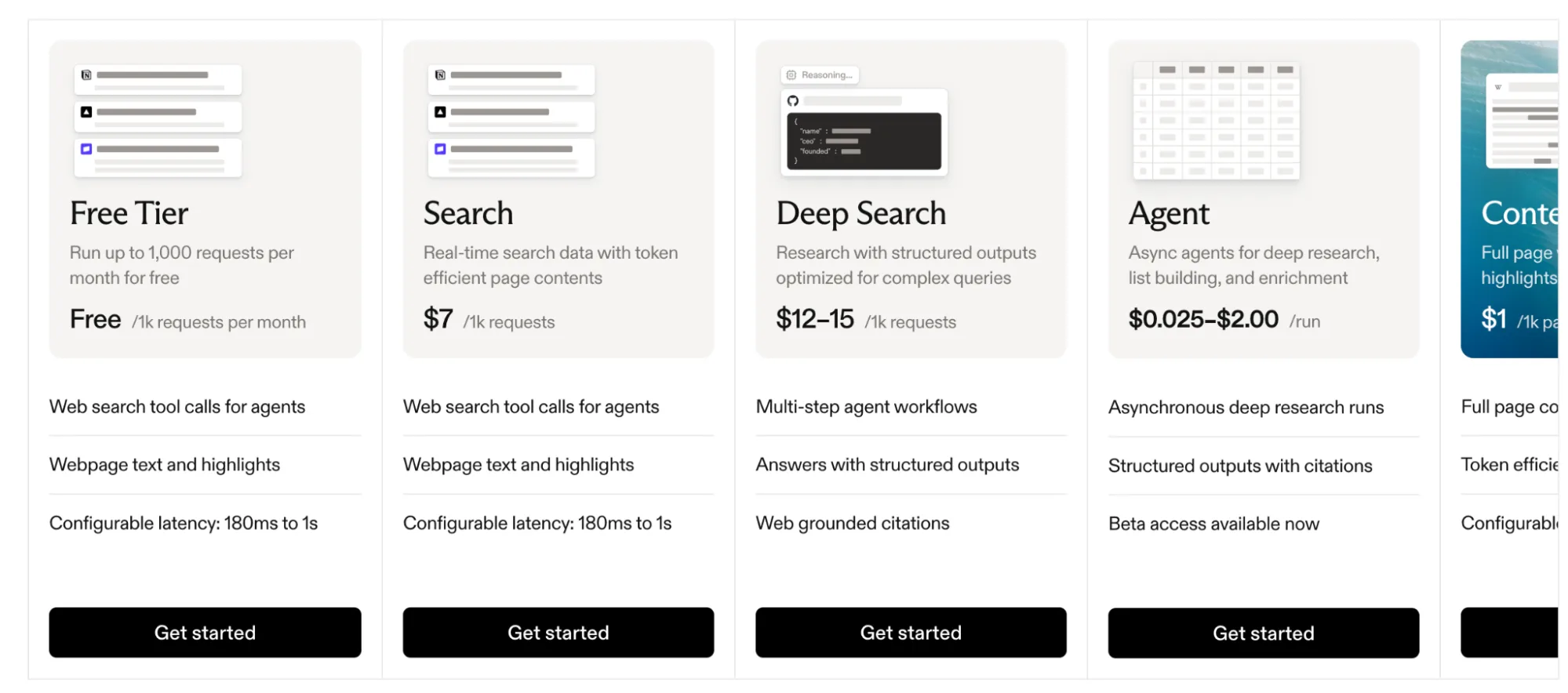
- A free tier of 1,000 requests per month.
- Standard search at $7 per 1,000 (raised from $5 in March 2026).
- A separate Agentic tier for agent workloads.
- Contents retrieval billed on top of search.
Best for: Research agents, concept-driven discovery, and anything where the queries are natural-language-heavy and built around intent.
Watch out for: Exa's docs show that full page content comes back through separate Contents API calls rather than in the initial search response, so every result you want to read costs an extra round trip. Running its own index also means recently published or niche pages can be missing, so test coverage on a news-heavy sample before you rely on it.
3. Tavily
Tavily is a web search API built specifically for agents. It returns relevance-scored, pre-cleaned results along with an optional extracted answer, and it has become the go-to search tool in most LangChain agents. When you need full-page content, /search supports include_raw_content to return it inline, and a dedicated /extract endpoint handles targeted extraction.
