Introducing Question and Highlights: High-Quality Answers from the Web, 100x Fewer Tokens
Getting an accurate answer — or pulling a specific piece of content — from a webpage with an LLM today means scraping the full page, chunking it, running it through your own model, and owning the prompt engineering yourself. Today we're launching two new formats for Firecrawl /scrape that replace all of that with one call:
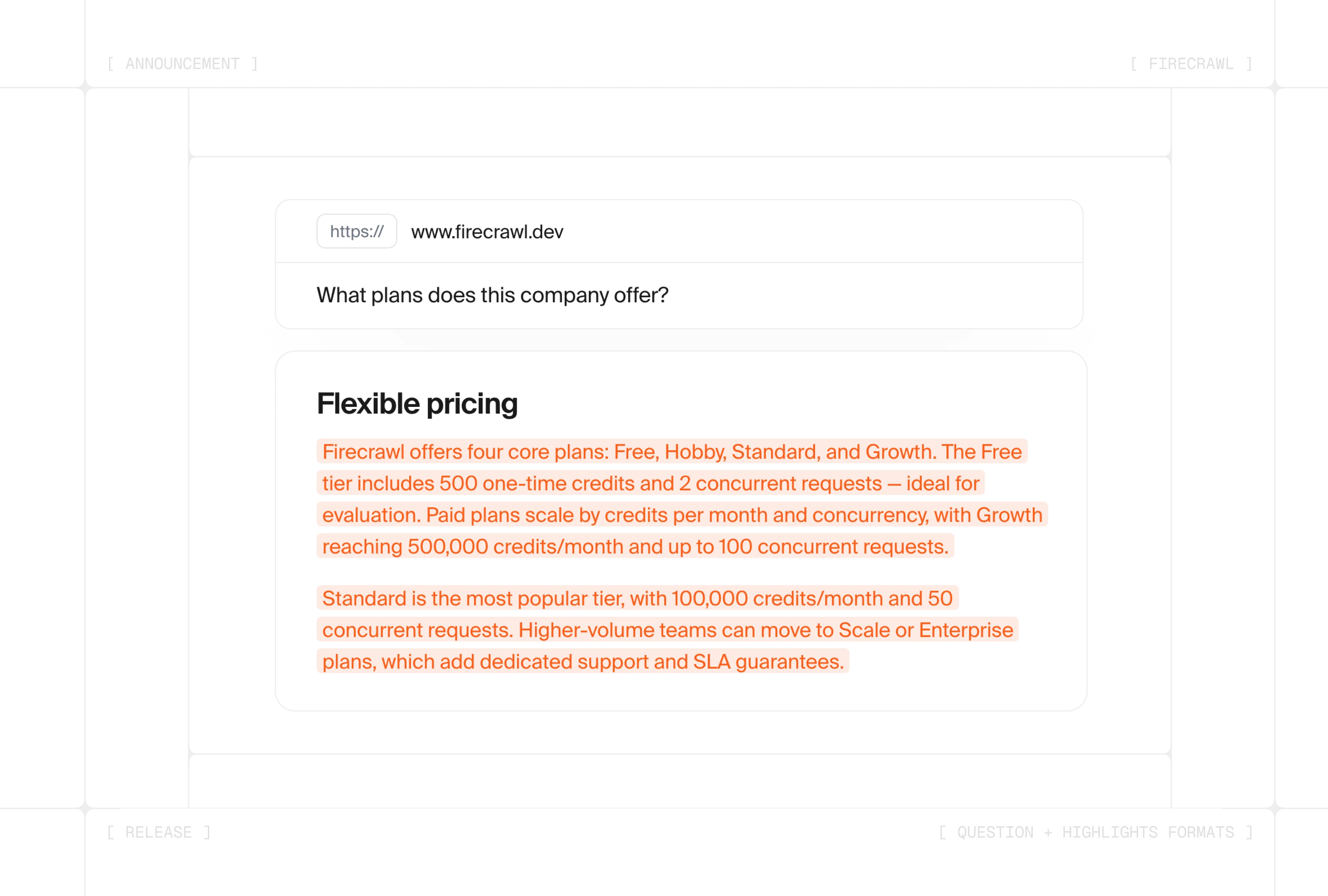
question— Pass a URL and a question, get a grounded answer back.highlights— Pass a URL and a query, get the exact sentences, code blocks, and tables from the page that match it back, verbatim.
