How to Create a Dermatology Q&A Dataset with OpenAI Harmony & Firecrawl Search

Recently, OpenAI released GPT-OSS, an open-source model that uses a new structured format called Harmony from prompt instructions. Harmony creates a structured approach for defining conversation flows, generating reasoning outputs, and organizing function calls. Combined with tools like Firecrawl for web discovery, this creates interesting possibilities for automated data generation pipelines.
Creating high-quality machine learning datasets has traditionally required manual curation and expensive data collection processes. This OpenAI GPT-OSS tutorial demonstrates how open source AI models can revolutionize AI dataset creation through web scraping for AI applications. By combining GPT-OSS with Firecrawl's web discovery capabilities, developers can now build automated data generation systems that produce structured data generation at scale. We'll walk through a complete pipeline for creating domain-specific datasets that reduces both time and costs. This dataset can then be used for fine-tuning GPT-OSS models or other LLMs.
This tutorial explores this emerging tech stack by building a complete Q&A dataset generation system. We'll use dermatology as our example domain, but the techniques apply to any field where you need structured data from web sources.
We'll walk through the following steps:
- Set up accounts and API keys for Groq and Firecrawl.
- Define Pydantic model and helper functions for cleaning, normalizing, and rate-limit handling.
- Use Firecrawl Search to collect raw dermatology-related data.
- Create prompts in the OpenAI Harmony style to transform that data.
- Feed the prompt and search results into the GPT-OSS 120B model to generate a well-structured Q&A dataset.
- Implement checkpoints so that if the dataset generation pipeline is interrupted, it can resume from the last saved point instead of starting over.
- Analyze the final dataset and publish it to Hugging Face for open access.
Let's get started.
What is GPT-OSS and Harmony?
GPT-OSS represents OpenAI's first open-weight language model release since GPT-2, introduced on August 5, 2025. It's available in two variants: gpt-oss-120b (117B parameters) and gpt-oss-20b (21B parameters). Released under the Apache 2.0 license with full model weights, they make powerful reasoning capabilities accessible to individual developers and smaller organizations.
The gpt-oss models were trained on the Harmony response format for defining conversation structures, generating reasoning output and structuring function calls. Unlike traditional chat models, Harmony introduces a multi-channel output system with distinct channels for reasoning ("analysis"), tool calls ("commentary"), and user-facing answers ("final"), plus a "developer" role that can augment system instructions.
When working with the GPT-OSS 120B model, you have to construct prompts in the Harmony format before sending requests for it to work correctly. This structure enables the same reasoning and tool-use capabilities that power OpenAI's commercial offerings, but with the flexibility to run locally, customize through fine-tuning, and deploy without API dependencies.
What is Firecrawl?
Firecrawl is the context API to search, scrape, and interact with the web at scale, converting websites into clean, structured data formats like Markdown, JSON, or HTML. Unlike traditional web scrapers that require custom code for each site, Firecrawl handles JavaScript rendering, respects robots.txt, manages rate limiting, and provides consistent output across different website structures. For more advanced extraction techniques, see our guide on extracting data using LLMs.
For this tutorial, we'll use Firecrawl's Search API to discover dermatology-related content across trusted medical websites. The Search API acts like a specialized Google search that returns structured results we can immediately process with our AI pipeline, eliminating the need to manually identify and scrape individual pages.
1. Environment Setup and Installation
First, we'll start by setting up environment variables for API keys, installing Python packages, importing libraries in a Jupyter Notebook, defining variables for later use in the project, and initializing the clients and encoders.
-
Go to the Groq Cloud and create an account. Then generate the Groq API key for free access to the models.
-
You can try Firecrawl's endpoints without an API key to start. When you're ready to go further, go to the Firecrawl website, sign up, and generate a key for higher rate limits and more credits. Firecrawl also provides free but limited access to the Search API.
-
Set the generated API keys as environment variables.
export FIRECRAWL_API_KEY="your_firecrawl_key_here"
export GROQ_API_KEY="your_groq_key_here"- Install the required Python packages: Firecrawl, OpenAI Harmony, Groq, Hugging Face Datasets, and Tenacity.
pip install firecrawl-py openai-harmony groq datasets tenacity- Load all the necessary Python libraries for generation, processing, analytics, and dataset uploading.
import os
import re
import time
import json
import random
from typing import List, Dict, Any, Optional
from tenacity import retry, stop_after_attempt, wait_exponential
from tqdm.auto import tqdm
import pandas as pd
from pydantic import BaseModel, Field, ValidationError
from firecrawl import FirecrawlApp
from groq import Groq
# Harmony
from openai_harmony import (
load_harmony_encoding,
HarmonyEncodingName,
Conversation,
Message,
Role,
SystemContent,
DeveloperContent,
ReasoningEffort,
)- Set the variables for controlling the data generation pipeline. Start with a small number of samples for testing, around 10 samples, to confirm it works and to stay within the free API use tiers. Then you can increase to 1000 or more for a larger dataset with paid plans.
