
After the initial hype and debates settled around OpenAI's surprise return to open-source AI with GPT-OSS, many have come to appreciate just how well OpenAI's GPT-OSS 20B follows instructions and how effectively it can be fine-tuned for specialized tasks.
What makes this tutorial practical: We'll use LoRA (Low-Rank Adaptation), a memory-efficient technique that updates only a small fraction of the model's parameters. This means you can fine-tune a 20-billion parameter model on consumer hardware in just a few hours, rather than requiring enterprise-grade infrastructure.
By the end, you'll have a specialized dermatology assistant that provides focused, professional responses while maintaining the reasoning capabilities of the original GPT-OSS model. This approach builds on similar techniques used in our Llama 4 fine-tuning guide and DeepSeek fine-tuning tutorial.
In this tutorial, we will walk through fine-tuning the full GPT-OSS 20B model on the Firecrawl Dermatology Q&A dataset we built in the earlier tutorial using AI search and web scraping API capabilities. Along the way, we will cover:
- Understanding the dataset
- Setting up the environment and installing dependencies
- Loading the model and tokenizer
- Defining the OpenAI Harmony prompt format
- Preparing and formatting the dataset
- Running baseline evaluations
- Configuring the trainer
- Training the model
- Evaluating post-training performance
- Running inference with Hugging Face pipelines
By the end, you will have a clear, hands-on workflow for fine-tuning GPT-OSS 20B on your own data.
Why fine-tune GPT-OSS 20B?
Fine-tuning allows you to adapt a general-purpose language model to excel at specific tasks or domains. Instead of training a model from scratch (which requires massive datasets and computational resources), fine-tuning takes a pre-trained model and teaches it new behaviors using a smaller, targeted dataset. For more examples of creating specialized training data, see our guide on building custom instruction datasets. If you're working with different models, explore our Gemma fine-tuning tutorial and DeepSeek fine-tuning guide for alternative approaches. For creating training datasets, see data extraction using LLMs.
Why fine-tune GPT-OSS 20B for our dermatology dataset?
While GPT-OSS 20B is highly capable out of the box, it tends to give lengthy, general responses when asked medical questions. By fine-tuning on our curated dermatology Q&A dataset, we can teach it to:
- Generate concise, clinically relevant answers
- Use appropriate medical terminology
- Follow a consistent response format
- Focus on dermatology-specific knowledge
1. Overview of the Firecrawl Dermatology Dataset