Tavily's real edge is how little work it takes to wire up. Dropping it into a LangChain agent took me just about three lines, and it carries a wide documentation footprint so almost every question is answered well.
Key features:
- Scored results: Relevance-ranked results with an optional include_answer field for a quick extracted answer.
- Search depth: A search_depth setting that trades latency for broader source coverage on multi-document questions.
- Query controls: Options like topic and include_raw_content for news, finance, and markdown output.
- Multi-endpoint platform:
/search,/extract,/crawl,/map, and/researchcover search plus content workflows in a single API. - Safety layer: Built-in screening for PII and prompt-injection content before results reach your model.
Pros:
- Took 5 of 8 categories in an independent head-to-head benchmark on speed and relevance.
- A flat $0.008 per credit PAYG basic search makes spend easy to predict.
- Native integrations across LangChain, LlamaIndex, and CrewAI.
Cons:
- The Nebius acquisition brings roadmap uncertainty, more on that under Watch out for.
- It scored 13.67 in the AIMultiple benchmark, a notch below the top tier.
Pricing:
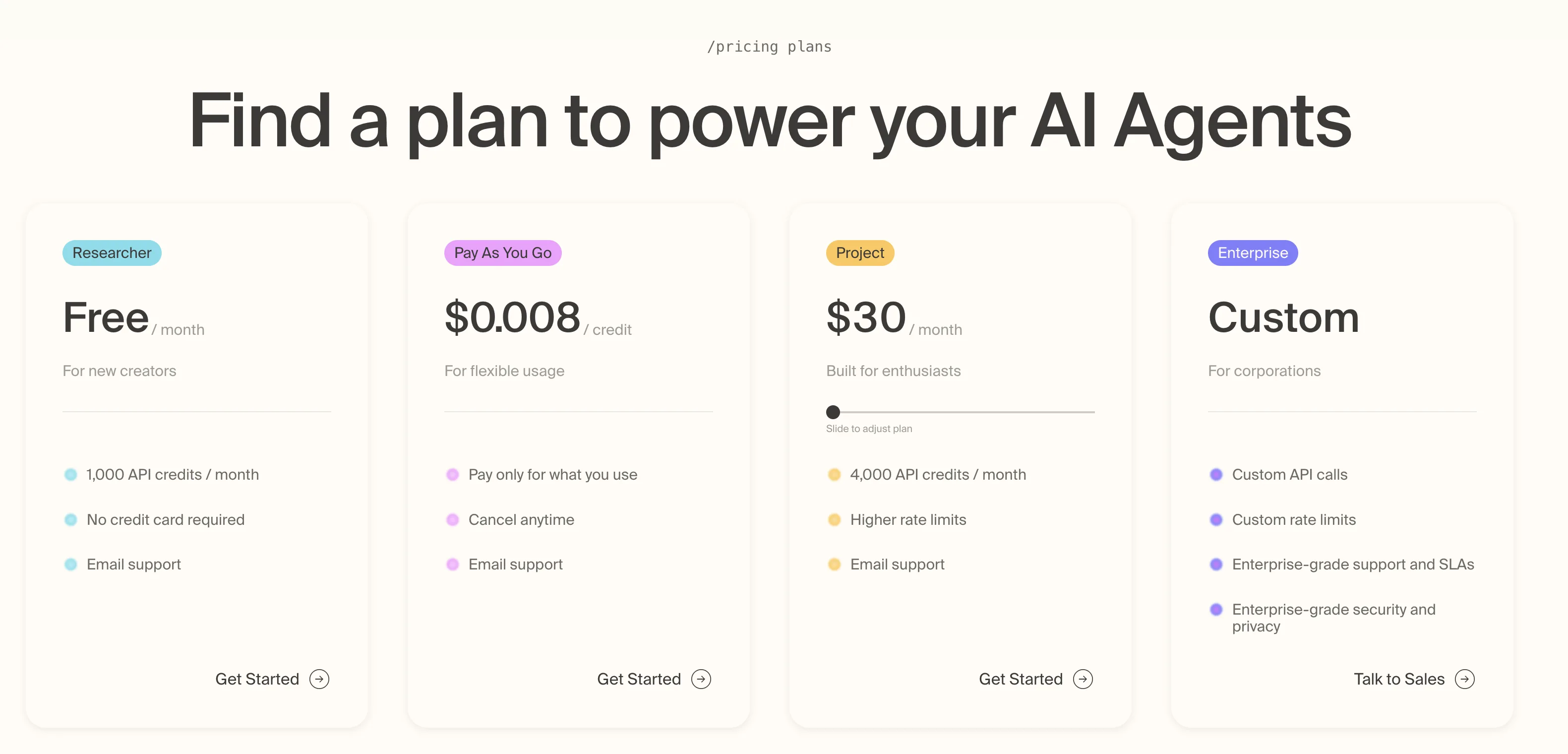
- A free tier of 1,000 credits per month.
