TL;DR: Should you use Claude web fetch or Firecrawl?
- Claude web fetch is a free, beta API feature for retrieving static web pages and PDFs. It is perfect for lightweight research where you already have the URL.
- JavaScript rendering remains the primary weakness of Claude's native tool. It cannot 'see' content on modern React, Vue, or Angular applications.
- Firecrawl handles modern web complexities like proxy rotation, agentic web extraction, and full-site crawling out-of-the-box.
- Firecrawl's
/interactendpoint goes further still — it keeps a live browser session open so your agent can click buttons, fill forms, scroll, and log in to extract content that never appears in a static response. - Claude Code's WebFetch is distinct from the server-side API tool, using local Axios calls that add secondary token costs.
- Production readiness requires reliability. For multi-page crawls or structured extraction from dynamic sites, Firecrawl is the recommended engineering path.
Every sufficiently advanced scraper eventually implements its own browser.
This popular axiom in systems programming perfectly captures how web scraping evolves. This quote dates back to the early days when cURL was enough. Then came Selenium, headless Chrome, and eventually managed APIs and headless browser orchestration.
The comparison between Claude web fetch vs Firecrawl for your agentic workflows often comes down to this exact technical boundary. While Anthropic's native tool handles simple static retrieval, it fails at the "eventually implements its own browser" stage and struggles with JavaScript rendering, dynamic URLs, and complex multi-page structures. Firecrawl, by contrast, is purpose-built to navigate these complexities for high-scale web scraping, structured JSON extraction, and autonomous agent workflows.
With this comparison, I'll provide the technical breakdown you need to decide which tool fits your production requirements.
Claude web fetch vs. Firecrawl: What is the difference?
Use this feature breakdown to decide which tool fits your specific agentic use case:
| Capability | Claude web fetch | Firecrawl |
|---|---|---|
| Static HTML pages | ✅ | ✅ |
| JavaScript rendering | ❌ | ✅ (Headless Chromium) |
| PDF extraction | ✅ | ✅ |
| Structured JSON | ❌ | ✅ (Schema-based) |
| Full-site crawling | ❌ | ✅ (/firecrawl:crawl) |
| URL mapping | ❌ | ✅ (/firecrawl:map) |
| Interactive browsing (click, fill, navigate) | ❌ | ✅ (/interact endpoint) |
| Proxy rotation | ❌ | ✅ (Managed infra) |
| Auth handling | ❌ | ✅ (Browser Sandbox) |
| Cost model | Token-based | Credit-based (Predictable) |
What is the Claude web fetch tool?
The Claude web fetch tool is a server-side API feature that allows Claude to retrieve full text content from specified URLs and PDFs during a conversation. Anthropic released this tool in beta in late 2025.
It functions by including the tool in your API request, passing a URL, and letting Claude autonomously fetch the page content. The latest web_fetch_20260209 version supports Claude Opus 4.6 and includes dynamic filtering to reduce token consumption by stripping irrelevant metadata before content hits the context window.
What are the limitations of the Claude web fetch tool?
While convenient, the native fetch tool has several hard limits that frequently break production agent workflows:
- No JavaScript rendering: The tool only fetches the initial HTML. Pages built on React or Vue return an empty shell.
- No dynamic URL construction: Claude can't generate and fetch a new URL. It only accesses links already present in the conversation history.
- Prompt injection risks: Injected content in a user message can trigger unintended fetches. Anthropic recommends using
allowed_domainsas a critical safety mitigation. - Zero handling for complex sites: The tool can't handle JavaScript-heavy pages, login walls, or navigate multi-page structures.
