
TL;DR: Best Brave Search Alternatives
| Tool | Best for | Standout feature | Free tier |
|---|---|---|---|
| Firecrawl | Full web data stack for AI agents | Search, Scrape, Interact, Crawl — find sources, extract clean context, ship | 1,000 credits/month |
| Exa | Semantic search for research-heavy apps | Embedding-based search that understands meaning | 1,000 credits |
| Tavily | AI search and research workflows | AI-optimized results, include_raw_content and /extract for full content | 1,000 credits/month |
| Parallel AI | Agentic web research at scale | Runs multiple search agents simultaneously | None listed |
| LLMLayer | All-in-one web infrastructure | Search, scrape, crawl, and answers in one API | $2 in free credits |
Brave Search API has earned a loyal following among developers building privacy-conscious search features and AI pipelines. Its independent index, clean pricing, and no-tracking policy make it a compelling default for many teams.
But depending on your use case, you may run into its limits: search snippets without full-page extraction, rate caps on lower tiers, or the need for richer AI-optimized output formats.
We looked at five alternatives that offer different trade-offs, from deep content extraction to semantic search to all-in-one web infrastructure, to help you find the right fit.
What is Brave Search API: quick overview
Brave Search API is a programmable web search service from Brave that lets developers query Brave's independent web index over HTTP and use the results inside their own apps, search experiences, and AI systems.
Unlike search APIs that license results from Google or Bing, Brave crawls and indexes the web itself: over 30 billion pages, updated with millions of new pages daily to capture recent events and fresh content.
Brave, the company behind it, passed 100 million monthly active users in October 2025. Its browser built a reputation on privacy-first browsing (no user tracking, no profile building), and that same philosophy carries into the search API.
Main capabilities:
- Standard web search: URLs, titles, snippets, and metadata from an index of 30B+ pages
- Vertical and rich results: specialized endpoints for news, images, videos, and local results
- AI-oriented output: extra snippets, schema-enriched data, and an "Answers" endpoint that returns summarized, grounded responses with citations, designed for LLMs and agents
- Real-time data: index updated daily to surface recent content
Quick specs:
| Feature | Detail |
|---|---|
| Index size | 30B+ pages |
| Index freshness | Millions of pages updated daily |
| Free tier | $5/month in credits (~1,000 queries) for new users; existing free plan users retain 2,000 queries/month |
| Paid plans | From $5 per 1,000 requests |
| Privacy | SOC 2 Type II certified, no user tracking |
| Rate limits | Up to 50 queries/second (Pro AI plan) |
Best suited for:
Teams that need a lightweight, privacy-respecting search layer integrated into a product where search is a supporting feature, not the core offering. If your app needs to surface relevant links or ground AI responses with fresh web results, and you don't want to build on top of Google or Bing, Brave Search API is a solid starting point.
Why users look for Brave Search API alternatives
| Issue Category | Key Problem |
|---|---|
| Pricing | Free tier removed; new users get ~1,000 queries/month in credits only |
| Search quality | Independent index still maturing; niche query results lag behind Google |
| AI agent support | Agentic workflow features still developing for production use cases |
| Extraction depth | Returns snippets only; no full-page content without a separate scraper |
| Rate limits | Lower tiers cap at 1 query/second, limiting high-throughput apps |
| Output format | Raw JSON SERPs require additional processing for AI/LLM consumption |
A developer who ran Brave Search API in production for three months shared a detailed breakdown of where it fell short for their research agent:
We saw our free tier going from 5,000 queries/month to $5 in credits which is fine for production but very annoying when you're burning through queries during eval runs. For a bigger structural limitation for my use case, Brave gives you search results and not full page content so if your agent needs to read the article or report, you need a separate scraping layer on top.