- PAYG basic search at $0.008 per credit.
- Paid tiers from around $30/month.
Best for: AI search and research workflows, especially LangChain and LlamaIndex pipelines that want drop-in search plus optional raw content or extraction from the same platform.
Watch out for: The Nebius acquisition. Nebius announced the deal on February 10, 2026 and is folding Tavily in as the agentic-search layer of its enterprise AI cloud, which tilts the roadmap toward big accounts like its existing customers IBM and Cohere. Pricing and direction are still shaking out, so check the current terms before you build a product on the free tier.
4. Brave Search API
Brave Search API runs against Brave's own independent index of roughly 30 billion pages, so your queries never touch Google or Bing. It fits privacy-bound deployments and latency-sensitive agents.
The feature that sets Brave apart is Goggles, a small re-ranking language that lets you boost, downrank, or filter results by URL pattern right at query time. Neither Google nor Bing hands that kind of control to API users.
Key features:
- Independent index: Around 30 billion pages crawled by Brave, never routed through Google or Bing.
- Goggles: Re-ranking rules applied at query time to boost, downrank, or filter results by URL pattern.
- Vertical endpoints: Web, news, video, and an LLM-context endpoint in one API.
- Rate-limit controls: Response headers like X-RateLimit plus explicit Api-Version pinning for stable production behavior.
- Clean JSON: Structured responses with optional snippets sized for LLM context.
Pros:
- The lowest latency in the benchmark at 669ms.
- The only API that beat Tavily by a margin big enough to mean something.
- Its independent index keeps results clear of Google's ranking habits.
Cons:
- Coverage on niche technical content runs narrower than Google-proxied APIs.
- It returns SERP-style JSON, so a RAG pipeline tacks on a separate extraction step.
- Metered billing with no spending cap, flagged under Watch out for.
Pricing:
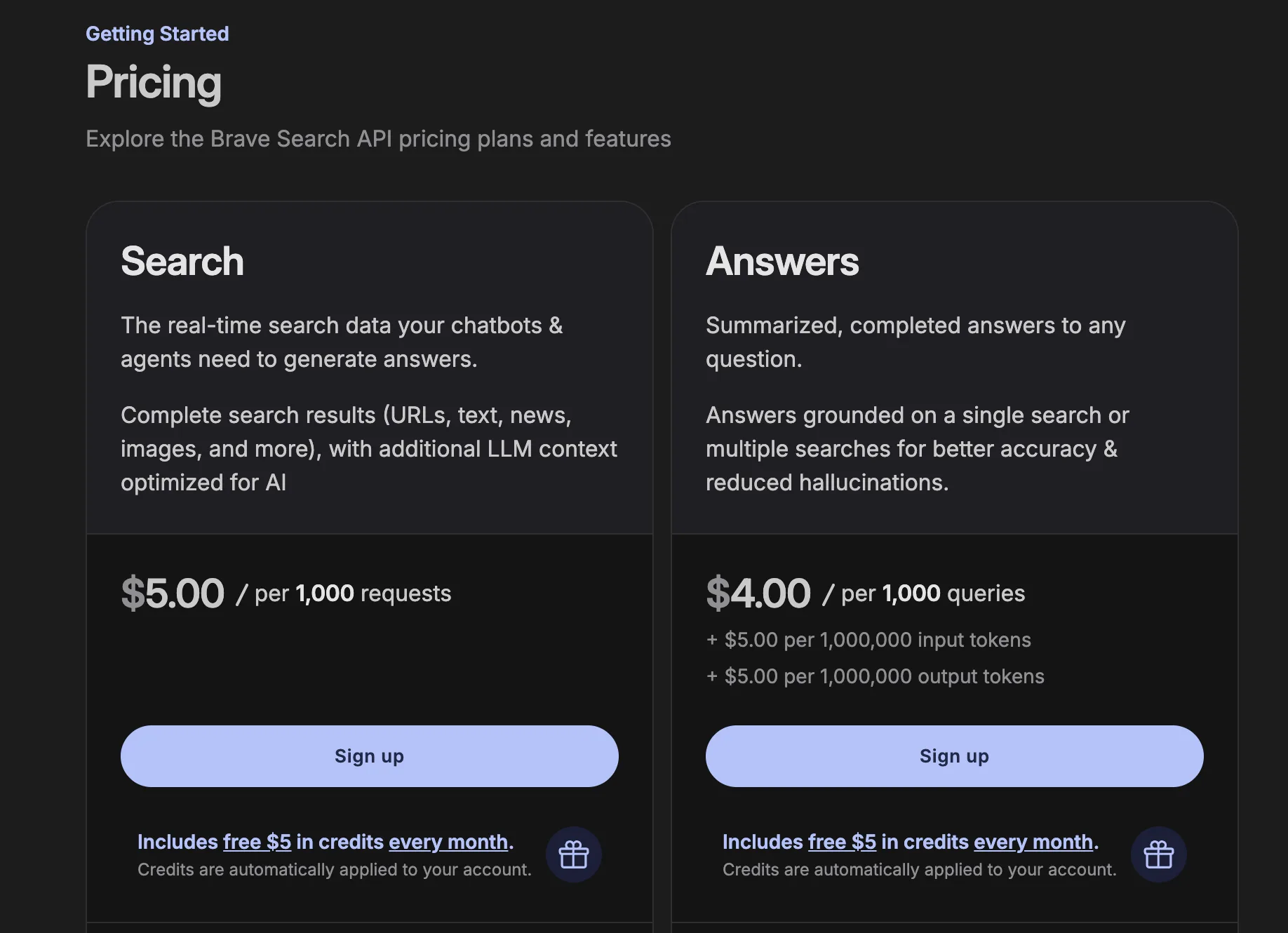
- $5 in monthly credits (~1,000 queries), with no standalone free tier since February 2026.
