
TL;DR - Best Parallel AI alternatives
| Tool | Best for | Standout feature | Free tier |
|---|---|---|---|
| Firecrawl | Full web data stack for AI agents | Search, Scrape, Interact, Crawl — one API, consistent markdown output | 1,000 credits/month |
| Exa | Semantic search and content discovery | Embeddings-based search, Find Similar, full-content retrieval | 1,000 credits/month |
| Tavily | AI search and research workflows | Transparent flat pricing, native LangChain integration | 1,000 credits/month |
| Linkup | Verified facts and trusted sources | Ranked #1 on SimpleQA, two-tier Standard and Deep search | €5 free/month |
At AI Engineer Europe 2026, Weaviate's Leonie Monigatti made a point worth sitting with: context engineering is roughly 80% agentic search. The quality of what you put into your agent's context window determines everything downstream. Outdated context produces answers that sound authoritative but aren't. What separates a polished demo from an agent you can actually ship is fast, fresh, citable web search for AI agents.
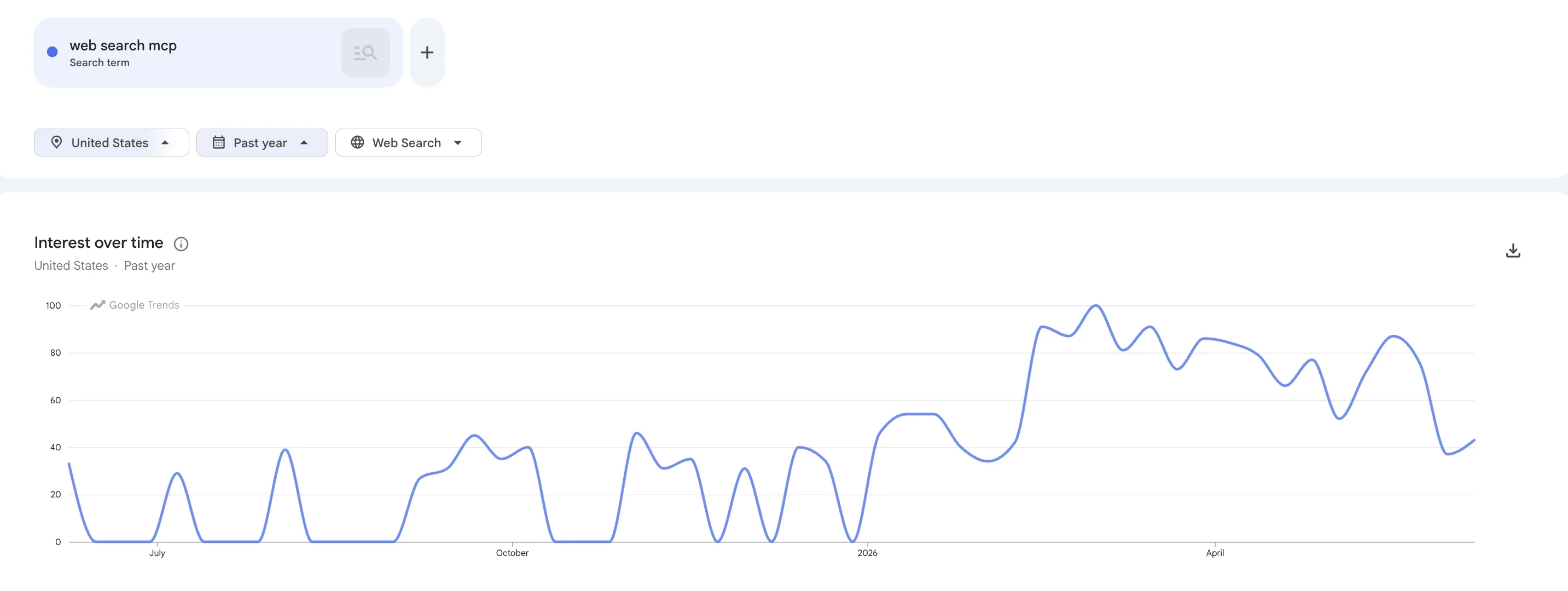
Google Trends: search interest in "web search MCP" over the past 12 months
Parallel AI has made a strong push in the agentic web search space — raising at a $2B valuation and building a suite of products for AI-powered web search and deep research. But its multi-product architecture (6 separate APIs, 9 processor tiers for the Task API alone) can add friction for teams that need a simpler, unified stack.