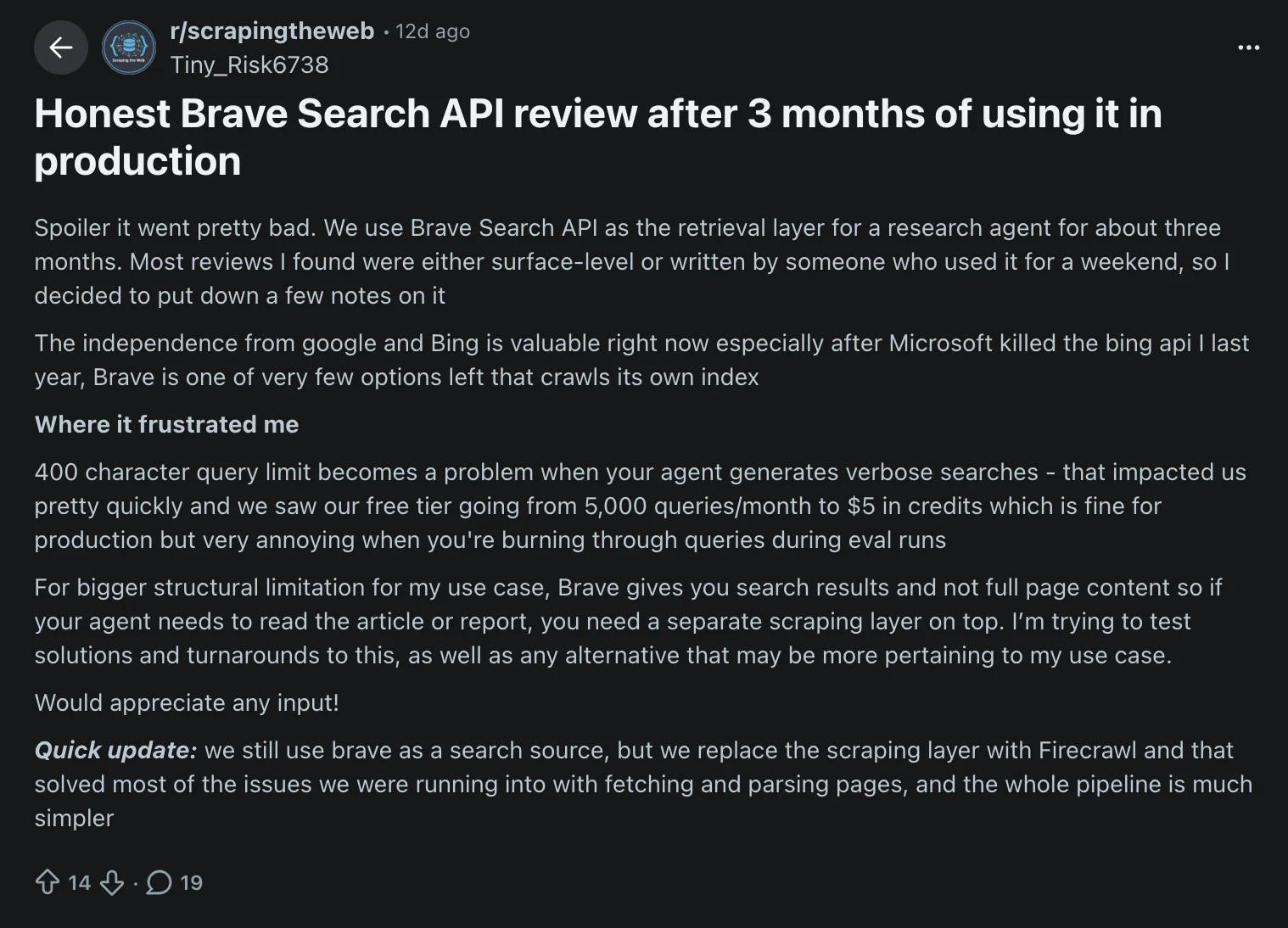
Honest Brave Search API review after 3 months of using it in production — r/scrapingtheweb
Their eventual fix was replacing the scraping layer with Firecrawl, which simplified the pipeline and resolved most of the fetching and parsing issues. The reasons below explain why teams reach that same conclusion.
Reason #1: The free tier was quietly removed
The biggest recent friction point for developers is the elimination of Brave's zero-cost plan.
As recently as August 2025, Brave offered up to 5,000 free queries per month with no billing required. By February 2026, that plan was gone for new users. In its place: a credit-based system where new signups receive $5 in monthly credits (roughly 1,000 queries) before charges kick in.
A Reddit thread flagged the change and drew significant developer pushback. A Brave team member clarified that existing free plan subscribers remain unaffected, but new users no longer have access to a genuinely free tier.
