
TL;DR
- n8n is a no-code workflow automation platform with 500+ integrations — build complex scrapers visually in minutes by connecting nodes
- Firecrawl is now a native n8n integration: install the node on n8n Cloud, click Connect, and start building without managing API keys separately
- n8n Cloud credit offer: the launch offer has expired; get 10,000 free credits when you connect Firecrawl through n8n Cloud
- Three official starter templates cover RAG ingestion into Pinecone, Supabase vector storage, and company lead enrichment
- This post covers eight additional proven workflow patterns for market intelligence, competitor monitoring, lead generation, and more
Web scraping used to require coding skills, debugging sessions, and constant maintenance work. Today, n8n has changed the game by making complex data extraction workflows accessible through visual automation. With over 500 integrations and AI-powered nodes, you can build scrapers that would take weeks to code in just minutes.
The platform's template library already contains many proven scraping workflows that tackle real business problems. From monitoring website changes to scraping Google Maps, these patterns show how teams automate their data collection with little to no code. You can clone any workflow and customize it for your specific needs without starting from scratch.
Get Started: Learn the basics with our Firecrawl + n8n automation guide. For visual AI development without n8n, try our LangFlow tutorial.
This article showcases eight of these proven workflows, covering everything from competitive intelligence to lead generation. Each template demonstrates how teams use visual automation and AI-powered extraction to solve real data collection challenges.
Each workflow includes detailed descriptions, technical implementation insights, and tips for customization. You can import these templates directly into your n8n instance and adapt them for your specific needs. By the end, you'll have a toolkit of workflows ready to deploy for a wide range of scraping projects.
Firecrawl is now a native n8n integration — install the Firecrawl node on n8n Cloud, click Connect, and you're ready to build. No separate sign-up, no API keys to track down.
n8n Cloud credit offer: The launch offer has expired. Get 10,000 free credits when you connect Firecrawl through n8n Cloud.
What is n8n?
n8n is a visual workflow automation platform that lets you connect apps and services without coding. Think of it as a more powerful alternative to Zapier.
Instead of writing code, you drag and drop "nodes" (building blocks) to create automated workflows. Each node performs one task—like "scrape a website" or "send an email"—and data flows between them to complete the full process.
For example, a workflow could look like, "Every hour → Check competitor website → If changes detected → Send Slack notification." Each arrow represents data flowing from one node to the next.
This article assumes you're familiar with n8n. If not, check the n8n quickstart guide first. The import links below take you to n8n's workflow library where you can preview templates and copy them to your own instance.
Why use Firecrawl in your n8n workflows?
Standard HTTP request nodes only fetch raw HTML. That means JavaScript-rendered content and dynamically loaded data come back empty or broken. Firecrawl removes those problems:
- JavaScript rendering: handles React, Vue, and other dynamic sites automatically — no headless browser to set up or maintain
- Clean, structured output: converts any webpage to LLM-ready markdown or structured JSON, so data flows straight into AI nodes without reformatting
- Full API surface in one node: use Firecrawl's web scraping API to scrape single pages, crawl entire sites, run web searches with content, map site structure, and extract specific fields using natural language prompts — all available through the Firecrawl node
- Native integration on n8n Cloud: one-click connect, usage tracked in your Firecrawl dashboard, no credential juggling
How to connect Firecrawl to n8n
On n8n Cloud:
- In your workflow, open the Nodes Panel and search for Firecrawl
- Add the node and click Connect to Firecrawl in the credentials panel
- Enter your email — n8n creates your Firecrawl account automatically
- Done. Your 10,000 free credits are active
On self-hosted n8n:
An admin needs to enable community nodes in the Admin Panel and install the Firecrawl node. Once installed, anyone on the instance can connect by adding the node to a workflow and entering their Firecrawl API key from firecrawl.dev/app.
Three official Firecrawl + n8n starter templates
The native integration ships with three official templates to get you building immediately:
1. Scrape and ingest web pages into a Pinecone RAG stack
Send a URL, Firecrawl scrapes it into clean markdown, and n8n stores it as vector embeddings in Pinecone and other vector databases. A chat interface lets an AI agent query the knowledge base with context-aware answers. Use this to build internal knowledge bases from documentation, support articles, or product pages.
2. Scrape and ingest web content into Supabase pgvector
Same ingestion pattern, but with Supabase as your vector store — open-source, self-hostable, and with built-in deduplication. Use this when you want full control over where your data lives.
