
Have you ever wondered how OpenAI's Deep Research or Perplexity's AI Search really works? Behind the scenes, these systems rely on web crawling, scraping, extraction, and search. Without these services, most AI systems would struggle with hallucinations and deliver unreliable results. Tools like Firecrawl provide the core building blocks that make billion-dollar AI platforms viable.
In this article, we will explore ten AI projects you can build with Firecrawl, using it as a web extraction engine for your AI models. The projects are divided into three levels: beginner-friendly, intermediate, and advanced SaaS projects. Each comes with step-by-step guidance and source code, so you can replicate and build your own AI applications quickly.
Quick Navigation:
- Beginner Projects - No coding required
- Intermediate Projects - Python/JavaScript
- Advanced Projects - Production-ready SaaS
What is Firecrawl?
Firecrawl is the context API to search, scrape, and interact with the web at scale. It's an API service that takes any URL, crawls it, and transforms the content into clean, structured, LLM-ready data. Unlike traditional scrapers, Firecrawl does not require a sitemap and can automatically discover all accessible subpages, providing reliable streams of content in formats that AI can utilize immediately.
Firecrawl is designed for developers, researchers, and AI agents who need reliable AI agent tools. It handles complex technical challenges such as JavaScript rendering, dynamic content, proxies, and data structuring, so you don't have to. With a single API call, you can generate results in markdown, JSON, summaries, or screenshots, making it easy to build AI applications and power search, workflows, and intelligent systems at scale.
Firecrawl's APIs:
- Scrape: Extract a single URL into LLM-ready formats such as markdown, JSON, summary, screenshot, or HTML
- Crawl: Automatically scrape all URLs from a website and return their content
- Map: Generate a complete list of a site's URLs quickly
- Search: Search the web and retrieve full page content from the results
- Extract: Pull structured data from one page, multiple pages, or entire sites using AI.
Key Features:
- LLM-ready outputs: Formats include markdown, summaries, structured JSON, screenshots, HTML, and metadata
- Handles complexity: Operates with proxies and dynamic or JavaScript-rendered content
- Fast and scalable: Designed for speed and high-throughput use cases
- Customizable: Control crawl depth, headers, and tag exclusions
- Media parsing: Extract text from PDFs, DOCX files, and images
- Actions support: Includes features for clicking, scrolling, inputting, and waiting before extracting content
- Built for reliability: Delivers accurate results even in the most challenging environments.
Starter Firecrawl Projects for AI Automation: Level 1
These beginner-friendly Firecrawl projects use visual tools and simple workflows, allowing you to create powerful AI solutions without needing to write complex code. These projects are great for AI-powered workflows and agentic systems. They have either tutorial guides, templates, or visual interfaces, making it easy for anyone to get started.
1. AI-powered Market Intelligence Bot
An AI-powered Market Intelligence Bot continuously monitors trusted news and niche sources. It automatically scrapes articles, filters them by keywords and sentiment, and transforms high-value updates into concise, decision-ready insights.
This bot saves hours of manual tracking by highlighting competitor moves, emerging trends, and customer sentiment. It reduces noise through deduplication and delivers summaries directly to Slack or email. Users can easily customize the sources, topics, and frequency of these updates.
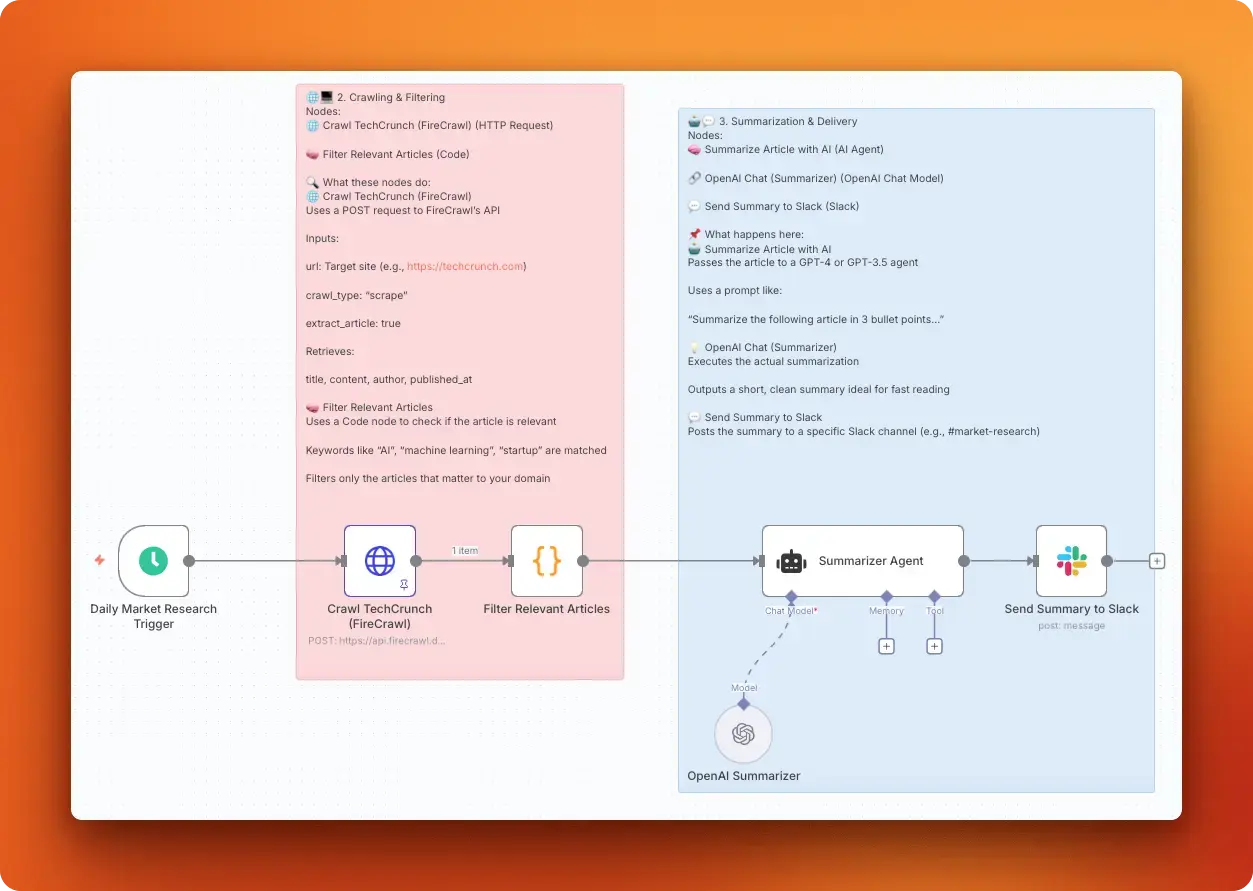
This workflow shows you how to:
- Use Firecrawl's
/scrapeendpoint (via an HTTP node) to handle JavaScript-heavy pages and dynamic content. - Filter and deduplicates articles in a JavaScript step using keywords and basic sentiment.