TARGET_SAMPLES = 10
MAX_URLS = 200
MAX_PER_QUERY_ALLOWED = 100
N_QA_PER_REQUEST = 5
GROQ_MODEL = "openai/gpt-oss-120b"
GROQ_DELAY = 2.1
FIRECRAWL_SEARCH_RPM = 6
SEARCH_DELAY = 60.0 / FIRECRAWL_SEARCH_RPM
# Groq backoff tuning
MAX_ATTEMPTS = 6
BASE_BACKOFF = 2.0
MAX_BACKOFF = 60.0
# Checkpoint paths
OUT_DIR = "data_derm_qa_search_harmony_groq"
CSV_PATH = os.path.join(OUT_DIR, "dermatology_qa_search_harmony_groq.csv")
JSONL_PATH = os.path.join(OUT_DIR, "dermatology_qa_search_harmony_groq.jsonl")
TMP_JSONL = JSONL_PATH + ".tmp"
TMP_CSV = CSV_PATH + ".tmp"- Using the API keys, initialize the Firecrawl and Groq clients.
assert os.getenv("FIRECRAWL_API_KEY"), "Set FIRECRAWL_API_KEY"
assert os.getenv("GROQ_API_KEY"), "Set GROQ_API_KEY"
fc = FirecrawlApp(api_key=os.getenv("FIRECRAWL_API_KEY"))
groq_client = Groq(api_key=os.getenv("GROQ_API_KEY"))- Load the Harmony encoder for prompt encoding.
encoding = load_harmony_encoding(HarmonyEncodingName.HARMONY_GPT_OSS)2. Data Model and Helper Utilities
In this section, we define the necessary helper functions and data model for validation. These utilities help us create reliable data pipelines with built-in retry logic, logging, checkpointing, and data cleaning.
QAItem:Defines the Q&A item format with validation rules. This function ensures questions, answers, and metadata meet length and format requirements.
class QAItem(BaseModel):
question: str = Field(..., min_length=12)
answer: str = Field(..., min_length=80) # Force detailed answers
condition: str = Field(..., min_length=3)
difficulty: str = Field(..., pattern="^(easy|medium|hard)$")
source_url: str-
show_sample:This helper function provides a quick way to inspect the dataset by printing the first available row. -
normalize_question:This function standardizes question text to make it consistent and easier to compare or deduplicate. -
_parse_retry_after: This utility looks for "retry after Xs" in a message. If found, it extracts the number of seconds and returns it as a float; otherwise, it returnsNone. -
_sleep_backoff: This function manages waiting between retries when requests fail or hit rate limits. If the server explicitly specifies a wait time, it uses that value (plus a small buffer) before retrying. If no wait time is given, it applies an exponential backoff strategy with a random jitter to spread out retries and reduce the chance of repeated collisions.
def show_sample(stage: str, rows: List[Dict[str, Any]]) -> None:
print(f"\n--- Sample @ {stage} ---")
try:
print(json.dumps((rows or [{}])[0], ensure_ascii=False, indent=2)[:1200])
except Exception:
print((rows or [{}])[0])
def normalize_question(q: str) -> str:
return " ".join(q.lower().split()).rstrip("?.!")
def _parse_retry_after(msg: str) -> Optional[float]:
m = re.search(r"retry after\s*(\d+)s", msg, re.I)
if m:
return float(m.group(1))
return None
def _sleep_backoff(attempt: int, server_msg: str = "") -> None:
ra = _parse_retry_after(server_msg)
if ra is not None:
to_sleep = min(MAX_BACKOFF, ra + 1.0)
tqdm.write(f"Rate limit: server asked for {ra}s -> sleeping {to_sleep:.1f}s")
time.sleep(to_sleep)
return
backoff = min(MAX_BACKOFF, BASE_BACKOFF * (2 ** (attempt - 1)))
jitter = random.uniform(0.2, 1.0)
to_sleep = backoff + jitter
tqdm.write(f"Backoff: attempt {attempt}, sleeping {to_sleep:.1f}s")
time.sleep(to_sleep)-
load_checkpointattempts to read previously saved data, preferring CSV for speed but falling back to JSONL if necessary, ensuring that work can resume without starting over. -
save_checkpointwrites the current dataset to both CSV and JSONL formats, using temporary files and atomic replacement to prevent corruption if the process is interrupted.
Together, they make the data pipeline fault-tolerant and efficient.
def load_checkpoint() -> List[Dict[str, Any]]:
"""
Load existing saved items from CSV or JSONL. Return list of dicts.
Preference: CSV if exists (faster), else JSONL.
"""
if os.path.exists(CSV_PATH):
try:
df = pd.read_csv(CSV_PATH)
records = df.to_dict(orient="records")
tqdm.write(f"Loaded {len(records)} existing rows from {CSV_PATH}")
return records
except Exception as e:
tqdm.write(f"Failed to read CSV checkpoint: {e}")
if os.path.exists(JSONL_PATH):
try:
recs = []
with open(JSONL_PATH, "r", encoding="utf-8") as f:
for line in f:
if not line.strip():
continue
recs.append(json.loads(line))
tqdm.write(f"Loaded {len(recs)} existing rows from {JSONL_PATH}")
return recs
except Exception as e:
tqdm.write(f"Failed to read JSONL checkpoint: {e}")
return []
def save_checkpoint(all_items: List[Dict[str, Any]]) -> None:
"""
Atomically write JSONL and CSV checkpoint files for all_items.