3. Enrich company leads with Firecrawl, OpenRouter AI, and Supabase
Point it at any company website and get back structured business signals: industry, pricing model, funding stage, tech stack, and hiring status. Use this to enrich inbound leads or build a competitive landscape database running entirely on your own infrastructure.
Eight n8n web scraping workflow templates
Let's explore eight powerful n8n web scraping workflows that solve real business problems. Each template demonstrates how to extract, process, and deliver web data without writing complex code.
How these workflows work
All these workflows follow n8n automation patterns and best practices:
- HTTP Request nodes that communicate with Firecrawl's API endpoints using simple POST requests and API keys
- Data transformation logic using Code nodes to filter, format, and process scraped content before sending it downstream
- Multi-platform output integration connecting scraped data to Slack notifications, Gmail alerts, Telegram messages, and Google Sheets storage
- Flexible scheduling mechanisms including time-based triggers, webhook activations, and manual form submissions
- Built-in error handling with retry logic, timeout configurations, and fallback workflows to handle API failures gracefully
- Asynchronous job management for large-scale crawling operations that process multiple URLs in parallel
These eight n8n workflows are made with Firecrawl's AI-powered web scraping engine.
While traditional web scraping approaches require constant maintenance when websites change their HTML structure, Firecrawl solves this by converting any website into clean, structured data that works reliably across different sites and frameworks. Instead of writing brittle CSS selectors that break when websites update their design, Firecrawl handles JavaScript-heavy sites automatically and provides multiple output formats, making n8n workflows more maintainable and robust.
If you're interested in building similar automations, Firecrawl's documentation provides comprehensive guides for getting started.
For more on Firecrawl's integrations with n8n for powerful no-code solutions, see our previous article about Firecrawl and n8n web automation.
Explore More Tools: Compare web scraping libraries for custom implementations or explore browser automation tools for complex JavaScript sites.
1. AI-powered market intelligence bot
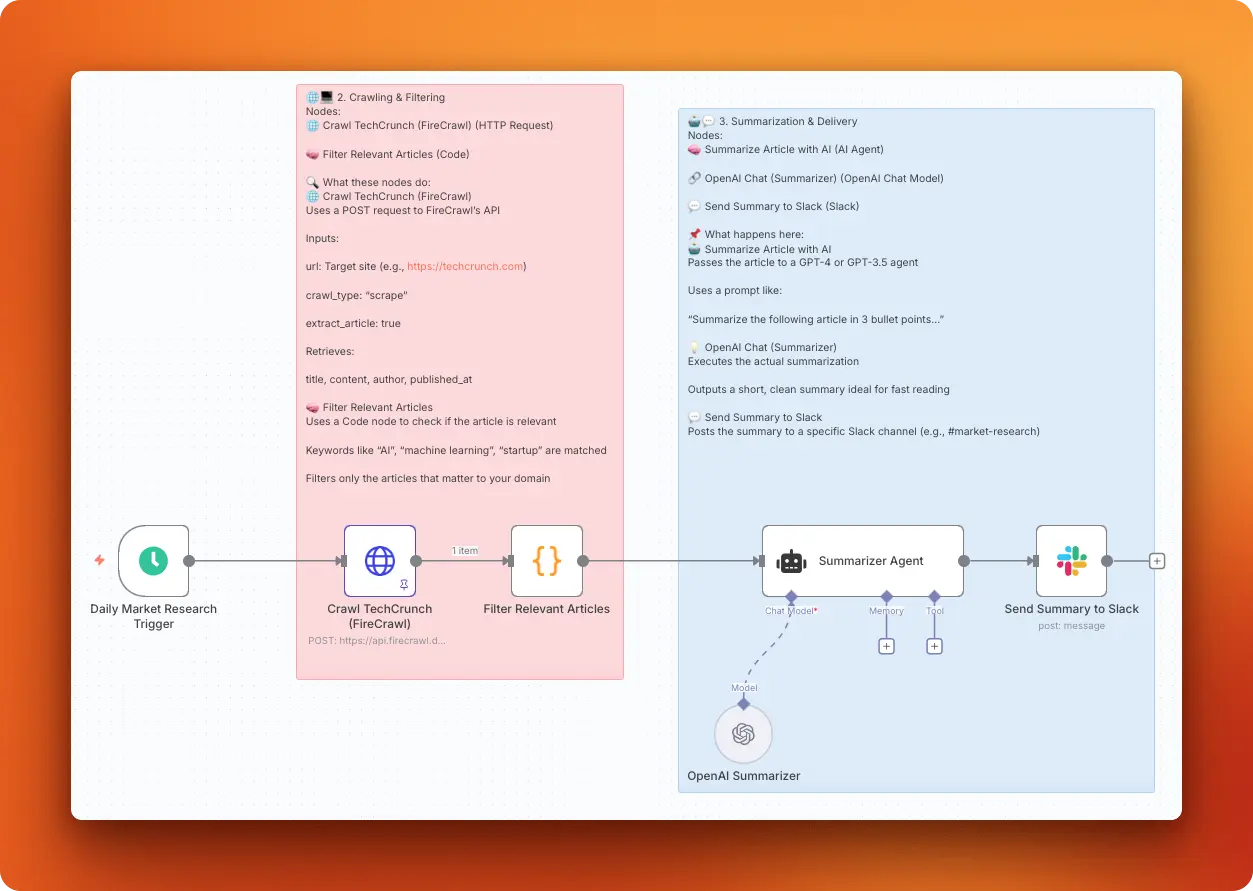
This workflow automates the collection and analysis of market-related data, specifically news and insights relevant to particular industries or niches. This workflow scrapes news articles, processes the data for sentiment analysis, and delivers concise insights to stakeholders via preferred communication channels.
Import link: AI-powered market intelligence bot
Key features
- Automated scraping: Continuously monitors news sources for relevant articles without manual checking
- AI filtering: Uses keyword matching and sentiment analysis to surface only relevant content
- Flexible delivery: Sends summaries to Slack, email, or other preferred communication channels
- Easy customization: Adjust sources, keywords, and delivery frequency as needs change
Technical details