- Summarize each article into three bullet points with OpenAI's
gpt-4o-mini. - Run on a schedule and posts “AI Research Summary” messages with titles and links to Slack (or email).
- Include simple configuration, logging, and retries for reliability.
Skills you will learn:
- HTTP API integration with Firecrawl (/scrape)
- Web scraping and structured data parsing
- JavaScript filtering, deduping, and basic sentiment scoring
- Prompt design and concise AI summarization
- Slack/email delivery and message formatting
- Scheduling, monitoring, and error handling
- Config-driven customization (sources, keywords, frequency)
Guide: Web Scraping with n8n: 8 Powerful Workflow Templates
Import link: AI-powered market intelligence bot
How to start: This is a pre-built n8n workflow. Click "Use for free" to import it into your n8n instance and customize it for your needs.
2. Build a PDF RAG System with LangFlow and Firecrawl
Develop a robust PDF Retrieval-Augmented Generation (RAG) system that addresses the challenges of working with PDFs, including fixed layouts that disrupt the reading order, multi-column pages, tables, and images, plus scanned files that require Optical Character Recognition (OCR) processing.
This RAG system enables your team to search for, retrieve, and discuss clean and reliable context from actual documents. The result is a fast and maintainable knowledge assistant that transforms cumbersome PDFs into accurate, easily accessible answers for everyday use.
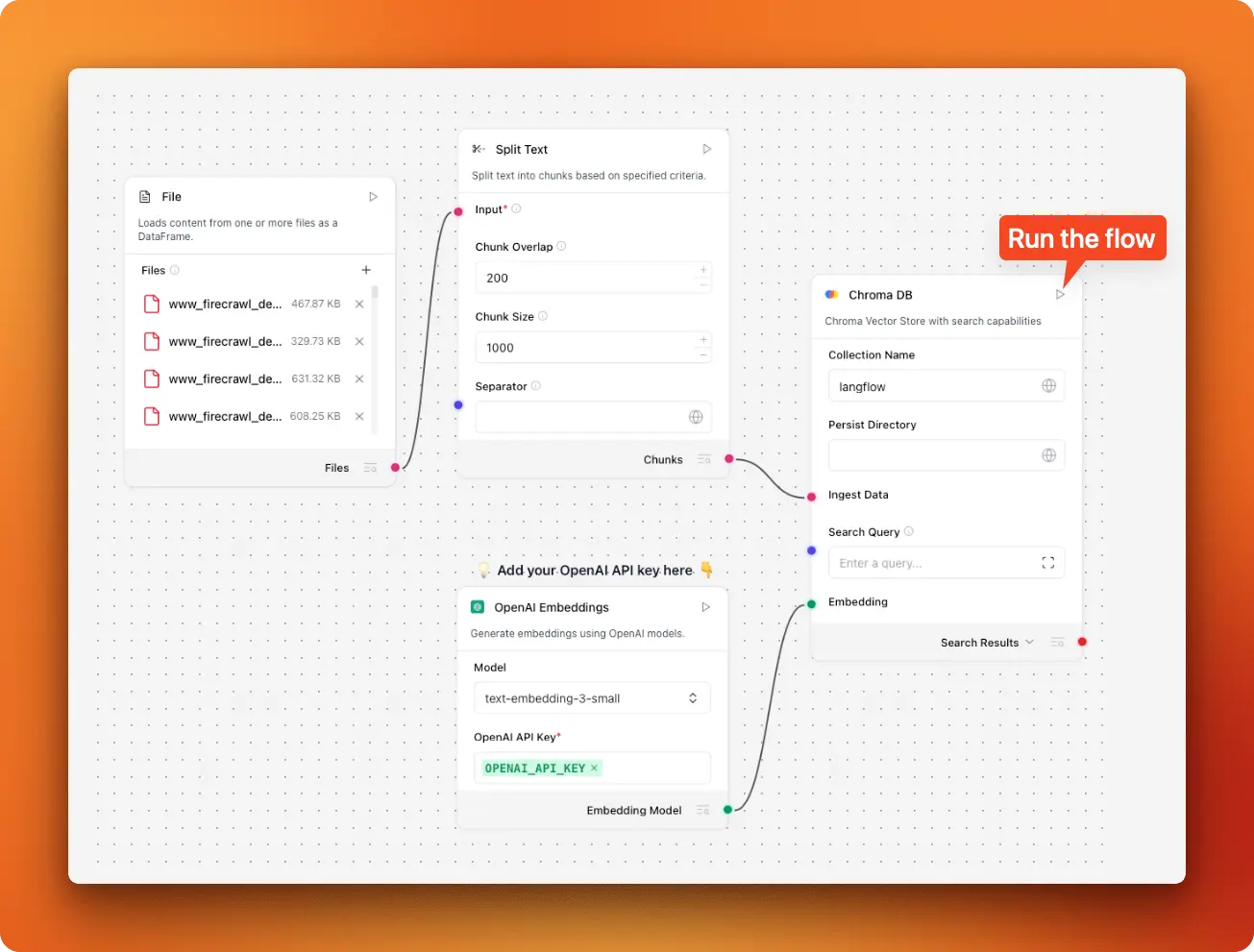
This workflow shows you how to:
- Collect PDFs from websites using Firecrawl's web-to-PDF conversion (map links, filter, download) for a fresh, scalable corpus.
- Ingest documents in LangFlow's Vector Store RAG template (file loader, text splitter, embeddings, vector DB).
- Swap Astra DB for Chroma for simple local use, wiring chunks and embeddings for both ingestion and QA flows with a shared collection name.
- Expose the flow as a REST API and adds a Streamlit chat UI with streaming responses and chat history.
- Harden the system with better chunking and metadata, error handling and monitoring, optional authentication, re-ranking, and a path to scale the vector store.
Skills you will learn:
- Diagnosing PDF-to-text issues and OCR basics for scanned documents
- Firecrawl API usage for mapping sites and web-to-PDF collection
- Building visual RAG pipelines in LangFlow (ingestion + QA)
- Working with embeddings and ChromaDB as a vector database
- Effective chunking and metadata design for better retrieval
- Creating a Streamlit chat frontend via LangFlow's REST API
- Reliability practices: logging, error handling, monitoring, re-ranking, and scaling.
Guide: Building a PDF RAG System with LangFlow and Firecrawl
How to start: This uses LangFlow's pre-built Vector Store RAG template. Import it and follow the tutorial to customize it for PDF processing.
3. Firecrawl Search to Slide Show
Turns web search into presentation slides. Using Firecrawl's /search endpoint, this JavaScript project finds topic-relevant pages and retrieves full page content in a single call, then distills multi-source material into accurate, concise slide bullets with optional speaker notes. The output includes an interactive HTML slideshow and an exportable JSON outline, creating rich, well-structured presentations quickly without manual copy-pasting.