This guide covers four alternatives across different use cases: Firecrawl for the complete web data toolkit, Exa for semantic discovery, Tavily, and Linkup.
What is Parallel AI: Quick overview
Parallel AI is a web API built for AI agents, with a focus on high-accuracy web search, deep research, and data enrichment. It's founded and led by Parag Agrawal, the former CEO of Twitter. It's trusted by companies like Harvey, Modal, and Formation Bio.
Main products:
- Search: AI-powered web search returning dense excerpts optimized for LLMs
- Task API: Multi-step deep research API with 9 processor tiers (from Basic to Ultra8x)
- Extract: Fetch and parse full page content into markdown (1-3s cached, 60-90s live)
- Chat: Conversational interface backed by live web search
- Monitor: Continuous web monitoring for changes and events
- FindAll: Build structured datasets from natural language criteria
- Index: Content owner platform for AI agent usage and revenue tracking
Pricing: Per-request pricing across 6 APIs. Extract: $0.001/request. Task API ranges from $0.12 (Basic) to $2.40 (Ultra8x) per request. Search pricing available via their platform.
Why developers look for Parallel AI alternatives
Teams typically explore alternatives when they need consistent LLM-ready output across all endpoints, a single unified API with predictable flat-rate pricing, open-source or self-hosted infrastructure, or a simpler onboarding path without choosing between multiple products and processor tiers. Others need transparent public pricing before committing to a sales conversation, or specialized capabilities like browser interaction and full-site crawling that Parallel doesn't cover.
Latency is the often-overlooked dealbreaker. An independent benchmark by AIMultiple — evaluating 8 search APIs across 100 real-world AI/LLM queries — found that latency varies 20x across providers, from 669ms (Brave) to 13.6 seconds for Parallel Search Pro. Firecrawl came in at 1,335ms — significantly faster than Parallel while delivering comparable result quality.