Scraping strategy: You configure Firecrawl's API through an HTTP POST request to the /scrape endpoint. The endpoint crawls the given URL and returns structured article data including title, content, author, and publication date while automatically handling JavaScript rendering and dynamic content loading. The HTTP node contains the details of this POST request and how the article parsing is handled.
Data processing: A Code node filters scraped articles using keyword matching against predefined terms like "AI", "machine learning", "startup", and "generative" in JavaScript. The filtering logic checks both article titles and content, keeping only articles where the title or content includes any specified keyword.
AI processing: The workflow connects an AI Agent node to OpenAI's gpt-4o-mini model with the prompt "Summarize the following article in 3 bullet points" followed by the article title, description, and content. This model choice balances cost and quality while producing concise summaries perfect for quick team updates.
Output format: Summaries are posted to a specified Slack channel using the format "🔍 AI Research Summary:" followed by the article title, source link, and the AI-generated bullet points. The message structure makes it easy to scan multiple updates and click through to full articles when needed.
Business value
This workflow helps market analysts, product managers, and marketing teams stay informed about industry developments without manual research. Teams can monitor competitor news, industry trends, and customer sentiment with minimal time investment.
Implementation tips
- Customization: Adapt the workflow to fit the specific needs of your organization by adjusting the scraped sources or the frequency of data collection. Regularly review and update the sources so it stays relevant.
- User Feedback: Gather feedback from stakeholders regarding the relevance and format of the insights delivered to make ongoing adjustments to the workflow.
- Integration: Consider integrating this workflow with CRM systems or dashboards to visualize insights and make them more accessible to decision-makers.
2. Monitor website changes with Gmail alerts
![]()
This workflow automatically monitors any webpage for content changes and sends email notifications when changes are detected. It uses Firecrawl to scrape content, Google Sheets to store and compare versions, and Gmail to deliver alerts when differences are found.
Import link: Monitor dynamic website changes with Firecrawl, Sheets and Gmail alerts
Key features
- Dynamic website support: Handles JavaScript-heavy sites that basic scrapers can't access
- Smart notifications: Only sends alerts when content actually changes to avoid spam
- Historical tracking: Maintains a complete log of all changes in Google Sheets
- Reliable operation: Continues working even if individual components fail
Technical details
Scraping strategy: You configure Firecrawl's API through an HTTP POST request to extract webpage content in both markdown and HTML formats. The request uses Bearer token authentication and targets your specified URL for monitoring.
Output format: When changes occur, Gmail sends email alerts with timestamps describing what content changed.
Business value
This workflow helps teams monitor competitor websites, product pages, pricing updates, or important announcements without manual checking. Perfect for staying informed about changes that could impact business decisions while saving time on routine monitoring tasks.