"""
os.makedirs(OUT_DIR, exist_ok=True)
# Write JSONL tmp
try:
with open(TMP_JSONL, "w", encoding="utf-8") as f:
for rec in all_items:
f.write(json.dumps(rec, ensure_ascii=False) + "\n")
os.replace(TMP_JSONL, JSONL_PATH)
except Exception as e:
tqdm.write(f"Failed to write JSONL checkpoint: {e}")
# Write CSV tmp
try:
df = pd.DataFrame(all_items)
df.to_csv(TMP_CSV, index=False)
os.replace(TMP_CSV, CSV_PATH)
except Exception as e:
tqdm.write(f"Failed to write CSV checkpoint: {e}")
tqdm.write(f"Checkpoint saved: {len(all_items)} rows -> {JSONL_PATH}, {CSV_PATH}")clean_items: This function filters and corrects dataset entries to maintain quality standards.
def clean_items(items: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
out: List[Dict[str, Any]] = []
for it in items:
if len(it.get("answer", "")) < 80:
continue
if not it.get("condition"):
continue
diff = it.get("difficulty", "").lower()
if diff not in {"easy", "medium", "hard"}:
it["difficulty"] = "medium"
out.append(it)
return out3. Web Discovery with Firecrawl (Rate‑Limited Search)
The firecrawl_search_with_ratelimit function automates web discovery for dermatology-related content by running multiple targeted search queries through the Firecrawl API.
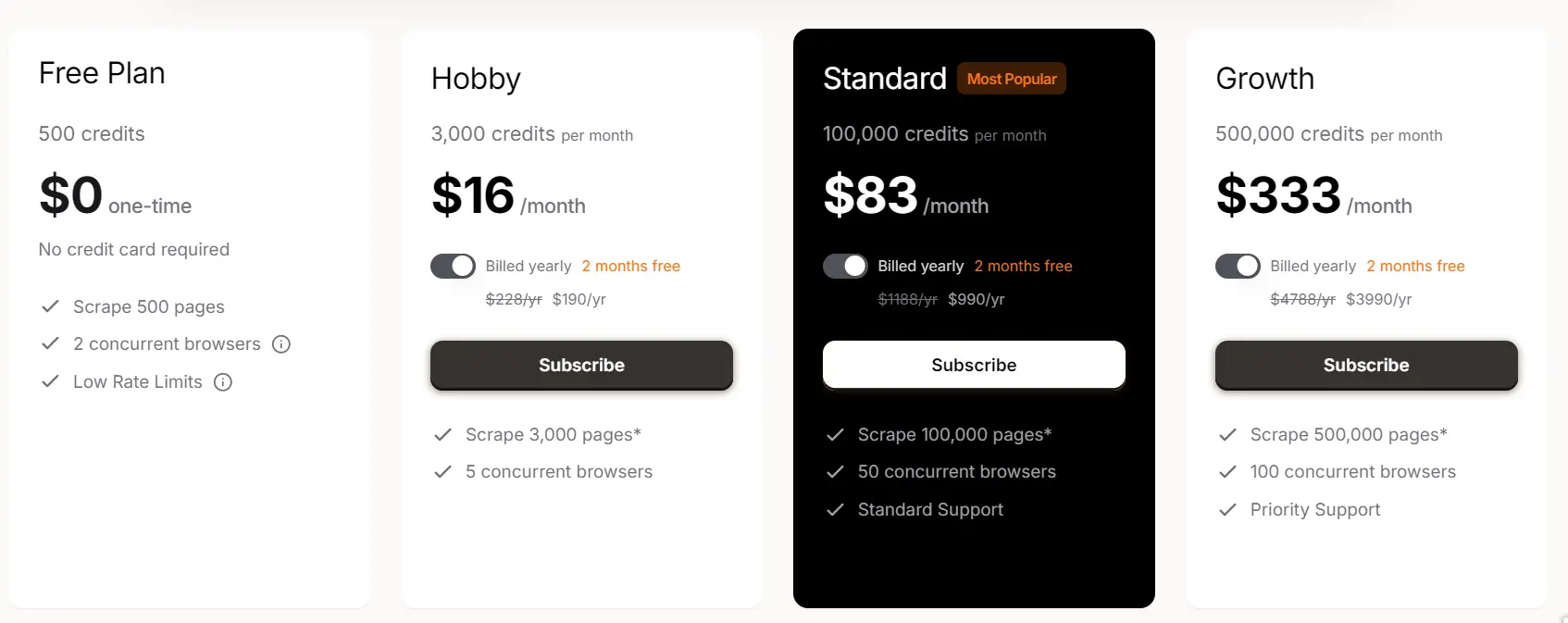
Note: The Firecrawl API offers free credits for new users, but these come with rate limits and are insufficient for generating a dataset of 1,000 samples.
For large-scale data collection, subscribe to the "Standard" plan via the Firecrawl Pricing Page.
We will create a list of queries and URLs:
- DERM_QUERIES: These are Google-like search strings targeting sites or topics about dermatology.
- DEFAULT_URLS: These are fallback links in case the search fails or returns too few results.
Then, we will define the firecrawl_search_with_ratelimit function, which will:
- Split your total search limit across multiple queries.
- Search the web for dermatology-related queries using the Firecrawl API.
- Retry if rate-limited.
- Collect unique URLs from search results.
- Stop when a given limit of results is reached.
- Show progress in the terminal.