The Firecrawl Dermatology Dataset (kingabzpro/dermatology-qa-firecrawl-dataset) was built through a streamlined pipeline that combined Firecrawl's web search API with the GPT-OSS 120B model via Groq. This AI crawling approach systematically searched trusted dermatology websites, and for each page discovered through the web crawling API, the model generated concise Q&A pairs based on titles and descriptions, which were then validated for length, difficulty, and source attribution.
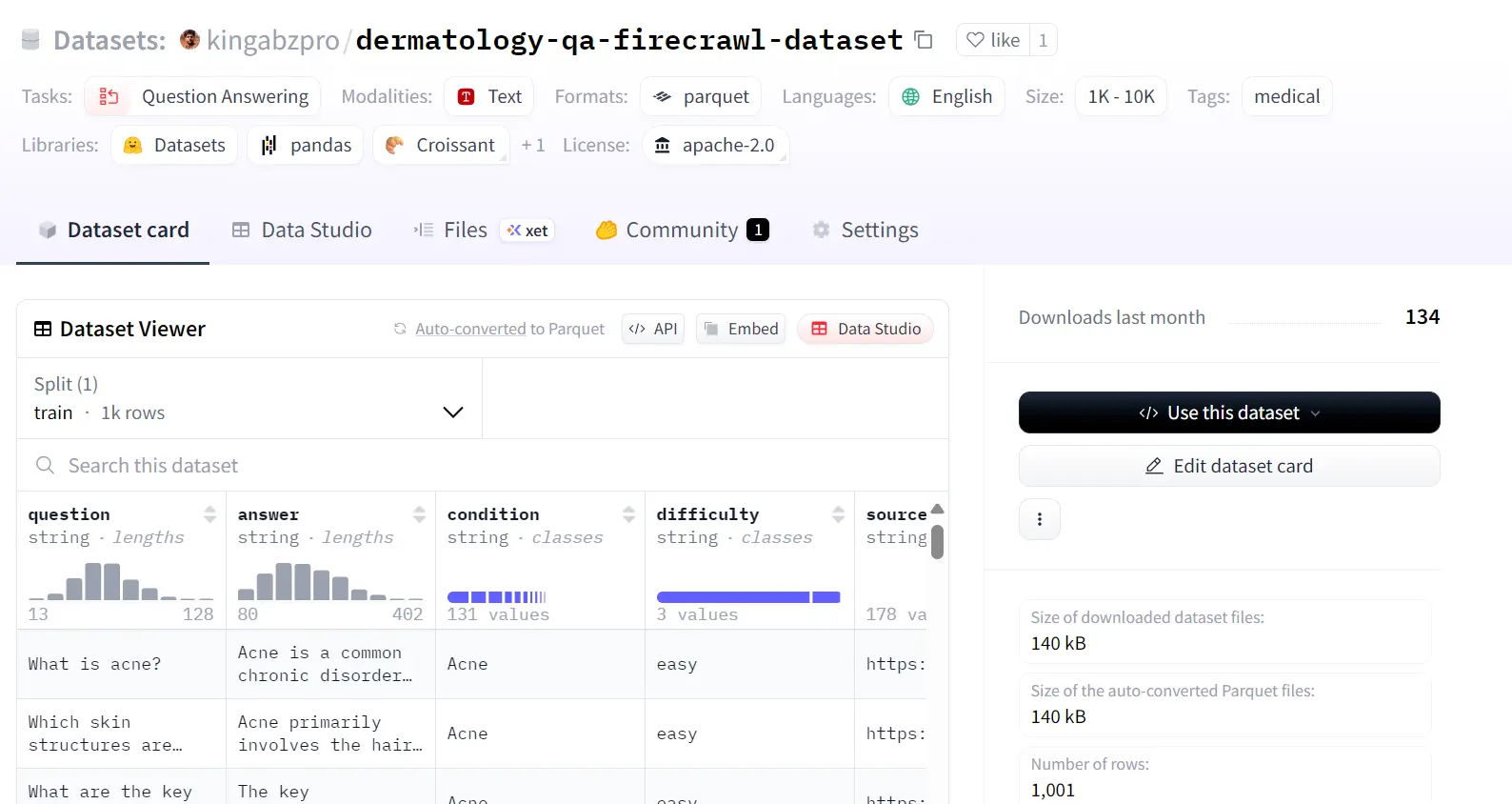
To ensure quality, questions were normalized to avoid duplicates, progress was saved in CSV/JSONL for resumability, and post-processing checks were applied to detect duplicates, analyze answer lengths, and track source usage. The final cleaned dataset was organized and uploaded to the Hugging Face Hub.
Please follow the complete tutorial How to Create a Dermatology Q&A Dataset with OpenAI Harmony & Firecrawl Search and learn about the code, strategies, and steps required to generate this data with the Firecrawl web scraping API and LLM. This AI scraping workflow demonstrates how modern web search API tools can efficiently gather domain-specific training data, similar to techniques used in our LLM data extraction guide. We'll assume that you've already set up your Firecrawl and Hugging Face accounts.
2. Environment Setup & Dependencies
We'll begin by creating an A100 SXM pod using the latest PyTorch image on RunPod. Make sure you have at least $5 of credit in your RunPod account, since we will be running experiments that include training, evaluation, and inference.
Setting up RunPod
- Create account at runpod.io
- Add ~$10 credits (Training costs ~$5-10)
- Select "A100 SXM" pod
- Choose "PyTorch 2.1" template
- Launch and click "Connect to Jupyter Lab" link to launch the environment in your browser
If you already have a RunPod account, make sure you have at least $5 of credit, since we will be running experiments that include training, evaluation, and inference.
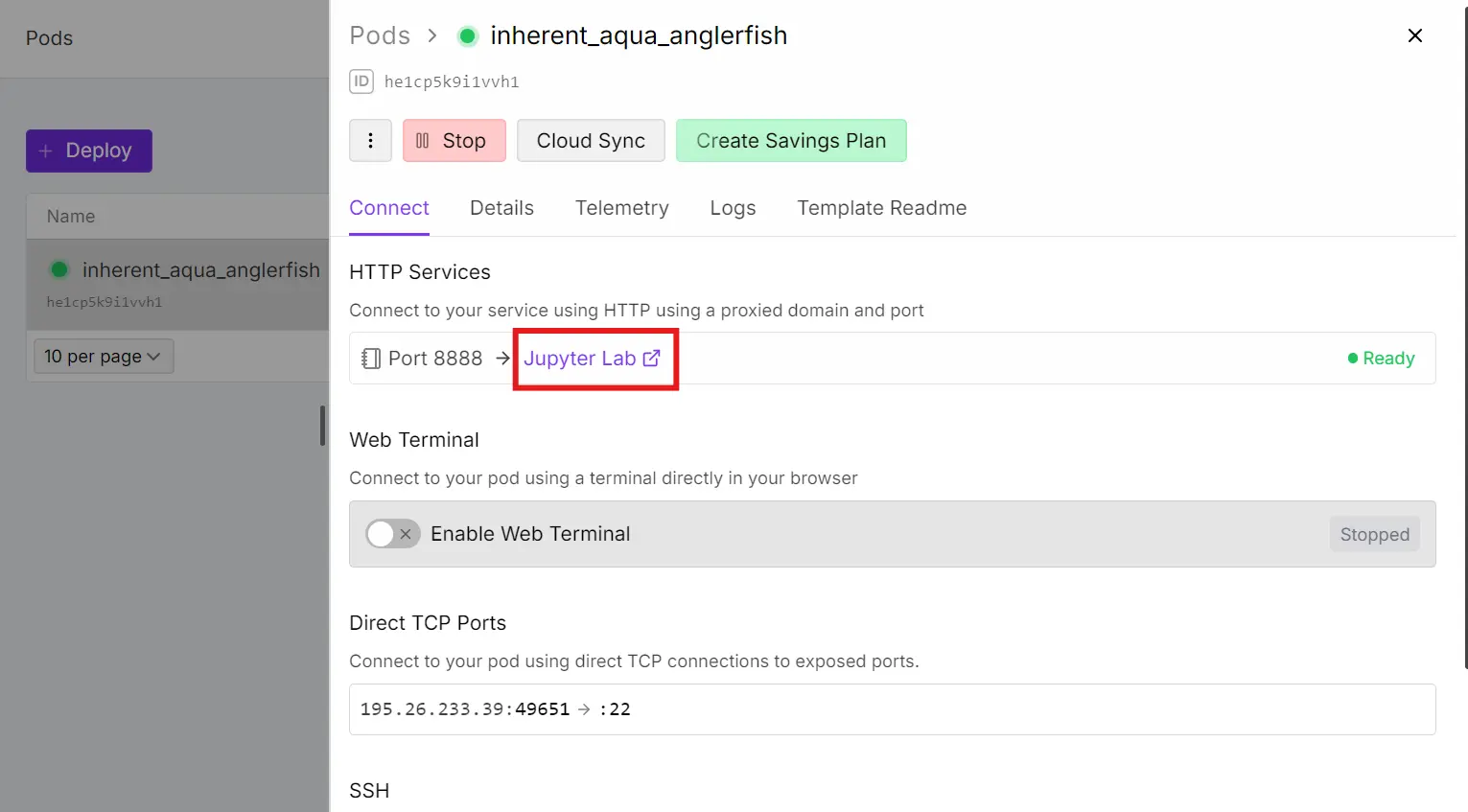
Then, create a new Python notebook, create a cell, and install the required packages.
%%capture
%pip install -U accelerate
%pip install -U peft
%pip install -U trl
%pip install -U bitsandbytes
%pip install -U "transformers==4.55.4" # Pin to working version
%pip install -U tensorboard
%pip install -U openai-harmony
%pip install -U tiktoken
%pip install -U pyctcdecodeIf you followed the previous derm tutorial, you should already have a Hugging Face account and API key. Login to the Hugging Face CLI to enable saving and pushing models, tokenizers, and metadata.
from huggingface_hub import notebook_login