In multi-step agent workflows, that latency compounds fast. A research agent making 5 search calls waits 3 seconds total with a fast API — or 68 seconds with Parallel Pro. For real-time applications like customer support bots or coding assistants, sub-second response times are essential.
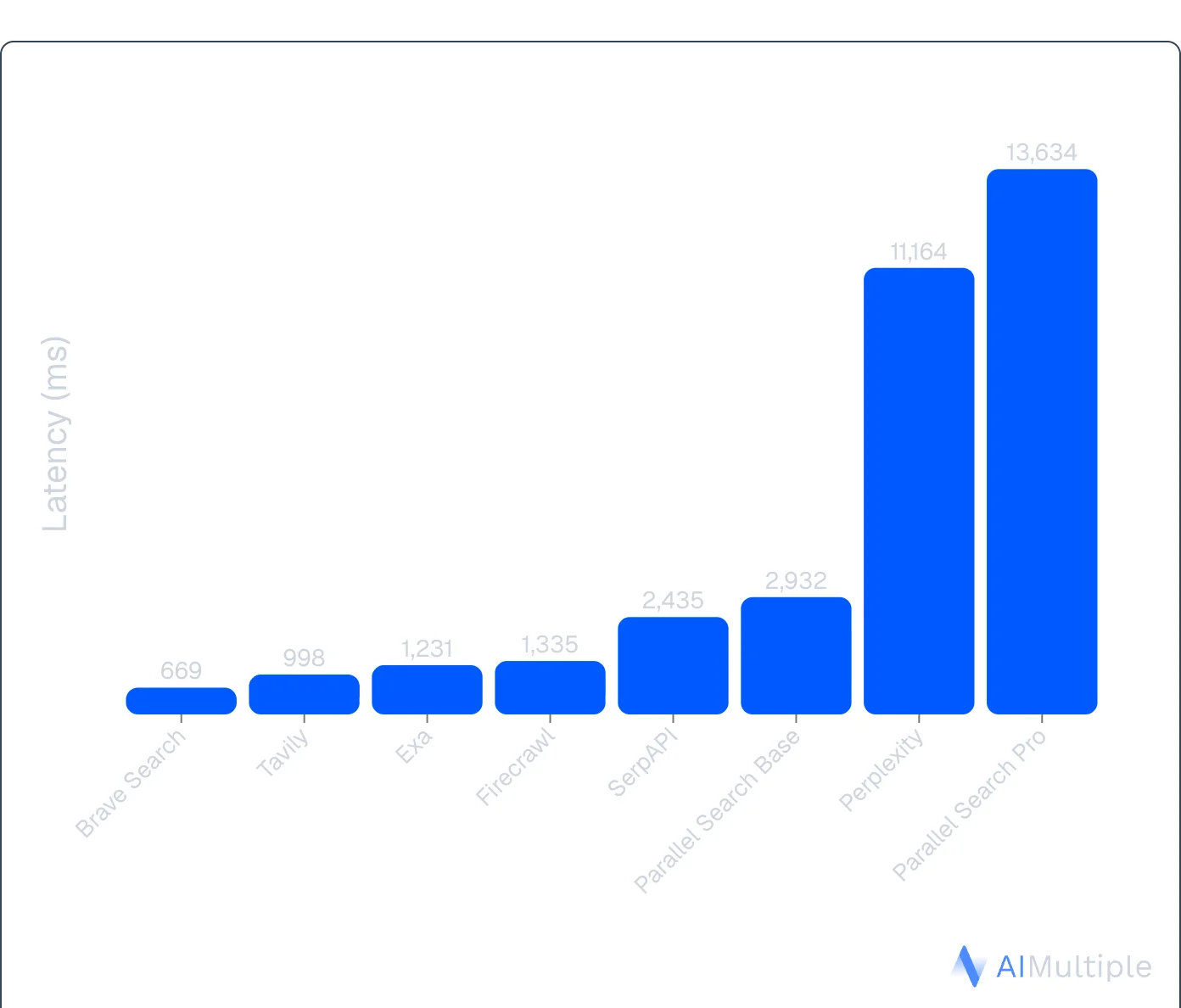
Source: AIMultiple Agentic Search Benchmark 2026
Top 4 Parallel AI alternatives
1. Firecrawl: Web context APIs for AI agents
Firecrawl searches, scrapes, and cleans the web for AI agents. It's built AI-first from the ground up — every output format, every endpoint, and every default is designed for what agents actually need. With over a million developers using it and 130K+ GitHub stars, it has become the default web data stack for AI teams building production workflows. Companies like DoorDash, Alibaba, Zapier, and Stanford University rely on it for production AI pipelines.
| Feature | Firecrawl | Parallel AI |
|---|---|---|
| Primary use case | Web context APIs: Search, Scrape, Interact, Crawl | AI web search, deep research, enrichment |
| Output format | Consistent markdown + structured JSON on every request | Varies: excerpts (Search), markdown (Extract), JSON (Task) |
| JavaScript rendering | Automatic (included, all endpoints) | Supported (Extract API, 60-90s for live fetches) |
| API surface | One unified API | 6 separate APIs, 9 Task tiers |
| Pricing model | 1 credit = 1 page (flat) | Per-request, varies by API and tier |
| Free tier | 1,000 credits/month | Free tier available |
| Open source / self-hosted | Yes (130K+ GitHub stars, AGPL-3.0) | No (proprietary SaaS) |
| Browser interaction | Yes (/interact endpoint) | No |
| CLI | Yes | Yes (Parallel CLI) |
How Firecrawl compares to Parallel AI
Consistent output, every request
Parallel returns different formats depending on which product you use: Search returns compressed excerpts, Extract returns markdown, and the Task API returns structured JSON. When you're building AI pipelines, switching output formats between steps adds parsing and normalization overhead. Firecrawl returns clean, token-efficient markdown (or structured JSON — your choice) on every request across every endpoint.