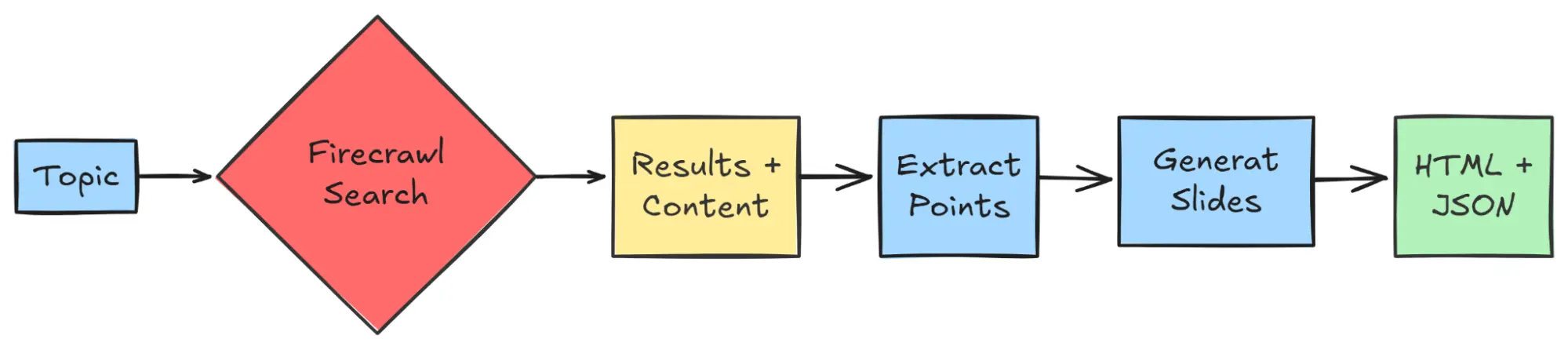
This workflow shows you how to:
- Queries Firecrawl's
/searchwith your topic and enables built-in scraping to fetch cleaned page content in one step. - Normalizes and deduplicates results, extracting titles, key points, and supporting facts.
- Uses an OpenAI model to generate slide bullets and optional speaker notes from aggregated context.
- Structures content into a slide schema (sections, slides, bullets, links) and renders an interactive HTML slideshow; also supports JSON export.
- Adds reliability basics: configurable topic, max results, rate limits, retries, and simple content filters.
Skills you will learn:
- Firecrawl Search API basics (
/searchwith scraping) - Multi-source data cleaning and deduplication
- Prompting for concise slide generation
- JSON slide schema design and HTML rendering
- OpenAI model integration for summarization
- Rate limiting, retries, and simple logging for reliability.
GitHub: firecrawl-app-examples/search-to-slides
How to start: This is a complete working example. Clone the repo and examine the code to learn the implementation patterns.
Mid-Level Firecrawl Projects for Real-World Use Cases: Level 2
Mid-level Firecrawl projects require some coding experience and can be complex. Anyone can follow the provided guides to build AI applications in just a few hours. The clear instructions and resources make it accessible, even for those who may not feel completely confident in their coding skills.
4. Travel Deal Finder with FireCrawl
Build and deploy a Travel Deal Finder that searches the web for flights, summarizes the best options, and provides booking links using Kimi K2 (via Groq) and the Firecrawl API. It aggregates recent airline and OTA pages, structures results by airline, route, price, and key restrictions, supports an optional deep-scrape for richer details, offers a clean Gradio UI, and ships to Hugging Face Spaces for easy access.
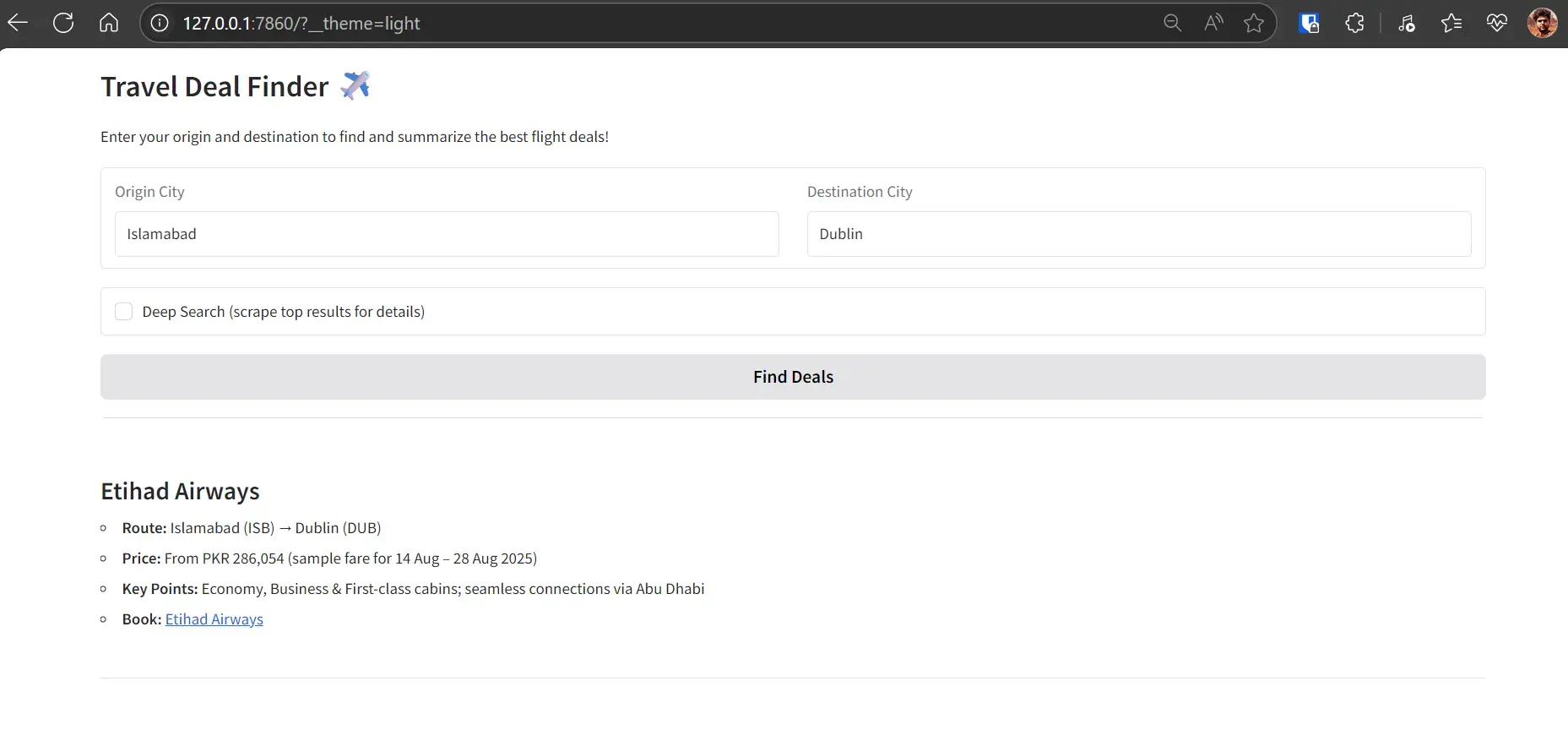
You will build a lightweight workflow that:
- Uses Firecrawl Search to fetch recent flight results for a given route (e.g., “New York to Tokyo”)
- Optionally scrapes top result pages with Firecrawl Scrape to pull page content for deeper details
- Summarizes and structures results with Kimi K2 via Groq (airline, route, price, key points, booking link)
- Builds a Gradio web UI with origin/destination inputs and a “Deep Search” toggle, runnable locally
- Deploys on Hugging Face Spaces.