For developers who relied on Brave as a zero-cost search layer for prototyping or low-volume apps, this change prompted a search for alternatives. Teams using Brave as their OpenClaw search provider were directly affected, since Brave is OpenClaw's default web_search configuration.
Reason #2: Search quality is still maturing
Brave's independent index is a genuine differentiator, but it comes with a trade-off. Because Brave crawls and ranks the web without relying on Google or Bing, its result quality is still catching up for long-tail or niche queries.
As one user put it in a Reddit thread: Brave's fully independent index is a good thing, but it means quality gaps exist compared to more established engines. Brave acknowledges this is an ongoing journey (their index is growing by 100M+ pages/day), but for production use cases that require Google-level result quality, it remains a gap to consider.
Reason #3: AI agent support is still catching up
We're in an era where developers routinely run 10+ agentic workflows: research pipelines, competitive monitoring, RAG systems, real-time assistants, all depending on reliable web data under the hood. For these use cases, the web data stack needs to be robust: deep extraction, structured output, and the ability to handle dynamic pages without extra configuration.
Brave is clearly investing in this direction with its Answers endpoint and AI Grounding features. But for teams building production-grade agents today, Brave's tooling for agentic workflows (full-page content retrieval, multi-step navigation, and structured data extraction) is still developing. It's a solid foundation, and the trajectory is promising, but developers with demanding AI workflows often find themselves needing more. For a side-by-side look at the best deep research APIs for these production workloads—covering accuracy benchmarks, latency, and cost tradeoffs—see our full provider comparison—or our web search APIs guide for a broader look at SERP providers alongside AI-native platforms.
Reason #4: Snippets only, no full-page extraction
Brave Search API returns URLs, titles, and content snippets. It does not extract full page content.
For AI workflows that need complete article text, product details, or structured data from specific pages, developers must pair Brave with a separate scraping tool. This adds integration complexity and cost to what was meant to be a simple search layer.
Reason #5: Rate limits on lower tiers
The free credit allowance runs at 1 query per second. Even the entry paid tier has rate limits that may not suit high-throughput applications like real-time agents or batch research pipelines. Reaching 50 queries/second requires the Pro AI plan, which is a significant jump for teams with moderate but spiky usage.
Reason #6: Raw JSON output needs post-processing for AI
Brave returns standard SERP-style JSON: links, snippets, metadata. While the Answers endpoint adds summarization with citations, the base search output isn't directly optimized for LLM consumption. Teams building RAG pipelines or AI agents often find they need to clean, reformat, or chunk the results before feeding them into a model.
Top 5 Brave Search API alternatives in 2026
These alternatives offer different approaches to the gaps we outlined above: deeper extraction, stronger AI agent support, broader index quality, and output that feeds directly into LLM pipelines without extra processing.
| Alternative | Best for | Quick differentiator |
|---|---|---|
| Firecrawl | Full web data stack for AI agents | Search, Scrape, Interact, Crawl — find sources, extract clean context, ship |
| Exa | Semantic search for research-heavy apps | Embedding-based search that understands meaning |
| Tavily | AI search and research workflows | AI-optimized results, include_raw_content and /extract for full content |
| Parallel AI | Agentic web research at scale | Runs multiple search agents simultaneously |
| LLMLayer | All-in-one web infrastructure | Search, scrape, crawl, and answers in one API |
1. Firecrawl: Web context APIs for AI agents
Firecrawl searches, scrapes, and cleans the web for AI agents. It's built AI-first from the ground up — every output format, every endpoint, and every default is designed for what agents actually need, not retrofitted from a human-facing product.
With over a million developers using it, Firecrawl has become the default web data stack for AI teams and the go-to choice for production AI agents and workflows. It's fully open source (130K+ GitHub stars), with ZDR and SOC 2 Type 2 for teams with compliance requirements.
| Feature | Firecrawl | Brave Search API |
|---|---|---|
| Primary use case | Web context APIs: Search, Scrape, Interact, Crawl | Web search and discovery |
| Output format | Token-efficient markdown, structured JSON | Raw JSON SERPs (snippets, metadata) |
| Full-page extraction | Yes, included | No, snippets only |
| JavaScript rendering | Automatic, included at no extra cost | Handled in index, not extractable |
| Post-processing needed | No | Yes, for most AI workflows |
| Free tier | 1,000 credits/month | $5/month in credits (~1,000 queries) |
| Open source | Yes (130K+ GitHub stars) | No |
| Interact endpoint | Yes (session-based page interaction) | No |
| CLI | Yes (built-in Claude skill) | No |
Full content, not snippets
Most search APIs return links and snippets that still need post-processing before they're useful in an agent context. Firecrawl's Search finds the relevant pages and returns their full content — clean, token-efficient markdown or structured JSON ready to use immediately.