notebook_login()We'll reference the following variables multiple times throughout this tutorial, so set them up early.
BASE_MODEL_ID = "openai/gpt-oss-20b"
SAVED_MODEL_ID = "gpt-oss-20b-dermatology-qa"
DATASET_NAME = "kingabzpro/dermatology-qa-firecrawl-dataset"3. Load GPT-OSS 20B Model and Tokenizer
We will load GPT-OSS 20B with MXFP4 support. If your machine has Triton ≥ 3.4 and kernels installed, MXFP4 kernels will run on a broad set of CUDA GPUs. Otherwise, Transformers will dequantize to bfloat16 on load. We have enough memory here to run bf16 if needed.
We will also load the corresponding tokenizer using the same model ID.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, Mxfp4Config
quantization_config = Mxfp4Config(dequantize=True)
model_kwargs = dict(
attn_implementation="eager",
torch_dtype=torch.bfloat16,
quantization_config=quantization_config,
use_cache=False,
device_map="auto",
)
model = AutoModelForCausalLM.from_pretrained(BASE_MODEL_ID, **model_kwargs)
tokenizer = AutoTokenizer.from_pretrained(BASE_MODEL_ID)4. Define OpenAI Harmony Prompt Format
OpenAI's Harmony is a new structured response/prompt format introduced with the gpt-oss models to standardize multi-channel LLM interactions, separating hidden reasoning (analysis), tool-use preambles and calls (commentary), and user-facing answers (final), with an explicit role hierarchy.
In this step, we will create a helper function that:
- Takes a question-answer pair from our dataset
- Wraps it in the Harmony conversation format
- Renders the conversation into tokens
- Decodes it back into text for training or inspection
from openai_harmony import (
Conversation,
DeveloperContent,
HarmonyEncodingName,
Message,
Role,
load_harmony_encoding,
)
# Load the Harmony encoder once
enc = load_harmony_encoding(HarmonyEncodingName.HARMONY_GPT_OSS)
DERM_DEV_INSTRUCTIONS = (
"You are a board-certified dermatologist answering various dermatology questions."
" Answer clearly in 1-3 sentences. No speculation."
)
def render_pair_harmony(question: str, answer: str) -> str:
"""Harmony-formatted prompt for training."""
convo = Conversation.from_messages(
[
Message.from_role_and_content(
Role.DEVELOPER,
DeveloperContent.new().with_instructions(DERM_DEV_INSTRUCTIONS),
),
Message.from_role_and_content(Role.USER, question.strip()),
Message.from_role_and_content(Role.ASSISTANT, answer.strip()),
]
)
tokens = enc.render_conversation(convo)
return enc.decode(tokens)5. Load and Format the Dataset
We will now load the kingabzpro/dermatology-qa-firecrawl-dataset from Hugging Face. This dataset contains dermatology-related question-answer pairs, along with metadata such as the condition, difficulty level, and source URL.