One API replaces a multi-vendor stack
Parallel's 6-product model gives flexibility but requires understanding which product and tier fits each task. Firecrawl covers the full workflow — Search finds live sources, Scrape converts URLs to clean context, Interact handles dynamic pages, Crawl navigates entire sites — under a single API key at one flat credit per page.
Context-aware search
Firecrawl's Search endpoint supports a context parameter so agents can describe what they're actually trying to do, not just fire off keyword queries. It also supports specialized source types in a single call: news for fresh coverage, github for repository searches, research for academic papers from arXiv and PubMed, and pdf for document searches — each returning full content immediately.
from firecrawl import Firecrawl
app = Firecrawl(api_key="fc-YOUR_API_KEY")
# Search with full content in one call
results = app.search(
"latest AI agent frameworks 2026",
limit=5,
scrape_options={"formats": ["markdown"]}
)
for result in results.web or []:
print(result.markdown) # Full page content, ready for your pipelineStructured extraction without selectors
Firecrawl's Scrape endpoint extracts structured data using natural language prompts or a JSON Schema — no CSS selectors, no XPath, no parsing logic. When a site changes its HTML structure, your extraction keeps working automatically.
from firecrawl import Firecrawl
app = Firecrawl(api_key="fc-YOUR_API_KEY")
result = app.scrape(
"https://techcrunch.com/some-article",
formats=[{
"type": "json",
"prompt": "Extract company name, funding stage, and headcount"
}]
)
print(result.json)Token efficiency that pays for itself
Parallel returns dense excerpts optimized for LLMs, but the underlying content still carries noise. Firecrawl strips navigation, ads, scripts, and footers — returning 94% fewer input tokens than raw HTML, saving ~35,980 tokens per page. On Claude Sonnet, that's $0.108 saved per scrape — enough that the Standard plan ($83/month for 100K credits) saves over $10,000 in LLM input costs at full usage.
Handles dynamic pages with Interact
Many sites hide content behind "Load More" buttons, require form submissions, or paginate across multiple views. Parallel's Extract API handles static and cached pages well, but for complex interactive pages Firecrawl's Interact endpoint handles these automatically — clicking buttons, filling fields, navigating pagination — without custom automation code.