This is what Anthropic's official documentation says about the Claude web fetch tool's limitations:
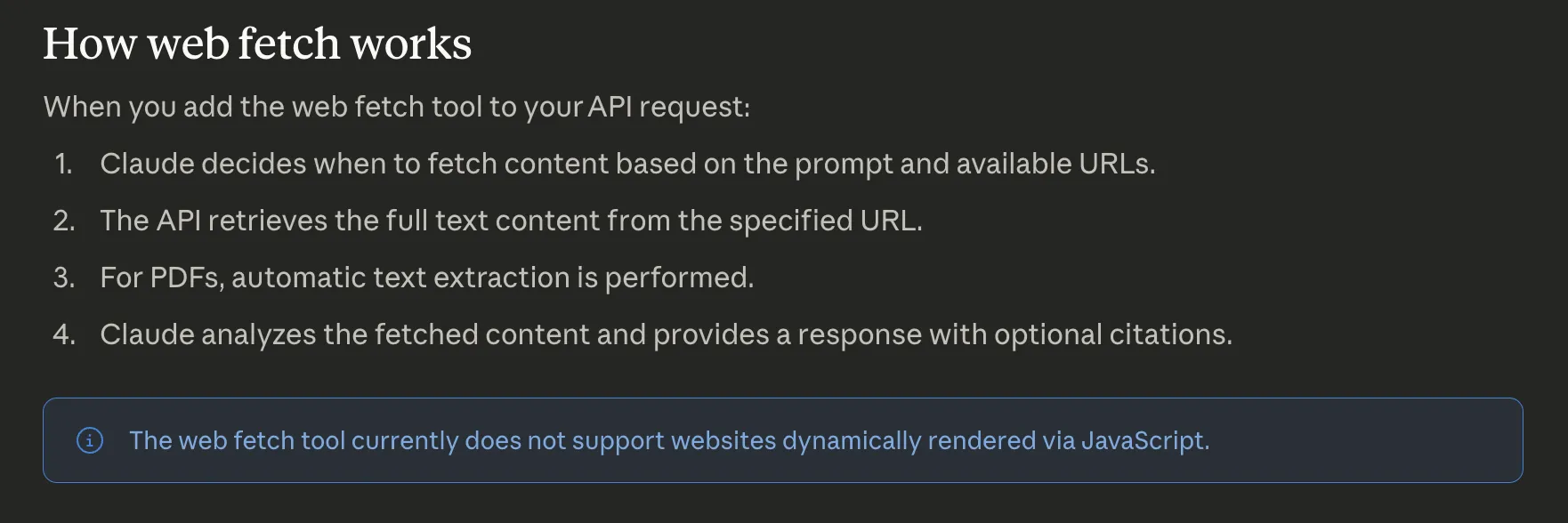
How does web fetch work in Claude models?
In a typical research pipeline, the harness uses a "search-then-fetch" pattern. First, web_search finds relevant URLs. Then, web_fetch pulls the full content from specific results. This works well for static documentation and PDF analysis.
The official documentation defines four parameters for the tool:
max_uses: Limits fetches per request.allowed_domains: Restricts accessible URLs for safety.max_content_tokens: Controls how much text enters the context window.citations: Enables source attribution in the model's response.
How can you use the Claude web fetch tool in your workflows?
The simplest option requires no setup at all. Web fetch is enabled by default in the Claude web app, Claude desktop app, and Claude Code CLI — just paste a URL into your prompt and Claude will fetch it automatically. No API keys, no tool configuration, no code.
For programmatic control, you can implement a basic fetch loop using the Python SDK. This approach works for simple research tasks where site structure is predictable.
import anthropic
from dotenv import load_dotenv
load_dotenv()
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
messages=[
{
"role": "user",
"content": "Summarize the content at https://docs.firecrawl.dev/introduction"
}
],
tools=[
{
"type": "web_fetch_20260209",
"name": "web_fetch",
"max_uses": 5,
"citations": {"enabled": True}
}
]
)
for block in response.content:
if getattr(block, 'text', None):
print(block.text)You can see Claude fetches the full page content as markdown and provides you with a response.
Here's a summary of the Firecrawl introduction/quickstart page:
***
## 🔥 What is Firecrawl?
Firecrawl allows you to turn entire websites into LLM-ready markdown.