Since our model will be trained using the Harmony prompt format, we need to:
- Load the dataset from Hugging Face
- Convert each Q&A pair into Harmony-formatted text using our
render_pair_harmonyfunction - Add a new text column containing the formatted conversations
- Split the dataset into training and test sets (90/10 split)
- Inspect the dataset to confirm the transformation
from datasets import load_dataset
# Load dataset
dataset = load_dataset("kingabzpro/dermatology-qa-firecrawl-dataset", split="train")
def to_harmony_batch(examples: dict) -> dict:
"""Convert batch of dermatology Q&A pairs to harmony format."""
questions = examples["question"]
answers = examples["answer"]
formatted_texts = []
for question, answer in zip(questions, answers):
formatted_text = render_pair_harmony(question.strip(), answer.strip())
formatted_texts.append(formatted_text)
return {"text": formatted_texts}
# Process dataset
dataset = dataset.map(to_harmony_batch, batched=True)
dataset = dataset.train_test_split(test_size=0.1, seed=42)
print(dataset)
print(dataset["train"][0]["text"])As we can see, the dataset has been successfully split into 900 training samples and 101 test samples.
The new “text” column now contains the Harmony-formatted conversations, which include explicit role tags for the developer, user, and assistant. This ensures that the model learns structured, role-based interactions during training.
DatasetDict({
train: Dataset({
features: ['question', 'answer', 'condition', 'difficulty', 'source_url', 'text'],
num_rows: 900
})
test: Dataset({
features: ['question', 'answer', 'condition', 'difficulty', 'source_url', 'text'],
num_rows: 101
})
})
<|start|>developer<|message|># Instructions
You are a board-certified dermatologist answering various dermatology questions. Answer clearly in 1-3 sentences. No speculation.<|end|><|start|>user<|message|>What type of skin changes accompany the pustules in GPP?<|end|><|start|>assistant<|message|>The skin surrounding the pustules becomes erythematous, which means it appears red and inflamed. The affected skin is also painful. These changes occur during the recurrent flares of the disease.<|end|>6. Run Baseline Inference (Before Fine-Tuning)
Before fine-tuning, it's good practice to establish a baseline so we can later measure how the model's style, accuracy, and domain-specific vocabulary improve.
To do this, we will:
- Create a helper function
render_inference_harmonythat formats a user question into the Harmony prompt style (without an assistant response). - Pass the formatted prompt through the model to generate an answer.
- Extract the final assistant response from the Harmony output.
- Compare the generated answer with the original dataset answer.
The render_inference_harmony function is similar to render_pair_harmony, but it omits the assistant role so the model is encouraged to generate the response itself.
def render_inference_harmony(question: str) -> str:
"""Harmony-formatted prompt for inference."""
convo = Conversation.from_messages(
[
Message.from_role_and_content(
Role.DEVELOPER,
DeveloperContent.new().with_instructions(DERM_DEV_INSTRUCTIONS),
),
Message.from_role_and_content(Role.USER, question.strip()),
]
)
tokens = enc.render_conversation_for_completion(convo, Role.ASSISTANT)
return enc.decode(tokens)Here we select a sample from the test set, format it, tokenize it, and generate a response.
question = dataset["test"][20]["question"]
text = render_inference_harmony(question)
inputs = tokenizer(text, return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0])When we run inference, the model produces a Harmony-formatted response that includes both the analysis (hidden reasoning) and the final (user-facing) channels.
<|start|>developer<|message|># Instructions
You are a board-certified dermatologist answering various dermatology questions. Answer clearly in 1-3 sentences. No speculation.<|end|><|start|>user<|message|>Why might winter be a problematic season for some people with eczema?<|end|><|start|>assistant<|channel|>analysis<|message|>They ask: "Why might winter be a problematic season for some people with eczema?" A dermatologist must answer succinctly. We'll provide reasons: cold, dry air, indoor heating increases dryness, reduces skin barrier, triggers flare-ups. Also less humidity helps dryness, exposure to indoor allergens, etc. Provide 1-3 sentences. Must be no speculation. Provide factual explanation. Must answer clearly.<|end|><|start|>assistant<|channel|>final<|message|>Winter can trigger eczema flare-ups because cold, dry air and indoor heating strip the skin of moisture, compromising the skin barrier and making it more prone to irritation and infection. Lower humidity also increases scratching and can worsen inflammation, so maintaining skin hydration is particularly important during the colder months.<|return|>The raw output includes Harmony's analysis and final channels. Since we only want the user-facing answer, we can extract the text inside the <|start|>assistant<|channel|>final<|message|> ... <|return|> block.
start_idx = response[0].find("<|start|>assistant<|channel|>final<|message|>") + \
len("<|start|>assistant<|channel|>final<|message|>")
end_idx = response[0].rfind("<|return|>") if "<|return|>" in response[0] else len(response[0])
final_answer = response[0][start_idx:end_idx].strip()
print(final_answer)The generated response is detailed and explains the mechanisms that lead to eczema flare-ups and how to prevent them. This explanation significantly differs from the original dataset.