Benchmark performance
An agentic search benchmark by AIMultiple — evaluating 8 search APIs across 100 real-world AI/LLM queries — ranked Firecrawl #2 overall (Agent Score: 14.58), near the top of the field and well ahead of the remaining competitors. On latency, Firecrawl came in at 1,335ms — significantly faster than Parallel Search Pro's 13.6 seconds. In multi-step agent workflows where search calls stack up, that gap compounds quickly.
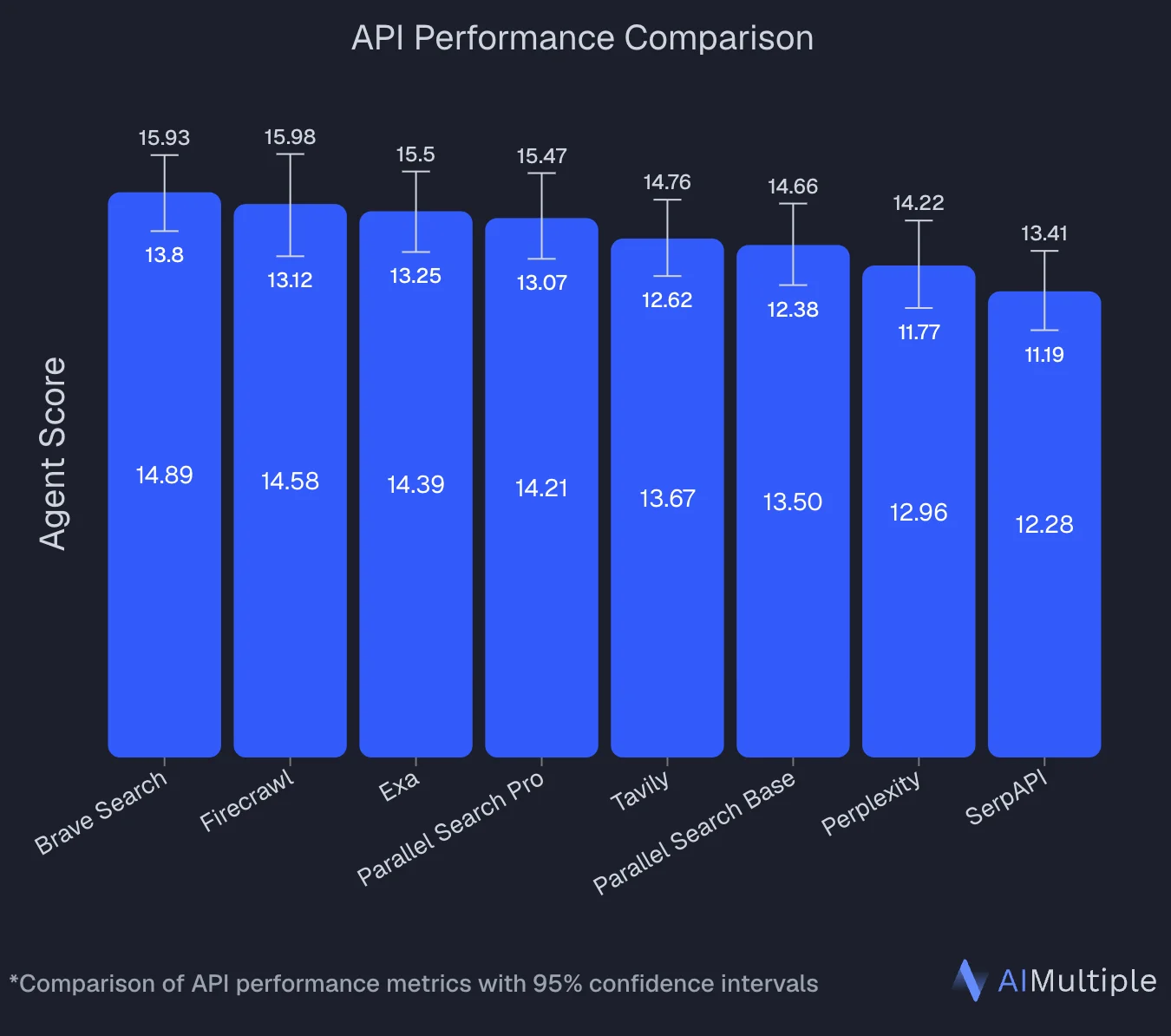
Source: AIMultiple Agentic Search Benchmark 2026
Parallel's Extract API reports 1-3s for cached fetches, with live fetches taking 60-90 seconds. For pipelines that need consistent, sub-second turnaround on fresh URLs, Firecrawl is optimized for that use case.
Open source and self-hosted
Firecrawl is fully open source and can be self-hosted for teams with data residency requirements, security constraints, or cost optimization at scale. Parallel is a proprietary SaaS platform with no self-hosting option.
Firecrawl endpoints
- Search: Search the live web and get full content back in one call
- Scrape: Convert any URL into clean markdown or structured JSON
- Parse: Convert PDFs and documents into usable text
- Crawl: Navigate entire sites without sitemaps
- Map: Discover site structure fast
- Interact: Automate browser actions — click buttons, fill forms, navigate multi-step flows
Firecrawl is also an official Claude plugin and integrates with LangChain, LlamaIndex, n8n, and Lovable.
When to choose Firecrawl over Parallel AI
- Choose Firecrawl when you need a single unified API with consistent output: one API key, one credit per page, one output format across every endpoint.
- Choose Firecrawl when you need the full workflow in one place: Search finds fresh sources, Scrape turns them into token-efficient context, Interact handles dynamic pages, Crawl goes deep across sites.
- Choose Firecrawl if open source, self-hosting, or data residency requirements are a factor (130K+ GitHub stars, AGPL-3.0).
- Choose Parallel when you need deep multi-step research with configurable compute budgets across their Task API tiers, or the Monitor API for continuous web event tracking.