Both formats are up to 100x more token-efficient than a full scrape, run on a fully managed LLM stack, and ship with prompt-injection hardening built in.
Question format
question returns a focused, grounded answer drawn directly from the page — no footers, ads, or irrelevant prose crowding your context window. Pass a URL and the question you want answered:
import { Firecrawl } from "firecrawl";
const firecrawl = new Firecrawl();
const doc = await firecrawl.scrape("https://docs.firecrawl.dev/features/scrape", {
formats: [
{
type: "question",
question: "What file formats does /scrape support?",
},
],
});
console.log(doc.question);The answer is synthesized by a managed LLM that's strictly instructed to ground its response in the page content. If the page doesn't contain the answer, the model says so rather than inventing one.
Highlights format
highlights is built for compliance, code extraction, and financial data capture — workflows where the answer is consumed as data and the source attribution needs to be unambiguous. Pass a URL and a query, and Firecrawl returns the exact text on the page that matches it:
const doc = await firecrawl.scrape("https://docs.firecrawl.dev/features/scrape", {
formats: [
{
type: "highlights",
query: "Show me the code example for scraping with markdown format.",
},
],
});
console.log(doc.highlights);A fine-tuned model selects line indices rather than generating prose, and Firecrawl reassembles the relevant text verbatim from sentences, code blocks, and table rows on the page:
- Consecutive sentences from the same block re-join into paragraphs
- Consecutive code lines wrap in fenced blocks with their original language preserved
- Table rows rebuild into markdown tables with headers automatically included
Nothing is rewritten or invented.
Highlights Focus Benchmark
We measure highlights on Focus: how closely a returned snippet matches the ideal passage on the page. A perfect 1.0 means the response is exactly as focused as the ground truth — lower scores reflect either missing content or responses padded with surrounding noise.