We aim to reduce response length and train the model to provide direct answers without verbose internal reasoning. Since API usage is charged per token generated, training the model to produce concise responses reduces the costs while also improving user experience through faster, more focused answers.
Look at this example from the baseline output.
Winter can trigger eczema flare-ups because cold, dry air and indoor heating strip the skin of moisture, compromising the skin barrier and making it more prone to irritation and infection. Lower humidity also increases scratching and can worsen inflammation, so maintaining skin hydration is particularly important during the colder months.We can compare this with the original answer from the training data.
dataset["test"][20]["answer"]The original response is concise and only mentions the trigger.
During winter, indoor air tends to be dry, which can trigger eczema flare-ups for some individuals. The dryness of indoor environments in winter is a known trigger for these patients.7. Configure LoRA Fine-Tuning Parameters
Instead of fine-tuning the entire model, we use LoRA (Low-Rank Adaptation). LoRA updates only a small subset of parameters while keeping the base model frozen, which drastically reduces memory usage and training cost. This makes training much faster, often just a few minutes per epoch.
We start by defining a LoraConfig that specifies the rank, scaling factor, and the exact target layers where LoRA adapters will be injected.
- r=8: Controls adapter size and capacity.
- lora_alpha=16: Scaling factor that amplifies LoRA updates.
- target_modules="all-linear": Apply LoRA to all linear layers in the model.
- target_parameters=[...]: Explicitly selects which layer parameters to adapt.
from peft import LoraConfig, get_peft_model
peft_config = LoraConfig(
r=8,
lora_alpha=16,
target_modules="all-linear",
target_parameters=[
"7.mlp.experts.gate_up_proj",
"7.mlp.experts.down_proj",
"15.mlp.experts.gate_up_proj",
"15.mlp.experts.down_proj",
"23.mlp.experts.gate_up_proj",
"23.mlp.experts.down_proj",
],
)
peft_model = get_peft_model(model, peft_config)
peft_model.print_trainable_parameters()LoRA fine-tuning updates only about 0.07% of the model's parameters, specifically in select MLP layers. This makes training fast, memory-efficient, and cost-effective.
The best part: the saved LoRA adapter is only ~60 MB, which means you can load it quickly, store it easily, and serve it efficiently without needing to handle the full 20B-parameter model.
trainable params: 15,040,512 || all params: 20,929,797,696 || trainable%: 0.0719After that, we will configure the training setup using SFTConfig from the trl library.
This defines key hyperparameters such as learning rate, batch size, gradient accumulation, warmup ratio, and scheduler type.
from trl import SFTConfig
training_args = SFTConfig(
learning_rate=2e-4,
gradient_checkpointing=True,
num_train_epochs=1,
logging_steps=10,
bf16=True,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
gradient_accumulation_steps=2,
max_length=2048,
warmup_ratio=0.03,
eval_strategy="steps",
eval_steps=10,
lr_scheduler_type="cosine_with_min_lr",
lr_scheduler_kwargs={"min_lr_rate": 0.1},
output_dir=SAVED_MODEL_ID,
report_to="tensorboard",
push_to_hub=True,
)Explanation of each parameter:
- learning_rate: The step size for updating model weights. A higher LR speeds up learning but risks instability; a lower LR is more stable but slower.
- gradient_accumulation_steps: Accumulates gradients over 2 steps before updating weights. This effectively increases the batch size without requiring more GPU memory.
- warmup_ratio: Gradually increases the learning rate during the first 3% of training steps to avoid sudden large updates at the start.
- lr_scheduler_type: Uses a cosine decay schedule for the learning rate, smoothly reducing it over time.
- lr_scheduler_kwargs: Ensures the learning rate never falls below 10% of the initial value, preventing the model from "stalling" late in training.
- num_train_epochs: Number of full passes through the dataset. More epochs = more training, but risk of overfitting.
- per_device_train_batch_size: Number of training samples per GPU per step.
- per_device_eval_batch_size: Number of evaluation samples per GPU per step.
- gradient_checkpointing: Saves GPU memory by recomputing intermediate activations during backpropagation. Useful for large models.
- max_length: Maximum sequence length (in tokens) for training samples. Controls how much context the model can see.
- logging_steps: Logs training metrics (loss, LR, etc.) every 10 steps.
- eval_strategy: Runs evaluation at fixed step intervals (instead of only at the end of an epoch).
- eval_steps: Runs evaluation every 10 steps. Useful for quick feedback during training.
- report_to: Sends logs to TensorBoard for visualization.
- output_dir: Directory where checkpoints and final model are saved.
- push_to_hub: Automatically pushes the trained model to the Hugging Face Hub for sharing and reuse.
- bf16=True: Uses bfloat16 precision (supported A100 GPUs). This reduces memory usage and speeds up training while maintaining numerical stability.