- Search at $5 per 1,000 requests, up to 50 requests per second on Pro AI.
- Answers at $4 per 1,000 queries plus token charges.
Best for: Privacy-first apps, GDPR-sensitive deployments, and latency-constrained high-volume workloads.
Watch out for: Metered billing with no spending cap. Brave removed its standalone free tier and now keeps a billable card on file from signup, charging you the moment your $5 monthly credit, about 1,000 queries, runs dry.
The rate-limiting docs run a 1-second sliding window that throws a 429 when you burst past it, and free-credit keys are capped at 1 query per second, so any real production traffic needs throttling and volume alerts.
5. Perplexity Sonar

Perplexity Sonar is a synthesis API. It runs a live web search and returns a written, cited answer instead of a list of results, and the endpoint speaks OpenAI's Chat Completions format.
What makes Sonar stand out is that retrieval, reasoning, and citation all happen inside one OpenAI-compatible call. I pointed an existing OpenAI client at it for this piece, swapped the base URL and the model name, and it ran without any other changes.
Key features:
- Model lineup: Models spanning sonar, sonar-pro, sonar-reasoning-pro, and sonar-deep-research for different speed and depth needs.
- OpenAI-compatible endpoint: A drop-in base URL at https://api.perplexity.ai for any chat-completions client.
- Inline citations: A citations array on every response so answers stay traceable.
- Domain filter: A search_domain_filter to constrain the candidate sources.
- LangChain integration: The langchain-perplexity package for agent pipelines.
Pros:
- Folds search, synthesis, and citation into a single call.
- A two-line move from any OpenAI chat-completions client.
- Domain filtering tightens up citation quality.
Cons:
- It averaged 11+ seconds per query in the benchmark, fine for an overnight job but it'd feel like forever in a chat box where users leave after a second or two.
- It landed below the top tier on result quality.
- You get limited visibility into how it picks sources, detailed under Watch out for.