DERM_QUERIES = [
"site:dermnetnz.org acne",
"site:aad.org eczema",
"site:nhs.uk rosacea",
"site:dermnetnz.org psoriasis",
"site:aad.org melanoma",
"dermatology common skin conditions overview",
"dermatitis causes symptoms",
]
DEFAULT_URLS = [
{"url": "https://dermnetnz.org/topics/acne", "title": "Acne"},
{"url": "https://dermnetnz.org/topics/eczema", "title": "Eczema"},
{"url": "https://dermnetnz.org/topics/psoriasis", "title": "Psoriasis"},
]
def firecrawl_search_with_ratelimit(queries: List[str], limit: int) -> List[Dict[str, Any]]:
results: List[Dict[str, Any]] = []
seen = set()
per_query = max(1, limit // max(1, len(queries)))
per_query = min(per_query, MAX_PER_QUERY_ALLOWED)
print(f"Search: per_query={per_query} (capped at {MAX_PER_QUERY_ALLOWED})")
try:
with tqdm(queries, desc="Searching", unit="query") as pbar:
for q in pbar:
time.sleep(SEARCH_DELAY)
try:
resp = fc.search(q, limit=per_query)
except Exception as e:
msg = str(e)
if "Payment Required" in msg or "Insufficient credits" in msg:
tqdm.write(f"⚠️ Free tier limit reached: {e}")
tqdm.write("💡 Tip: Upgrade at https://firecrawl.dev/pricing")
pbar.set_postfix(found=len(results))
continue
elif "429" in msg or "Rate limit" in msg or "retry" in msg.lower():
print(f"Rate limit hit for '{q}': {msg}")
_sleep_backoff(1, server_msg=msg)
try:
resp = fc.search(q, limit=per_query)
except Exception as e2:
print(f"Retry failed for '{q}': {e2}")
pbar.set_postfix(found=len(results))
continue
else:
print(f"Search call error for '{q}': {e}")
pbar.set_postfix(found=len(results))
continue
data = getattr(resp, "data", resp) or []
for item in data:
url = item.get("url") or item.get("link")
if not url or url in seen:
continue
seen.add(url)
results.append(
{
"url": url,
"title": item.get("title")
or item.get("metadata", {}).get("title", ""),
"description": item.get("description") or "",
}
)
if len(results) >= limit:
pbar.set_postfix(found=len(results))
return results
# update postfix so user sees current found count
pbar.set_postfix(found=len(results))
except KeyboardInterrupt:
print("Search interrupted by user; returning current results.")
return results4. Prompt Construction with OpenAI Harmony
The build_harmony_prompt function creates a structured prompt for OpenAI’s Harmony API, a conversation-building interface that enforces a strict JSON output format. This ensures the model generates dermatology Q&A pairs that are:
- Factual
- Non-overlapping
- Grounded only in the provided text and URL
Our Harmony prompt function will:
- Define strict rules for the model (SYSTEM_MSG)
- Set system metadata using SystemContent for model identity, reasoning effort, conversation start date, and knowledge cutoff
- Add developer instructions using DeveloperContent for task-specific constraints and formatting rules (higher priority than system)
- Add user request which includes the source text, URL, and number of Q&A pairs to generate
- Assemble conversation following the role hierarchy (system > developer > user > assistant) in Harmony's structured format
- Tokenize & decode into a final prompt string with separate channels for reasoning ("analysis") vs final output ("final")
- Return the prompt for API use
SYSTEM_MSG = (
"You are a careful dermatology assistant. Generate factual, non-overlapping "
"Q&A pairs grounded ONLY in the provided title/description. No guessing. "
"Provide detailed, evidence-based answers (2-4 sentences) supported by the text. "
"Each item must include: question, answer, condition, difficulty (easy|medium|hard), "
"and the source URL. Output exactly one JSON object with key 'items'. Return only JSON."
)
def build_harmony_prompt(text: str, url: str, k: int) -> str:
system = (
SystemContent.new()
.with_model_identity("Dermatology Q&A generator")
.with_reasoning_effort(ReasoningEffort.MEDIUM)
.with_conversation_start_date("2025-08-12")
.with_knowledge_cutoff("2024-10")
.with_required_channels(["final"])
)
developer = DeveloperContent.new().with_instructions(SYSTEM_MSG)
user_msg = f"Source URL: {url}\n\nCreate up to {k} dermatology Q&A pairs strictly from this text:\n\n{text}"
convo = Conversation.from_messages(
[
Message.from_role_and_content(Role.SYSTEM, system),
Message.from_role_and_content(Role.DEVELOPER, developer),
Message.from_role_and_content(Role.USER, user_msg),
]
)
token_ids = encoding.render_conversation_for_completion(convo, Role.ASSISTANT)
prompt_text = encoding.decode(token_ids)
return prompt_text5. Q&A Generation via OpenAI GPT‑OSS‑120B
The generate_items_from_text function uses GPT‑OSS‑120B via Groq Cloud to generate dermatology Q&A pairs from the structured prompt created by build_harmony_prompt.
Note: Groq Cloud provides free access to multiple AI models, but with rate limits. You can check your current limits by going to the Limits page.