8. Train the Model with SFTTrainer
We'll now set up the SFTTrainer, which conveniently combines the model, training arguments, train/eval datasets, and tokenizer into a single, easy-to-use API.
After that, we will start the training process.
from trl import SFTTrainer
trainer = SFTTrainer(
model=peft_model,
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
processing_class=tokenizer,
)
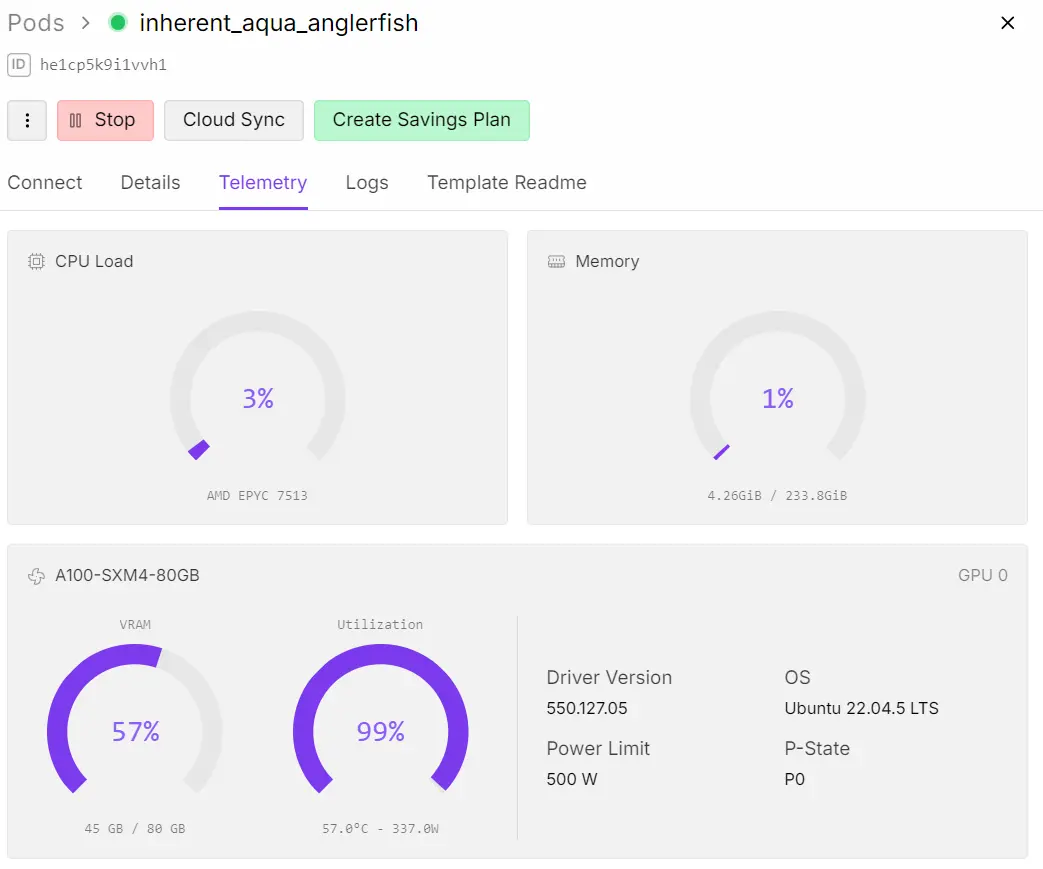
trainer.train()Once training begins, you can monitor GPU usage directly from your RunPod dashboard. In our case, GPU utilization reached ~99%, which confirms that the model is efficiently training on the GPU.
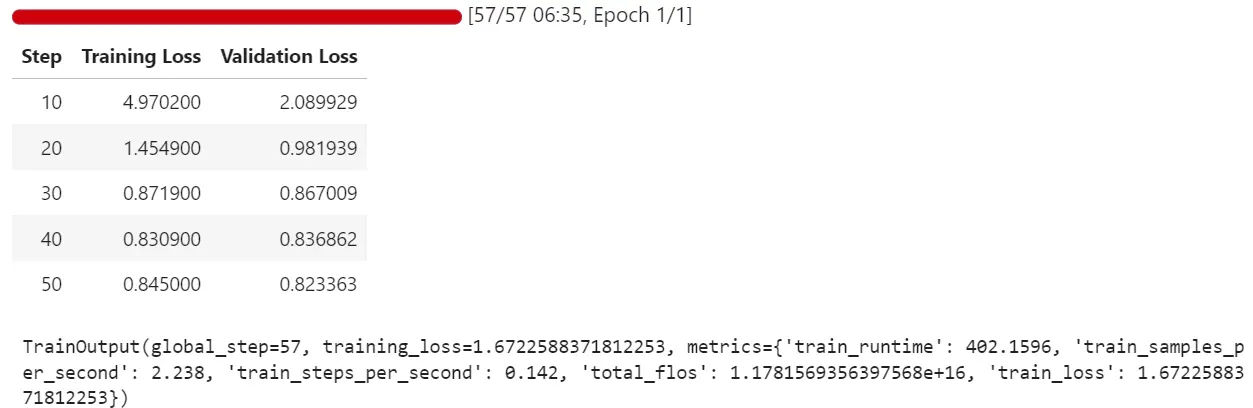
The training process took about 7 minutes per epoch. As expected, both training and validation losses decreased steadily, indicating that the model was successfully learning patterns from the new dataset.