Skills you will learn:
- Firecrawl Search and Scrape API usage
- Groq SDK for structured summarization
- Prompt design for concise, schema-driven outputs
- Data cleaning and deduplication of multi-source results
- Gradio UI development and local testing
- Hugging Face Spaces deployment and secret management
Guide: Building AI Applications with Kimi K2: A Complete Travel Deal Finder Tutorial
GitHub: kingabzpro/Travel-with-Kimi-K2
Demo: Travel With Kimi K2
5. Medical Prescription Analyzer
Create a Medical Prescription Analyzer using Grok 4 that can read prescription images, extract medication names, and compile dosage information, prices, availability, and purchase links. This involves using tool calls and web searches with scraping. The output is a clear, markdown report suitable for real-world use.
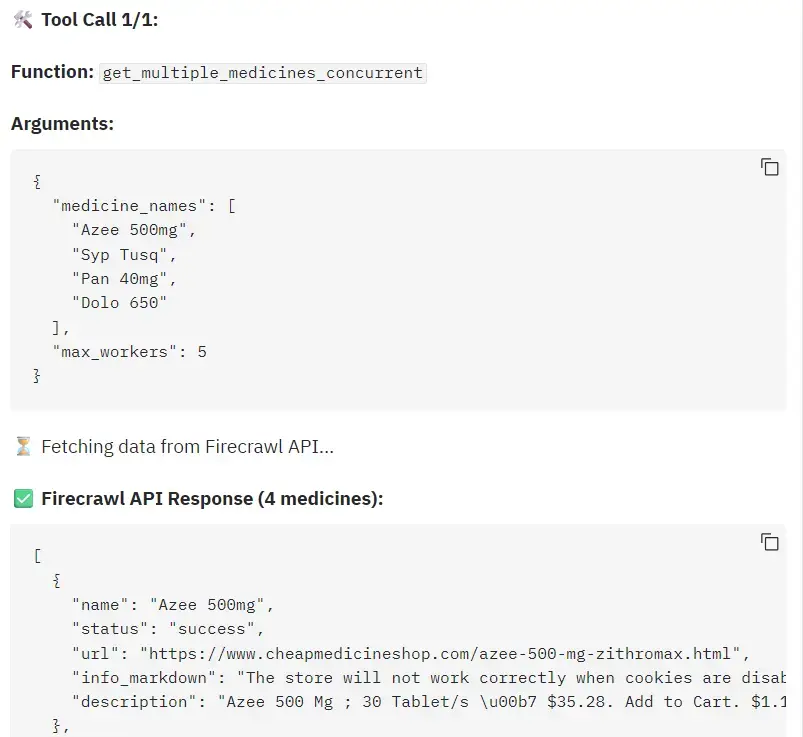
You will build an agentic workflow that:
- Set up the xAI SDK client for Grok 4.
- Accepts a prescription image, encodes it to base64, and starts a Grok 4 image-analysis chat.
- Defines two tools (single-medicine fetch and concurrent multi-medicine fetch) and lets the model auto-call them, using function calling.
- Uses Firecrawl search with built-in scraping to retrieve markdown from pharmacy sites for price/availability.
- Aggregates tool results and generates a structured markdown report with sections per medicine
- Adds concurrency, timeouts, and simple logging for reliability
- Optionally ships a Gradio UI to upload images and stream the final report.
Skills you will learn:
- xAI SDK integration and Grok 4 tool/function calling
- Vision input handling and base64 image encoding
- Firecrawl search/scrape for structured markdown data
- Concurrent fetching with
ThreadPoolExecutorand timeouts - Schema-driven prompt design and markdown report generation
- Gradio UI basics, streaming, and simple logging/error handling.
Guide: Building a Medical AI Application with Grok 4
GitHub: kingabzpro/Medical-AI-with-Grok4
6. Automated Price Tracking
Build an Automated Price Tracking Assistant that monitors products you choose across e-commerce sites, stores price history, and alerts you when discounts cross a threshold. It uses a minimal Streamlit UI to add products, Firecrawl for resilient AI scraping (including name, price, and image), a Postgres database for historical storage, and GitHub Actions for scheduled checks. It works for most sites and is free-tier friendly for personal use.