Pricing:
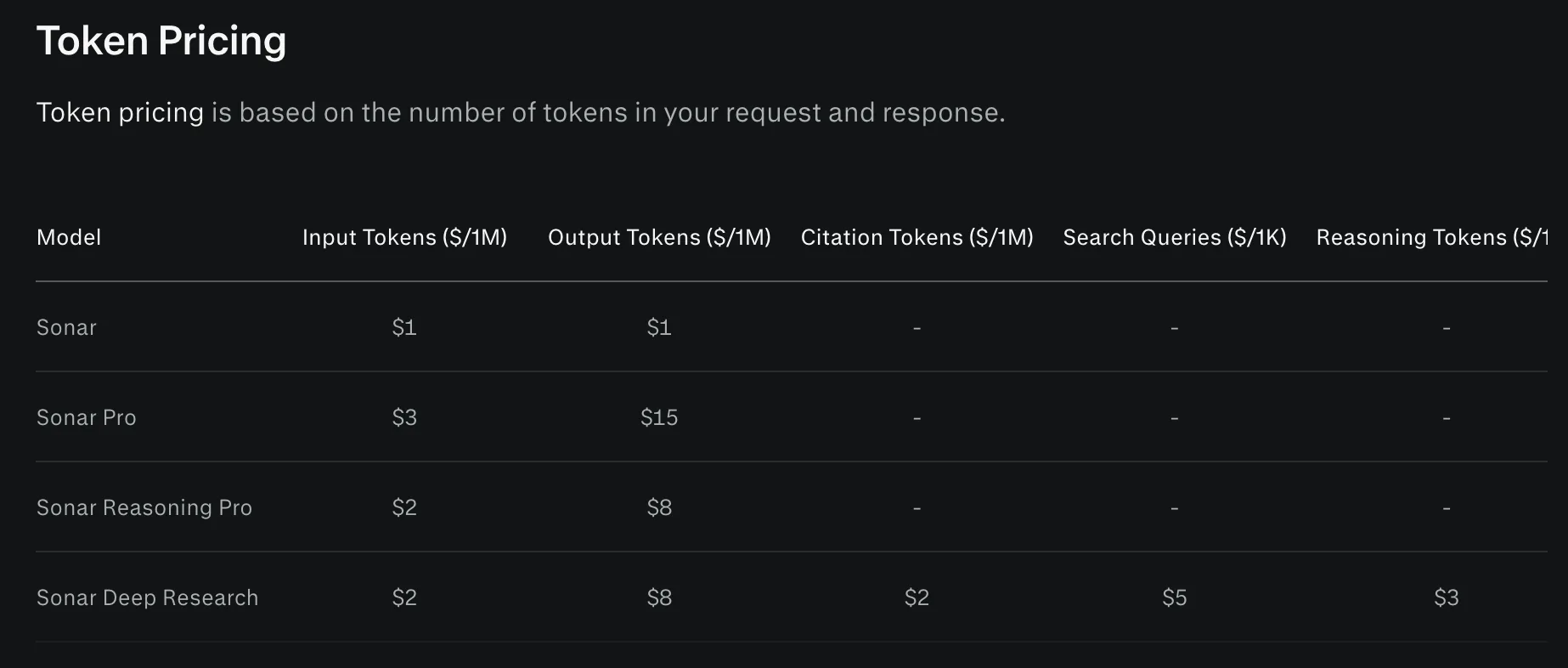
- A free tier of 100 queries per day.
- Token-based rates plus a per-request search-context fee (Low, Medium, High).
- Rate-limit tiers that scale by lifetime credit purchase (Tier 0 through 5).
Best for: Batch research, async pipelines, and cases where you want a cited answer without building your own retrieval and synthesis layer.
Watch out for: Limited source transparency and tiered limits. Perplexity's changelog notes that since April 18, 2025, Sonar Pro and Sonar Reasoning Pro stopped reporting citation-token counts and the number of search results in the API usage field.
So the response will not tell you which sources got weighted, even though search_domain_filter still lets you scope the candidate set. Rate limits also scale by how much you have spent over the life of the account, Tier 0 through Tier 5, so steady production volume keeps pushing you up the tiers.
6. Serper
Serper hands you back raw search-engine results pages as JSON from Google.
The pull here is the API pricing. It's almost like buying queries wholesale because you pay just $1/1000 queries and the price goes lower as you commit to higher monthly pricing plans.
Key features:
- Raw SERP JSON: Titles, URLs, snippets, and knowledge panels straight off the results page.
- Engine coverage: Serper focuses on Google, but you can always pick SerpAPI (a competitor) that covers 40 search engines.
- Playground: A console for testing calls before you write any code.
- No extraction layer: The response stops at the SERP, so page fetching and cleanup stay in your pipeline.
Pros:
- The cheapest raw signal once you are at scale.
- Super quick as they do not run any processing on the server
- Detailed docs and a playground which makes it easy for devs to build products around Serper.