Before running evaluations, we will save the fine-tuned model locally and then push it to the Hugging Face Hub. The push_to_hub method automatically creates a new repository and uploads the model's LoRA weights, training arguments, and metadata.
trainer.save_model(SAVED_MODEL_ID)
trainer.push_to_hub(dataset_name=SAVED_MODEL_ID)The fine-tuned model is now available at [your-hf-username]/gpt-oss-20b-dermatology-qa (e.g. kingabzpro/gpt-oss-20b-dermatology-qa).
If you encounter issues running the above code, please refer to the provided notebook in the project repository: fine-tuning-gpt-oss-derma.ipynb.
9. Evaluate Model Inference (After Fine-Tuning)
Now that training is complete, it is time to evaluate the fine-tuned model.
First, restart your Jupyter kernel to free up GPU memory. Then, reload the base model (GPT-OSS 20B) and merge it with the fine-tuned LoRA adapter using the merge_and_unload function. This gives us a single model with the fine-tuned weights applied.
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
BASE_MODEL_ID = "openai/gpt-oss-20b"
SAVED_LORA_MODEL_ID = "gpt-oss-20b-dermatology-qa"
# Load the tokenizer
tokenizer = AutoTokenizer.from_pretrained(BASE_MODEL_ID)
# Load the original model first
model_kwargs = dict(
attn_implementation="eager", torch_dtype="auto", use_cache=True, device_map="cuda"
)
base_model = AutoModelForCausalLM.from_pretrained(
BASE_MODEL_ID, **model_kwargs
)
# Merge fine-tuned weights with the base model
model = PeftModel.from_pretrained(base_model, SAVED_LORA_MODEL_ID)
model = model.merge_and_unload()Since the kernel was reset, all temporary variables and datasets are cleared.
We will reload the dataset, split it into train/test sets (using the same seed for reproducibility), and re-add utility functions for prompt formatting and answer extraction.
from datasets import load_dataset
# Load dataset
dataset = load_dataset("kingabzpro/dermatology-qa-firecrawl-dataset", split="train")
dataset = dataset.train_test_split(test_size=0.1, seed=42)
from openai_harmony import (
Conversation,
DeveloperContent,
HarmonyEncodingName,
Message,
Role,
load_harmony_encoding,
)
# Load the Harmony encoder once
enc = load_harmony_encoding(HarmonyEncodingName.HARMONY_GPT_OSS)
DERM_DEV_INSTRUCTIONS = (
"You are a board-certified dermatologist answering various dermatology questions."
" Answer clearly in 1-3 sentences. No speculation."
)
def render_inference_harmony(question: str) -> str:
"""Harmony-formatted prompt for inference."""
convo = Conversation.from_messages(
[
Message.from_role_and_content(
Role.DEVELOPER,
DeveloperContent.new().with_instructions(DERM_DEV_INSTRUCTIONS),
),
Message.from_role_and_content(Role.USER, question.strip()),
]
)
tokens = enc.render_conversation_for_completion(convo, Role.ASSISTANT)
return enc.decode(tokens)
def extract_final_answer(text):
# Find the start of the assistant's final message
start_marker = "<|start|>assistant<|message|>"
start_idx = text.find(start_marker)
if start_idx == -1:
return "No answer found in the text"
# Move to the beginning of the actual answer
start_idx += len(start_marker)
# Find the end of the answer (either next tag or end of text)
end_idx = text.find("<|end|>", start_idx)
if end_idx == -1:
end_idx = len(text)
# Extract and clean the answer
answer = text[start_idx:end_idx].strip()
return answerWe will provide the 21st sample from the test dataset to the fine-tuned model and generate the response, displaying only the answer instead of the full response.
question = dataset["test"][20]["question"]
text = render_inference_harmony(question)
inputs = tokenizer(text, return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
final_answer = extract_final_answer(response[0])
print(final_answer)As a result, our fine-tuned model has generated a concise, relevant answer similar to how the dataset is designed.
During winter, the dry skin that is typical in eczema can become even more dry, which may worsen eczema symptoms. The lack of moisture in the air can increase skin dryness.Let's try another sample from the dataset.
question = dataset["test"][50]["question"]
text = render_inference_harmony(question)
inputs = tokenizer(text, return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
final_answer = extract_final_answer(response[0])
print(final_answer)The generated answer is similar to the original answer. We have fine-tuned the model to adapt to the style and ensure it generates fewer tokens in response to dermatology questions.
The source suggests that clinicians approach the diagnosis of rosacea as a dynamic process that requires ongoing reassessment as patients develop new symptoms or present new presentations, rather than a one-time determination. This approach is intended to address changing manifestations within patients and evolving presentations in the population.Here is the ground truth answer.
dataset["test"][50]["answer"]It's quite similar to the generated response.