Implementation tips
- Setup requirements: Configure API credentials for Firecrawl, Google Sheets OAuth2, and Gmail access before deployment.
- Sheet structure: Create Google Sheets with "Log" and "Comparison" tabs following the workflow's expected format.
- Customization: Adjust monitoring frequency, change email templates, or modify sensitivity settings based on your specific monitoring needs.
3. Daily website data extraction with Telegram alerts
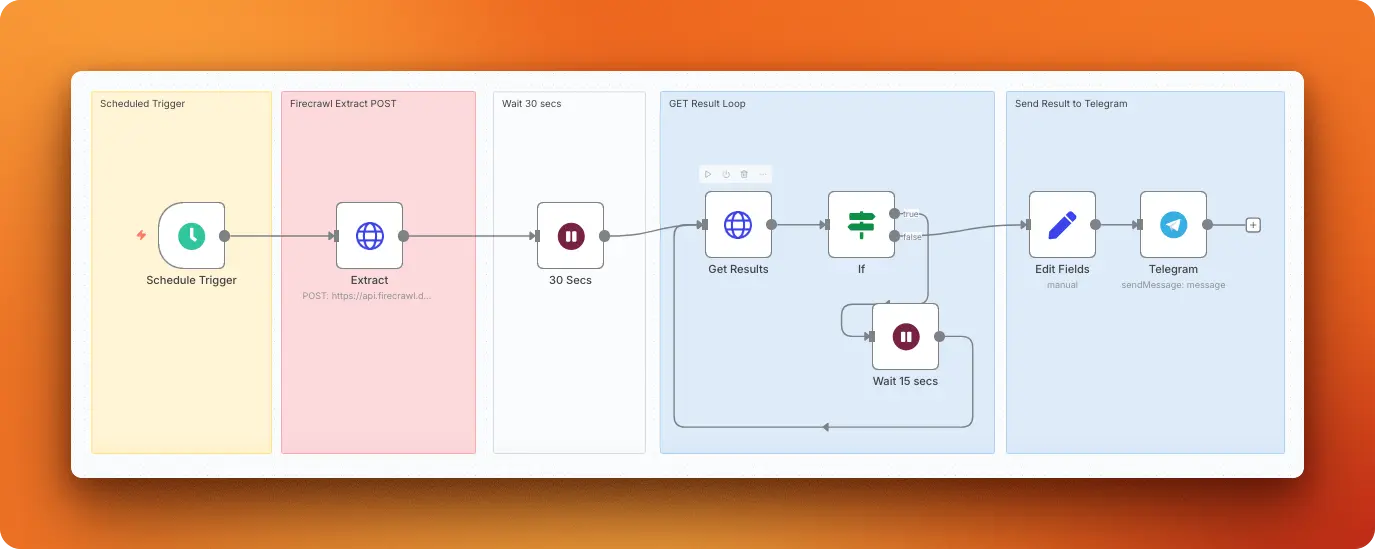
This workflow extracts structured data from any webpage daily using Firecrawl's AI-powered extraction engine and delivers formatted results to your Telegram chat. You can target specific data points using custom prompts and JSON schemas, making it perfect for tracking product updates, financial data, or any structured information that changes regularly.
Import link: Daily website data extraction with Firecrawl and Telegram alerts
Key features
- Daily automation: Runs at a specified time to extract fresh data without manual intervention
- Custom extraction: Uses natural language prompts and JSON schemas to target specific information
- Smart retry logic: Waits and retries if initial processing fails to ensure reliable data collection
- Instant Telegram delivery: Sends formatted results directly to your chat for immediate access
Technical details
Scraping strategy: You configure Firecrawl's /extract endpoint with a custom JSON schema that defines exactly which data fields to extract, such as member names, transaction amounts, and dates. You include a prompt field with extraction instructions, submit the job via POST request, then retrieve the structured results with a follow-up GET request.
Output format: The workflow sends results as plain text messages to a specified Telegram chat using the data variable. The message contains the raw extracted data in whatever format Firecrawl returns, which typically includes all the structured fields defined in the original schema.
Business value
This workflow helps teams automate data collection from websites that update regularly, such as financial data, product information, or compliance monitoring. You can stay informed about important changes without manual checking while ensuring consistent data format for analysis.
Implementation tips
- Design detailed schemas: Create JSON schemas that specify exactly what data fields you want to extract.
- Test extraction accuracy: Verify the workflow captures the right data before setting up daily scheduling.