It provides a powerful API for web scraping, searching, and browser automation.
***
## 🚀 Getting Started
You can get started by calling the API directly without a key to try it, then add one for higher rate limits. You can also try it instantly in the Playground without writing any code, or sign up for a key when you scale.
The Firecrawl skill is the fastest way for agents to discover and use Firecrawl, and can be installed via a simple CLI command.
You can also use the MCP Server to connect Firecrawl directly to Claude, Cursor, Windsurf, VS Code, and other AI tools.
***
## ✅ Why Firecrawl?
Key benefits include:
- LLM-ready output: Clean markdown, structured JSON, screenshots, and more
- Handles the hard stuff: Proxies, JavaScript rendering, and dynamic content
- Reliable: Built for production with high uptime and consistent results
- Fast: Results in seconds, optimized for high-throughput
- Browser Sandbox: Fully managed browser environments for agents, zero config, scales to any size
- MCP Server: Connect Firecrawl to any AI tool via the Model Context Protocol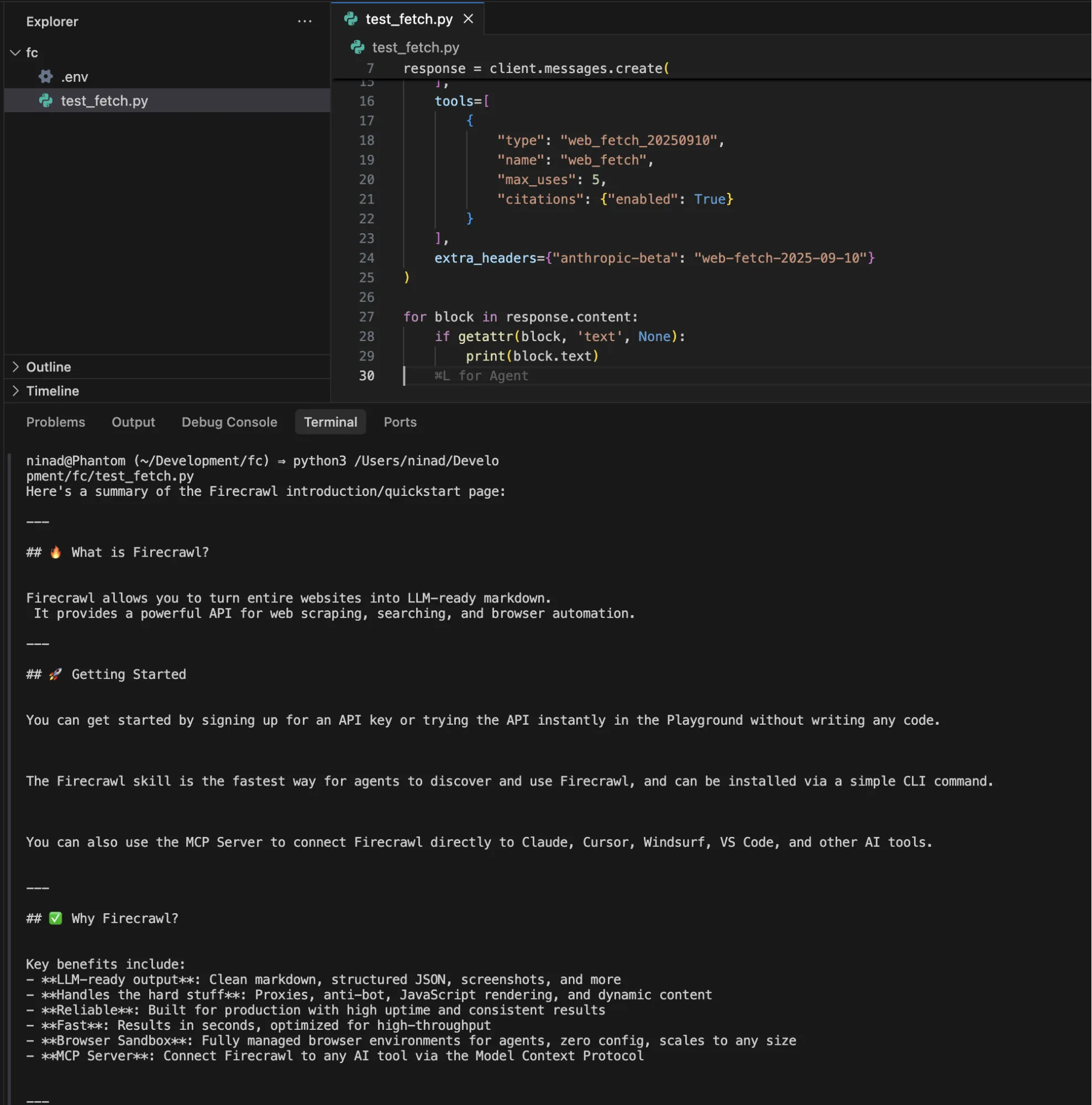
For workflows that combine discovery and retrieval, pair it with web_search:
tools=[
{"type": "web_search_20260209", "name": "web_search", "max_uses": 3},
{
"type": "web_fetch_20250910",
"name": "web_fetch",
"max_uses": 5,
"max_content_tokens": 50000
}