'The source suggests using a stepped approach, which typically involves evaluating the patient and then progressing through treatment options as needed. The text also mentions a differential diagnosis list to aid in distinguishing rosacea from other similar conditions.'10. Run Inference with Hugging Face Pipeline
So far, we have taken multiple steps to run inference: loading the base model, merging LoRA weights, setting up the tokenizer, and formatting prompts with Harmony.
But what if there was a simpler way?
Enter the Hugging Face pipeline API.
With just the model name, task type, and device, you can start asking questions directly, no manual merging or setup required.
Restart the kernel to free up memory, then try the following code:
from transformers import pipeline
# Replace with your actual HuggingFace username
model_path = "PUT_YOUR_HUGGINGFACE_USERNAME_HERE/gpt-oss-20b-dermatology-qa"
# For testing, you can also use the example model:
# model_path = "kingabzpro/gpt-oss-20b-dermatology-qa"
# Load pipeline
generator = pipeline(
"text-generation",
model=model_path,
device="cuda" # or device=0
)
question = "How does the source suggest clinicians approach the diagnosis of rosacea?"
output = generator(
[{"role": "user", "content": question}],
max_new_tokens=200,
return_full_text=False
)[0]
print(output["generated_text"])The generated answer is quite similar to the dataset but lengthy. Why? We still need to provide it with a similar style and instructions that the model was trained on.
The source advises that clinicians should not rely solely on clinical presentation to diagnose rosacea. Instead, they should use a standardized, validated diagnostic tool such as the 2016 International Rosacea Consensus (IRC) criteria to confirm the diagnosis. This approach ensures a consistent and evidence-based assessment rather than a subjective interpretation of symptoms.To get answers closer to the fine-tuning dataset style, we need to guide the model with the same instructions used during training. Let's wrap the question in the Harmony-style prompt:
prompt = "<|start|>developer<|message|># Instructions\n\nYou are a board-certified dermatologist answering various dermatology questions. Answer clearly in 1-3 sentences. No speculation.<|end|><|start|>user<|message|>How does the source suggest clinicians approach the diagnosis of rosacea?<|end|><|start|>assistant"
output = generator(
prompt,
max_new_tokens=200,
return_full_text=False
)[0]
print(output["generated_text"])As a result, we achieved much better outcomes that match our training dataset's concise style, compared to the verbose response from the first approach.
The source indicates that clinicians should consider rosacea when patients present with erythematous facial skin and may need to differentiate it from other conditions such as acne. Recognizing these features helps in identifying rosacea.This is the power of prompt engineering!
- Without instructions: the model still works, but responses are longer and less aligned with the dataset style.
- With Harmony-style instructions: the model produces short, precise, and clinically relevant answers, exactly as intended.
Summary
This tutorial walked through the end-to-end process of fine-tuning GPT-OSS 20B on a custom dermatology Q&A dataset created with Firecrawl's web search API.
- Environment setup: A RunPod A100 pod with PyTorch was used, installing required libraries (transformers, trl, peft, openai-harmony, etc.) and logging into Hugging Face Hub.
- Model & Tokenizer loading: GPT-OSS 20B was loaded with bf16 support for efficient inference.
- Harmony prompt format: Q&A pairs were wrapped in OpenAI Harmony format, ensuring structured, role-based training data.
- Dataset preparation: The dataset was converted into Harmony-formatted text and split into train/test sets.
- Baseline inference: Pre-fine-tuning inference showed verbose answers with hidden reasoning tokens, highlighting the need for domain adaptation.
- LoRA Fine-Tuning: LoRA adapters were applied to selected MLP layers, updating only 0.07% of parameters for efficient training.
- Training with SFTTrainer: The model was fine-tuned in ~7 minutes per epoch, with steadily decreasing training/validation loss.
- Evaluation: After merging LoRA weights, the fine-tuned model produced concise, clinically relevant answers aligned with the dataset style.
- Pipeline inference: Hugging Face pipeline simplified inference, but prompt engineering (Harmony-style instructions) was key to achieving short, precise, domain-specific answers.
With the example, we see how fine-tuning can transform a general-purpose language model into a domain-specific expert with minimal computational resources. By leveraging AI search capabilities through web crawling API tools to build high-quality datasets, and then using LoRA adapters with structured prompt formatting, we successfully adapted GPT-OSS 20B to generate concise, clinically relevant dermatology responses that match our dataset's style.
Effective fine-tuning requires not just quality data and proper training configuration, but also consistent prompt engineering throughout the entire pipeline, from training to inference. The combination of modern AI crawling techniques for dataset creation and efficient fine-tuning methods demonstrates how web scraping API services can accelerate AI development. With just a few hours of cloud compute time and careful attention to format consistency, you can apply this same approach to create specialized models for your own domain expertise.
For more advanced applications, explore how fine-tuned models can power RAG systems or learn about other fine-tuning approaches with Gemma 3 using similar web-scraped datasets.