- Monitor processing times: Adjust wait times if your target websites typically take longer to process.
4. Scrape public email addresses
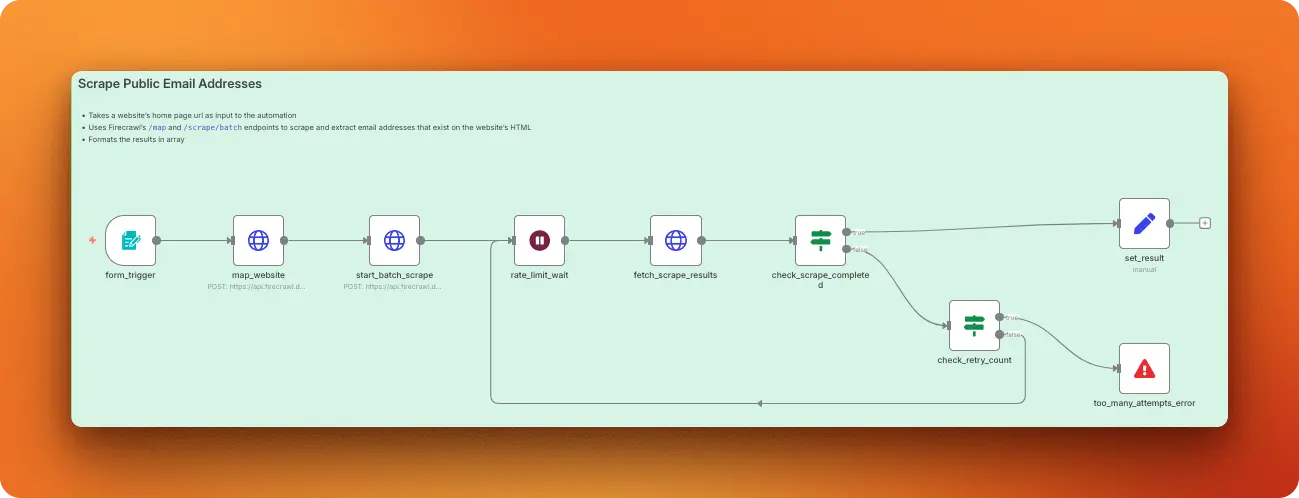
This workflow discovers and extracts all public email addresses from any website by mapping relevant pages and scraping them with AI-powered extraction. It handles common email obfuscation techniques like replacing "@" with "(at)" or "." with "(dot)" and returns a clean, deduplicated list of valid email addresses.
Import link: Scrape public email addresses from any website using Firecrawl
Key features
- Intelligent page discovery: Maps websites to find contact, about, and team pages likely to contain emails
- Handles obfuscation: Converts "(at)" and "(dot)" back to proper email format automatically
- Smart deduplication: Returns only unique, valid email addresses with case-insensitive filtering
- Error handling: Includes retry logic to handle processing delays and failed requests
Technical details
Scraping strategy: The workflow starts with Firecrawl's /v1/map endpoint to discover relevant pages using the search terms "about contact company authors team" with a limit of 5 pages. These discovered URLs then get passed to the /v1/batch/scrape endpoint with both markdown and json formats enabled, The batch scrape includes a detailed JSON schema that expects an email_addresses array with valid email format validation.
Data processing: The workflow handles email obfuscation by converting variants like "user(at)example(dot)com" to proper "user@example.com" format. It then combines email addresses from all scraped pages, filters out invalid entries, and includes retry logic to handle processing delays.
Output format: The workflow returns results as a clean array called scraped_email_addresses containing all unique email addresses found across the mapped pages. The workflow deduplicates addresses case-insensitively and excludes any emails hidden in HTML comments, script tags, or style blocks.
Business value
This workflow helps sales and marketing teams quickly gather contact information from target websites without manual browsing or copy-pasting. You can build prospect lists, research potential partners, or collect leads for outreach campaigns while saving hours of manual email hunting.
Implementation tips
- Target relevant page types: Modify the search terms to focus on specific page types that match your target audience.
- Validate extracted emails: Consider adding email validation services for higher accuracy in outreach campaigns.
- Respect rate limits: Monitor your Firecrawl usage to avoid hitting API limits with large-scale scraping operations.