]The code works well for pulling static documentation into context before coding, summarizing research papers from known URLs, analyzing blog posts or changelogs referenced by a user, and PDF text extraction for reports or contracts.
As I'd already mentioned in the limitations, our fetch tool code will break if:
- A site loads content via JavaScript after the initial HTML response
- The URL is behind a login wall
- The link has multi-page crawl requirements
- Any domain that returns
url_not_accessibleorurl_not_allowederrors
These limitations mean, a meaningful chunk of modern sites won't be fetchable.
Why use Firecrawl with Claude for web extraction
Firecrawl provides a dedicated scraping engine that is faster and more precise than generic fetch tools. It is available as an official Firecrawl plugin in the Claude marketplace.
You can install it directly via the Claude Code CLI:
- Run:
claude plugin install firecrawl@claude-plugins-official- Execute:
/firecrawl:setupto bind your API key.
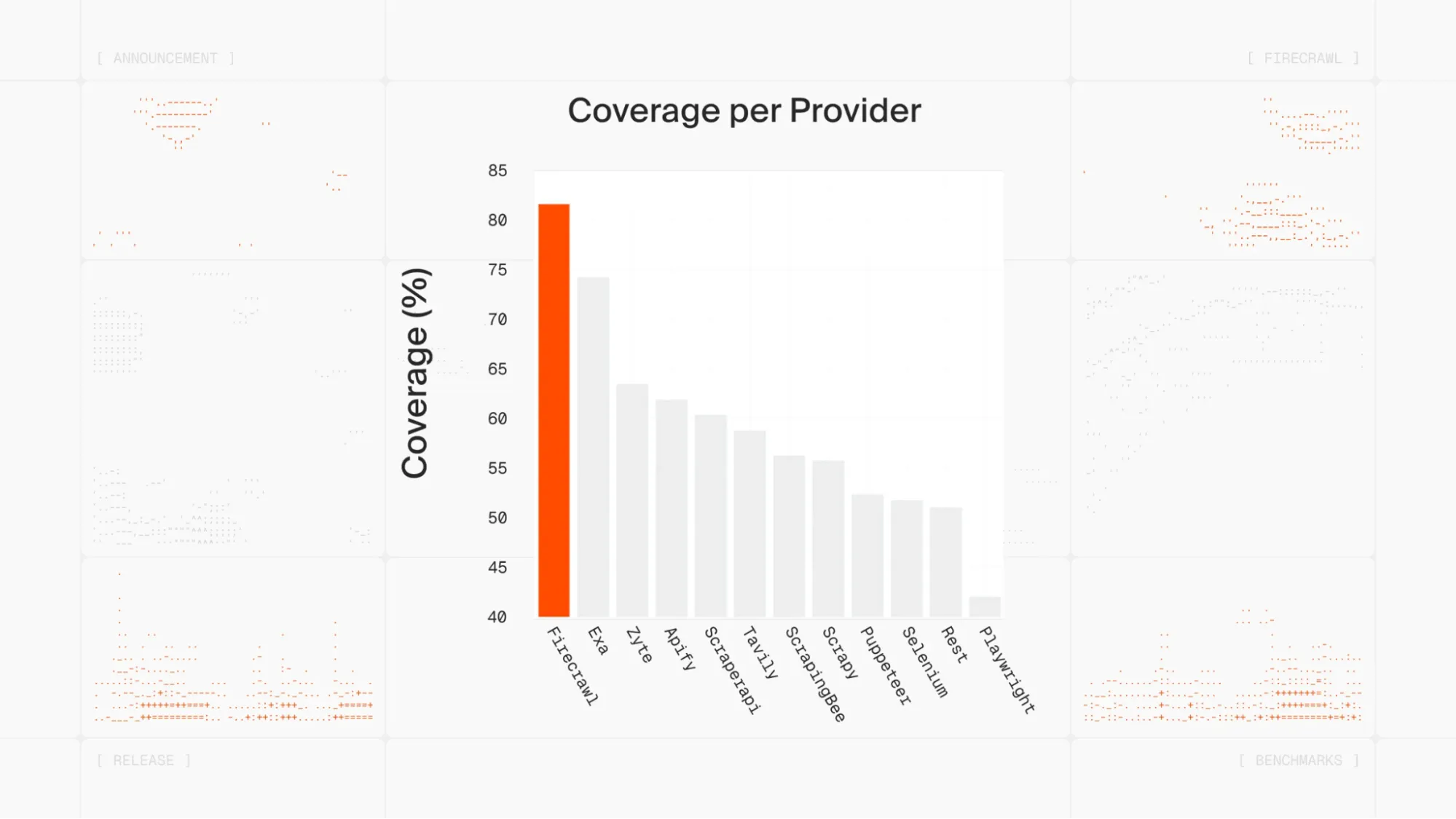
Recent benchmarks show Firecrawl achieving above 80% coverage on internal evaluation sets, significantly outperforming native AI fetch implementations.
Firecrawl is undoubtedly the most powerful web extraction tool available today, especially for AI agents. There's a reason popular tools like OpenClaw use Firecrawl as their web_fetch fallback — when a plain HTTP request fails on a JavaScript-heavy page, Firecrawl catches it and returns actual content using real browser rendering, automatically. That kind of reliability is what makes it the default scraping layer across the ecosystem.
Firecrawl has grown into one of the most widely adopted web extraction tools in the developer ecosystem. More than half a million developers and teams use it every day, including companies like Zapier and Replit. It's also one of the fastest-growing open-source projects on GitHub, with over 130K stars — a signal of how broadly the community has adopted it as the default scraping layer for AI applications.
One user Alex Reibman, wrote on X:
Moved our internal agent's web scraping tool from Apify to Firecrawl because it benchmarked 50x faster with AgentOps."
Which Firecrawl commands work inside Claude?
Once installed, Firecrawl exposes five commands to your agent:
- /firecrawl:scrape: Extracts a single page as clean markdown.
- /firecrawl:crawl: Recursively extracts content from an entire domain.
- /firecrawl:search: Searches the web and returns scraped results in one turn.
- /firecrawl:map: Discovers all nested URLs on a target site.
- /firecrawl:agent: Uses natural language to find and extract data across multiple sites autonomously.
With these five tools, your agent is better capable of crawling and reading through website content. You can prompt it as below:
Use Firecrawl agent to find the most recent research papers on browser automation and reference it in my article on browser automation
Firecrawl navigates, searches, and extracts, handling the multi-step browsing that web fetch just can't do.