Search also supports specialized source types: news for fresh coverage, github for repository and code searches, research for academic papers from arXiv and PubMed, and pdf for document searches — all returning full content, not snippets.
One API replaces a multi-vendor stack
With Brave Search API, you get snippets and then need a separate scraper to get actual page content. Most teams end up stitching together a search API, a scraper, and a browser tool. Firecrawl covers the full workflow — Find → Extract → Clean → Use — in a single API at one flat credit per page. Fewer vendors, simpler code, predictable costs.
Context-aware queries
Firecrawl supports a context parameter so agents can describe what they're actually trying to do, not just fire off a keyword query. Search bars were built for humans. Agents have more to say, and Firecrawl lets them.
Find, extract, and clean in one call
Brave Search API gives you links and snippets. To get the actual page content, you need a second tool. Firecrawl handles both in a single API call: it finds the relevant pages and extracts their full content, returning structured data ready for your model.
One flat credit per page, no parsing logic required.
Beyond standard web results, the search endpoint supports specialized source types (web, news, images) and content categories (github for repository and code searches, research for academic sources like arXiv and PubMed, pdf for document searches). You can filter by time range (past hour through custom date ranges), target results by country, and search for HD images by exact resolution using Google Images operators. For compliance-sensitive teams, the endpoint also supports Zero Data Retention (ZDR) via the enterprise parameter: end-to-end ZDR (enterprise: ["zdr"]) ensures neither Firecrawl nor its upstream search provider stores query or result data; anonymized ZDR (enterprise: ["anon"]) covers Firecrawl's side at standard search pricing.
Output that goes straight into your models
Brave returns SERP-style JSON that needs cleaning, chunking, and formatting before it's useful in an LLM context. Firecrawl returns output your pipeline can consume immediately: markdown, html, json, links, screenshot, summary, or image — no post-processing required.
You define what you need ("get product name, price, and reviews"), and Firecrawl's extraction engine pulls exactly that. No CSS selectors, no XPath.
from firecrawl import Firecrawl
firecrawl = Firecrawl(api_key="fc-YOUR-API-KEY")
# Search: find fresh sources and get full content back
results = firecrawl.search(
query="firecrawl",
limit=3,
scrape_options={"formats": ["markdown"]}
)
print(results)
# Scrape: turn any URL into clean, structured data
result = firecrawl.scrape(
"https://example.com",
formats=["json"],
json_options={"prompt": "Extract the founder names, roles, and backgrounds"}
)
print(result.json)The /interact endpoint: go deeper into any result
/interact is built for the search-then-dig-deeper workflow: scrape a page to get its initial content, then call /interact on the same scrapeId to keep going. Describe what you want in natural language ("click the next page and extract the pricing table") or write Playwright code directly for full control.
Sessions preserve state between calls, so you can chain multiple interactions without reinitializing — click a tab, then extract its content, then paginate. Persistent profiles let you save login state (cookies, localStorage) across separate scrapes, making authenticated content accessible at scale without re-entering credentials.
Endpoints that work together
- Search: Search the live web and get full content back immediately
- Scrape: Convert any URL into clean markdown or JSON
- Interact: Automate browser actions — click buttons, fill forms, navigate multi-step flows
- Crawl: Navigate entire sites without sitemaps
Firecrawl is also an official Claude plugin, integrating directly into Claude for AI-powered web research without writing code. The Firecrawl CLI, with a built-in Claude skill, covers terminal-based workflows. It also works with no-code tools like Lovable and n8n.