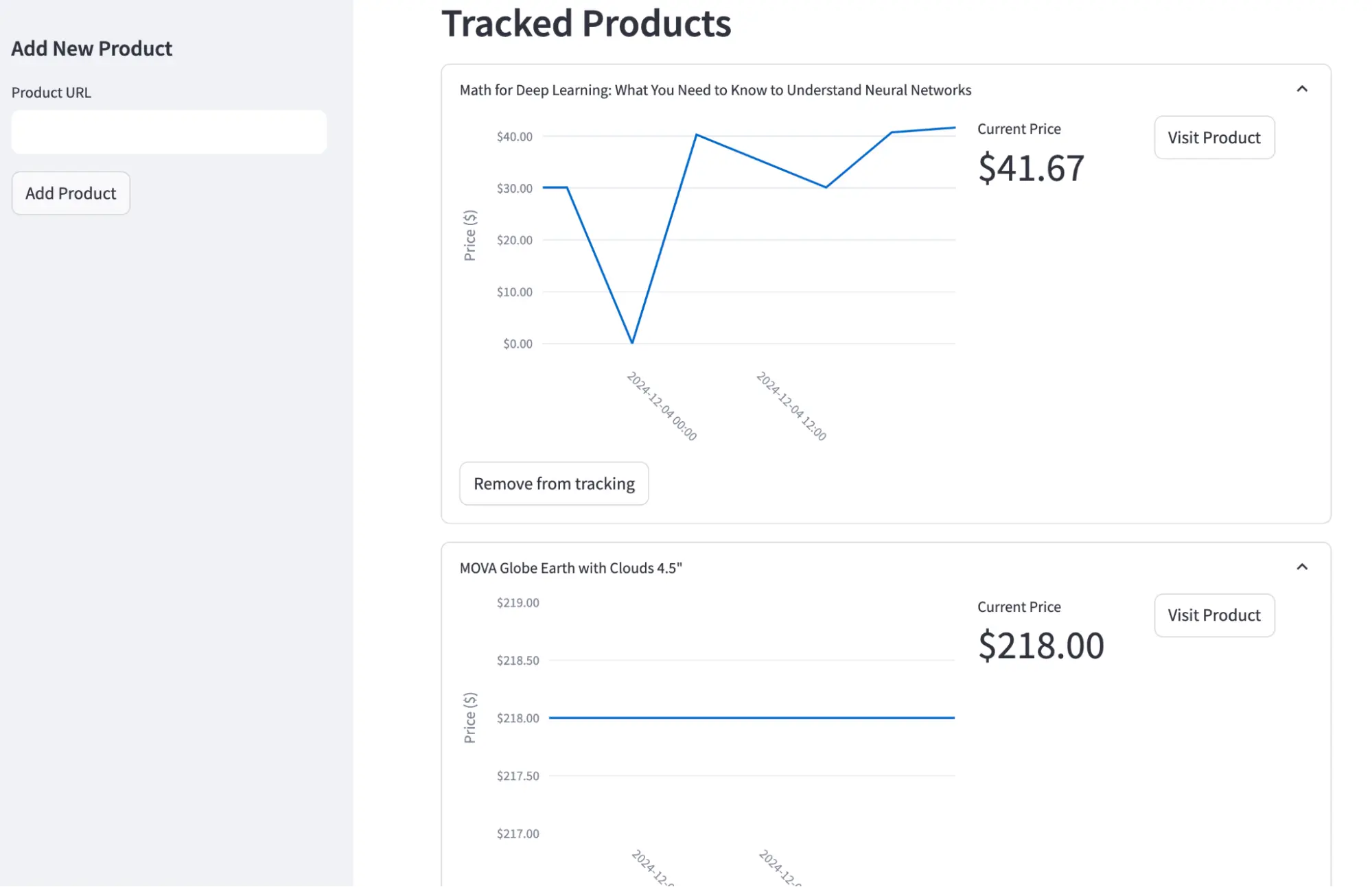
You will build an end to end workflow that:
- Creates a Streamlit UI with a sidebar to add product URLs, input validation, and a dashboard showing each item's price history
- Uses Firecrawl to scrape product name, price, currency, image, and timestamp into a normalized schema for consistent storage
- Defines a Postgres schema with SQLAlchemy (Product and PriceHistory) and helper methods to add products and append price snapshots
- Implements a price checker script that scrapes current prices, stores new snapshots, and visualizes trends with Plotly charts in the UI
- Schedules recurring checks via a GitHub Actions workflow (cron) with secrets for API keys and database URL
- Sends Discord notifications via webhook when the current price drops beyond a configurable percentage threshold.
Skills you will learn:
- Streamlit UI design and basic state handling
- Firecrawl scraping and structured extraction with Pydantic schemas
- URL validation utilities in Python
- SQLAlchemy ORM modeling and Postgres on Supabase
- Plotly and pandas for time-series visualization
- GitHub Actions scheduling, secrets, and CI basics
- Async notifications with
aiohttpand Discord webhooks
Guide: Building an Automated Price Tracking Tool
GitHub: firecrawl-app-examples/automated_price
7. Startup Idea Validator
Build a Startup Idea Validator that uses a LangGraph ReAct agent to assess market potential, community sentiment, and technical feasibility, combining Firecrawl-powered web research with Hacker News and GitHub signals, and presenting results in a responsive Streamlit chat UI with live tool progress and conversation memory for iterative validation.
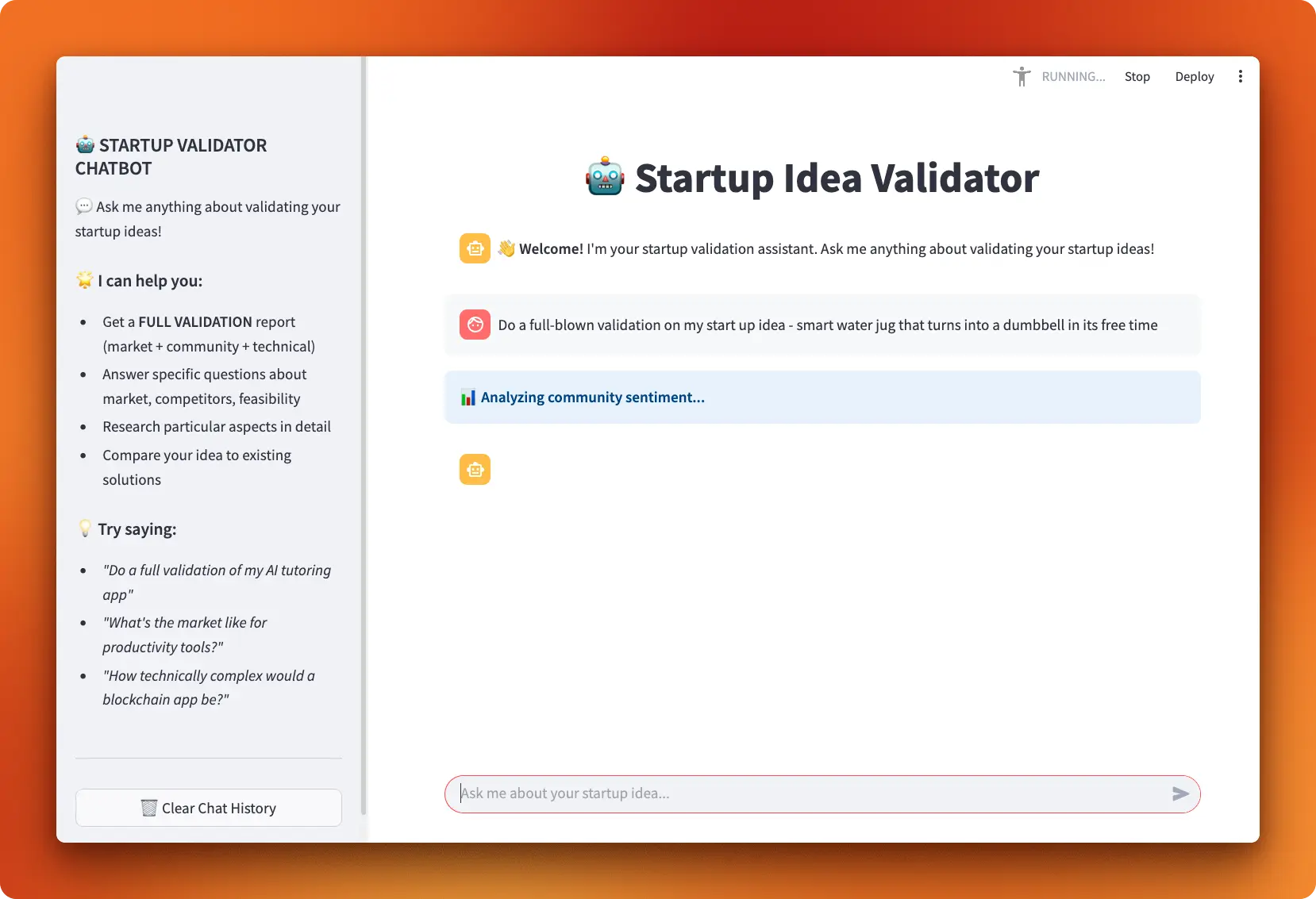
You will build an AI agentic workflow that:
- Implements three research tools
a. Firecrawl Search for market landscape
b. Hacker News (Algolia) for sentiment c. GitHub search for technical signals - Creates a LangGraph ReAct agent with memory and a clear system prompt to choose tools and synthesize findings
- Defines a “full validation” mode that runs all tools and outputs a structured report
- Builds a Streamlit chat interface that streams model responses, shows live tool activity, and maintains chat history.