Cons:
- No page extraction, so fetch, parse, and chunk all stay on your side, covered under Watch out for.
- Unused monthly calls do not roll over.
- It parses search results pages only, not arbitrary URLs.
Pricing:
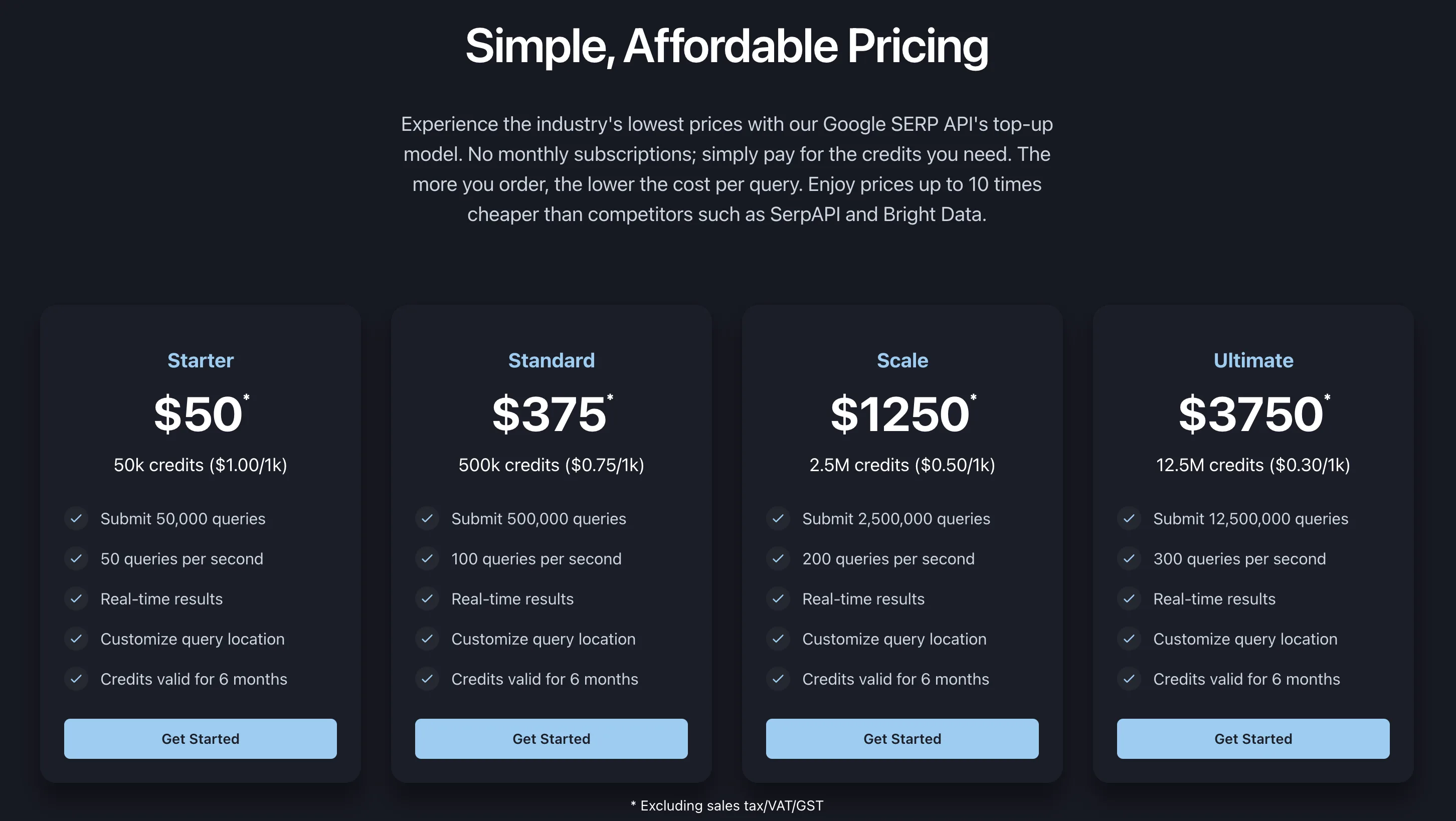
- Serper gives 2,500 free queries, then from ~$1 per 1,000 queries on the $50/month plan
Best for: High-volume workloads that already have an extraction layer, and teams that want one integration spanning several search engines.