Pricing
| Plan | Monthly cost | Credits included |
|---|---|---|
| Free | $0 | 1,000 credits |
| Hobby | $16 | 5,000 credits |
| Standard | $83 | 100,000 credits |
| Growth | $333 | 500,000 credits |
| Scale | $499 | 1,000,000 credits |
| Enterprise | Custom | Unlimited |
When to choose Firecrawl over Brave Search API
Choose Firecrawl if you need:
- The full workflow in one API: Search finds fresh sources, Scrape turns them into token-efficient context, Interact handles dynamic pages, Crawl goes deep across sites — Find → Extract → Clean → Use
- Clean web context without post-processing — markdown and structured JSON built for agents, not humans
- Real-web handling: JS-heavy pages, SPAs, geo-sensitive sources
- Session-based interaction with dynamic pages (forms, auth flows, pagination)
- ZDR compliance for sensitive query workloads
- Predictable flat-rate pricing per page
- Open source with self-hosting option
2. Exa: Semantic search for research-heavy applications
Exa takes a fundamentally different approach to search than Brave. Where Brave matches keywords against its index, Exa uses embeddings to understand the meaning and context of a query. This makes it particularly useful for research-heavy applications where intent matters more than exact keyword match.
| Feature | Exa | Brave Search API |
|---|---|---|
| Primary use case | Semantic search and research | Web search and discovery |
| Search method | Embedding-based (understands meaning) | Keyword-based against independent index |
| Unique feature | "Find Similar" (feed 1 URL, get 20 more) | Search Goggles for custom ranking |
| Output format | Links, full HTML, summarized answers | Raw JSON SERPs (snippets, metadata) |
| Free tier | 1,000 credits | $5/month in credits (~1,000 queries) |
| Privacy | SOC 2 Type II | SOC 2 Type II, no user tracking |
| Best for | Research, technical discovery, semantic queries | Lightweight privacy-first search layer |
How Exa compares to Brave
Understands meaning, not just keywords
Brave matches your query against its index using traditional keyword signals. Exa uses embeddings to understand intent. Ask Exa "find articles explaining how LLMs handle long context" and it aims to understand the concept, not just match those exact words. This approach makes it well-suited for research assistants, competitive intelligence, and complex question answering where keyword search falls short.
"Find Similar" for dataset building
Found one good result? Feed it back to Exa and get 20 more pages with similar content. This is useful for building comprehensive datasets around a topic without having to craft multiple search queries from scratch.
Five endpoints
- Search: Semantic queries that understand context and meaning
- Contents: Retrieve full HTML content from discovered pages
- Answer: Get summarized, cited responses instead of just links
- Research: Multi-hop queries across multiple sources
- Websets: Curated collections of high-quality sources
When to choose Exa over Brave
Consider Exa when your application needs to understand conceptual similarity and intent, not just surface pages that contain specific words. Technical documentation discovery, academic research assistants, and competitive intelligence workflows can benefit from semantic search.
One consideration: Exa's pricing is variable, with credit consumption ranging from 75 to 750+ credits per search depending on query complexity. This makes cost prediction harder than Brave's flat per-request model. High-volume use cases may benefit from a more predictable pricing structure.
For a detailed breakdown, see Firecrawl vs. Exa and our full Exa alternatives guide.
3. Tavily: AI search and research API

Tavily is a search API built for AI agents and LLMs. Unlike Brave, it optimizes results specifically for LLM consumption: ranked results with relevance scores and citations formatted for agent workflows. Tavily's platform also spans /extract, /crawl, /map, and /research, and /search supports include_raw_content for inline raw HTML alongside results.
It's particularly popular in the LangChain ecosystem, where native integrations make it easy to drop into an existing agent with minimal setup.
| Feature | Tavily | Brave Search API |
|---|---|---|
| Primary use case | AI search and research workflows | Web search and discovery |
| Output format | Ranked results with raw content via include_raw_content or /extract | Raw JSON SERPs (links, snippets) |
| LLM optimization | Yes, results ranked for agent context | Partial (Answers endpoint only) |
| Free tier | 1,000 credits/month | $5/month in credits (~1,000 queries) |
| Entry pricing | $30/month (4,000 credits) | $5 per 1,000 requests |
| At 100k requests | ~$800 PAYG basic search | ~$500-900 depending on plan |
| LangChain native | Yes | Available via community integrations |
| Best for | AI search and research workflows | Lightweight privacy-first search layer |
How Tavily compares to Brave
Results formatted for LLMs, not humans
Brave returns standard SERP JSON. Tavily's results include relevance scoring and are structured for direct injection into agent context windows. If you want search results that are already ranked and formatted for LLM consumption without post-processing, Tavily is closer to plug-and-play than Brave.