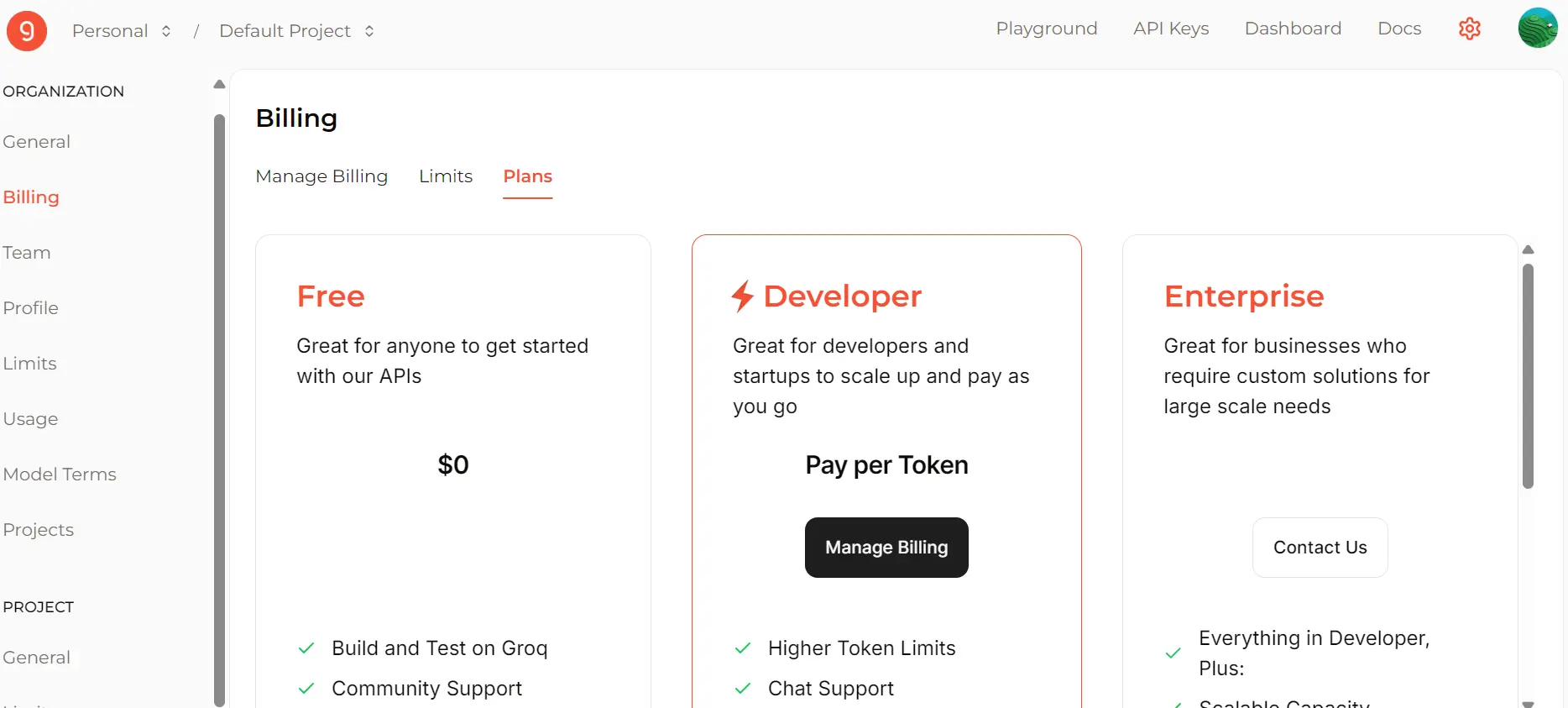
To generate 1,000 samples efficiently, subscribe to the "Developer" plan via the Billing page.
The Q&A generation function will:
- Wait if the last Groq API call was too recent
- Build the prompt using
build_harmony_prompt - Send the request to Groq GPT‑OSS‑120B
- Stream the output and assemble it into a string
- Parse JSON (with fallback extraction if malformed)
- Validate each Q&A item with QAItem (Pydantic)
- Retry on errors or rate limits
- Return the final list of validated Q&A items
_last_groq_call = 0.0
def generate_items_from_text(text: str, url: str, k: int) -> List[Dict[str, Any]]:
global _last_groq_call
attempt = 0
last_exc_msg = ""
while attempt < MAX_ATTEMPTS:
attempt += 1
elapsed = time.time() - _last_groq_call
if elapsed < GROQ_DELAY:
time.sleep(GROQ_DELAY - elapsed)
prompt_text = build_harmony_prompt(text, url, k)
try:
completion = groq_client.chat.completions.create(
model=GROQ_MODEL,
messages=[{"role": "user", "content": prompt_text}],
temperature=0.15,
max_completion_tokens=1600,
top_p=1,
reasoning_effort="medium",
stream=True,
)
out = ""
for chunk in completion:
try:
delta = chunk.choices[0].delta.content or ""
except Exception:
delta = getattr(chunk.choices[0], "delta", {}).get("content", "") or ""
out += delta
_last_groq_call = time.time()
data = {"items": []}
if out:
try:
data = json.loads(out)
except Exception:
s = out.find("{")
e = out.rfind("}")
if s != -1 and e != -1 and e > s:
try:
data = json.loads(out[s : e + 1])
except Exception:
data = {"items": []}
items: List[Dict[str, Any]] = []
for it in data.get("items", []) or []:
try:
qa = QAItem(**{**it, "source_url": url})
items.append(qa.model_dump())
except ValidationError:
continue
for it in items:
it["source_url"] = url
return items
except Exception as exc:
msg = str(exc)
last_exc_msg = msg
if "Payment Required" in msg or "Insufficient credits" in msg or "quota" in msg.lower():
tqdm.write(f"⚠️ Free tier limit reached: {exc}")
tqdm.write("💡 Tip: Upgrade at https://console.groq.com/settings/billing/plans")
return []
elif "429" in msg or "Rate limit" in msg or "RateLimit" in msg or "RateLimitError" in msg:
_sleep_backoff(attempt, server_msg=msg)
continue
inner = getattr(exc, "__cause__", None) or getattr(exc, "original", None)
if inner:
inner_msg = str(inner)
if "429" in inner_msg or "Rate limit" in inner_msg or "RateLimit" in inner_msg:
_sleep_backoff(attempt, server_msg=inner_msg)
continue
_sleep_backoff(attempt, server_msg=msg)
continue
tqdm.write(f"Giving up after {MAX_ATTEMPTS} attempts for {url}. Last error: {last_exc_msg}")
return []6. Orchestrating Firecrawl Search and Generation
The collect_from_search function is the top-level orchestrator that coordinates the entire pipeline for generating dermatology Q&A pairs. It integrates web discovery (via Firecrawl) with Q&A generation (via generate_items_from_text), while ensuring:
- No duplicate questions
- Progress is saved at every step
- Multiple passes are made until the target number of Q&As is reached
The orchestration function will:
- Load existing progress from checkpoints to avoid regenerating data
- Search for dermatology-related pages using
firecrawl_search_with_ratelimit - Fallback to default URLs if no search results are found
- Prepare candidate pages from search results (title/description)
- Generate Q&A pairs for each candidate page using
generate_items_from_text - Avoid duplicates by normalizing and checking questions before adding them
- Save progress after each batch of new items
- Retry with multiple passes (increasing Q&A count per page) until the target is met
- Display progress in real time using a single
tqdmprogress bar
def collect_from_search(target: int) -> List[Dict[str, Any]]:
collected: List[Dict[str, Any]] = []
seen_questions = set()
# Load existing checkpoint first
existing = load_checkpoint()
collected.extend(existing)
for rec in existing:
q = rec.get("question", "")
if q:
seen_questions.add(normalize_question(q))
# Discover pages
search_rows = firecrawl_search_with_ratelimit(DERM_QUERIES, MAX_URLS)
if not search_rows:
print("Search returned no results; falling back to DEFAULT_URLS")