The five commands cover most extraction scenarios you'll hit in production. Here's what the full pattern looks like using both SDKs directly: Firecrawl pulls clean markdown from the target page, then hands it to Claude as context.
Going deeper: Firecrawl's /interact endpoint
One capability that has no equivalent in Claude's native web fetch is the /interact endpoint. Rather than fetching a static snapshot, it keeps a live browser session open so you can take actions inside the page after scraping it — clicking buttons, filling forms, navigating pagination, or extracting content that only appears after user interaction. For a full guide to this browser automation API for agents, including scraping-for-agents patterns and code examples, see the dedicated interact endpoint guide.
The workflow has three steps:
- Scrape a URL with
POST /v2/scrape. The response includes ascrapeId. - Interact by calling
POST /v2/scrape/{scrapeId}/interactwith either a natural languagepromptor Playwrightcode. - Stop the session with
DELETE /v2/scrape/{scrapeId}/interactwhen you're done.
Here's a minimal example that searches Amazon and extracts a price. Starting with the CLI:
# Step 1 — scrape the page (scrape ID is saved automatically)
firecrawl scrape https://www.amazon.com
# Step 2 — interact using natural language prompts
firecrawl interact "Search for iPhone 16 Pro Max"
firecrawl interact "Click on the first result and tell me the price"
# Step 3 — stop the session
firecrawl interact stopFor more complex workflows you can pass raw Playwright code instead of a prompt, giving you full programmatic control over the browser. The endpoint also returns a liveViewUrl you can embed as an <iframe> to watch or share the session in real time.
Claude's web fetch has no concept of a stateful browser session. If the data you need is behind a button click, a login wall, or a lazy-loaded tab, /interact is the only path forward.
This is where the two tools divide cleanly. Firecrawl runs the extraction independently, against any URL, handling JavaScript rendering and proxy rotation before your model call ever happens. Claude receives clean markdown instead of raw HTML, which means less noise in the context window and more reliable reasoning over the content.
Pricing and operational limits
Firecrawl uses a credit-based model: 1 credit = 1 scraped page (or 1 PDF page). Crawls, searches, and agent actions all consume credits at the same rate unless advanced features are used.
| Tier | Credits (billed yearly) | Best for |
|---|---|---|
| Free | 1,000/month | Prototyping only |
| Hobby | ~$16/mo | Light production use |
| Standard | ~$83/mo | 100,000 pages/mo |
| Growth | Custom | High-volume pipelines |
A few things worth knowing before you commit to a plan:
- Credits do not roll over month to month on standard plans
- The free tier is 1,000 credits per month, refreshed monthly
- Auto-recharge credit packs do roll over
Claude web fetch has no per-request cost beyond standard token fees, but token consumption is unpredictable on long or complex pages. Firecrawl's credit model makes costs easier to forecast at scale.
You get clean Markdown and structured JSON output which also helps with context engineering. What you feed into an agent's context window directly shapes what it produces, and raw HTML from a basic fetch is far noisier than the filtered, structured content Firecrawl returns.
If you want to go deeper on how Firecrawl fits into Claude workflows, we cover the full setup in our official Claude plugin announcement.
There are also a few other interesting Claude Code plugins you can try if you're building out a broader Claude Code stack.
If you're using OpenAI Codex CLI instead, Firecrawl works there too — via either the MCP server or the Firecrawl CLI skill. Codex's built-in web search returns snippets only, and fetching full documentation pages from Codex hits the same JavaScript rendering wall — both integration paths fix that.
When to stay with Claude web fetch vs Firecrawl
Though I'm writing on the Firecrawl blog, I still have to say that Firecrawl is not always the solution for everyone.
If you're scraping simple static pages like documentation where you already have the URL, extracting text from a PDF, or analyzing a known blog post, Claude's web fetch does the job almost perfectly. You can use the built-in tool and not think about add-ons.
Once you're hitting JavaScript-rendered pages, login walls, or need to crawl more than a handful of URLs, web fetch won't get you there. When those limitations start to hamper your workflows, that's when you need a more robust scraping solution like Firecrawl.