- Manages configuration and secrets via .env (OpenAI, Firecrawl, GitHub), with basic error handling and status messaging for reliability .
Skills you will learn:
- LangGraph ReAct agents, tool orchestration, and memory
- Firecrawl Search API integration for market research
- Using Hacker News Algolia and GitHub REST APIs for sentiment and feasibility
- Prompt design for tool usage and structured decision report
- Streamlit chat apps with dual-mode streaming and session state
- Secrets management with dotenv and practical error handling
Guide: LangGraph Tutorial: Build a Startup Idea Validator with Interactive UI
Expert Firecrawl Projects for Scalable AI Systems: Level 3
These advanced Firecrawl projects are fully open source, actively maintained, and highly stable, making them suitable for deployment in production environments. They are designed for developers with strong coding skills who want to build or enhance scalable AI systems. Each project uses Firecrawl's powerful, enterprise-grade crawling, web search, and data extraction capabilities.
8. Open Deep Research with Firecrawl
Explore and run this advanced, self-hosted Open Deep Research Platform designed to replicate OpenAI's Deep Research capabilities. This platform orchestrates multi-step web investigations using live data by integrating Firecrawl for search, scraping, and extraction with robust LLM reasoning. It streams results through a real-time chat user interface (UI) and preserves sessions and files for continuity. The solution is cost-effective, customizable, and can be run entirely locally with Docker (using Postgres, Redis, and Minio) and the Next.js App Router.
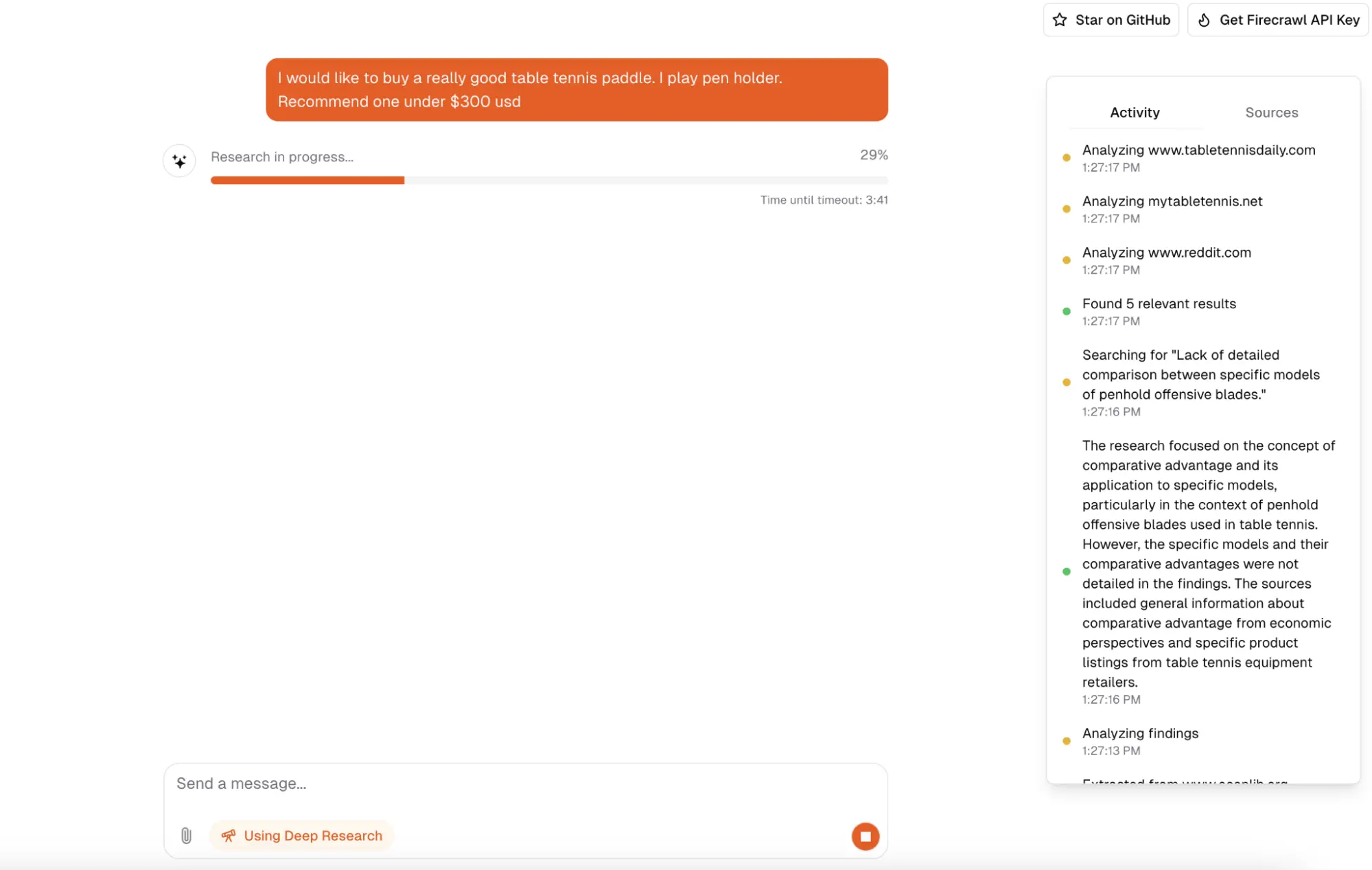
This projects demonstrates a complete SaaS workflow that:
- Runs PostgreSQL, Redis, and MinIO locally using Docker Compose, and to start the Next.js application, use the command `pnpm dev`
- Implements a streaming chat backend using Vercel AI SDK route handlers, configurable to OpenAI or Together models via environment variables.
- Integrates Firecrawl search, scrape, and extract to gather, clean, and structure web data
- Adds authentication and state management using NextAuth.js with support for anonymous sessions. It implements Upstash Redis for rate limiting, connects to a PostgreSQL database via Drizzle for chat history, and utilizes Vercel Blob for file uploads
- Builds a polished UI with Tailwind + shadcn/ui + Radix and Framer Motion. It showcases live tool progress and provides token-by-token responses. Additionally, there is an option to integrate Vercel CLI for environment and deployment workflows and Firecrawl CLI to agents real-time web data.
Skills you will learn:
- Next.js App Router, SSR, and React Server Component
- Vercel AI SDK streaming, object generation, and provider switching
- Firecrawl search/scrape/extract for real-time web data
- Auth with NextAuth.js, anonymous sessions, and rate limiting with Upstash Redis
- Postgres + Drizzle ORM schemas/migrations and Vercel Blob storage patterns
- Real-time chat UX with streaming and tool-status telemetry
- Docker Compose for local Postgres/Redis/Minio orchestration
- Reliability basics: error handling, logging, and monitoring in production-ready APIs
GitHub: nickscamara/open-deep-research
Guide: Building a Clone of OpenAI's Deep Research with TypeScript and Firecrawl
How to start: This is a production-ready codebase. The guide explains the architecture and how to run it locally. Clone the repo to explore and customize the implementation.