search_rows = DEFAULT_URLS
show_sample("search_results", search_rows[:3] or [])
# Build candidates (title fallback)
candidates = []
for r in search_rows:
desc = (r.get("description") or "").strip()
title = (r.get("title") or "").strip()
text = desc if desc else title
if not text:
continue
candidates.append({"url": r["url"], "text": text, "title": title})
if not candidates:
for u in DEFAULT_URLS:
t = u.get("title", "")
if t:
candidates.append({"url": u["url"], "text": t, "title": t})
show_sample("candidates_sample", candidates[:1] or [])
# Create a single overall tqdm bar
overall = tqdm(total=target, desc="Collected", unit="item")
if collected:
overall.update(len(collected))
# helper to add items and checkpoint
def add_items_and_checkpoint(items: List[Dict[str, Any]]) -> int:
added = 0
for it in items:
qn = normalize_question(it["question"])
if not qn or qn in seen_questions:
continue
seen_questions.add(qn)
collected.append(it)
added += 1
if added:
save_checkpoint(collected)
overall.update(added)
return added
# Single-pass loop (no per-loop tqdm)
total_pages = len(candidates)
for page_idx, row in enumerate(candidates, start=1):
if len(collected) >= target:
break
# update postfix so user sees page progress on the single bar
overall.set_postfix({"page": f"{page_idx}/{total_pages}"})
try:
items = generate_items_from_text(row["text"], row["url"], N_QA_PER_REQUEST)
added = add_items_and_checkpoint(items)
print(f"[{page_idx}/{total_pages}] {row['url']}: fetched {len(items)}, added {added} (total {len(collected)})")
except Exception as e:
print(f"[{page_idx}/{total_pages}] Gen error for {row['url']}: {e}")
# Additional passes (if needed)
pass_num = 2
per_page_k = N_QA_PER_REQUEST
while len(collected) < target and pass_num <= 4:
print(f"Pass {pass_num}: requesting {per_page_k} per page")
page_idx = 0
for page_idx, row in enumerate(candidates, start=1):
if len(collected) >= target:
break
overall.set_postfix({"pass": pass_num, "page": f"{page_idx}/{total_pages}"})
try:
items = generate_items_from_text(row["text"], row["url"], per_page_k)
added = add_items_and_checkpoint(items)
print(f"[pass {pass_num} {page_idx}/{total_pages}] {row['url']}: fetched {len(items)}, added {added} (total {len(collected)})")
except Exception as e:
print(f"[pass {pass_num} {page_idx}/{total_pages}] Gen error for {row['url']}: {e}")
pass_num += 1
per_page_k += 1
overall.close()
print(f"Collection finished: {len(collected)} items (target {target})")
return collected7. Run the Data Generation Pipeline
In this section, we will execute the full Q&A generation pipeline, either starting fresh or resuming from a saved checkpoint. This ensures that all collected Q&A items are cleaned, validated, and saved in multiple formats for downstream use. It also provides sample previews and runtime logs for quick inspection and tracking.
The next code block executes the complete pipeline we've built. The process will:
- Load any existing progress from checkpoints
- Search the web for dermatology content using Firecrawl
- Generate Q&A pairs from each page using GPT-OSS
- Clean and validate the results
- Save final dataset in multiple formats
Note that if you have a large number of samples, it can take a while to run.
start = time.time()
collected = collect_from_search(TARGET_SAMPLES)
cleaned = clean_items(collected)
show_sample("cleaned_QA_item", cleaned[:1] or [])
if not cleaned:
tqdm.write("No QA items extracted.")
# final save (already done incrementally, but ensure final CSV too)
save_checkpoint(cleaned)
df = pd.DataFrame(cleaned)
df["source_domain"] = df["source_url"].str.extract(r"https?://([^/]+)/?")
df = df[["question", "answer", "condition", "difficulty", "source_url", "source_domain"]]
show_sample("final_dataframe_row", df.head(1).to_dict(orient="records"))
elapsed = time.time() - start
tqdm.write(f"\nSaved {len(df)} rows to:\n- {CSV_PATH}\n- {JSONL_PATH}")
tqdm.write(f"Elapsed time: {elapsed/60:.1f} minutes")Understanding the Output
After fixing issues and rerunning the pipeline, we generated a complete dataset of dermatological Q&A samples, with the total based on the TARGET_SAMPLES variable you set earlier.