Here's how Firecrawl's Highlights format stacks up against Exa Highlights on a 10,000 URL test set:
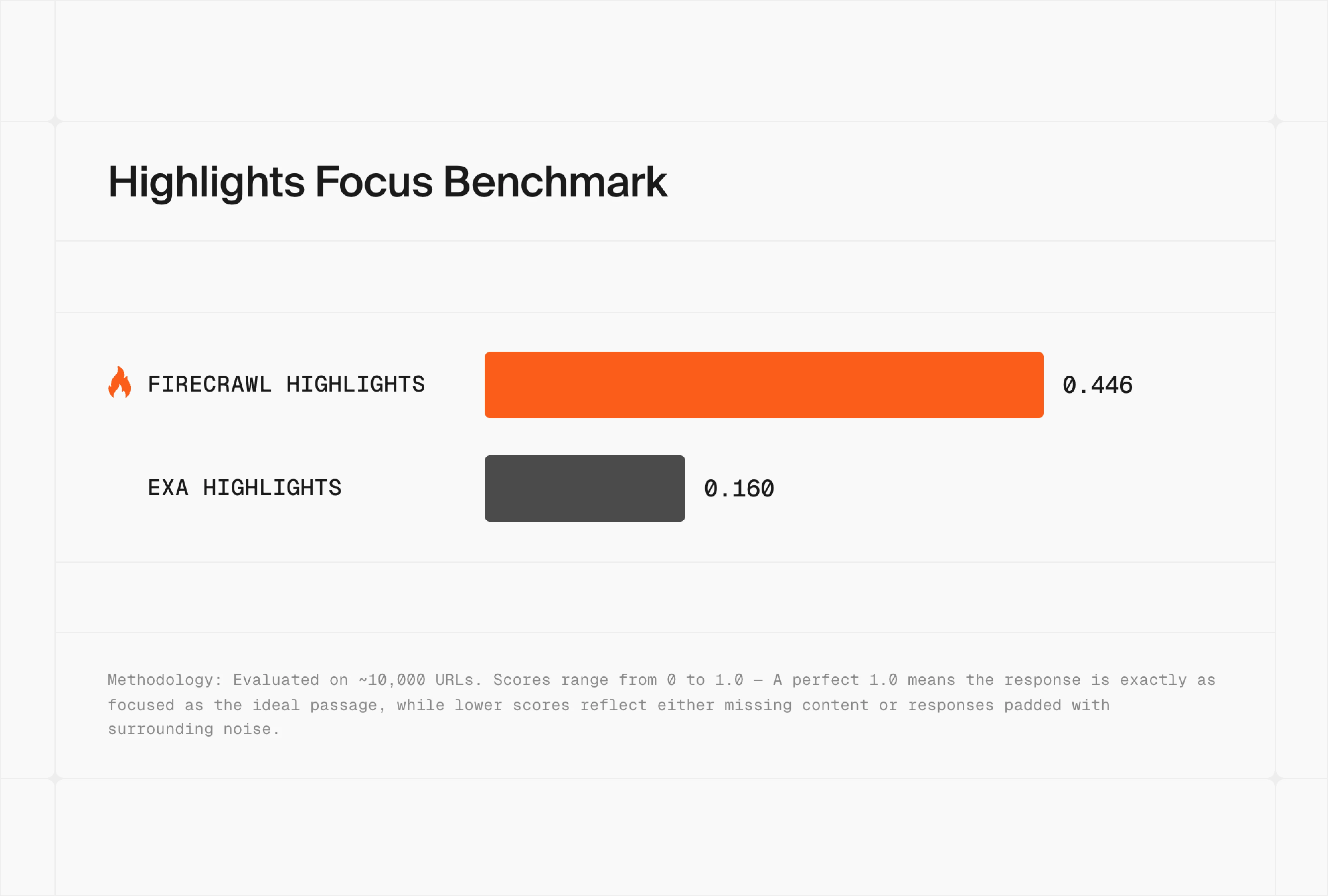
Firecrawl scored 0.446 to Exa's 0.160 — roughly 2.8x more focused. That gap is the difference between an excerpt your agent can drop straight into a citation and one it has to clean up first.
Why these formats matter for agents
Grounded, page-faithful output
question answers strictly from page content — zero hallucinations. highlights goes further, returning exact text drawn from the source. Whether your agent needs an accurate synthesized answer or a citable verbatim quote, both formats keep its output anchored to what's actually on the page.
Up to 100x fewer tokens per call
A standard /scrape call returns the full page as clean markdown (or HTML, JSON, screenshots, and more). question returns just the answer. highlights returns just the excerpts that match. For agents running dozens or hundreds of lookups, that difference compounds fast: lower inference costs, faster responses, and a leaner context window on every request.
A fully managed LLM stack
Firecrawl runs both formats on a managed model chain with automatic fallback and a production-tuned system prompt. The LLM integration, prompt engineering, and retry logic are all handled for you. Tokens and costs roll into the same Firecrawl billing and telemetry you already use for /scrape — one source of truth for usage and spend.
Hardened against prompt injection
Pages can contain text designed to hijack an LLM's behavior. Both formats are built to resist this:
- User prompts and page content are wrapped in distinct XML tags so the model can always tell them apart
- Page content is escaped with zero-width spaces so any embedded XML or instruction-like markup can't break out of its container
- The system prompt marks page content as untrusted and instructs the model to ignore and refuse any instructions embedded in the page
Try them today
question and highlights formats are live for all Firecrawl users.