9. FireGEO Open-Source SaaS Starter
The FireGEO Starter Kit for building Generative Engine Optimization (GEO) SaaS products includes a GEO-first brand monitoring engine, multi-provider AI analysis (featuring OpenAI, Anthropic, and Perplexity), Firecrawl-powered web scraping, BetterAuth for authentication, and Stripe for subscriptions and usage billing. It features a PostgreSQL and Drizzle backend, all built on a production-ready Next.js 15 and Tailwind CSS stack. With this kit, you can concentrate on developing GEO features and launch your product in days instead of months.
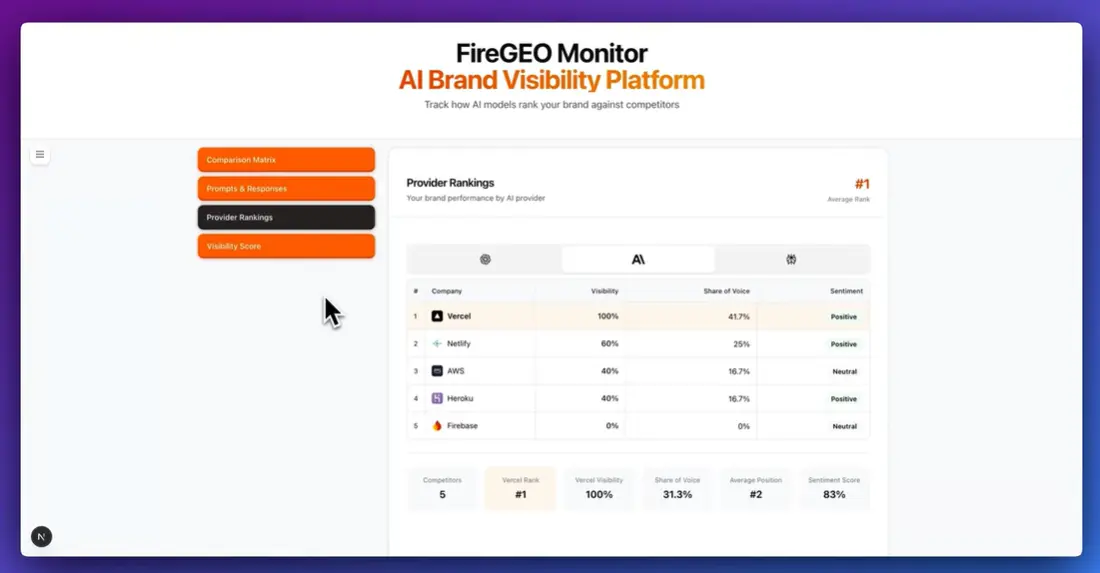
Try the open source repo by:
- Cloning the FireGEO repo, configures .env, runs npm run setup, and boots the app locally (auth, billing, DB, dashboards ready)
- Connects Firecrawl to gather clean, markdown-ready content from target sources for brand monitoring and competitor tracking
- Enables multi-provider AI analysis to score visibility, sentiment, and competitor mentions and generate GEO insights
- Configures Stripe plans (seats/usage), webhooks, and a customer portal; adds RBAC for teams
- Customizes prompts, providers, and monitoring rules; ships a responsive UI for reporting and alerts.
Skills you will learn:
- GEO-focused product design and brand monitoring
- Firecrawl integration for structured web content
- Multi-provider AI orchestration (OpenAI, Anthropic, Perplexity)
- Next.js 15 and Tailwind UI customization
- Stripe subscriptions, usage metering, and webhooks
- Postgres + Drizzle schema design and querying
- Authentication, roles, and team management
GitHub: firecrawl/firegeo
Guide: FireGEO: Complete SaaS Template for GEO Tools
How to start: This is a complete SaaS starter kit. Clone the repo and customize the pre-built components.
10. Fireplexity AI Search Engine
Fireplexity is an open-source Next.js answer engine that delivers real-time, cited answers instead of link lists. It uses Firecrawl to handle JavaScript-heavy pages and reliably scrape the web, scores and selects the most relevant content, then streams synthesized answers with inline, hoverable citations. It's vendor-flexible (use GPT-4o-mini or swap in any OpenAI-compatible endpoint) and showcases vertical features like live stock chart detection for over 180 companies to demonstrate end-to-end control of the pipeline.
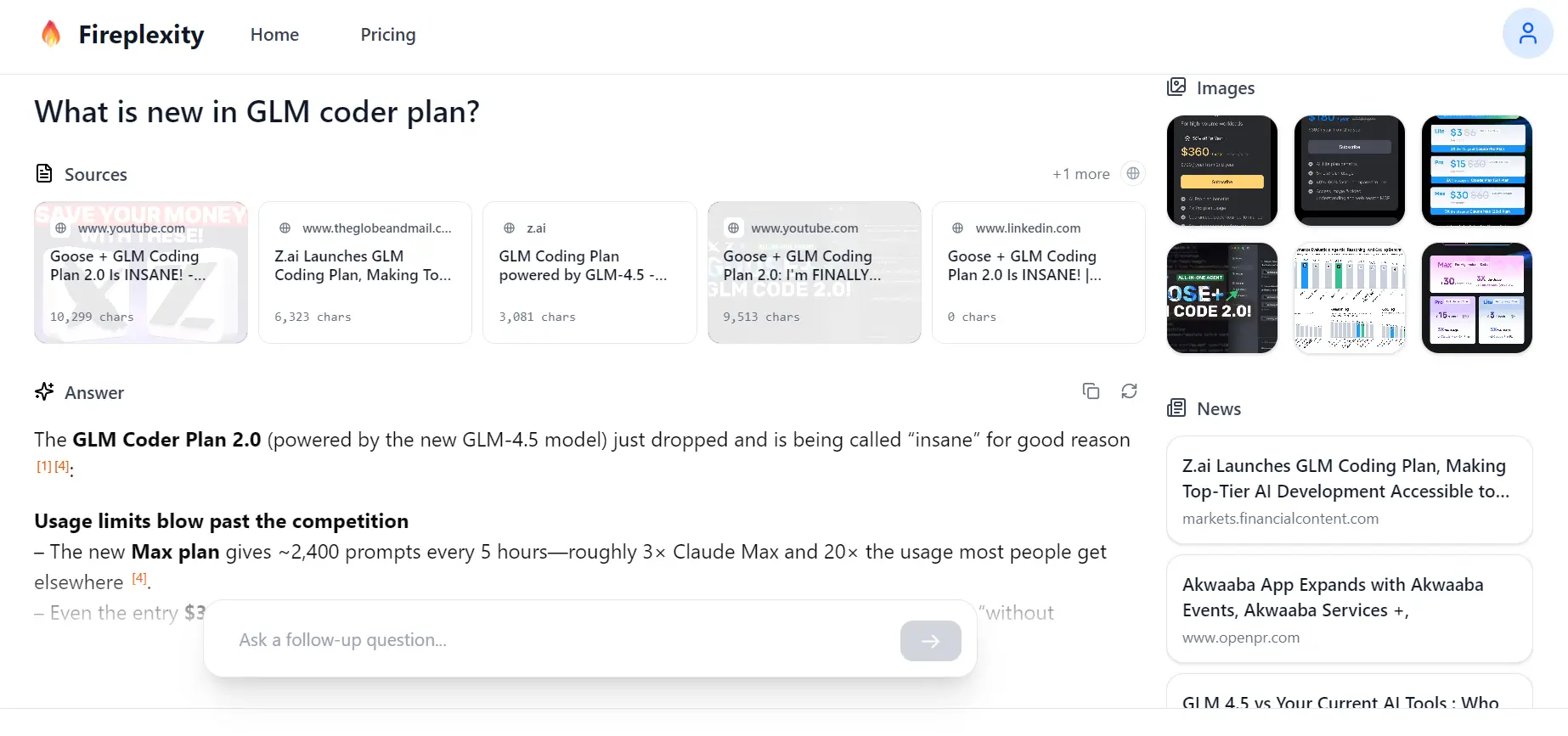
This projects demonstrates a complete workflow that:
- Accepts a query, searches the web with Firecrawl, and gathers candidate pages for answering.