Watch out for: The missing extraction layer. SerpApi describes itself as a SERP-parsing API that returns structured results from search engines, not full page content, so fetching, cleaning, chunking, and ranking all stay your pipeline's job on every turn. Standing that layer up (proxies, a headless browser for JS-rendered pages, extraction, retries) eats most of the per-query saving before you ever ship.
How to connect different search tools
Every provider listed here ships official LangChain and LlamaIndex integrations, so moving between them is usually a one-import change. You can prototype with one and swap in another without tearing up the agent.
LangChain
For Firecrawl with Langchain, I wrap it as a custom tool so the agent gets full-page markdown back in a single call.
from langchain.tools import Tool
from firecrawl import Firecrawl
firecrawl = Firecrawl(api_key="fc-YOUR_API_KEY")
def firecrawl_search(query: str) -> str:
results = firecrawl.search(
query,
limit=5,
scrape_options={"formats": ["markdown"]},
)
return "\n\n".join(item.markdown for item in results.web or [])
search_tool = Tool(
name="web_search",
func=firecrawl_search,
description="Search the web and return full page content",
)Output:
[Skip to main content](https://docs.langchain.com/oss/javascript/integrations/tools/webbrowser)
The Webbrowser Tool gives your agent the ability to visit a website and extract information.
[... full page markdown truncated ...]Exa has its own langchain-exa integration with ExaSearchRetriever, and Perplexity ships langchain-perplexity. Brave and SerpAPI both have maintained wrappers in the LangChain community tools namespace as well.
That's to say, you'll not have difficulties connecting either of these search tools within your existing workflows.
CLI
You can also run Firecrawl search directly from the terminal using the Firecrawl CLI.
npx -y firecrawl-cli@latest init --all --browserThen search with:
firecrawl search "your query"Limit results or pull full page content in one command:
firecrawl search "AI agents search tools" --limit 5 --scrape --scrape-formats markdownUsing MCP Servers
Tavily, Firecrawl, Brave, and Exa all publish official MCP servers. Add one to your config and the agent calls it as a native tool, with no integration code to write.
Firecrawl's MCP server exposes the search endpoint directly, so any MCP-compatible agent or LangGraph workflow can call search as a structured tool without you wrapping it.
For most agentic use-cases, this is the easiest route since it requires no more than a few lines of added code.
Wrapping up
You only need to answer a simple question. Do you want to build the pipeline for processing and extraction yourself or do you want the API to handle it?
Based on the answer, you can decide what provider or category of search tools to go with. For most use cases, we recommend search tools with full content extraction and plain SERP data within the same API calls. That's also why we designed Firecrawl to have a combined search and scrape API call. If you are comparing Parallel AI against alternatives specifically, see our Parallel AI alternatives deep-dive, which covers Firecrawl, Exa, Tavily, and Linkup with benchmark data on latency, output consistency, and pricing models.
Frequently Asked Questions
Do AI agents need a search tool if the LLM has a recent training cutoff?
Yes. The cutoff freezes what the model knows on one date, and everything after that simply does not exist for it. The moment your agent touches live prices, new releases, or recent events, it needs search to read what is actually true right now instead of guessing from stale memory.
What's the difference between a SERP API and an AI-native search API?
A SERP API hands you raw browser results: titles, URLs, and short snippets your code still has to clean before the model can use them. AI-native APIs like Firecrawl, Exa, and Tavily skip that grunt work and return results already shaped for a model to read. It really comes down to who does the cleanup, you or the API.
Can I use multiple search tools in the same agent?
Absolutely, and plenty of teams do. A popular combo is Exa to find the right sources by meaning, then Firecrawl to pull the full content from each one. LangChain and LlamaIndex both run multi-tool agents out of the box. Just remember every extra call adds cost and latency, so stack them only when the task earns it.
Which search tool works best with LangChain?
Tavily, if you want the fastest start. The TavilySearch class is about three lines and it is well documented. Firecrawl is the one to reach for when your agent needs full page content back in the same call, with a clean LangChain integration, and Exa and Brave have solid wrappers too. There is no wrong pick here.
How do I keep search costs predictable at scale?
Cap what each query returns with max_results, drop to basic search depth when speed beats coverage, and cache the queries that repeat across runs. Serper and Brave bill flat per-query rates with no multipliers, and Firecrawl's flat one credit per page keeps scraping costs predictable as you scale. Set volume alerts and you are covered.