Native LangChain integration
Tavily is one of the most commonly used search tools in LangChain-based agents. The integration is a few lines of code, which makes it a natural choice for teams already in that ecosystem. Brave has community integrations but isn't as tightly coupled to LangChain out of the box.
Five core endpoints
- Search: Real-time web queries with AI-optimized, ranked results; optional raw content via
include_raw_content - Extract: Pull full content from specific URLs with JavaScript rendering
- Crawl: Navigate entire websites using natural language instructions
- Map: Discover website structure before extraction
- Research: Multi-step agentic research that synthesizes results across sources
Pricing at scale
Tavily's free tier is more generous than Brave's current offering (1,000 credits/month vs ~1,000 queries for $5). At higher volumes, Tavily's pay-as-you-go model adds up: 100k requests costs around $800 on PAYG basic search, compared to Firecrawl's Standard plan at $83 for the same volume.
For a detailed comparison, see Firecrawl vs. Tavily and our full Tavily alternatives guide.
When to choose Tavily over Brave
Consider Tavily when you need AI-optimized search results that feed directly into agent context without additional formatting, especially if you're already using LangChain. It handles the "find relevant content and rank it for my LLM" use case more directly than Brave's raw SERP output — and when you need full page content, include_raw_content and /extract cover that in the same platform.
4. Parallel AI: Agentic web research built for scale
Parallel AI (officially Parallel Web Systems) is a newer entrant building web infrastructure specifically for AI agents. It raised $100M Series A in early 2025 with a thesis that the web's next major user is AI, and that existing search infrastructure wasn't built for it.
The core differentiator is accuracy. Parallel benchmarks itself at 47% on the HLE (Humanity's Last Exam) benchmark compared to Exa at 24%, Tavily at 21%, and Perplexity at 30%. Results include provenance and evidence for every output, rather than raw links or ranked snippets.
| Feature | Parallel AI | Brave Search API |
|---|---|---|
| Primary use case | Agentic web research and deep data retrieval | Web search and discovery |
| Search method | Multi-agent, evidence-based retrieval | Keyword-based against independent index |
| Output format | Structured results with full provenance | Raw JSON SERPs (snippets, metadata) |
| Pricing model | Pay per query, not per token | Pay per request |
| Privacy | SOC 2 Type II certified | SOC 2 Type II, no user tracking |
| Maturity | Newer, still building out ecosystem | Established, growing index |
What it offers
Parallel's product suite covers four main use cases:
- Search API: Real-time web queries optimized for agent consumption with sourced, evidence-backed results
- Task API (Deep Research): Multi-step research that reasons across sources, not just returns links
- Find All: Dataset building at scale, for teams that need comprehensive coverage of a domain
- Web Enrichment and Monitor API: Enrich records with live web data, and track changes over time
When to consider Parallel AI
Parallel is worth evaluating if you're building research-heavy agents that need high-accuracy outputs with clear sourcing, particularly for enterprise or compliance-sensitive workflows. Its pay-per-query model (not per token) is also useful for teams that need predictable cost scaling.
That said, it's a newer solution. Ecosystem integrations, SDKs, and community resources are still maturing compared to more established tools on this list. For teams that need a proven, production-ready stack today, Firecrawl or Exa may be the lower-risk choice. But if you're actively evaluating Parallel AI alternatives, that comparison covers the full competitive landscape.
5. LLMLayer: All-in-one web infrastructure for AI
LLMLayer offers a unified API that combines search, scraping, crawling, and LLM-powered answers in one platform. Where Brave covers search and Firecrawl covers extraction, LLMLayer tries to bundle both, along with a few additional capabilities, under a single integration.