What you'll see during execution:
- Search progress bar showing pages discovered
- Generation progress with items added per page
- Checkpoint saves every few items
- Rate limit warnings (normal on free tiers)
Success indicators:
- Generated Q&A pairs saved to CSV/JSONL files
- Final statistics showing item count and elapsed time
- Sample outputs displaying properly formatted Q&A items
If you see errors:
- "Payment Required" or "Rate limit" = Normal on free tiers, not a failure
- "Insufficient credits" = Upgrade your API plan
- Python errors = Check your API keys and dependencies
Most issues will likely be caused by rate limits and exceeding daily limits. Subscribe to a paid plan to resolve them.

8. Exploratory Analysis and Quality Checks
In this part, we will load the dataset, normalize the text, detect duplicates, and compute basic statistics to assess coverage, difficulty distribution, and answer quality.
- Load the dataset and display the last 5 samples.
import os
import re
import pandas as pd
input_dir = "data_derm_qa_search_harmony_groq"
csv_path = os.path.join(input_dir, "dermatology_qa_search_harmony_groq.csv")
df = pd.read_csv(csv_path)
df.tail()
-
Normalize text (lowercasing, trimming spaces, removing punctuation) for consistent comparison.
-
Find duplicates by question text only, answer text only, and question–answer pairs.
def normalize_text(text: str) -> str:
"""Lowercase, strip spaces, collapse multiple spaces, remove extra punctuation."""
if not isinstance(text, str):
return ""
text = text.lower().strip()
text = re.sub(r"\s+", " ", text) # collapse multiple spaces
text = re.sub(r"[^\w\s]", "", text) # remove punctuation
return text
def find_duplicates(df: pd.DataFrame, display=True):
# Create normalized columns
df = df.copy()
df["question_norm"] = df["question"].apply(normalize_text)
df["answer_norm"] = df["answer"].apply(normalize_text)
def get_duplicates(keys):
dup_df = df[df.duplicated(subset=keys, keep=False)]
return dup_df.sort_values(by=keys).reset_index(drop=True)
results = {
"by_question": get_duplicates(["question_norm"]),
"by_answer": get_duplicates(["answer_norm"]),
"by_exact_q_a": get_duplicates(["question_norm", "answer_norm"]),
}
return results
dupes = find_duplicates(df)
for k, v in dupes.items():
if not v.empty:
group_count = v.drop_duplicates(subset=v.columns.tolist()).shape[0]
total_rows = len(v)
print(f"{k}: {total_rows}")
else:
print(f"{k}: No duplicates found")There are four duplicate questions, ten answers, and two exact question and answer pairs in the dataset, which is normal.
by_question: 4
by_answer: 10
by_exact_q_a: 2Perfect uniqueness isn't required. Real-world datasets often have some natural overlap.
- Analyze the dataset for the following aspects: total number of items, number of unique conditions, difficulty distribution, mean and median answer lengths, count of short answers, and top source domains.
min_answer_length = 60
def analyze_basic_stats(df):
stats = {}
stats['n_items'] = len(df)
stats['n_conditions'] = int(df['condition'].nunique()) if 'condition' in df.columns else 0
stats['difficulty_counts'] = df['difficulty'].value_counts().to_dict() if 'difficulty' in df.columns else {}
stats['answer_len_mean'] = int(df['answer'].str.len().mean()) if 'answer' in df.columns else 0
stats['answer_len_median'] = int(df['answer'].str.len().median()) if 'answer' in df.columns else 0
stats['short_answers'] = int((df['answer'].str.len() < min_answer_length).sum()) if 'answer' in df.columns else 0
stats['top_domains'] = df['source_url'].str.extract(r"https?://([^/]+)/?")[0].value_counts().head(5).to_dict()
return stats, df
# Basic stats
stats, df_valid = analyze_basic_stats(df)
# display(pd.Series(stats)) For running in Jupyter notebook
print(pd.Series(stats))Output:
n_items 1001
n_conditions 131
difficulty_counts {'easy': 826, 'medium': 162, 'hard': 13}
answer_len_mean 197
answer_len_median 193
short_answers 0
top_domains {'www.aad.org': 381, 'dermnetnz.org': 361, 'ri...
dtype: object9. Publish the Dataset to Hugging Face Hub
At the end, we'll upload the finalized dermatology Q&A dataset to the Hugging Face Hub for public access. Publishing to the Hub makes the dataset easy to share, version-controlled, and accessible for downstream tasks such as fine-tuning, evaluation, or research.
-
Load the CSV dataset using Pandas.
-
Convert the Pandas dataset into a Hugging Face dataset.
import os
import pandas as pd
from datasets import Dataset
OUT_DIR = "data_derm_qa_search_harmony_groq"
CSV_PATH = os.path.join(OUT_DIR, "dermatology_qa_search_harmony_groq.csv")
repo_id = "YOUR_USERNAME/dermatology-qa-firecrawl-dataset" # Replace YOUR_USERNAME with your Hugging Face username
token = os.getenv("HUGGINGFACEHUB_API_TOKEN")
private = False
def load_local_dataset(csv_path: str) -> Dataset:
df = pd.read_csv(csv_path)
df = df.loc[:, ~df.columns.str.startswith("Unnamed:")]
return Dataset.from_pandas(df)
ds = load_local_dataset(CSV_PATH)- Create the data repository and push all the data files and metadata to the repository.
ds.push_to_hub(repo_id, token=token, private=private, commit_message="Add dermatology QA dataset")The dataset will be publicly available at https://huggingface.co/datasets/YOUR_USERNAME/dermatology-qa-firecrawl-dataset (replace YOUR_USERNAME with your actual Hugging Face username).