And if the content you need is behind any kind of interaction — infinite scroll, a login form, a multi-step checkout, a lazy-loaded tab — Firecrawl is the clear choice. The /interact endpoint lets your agent click, fill, scroll, and navigate just like a human would, then hand the extracted content back to Claude as clean text. Web fetch has no equivalent for this; it sees only what the server sends on the first response.
Final thoughts on Claude web fetch vs Firecrawl
The native Claude web fetch tool is an excellent entry point for simple retrieval workflows. It is zero-setup and free for API users. But for production agents that need to act autonomously across the modern web, its limitations are a bottleneck.
Firecrawl removes the scraping infrastructure burden, letting you focus on the reasoning logic of your agent rather than proxy rotation or DOM parsing. And with the /interact endpoint, it goes further than any fetch tool can — keeping a live browser session open so your agent can click, scroll, log in, and extract content that never appears in a static HTML response.
If I wanted to make a long-term bet, I'd go with Firecrawl. It's robust, handles most scraping scenarios perfectly, and there's a team of devs working to make the crawling and data extraction experience better every day. For a broader look at how it compares against other AI web scraping solutions, see the full tool comparison.
Ready to give your agent complete web access? Try Firecrawl for free today.
Frequently Asked Questions
What is the Claude web fetch tool?
The Claude web fetch tool is a beta API feature from Anthropic that allows Claude models to retrieve full text content from web pages and PDF documents as part of a conversation. It's enabled via the web-fetch-2025-09-10 beta header and costs nothing beyond standard input token fees for the fetched content.
Does Claude web fetch support JavaScript-rendered pages?
No. The web fetch tool retrieves static HTML from the initial server response. If a page loads its content dynamically via JavaScript, web fetch returns incomplete or empty content. For JavaScript-heavy sites, you need a headless browser-backed tool like Firecrawl.
Can Claude construct URLs to fetch on its own?
No. For security reasons, Claude can only fetch URLs that have already appeared in the conversation context, from user messages, previous search results, or earlier fetch results. This prevents prompt injection exfiltration attacks but also limits how much autonomy an agent has when discovering new URLs.
Is Firecrawl free to use with Claude?
Firecrawl offers 1,000 free credits per month on its free tier, enough for prototyping and testing. Production use requires a paid plan, with the Standard plan at $83/month for 100,000 pages. The Firecrawl Claude plugin and MCP server are free to install.
How do I install Firecrawl in Claude Code?
Run claude plugin install firecrawl@claude-plugins-official in your terminal, then run /firecrawl:setup and add your API key from firecrawl.dev/app/api-keys. The full setup takes about two minutes. Alternatively, add the Firecrawl MCP server directly: claude mcp add firecrawl -e FIRECRAWL_API_KEY=your-api-key -- npx -y firecrawl-mcp.
When should I use web fetch instead of Firecrawl?
Use web fetch when the target page is static, you already have the URL in your conversation, and you need a quick text extraction or PDF summary. Firecrawl is the better choice when you need JavaScript rendering, multi-page crawling, structured JSON output, or autonomous agent-style extraction across multiple sites.
Can Firecrawl work with self-hosted Claude or other LLMs?
Yes. Firecrawl's MCP server and API are LLM-agnostic. They work with Claude, GPT-4, Gemini, and any model that supports tool calling. You can also self-host the Firecrawl backend using Docker by pointing the CLI to a custom --api-url.
What is Firecrawl's /interact endpoint and when should I use it?
The /interact endpoint lets you scrape a page and then take actions inside it — clicking buttons, filling forms, scrolling, or navigating — using either natural language prompts or Playwright code. Use it when the content you need only appears after a user interaction, such as infinite scroll, a login wall, a multi-step form, or a lazy-loaded tab. Claude's native web fetch has no equivalent; it only sees the initial HTML response and cannot interact with the page at all.