2. Exa: Semantic search for AI agents
Exa is an AI-powered search engine built specifically for machines. Unlike Parallel's accuracy-optimized research approach, Exa uses embeddings-based semantic search to understand meaning rather than just matching keywords — making it strong for discovery workflows where you want to find conceptually related content.
| Feature | Exa | Parallel AI |
|---|---|---|
| Primary use case | Semantic search and content discovery | AI web search, deep research, enrichment |
| Search method | Embeddings-based semantic | Multi-step AI research with compute tiers |
| Unique capability | Find Similar (feed one URL, get 20 similar pages) | Task API with 9 processor tiers |
| Output format | Parsed HTML, text snippets, full content | Compressed excerpts (Search), markdown (Extract) |
| Free tier | 1,000 credits/month | Free tier available |
| Open source | No (proprietary) | No (proprietary) |
| Best for | Semantic discovery, RAG, research | Deep research workflows, business intelligence |
How Exa compares to Parallel AI
Semantic over accuracy-optimized
Parallel focuses on high-accuracy answers to specific questions using multi-step research workflows. Exa takes a different approach: embeddings-based semantic search finds conceptually similar pages, not just keyword matches or synthesized answers. This makes Exa better for open-ended discovery — "find me content similar to this URL" — versus Parallel's strength in structured research tasks.
Find Similar API
Exa's Find Similar endpoint is unique: feed it one URL and get back 20 semantically similar pages. This has no equivalent in Parallel's product suite and is particularly useful for competitive research, content clustering, and building training datasets.
Full content retrieval
Exa's Contents API retrieves clean, parsed content from search results in the same API call. Like Parallel's Extract API, it returns full page content — but Exa integrates this into the search-and-fetch workflow more directly for standard RAG frameworks use cases.
Exa APIs:
- Search: Semantic queries that understand context and intent
- Contents: Retrieve clean, parsed content from search results
- Find Similar: Feed one URL, get 20 semantically similar pages
- Answer: Summarized responses with citations
- Research: Automated deep research with structured JSON output
- Websets: Complex queries returning thousands of results
Pricing: Free tier with 1,000 requests/month. Paid tiers: $7/1k search requests, $12–15/1k deep search, $1/1k pages (Contents), $5/1k answers.
When to choose Exa over Parallel AI
Choose Exa when semantic discovery is the primary use case — finding conceptually related content, building content clusters, or identifying similar companies and articles. Exa's embeddings approach gives it a distinct edge for these workflows compared to Parallel's accuracy-focused research model.
The tradeoff: like Parallel, Exa is search and discovery focused. For teams that also need browser interaction, full-site crawling, or structured extraction without selectors, you'll still need a dedicated tool like Firecrawl alongside Exa.
For more context on Exa, see Firecrawl vs. Exa.
3. Tavily: AI search and research with transparent pricing
Tavily is a search API built for AI agents and LLMs. Like Parallel, it's designed for machines rather than humans — but takes a more accessible approach with publicly listed pricing and native integrations with popular AI frameworks. Its platform spans /search, /extract, /crawl, /map, and /research, with /search supporting include_raw_content for inline raw HTML.
| Feature | Tavily | Parallel AI |
|---|---|---|
| Primary use case | AI search and research workflows | AI web search, deep research, enrichment |
| Search method | Multi-source aggregation | Multi-step AI research with compute tiers |
| Unique feature | AI-optimized results with include_raw_content and /extract for raw content | Task API with 9 processor tiers |
| Output format | Structured results with raw content via include_raw_content or /extract | Compressed excerpts, markdown, structured JSON |
| Free tier | 1,000 credits/month | Free tier available |
| Pricing | $0.008/credit PAYG basic search (flat) | Per-request, varies by API and tier |
| Open source | No | No |
| Best for | AI search and research workflows | Deep research workflows, business intelligence |
How Tavily compares to Parallel AI
Transparent, predictable pricing
Parallel's pricing varies across 6 APIs and 9 Task tiers — from $0.001/Extract request to $2.40/Ultra8x Task request. Choosing the right tier adds overhead before you've written a line of code. Tavily charges a flat $0.008 per credit PAYG basic search. You know exactly what you'll pay before making a request.