- Ranks and deduplicates results, selecting the highest-signal passages.
- Scrapes selected URLs to clean markdown/HTML and extracts key facts/snippets.
- Streams answer synthesis with inline citations using GPT-4o-mini (or any OpenAI-compatible model).
- Renders an interactive Next.js UI with citation previews, optional live stock charts, and basic config/logging, rate limits, and retries.
Skills you will learn:
- Next.js app setup and streaming UI patterns
- Firecrawl search/scrape integration and content cleaning
- Relevance scoring, deduplication, and passage selection
- Prompt design for cited, real-time answer synthesis
- Interactive citation rendering with hover previews
- Model provider abstraction (OpenAI-compatible endpoints)
- Reliability basics: rate limiting, retries, and logging
- Optional finance data integration for live chart widgets
Demo: Fireplexity v2 - AI-Powered Multi-Source Search
GitHub: firecrawl/fireplexity
How to start: This is a production-ready open-source project. The announcement post provides a high-level overview. To learn how it works, clone the GitHub repository and study the codebase.
Getting the Most Out of Firecrawl
We've covered different AI projects you can build with the Firecrawl API, but here's how to get maximum value from them.
1. Choose the Right Endpoint for the Job
Before diving into endpoints, identify your primary goals. Firecrawl offers several endpoints, each optimized for different use cases:
/scrape: Ideal for quickly grabbing a single page's content/crawl: Great for gathering an entire site's docs, just set an appropriate depth limit to avoid unnecessary crawling/map: Use this when you only need to discover or list URLs, not their content/search: Combines a Google-like search with automatic scraping of results for open-ended information queries.
2. Leverage LLM Extraction for Structured Data
The /extract endpoint lets you define a prompt or JSON schema so pages come back as clean, structured fields. This removes a lot of post-processing, turns messy HTML into predictable JSON, and gives you lightweight domain parsers without writing custom scrapers.
3. Integrate with Agent Frameworks
Firecrawl becomes more powerful when used inside LangGraph, CrewAI, or OpenAI Agents. Agents can decide when to search, crawl, or extract, loop until they have enough context, and hand structured results to downstream tools. The outcome is autonomous, end-to-end data gathering with fewer brittle scripts.
4. Use the Playground
Use the Firecrawl Playground to test endpoints, tune options, and preview responses before you write a single line of code. You can experiment from the dashboard or main site in many cases without signing up. This is the fastest way to validate selectors, filters, and depth settings for your use case.
5. Learn from Firecrawl Tutorials
For more in-depth instructions and inspiration, take advantage of Firecrawl's growing library of tutorials. Check out the Firecrawl blog to learn about new integrations, projects, use cases, tools, and much more. Our library is continually expanding, and we publish the latest resources and technologies to keep our readers updated and engaged with us.
6. Optimize for Costs and Rate Limits
To optimize costs and manage rate limits, track your usage in the dashboard. Trim down high-cost operations such as deep crawls or PDF parsing. Use aggressive filtering for your requests: for the /scrape endpoint, utilize includeTags, excludeTags, and onlyMainContent; for the /crawl endpoint, apply includePaths, excludePaths, set a limit, and define the maxDiscoveryDepth. Schedule larger jobs during off-peak hours. Consider using an open-source or self-hosted runner for handling large workloads, but be aware that some features are available only in the cloud.
7. Build with Battle-Tested Templates
Don't start from scratch! Save time by adapting community examples. The firecrawl/firecrawl-app-examples repo and the Firecrawl organization on GitHub include ready-to-run projects and patterns for common needs. Clone, configure, and extend them to your stack so you can move from prototype to production in days instead of weeks. For teams that need a full web research agent scaffold — custom model, self-hosted infrastructure, and skill playbooks already wired in — the open-source firecrawl-agent stack bootstraps a complete project in two commands.
Conclusion
Firecrawl is a strong companion for modern AI development. Whether you are integrating Claude Code with the Firecrawl MCP server for web searches, browsing documentation, or supplying agentic workflows with fresh context, Firecrawl provides your code editor and pipelines with reliable access to accurate and up-to-date information from the web. Regardless of how advanced a large language model (LLM) becomes, real-world applications still require live data that only web search and crawling can provide.
Read More: How Credal Extracts 6M+ URLs Monthly to Power Production AI Agents with Firecrawl
If you build with Firecrawl, you align with how the industry ships AI today: agents that read, reason, and refresh their knowledge continuously. As AI touches more of our work, grounding models in current, verifiable sources keeps them useful and trustworthy over the long run.
In this blog, we explored ten projects you can build with the Firecrawl API: three beginner, four intermediate, and three advanced. Each project includes step-by-step guidance and code, allowing you to replicate it quickly. We also covered practical tips to maximize the benefits of Firecrawl. Ready to start building? Sign up for a free account and start scraping!
Frequently Asked Questions
What is Firecrawl used for?
Firecrawl is the context API to search, scrape, and interact with the web at scale, converting web content into LLM-ready formats like markdown and JSON for RAG systems, AI agents, and data extraction.
Can I use Firecrawl for free?
Yes, Firecrawl offers a free tier with 1,000 credits per month, suitable for testing and small projects. Sign up for a free account here.
What's the difference between web scraping and web crawling?
Web scraping extracts specific data from pages, while web crawling discovers and indexes multiple pages across a site. Firecrawl does both.
Which AI projects work best with Firecrawl?
RAG systems, AI agents, price tracking, market intelligence, and any application requiring real-time web data for LLMs.