For reference, here's an example of what the hosted dataset looks like:
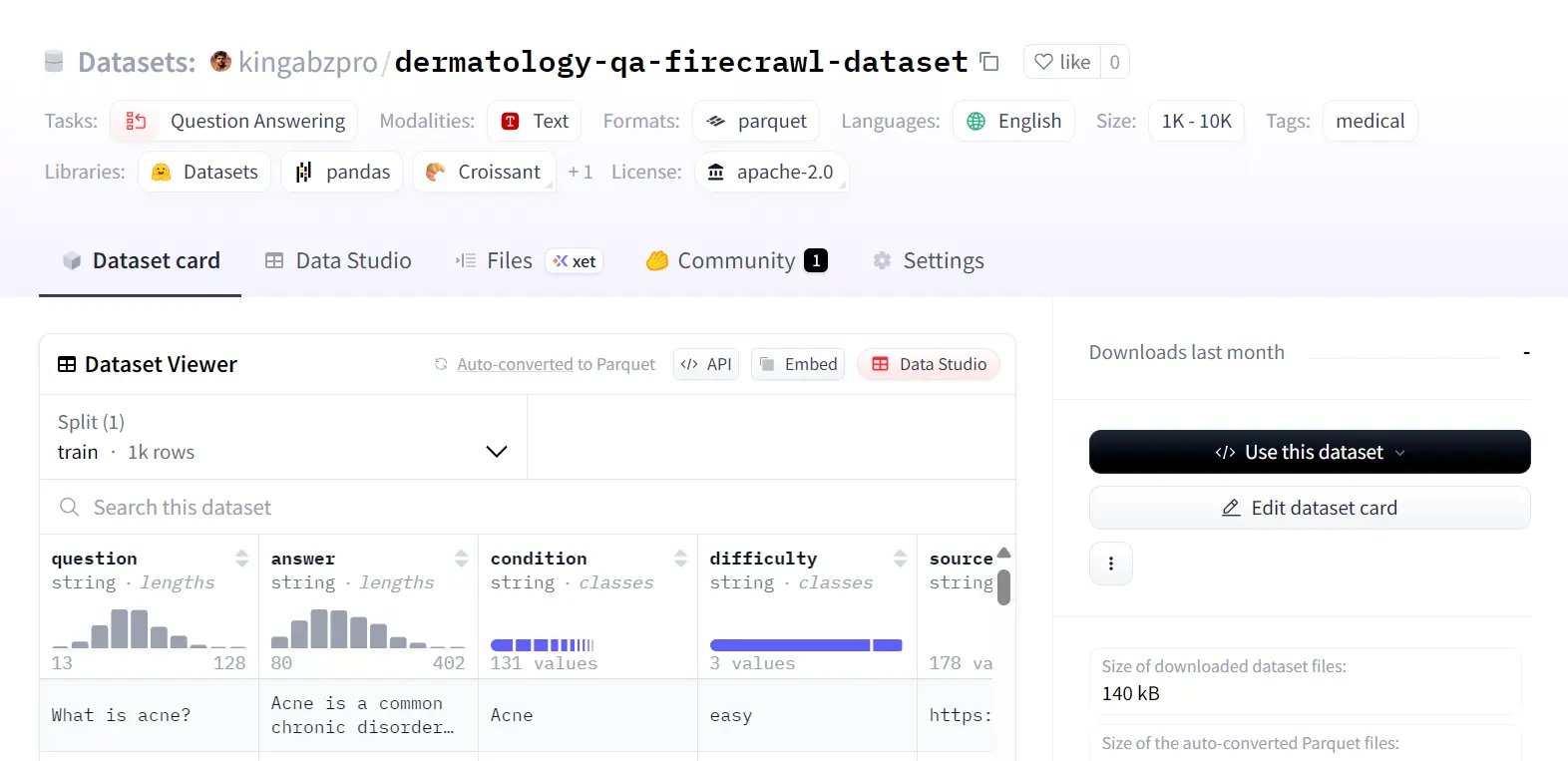
Summary
Here's a summary of the entire guide.
We began by setting up two APIs: Firecrawl for web search and Groq for the GPT-OSS 120B model. We then searched trusted dermatology websites, carefully following rate limits and retrying when necessary.
For each discovered page, we instructed the AI model to create clear and factual Q&A pairs based solely on the page's title and description. Each item was then validated for appropriate length, a difficulty label, and source URL.
We normalized questions to prevent duplicates and saved progress regularly in CSV/JSONL format, enabling the process to be paused and resumed at any time. The loop continued processing pages until the target number of items was collected.
Afterwards, we conducted simple checks to identify duplicates, count items, assess answer lengths, and determine the most frequently used sources. Finally, we organized everything into a clean dataset and uploaded it to the Hugging Face Hub for easy sharing and reuse.
This approach demonstrates how modern tools can work together to create valuable datasets efficiently. While we focused on dermatology, the same methodology applies to any domain where you need structured Q&A data from web sources. The combination of Firecrawl's search capabilities, OpenAI Harmony's structured prompting, and GPT-OSS's generation power creates a robust pipeline for dataset creation. You can explore similar approaches in our custom instruction dataset guide or learn how to use this dataset for fine-tuning GPT-OSS models.
Whether you're building training data for medical AI, creating educational content, or developing domain-specific knowledge bases, this workflow provides a solid foundation you can adapt for your specific projects and needs. For more advanced applications, consider exploring how to build RAG systems with your custom datasets or integrate them into AI agent frameworks.