LangChain-native integrations
Tavily is particularly popular in the LangChain and LlamaIndex communities, with native integrations that make adding real-time web search to your agent straightforward. The setup is simpler than configuring Parallel's multi-API architecture.
Five core endpoints:
- Search: Real-time web queries with AI-optimized results; optional raw content via
include_raw_content - Extract: Pull full content from URLs with JavaScript rendering
- Crawl: Navigate websites using natural language instructions
- Map: Discover website structure before extraction
- Research: Multi-step agentic research that synthesizes results across sources
When to choose Tavily over Parallel AI
Choose Tavily when you need predictable costs for AI search workflows, fast response times, and native integration with popular AI frameworks. It's also a strong fit when breadth of relevant results matters more than exhaustive multi-source synthesis — tasks like summarization, quick fact lookups, or building chatbots where you want clean, ranked results fast.
For teams that also need browser interaction on paginated or dynamic pages, a dedicated tool like Firecrawl alongside Tavily covers that gap. Read our detailed Tavily alternatives comparison for more context.
4. Linkup: Verified facts from trusted sources
Linkup is an AI search API for LLMs and AI agents, focused on sourcing data from trusted, authoritative sources. It ranks #1 on OpenAI's SimpleQA factuality benchmark, positioning itself as the most accurate search for applications that need verified facts — a direct challenge to Parallel's accuracy-first positioning.
| Feature | Linkup | Parallel AI |
|---|---|---|
| Primary use case | Fact retrieval from trusted sources | High-accuracy general web search |
| Search method | Two-tier (Standard and Deep) | Multi-step AI research with compute tiers |
| Unique feature | Trusted source integration, SimpleQA #1 | 9 Task processor tiers, Monitor API |
| Output format | Sourced answers with citations | Compressed excerpts, markdown, structured JSON |
| Free tier | €5 worth of queries/month | Free tier available |
| Pricing | €5/1k standard, €50/1k deep searches | $0.001/Extract to $2.40/Ultra8x Task |
| Open source | No | No |
| Best for | Business intelligence, trusted sources | Deep research, enrichment, monitoring |
How Linkup compares to Parallel AI
Competing on accuracy claims
Both Parallel and Linkup market on accuracy. Parallel runs its own benchmark suite (BrowseComp, FreshQA, HLE) using a proprietary GPT-5.4 harness. Linkup claims #1 on OpenAI's SimpleQA, an independent benchmark. The difference is in what's being measured: Linkup optimizes for factual precision from trusted sources; Parallel optimizes for coverage across diverse agentic search tasks.
Two-tier search vs. nine Task tiers
Linkup offers two clearly-named tiers — Standard for fast fact retrieval and Deep for chain-of-thought reasoning on complex questions. Standard handles queries like "What is Microsoft's Q3 2024 revenue?" while Deep handles multi-step questions like "What are Apple and Samsung's strategy differences for 2026?" Parallel's 9 Task tiers (Basic through Ultra8x) offer more granular compute control but require more decision-making overhead.
Public pricing and free tier
Linkup offers €5 in free queries each month and transparent per-query pricing — €5/1k standard searches, €50/1k deep searches. Parallel's pricing requires navigating its platform or contacting sales for full access.
Native integrations:
Linkup integrates natively with CrewAI, LangChain, Make, n8n, and Zapier — making it easy to add to existing AI workflows without custom code.
When to choose Linkup over Parallel AI
Choose Linkup when you need verifiable facts from trusted sources with a transparent, simple pricing model. It's ideal for business intelligence, competitive analysis, and GTM automation where data accuracy is the primary constraint and a two-tier pricing model is easier to reason about than nine compute tiers.
The tradeoff: Linkup doesn't offer web crawling, browser interaction, or structured extraction beyond search results. For those capabilities, a tool like Firecrawl fills the gap.