| Feature | LLMLayer | Brave Search API |
|---|---|---|
| Primary use case | Unified web infrastructure (search + scrape + answers) | Web search and discovery |
| Output format | Markdown, HTML, screenshots, PDFs, cited answers | Raw JSON SERPs (snippets, metadata) |
| Search pricing | $1 per 1,000 requests | $5 per 1,000 requests |
| Free tier | $2 in free credits, no card required | $5/month in credits (~1,000 queries) |
| JavaScript rendering | Included in scraper | Handled in index, not extractable |
| Best for | Teams needing search, scraping, and answers in one | Lightweight privacy-first search layer |
What it offers
LLMLayer bundles six capabilities that normally require multiple services:
- Web Search: Query across web, news, images, videos, and more. Filter by recency, localize by country, include or exclude domains
- Scraper: Convert any URL to markdown, HTML, screenshots, or PDFs, with JavaScript rendering included
- Map: Discover complete website structure in seconds
- Crawler: Navigate entire websites with sitemap generation and deep crawling
- Answer API: Search, reason, and answer in one call with citations included
- YouTube Transcript: Multi-language transcript extraction
When to consider LLMLayer over Brave
LLMLayer is worth considering when you need both search and scraping but want a single vendor rather than combining Brave with a separate scraper. Its search pricing ($1 per 1,000 requests) is also lower than Brave's ($5 per 1,000), which can matter at high volumes.
One consideration: LLMLayer is newer and has less market presence than the other tools on this list. Community adoption and third-party integrations are still growing, so teams that need a well-documented, widely-used stack may find the established alternatives lower risk.
Conclusion
Brave Search API is a solid choice for teams that want a lightweight, privacy-first search layer without depending on Google or Bing. But its recent removal of the free tier, snippet-only output, and still-maturing agentic tooling push many developers to look elsewhere, especially as AI workflows become more demanding.
The right alternative depends on what you're building:
- Firecrawl if you need the full web data stack: Search finds fresh sources, Scrape turns them into clean context, Interact handles dynamic pages — one API covering Find → Extract → Clean → Use
- Exa if semantic understanding matters more than keyword matching, particularly for research-heavy or discovery-driven applications
- Tavily for AI search and research workflows, with drop-in LangChain integration and raw-content options on
/searchor/extract - Parallel AI if you're building enterprise-grade research agents and want evidence-backed, sourced results at scale (and are willing to evaluate a newer platform)
- LLMLayer if you want a single API covering search, scraping, crawling, and answers, especially at high search volumes where its pricing is competitive
For most AI teams, Firecrawl is the most complete starting point: built AI-first with over a million developers and 130K+ GitHub stars, it covers Search, Scrape, Interact, and Crawl — the full web data stack — with token-efficient output and no platform lock-in. Try Firecrawl free with 1,000 credits per month (no card required) or explore the docs. If you're specifically building Claude-based agent workflows, see the Anthropic web search alternatives guide for a Claude-focused comparison.
Frequently Asked Questions
What is the Brave Search API used for?
The Brave Search API lets developers query Brave's independent web index of 30B+ pages programmatically. It is used for building search features into apps, powering AI agents with real-time web data, and grounding LLM responses with cited, up-to-date results.
Is there a free tier for the Brave Search API?
Brave Search API no longer offers a traditional free tier for new users. As of early 2026, new users receive $5 in monthly credits (roughly 1,000 queries) rather than a dedicated free plan. Existing free plan subscribers (up to 2,000 queries/month) retain access. Paid plans start at $5 per 1,000 requests.
Why do developers look for Brave Search API alternatives?
Developers explore alternatives when they need deeper content extraction beyond search snippets, semantic search capabilities, richer AI-optimized output formats, more aggressive rate limits, or a unified search-plus-scrape pipeline in a single API.
Which Brave Search API alternative is best for AI agents?
Firecrawl is the strongest choice for AI agents. Built AI-first, it covers the full workflow agents need: Search finds fresh pages from the live web, Scrape turns them into token-efficient context, Interact handles dynamic pages, and Crawl goes deep across sites — all in one API without post-processing.
Can Brave Search API alternatives handle JavaScript-rendered pages?
Yes. Firecrawl includes automatic JavaScript rendering at no extra cost. LLMLayer's scraper also includes JavaScript rendering. Exa and Tavily can retrieve content from dynamic pages depending on the endpoint used.
Is Firecrawl a good replacement for Brave Search API?
Firecrawl complements or replaces Brave Search API depending on your use case. If search quality matters, Firecrawl returns full-content results from the live web — no snippets, no pre-digestion, no post-processing required. If you also need full-page extraction alongside search, Firecrawl's combined Search and Scrape pipeline is far more capable than Brave's snippet-only results.