Conclusion: Choosing your Parallel AI alternative
Parallel AI is a capable platform for teams that need deep research workflows with configurable compute budgets and continuous web monitoring. When the multi-product architecture adds friction or you need more consistent output across endpoints, these alternatives offer focused approaches for those needs.
If you need the full web data stack, Firecrawl covers Search, Scrape, Interact, and Crawl in one API — built AI-first, with consistent markdown output on every request, flat-rate pricing, and open-source infrastructure (130K+ GitHub stars). For a full comparison, see Firecrawl vs. Parallel.
If semantic discovery is your priority, Exa's embeddings-based search and Find Similar API are the strongest options in the field. For AI search and research workflows with predictable costs and native LangChain integration, Tavily is the community standard. And for verified facts from trusted sources with a simple two-tier pricing model, Linkup's SimpleQA #1 ranking is worth considering.
Try Firecrawl free with 1,000 credits per month (no card required) or explore the docs.
Frequently Asked Questions
What is the main difference between Parallel AI and its alternatives?
Parallel AI is built around AI-powered web search and deep research with 6 separate APIs and 9 processor tiers for its Task API. Firecrawl offers the full web data stack (Search, Scrape, Interact, Crawl) under a single unified API built AI-first with consistent markdown output. Exa focuses on embeddings-based semantic search for conceptual discovery. Tavily offers AI search and research workflows across `/search`, `/extract`, `/crawl`, `/map`, and `/research` with transparent flat pricing. Linkup prioritizes verified facts from trusted sources and ranks #1 on OpenAI's SimpleQA benchmark.
Why do developers look for Parallel AI alternatives?
The main reasons are output consistency, pricing complexity, and workflow coverage. Parallel uses different output formats across its 6 APIs and its Task API has 9 processor tiers, which adds overhead when deciding what to use. Teams that need a single unified platform covering search, scrape, extraction, and browser interaction in one API often explore alternatives. Others need transparent public pricing or open-source infrastructure.
Which Parallel alternative is best for RAG pipelines?
Firecrawl is purpose-built for RAG: every request returns clean markdown ready for chunking and embedding, with structured extraction via natural language prompts or JSON Schema. It covers Search, Scrape, Crawl, and Interact in one API. Tavily is also strong, with native LangChain integration and AI-optimized results plus raw content options on `/search` via `include_raw_content` or a dedicated `/extract` endpoint. Exa's Contents API returns full-page content for RAG workflows.
Can Parallel alternatives handle JavaScript-rendered pages?
Yes. Firecrawl includes automatic JavaScript rendering at no extra cost across all endpoints. Exa supports JavaScript rendering via its Contents API. Tavily supports JavaScript-heavy sites. Parallel's Extract API handles JavaScript-heavy pages but can take 60-90 seconds for live fetches.
How does Firecrawl pricing compare to Parallel?
Firecrawl uses a simple credit-based system: 1 credit per page, with paid plans starting at $16/month for 5,000 credits. Parallel uses per-request pricing across 6 APIs at different rates from $0.001 per Extract request to $2.40 per Ultra8x Task request. Firecrawl's flat credit model is simpler to budget for at scale.
Do Parallel alternatives offer free tiers?
Yes. Firecrawl offers 1,000 free credits per month with no card required. Exa offers 1,000 credits in its free tier. Tavily includes 1,000 credits/month. Linkup gives €5 in free queries each month. Parallel offers a free tier for testing on its platform.
Can Parallel alternatives be self-hosted?
Firecrawl is fully open source (130K+ GitHub stars) and can be self-hosted under the AGPL-3.0 license, making it suitable for teams with data residency or compliance requirements. Exa, Tavily, Linkup, and Parallel are all proprietary cloud-only platforms.
Which alternative is best for agentic web research workflows?
Firecrawl covers the full agentic loop: Search finds live sources, Scrape turns them into token-efficient markdown, Interact handles dynamic pages, and Crawl goes deep across entire sites. For multi-hop semantic discovery, Exa's embeddings-based search and Find Similar API are strong. For verified factual answers in business intelligence workflows, Linkup's two-tier search is worth evaluating.