5. Stock trade report generation
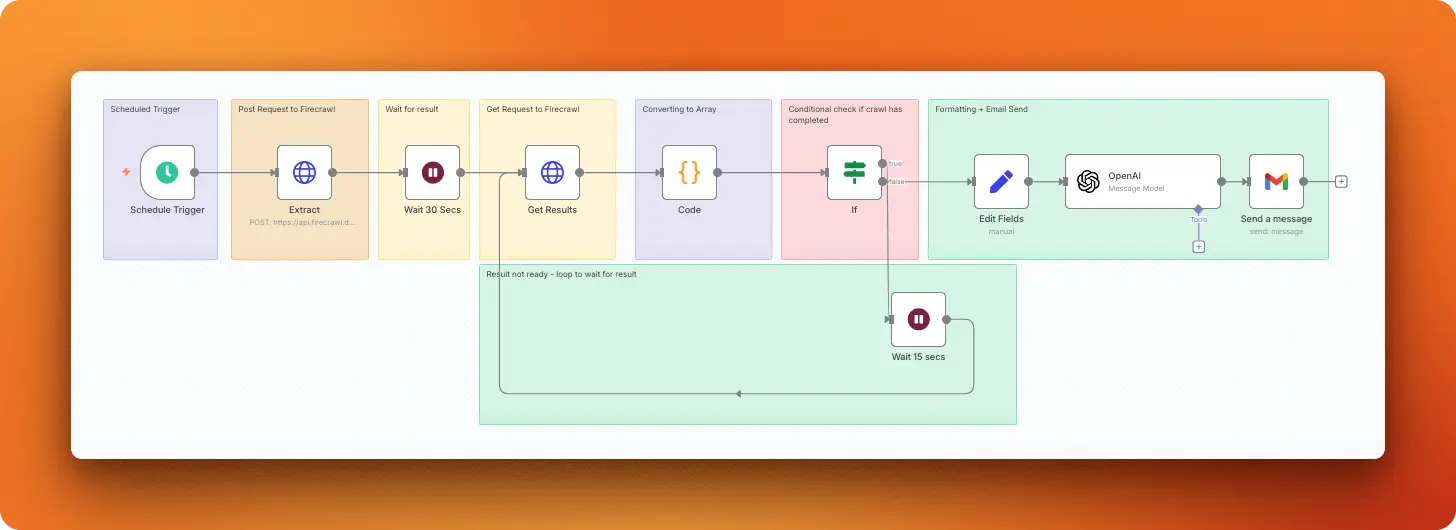
This workflow extracts congressional trading data from Quiver Quantitative's website, focusing on trades over $50,000 in the past month. It uses Firecrawl to scrape structured trading information, OpenAI to format the data into readable summaries, and Gmail to deliver daily reports with transaction details including congress member names, parties, assets traded, and amounts.
Import link: Daily US Congress members stock trades report via Firecrawl + OpenAI + Gmail
Key features
- Daily automation: Runs at a scheduled time to extract the latest congressional trading data
- AI formatting: Transforms raw trading data into human-readable summaries with key details
- High-value filtering: Focuses only on trades over $50,000 to surface significant transactions
- Email delivery: Sends formatted reports directly to your inbox for review
Technical details
Scraping strategy: The workflow uses Firecrawl's /extract endpoint to scrape congressional trading data from Quiver Quantitative. It includes a custom JSON schema and prompt specifically designed to extract trading information from their congress trading page, then retrieves the processed results with a follow-up GET request.
AI processing: The workflow connects to OpenAI's chatgpt-4o-latest model with a system prompt that formats raw trading data into readable summaries showing "Transaction Date, the Stock/Asset Purchase Amount, The Name of the Stock, the Name of the Purchaser and his/her party." The model receives the extracted JSON data and returns structured, human-readable trade summaries.
Output format: Gmail sends the formatted report with the subject "Congress Trade Updates - QQ" as plain text email. The message contains the AI-formatted trading summary that typically includes date, congress member name with party affiliation, stock symbol, and transaction amount in an easily scannable format.
Business value
This workflow helps investors and researchers get automated daily intelligence on congressional trading activity without manual website monitoring or data formatting. You can track significant trades that might indicate market trends or legislative insights while saving time on routine data collection.
Implementation tips
- Monitor data quality: Review the first few reports to ensure extraction captures all relevant trading information accurately.
- Customize filtering criteria: Adjust the $50,000 threshold or time range to match your specific research interests.
- Set optimal timing: Schedule the workflow to run after Quiver Quantitative typically updates their data for the day.
6. Competitor website monitoring
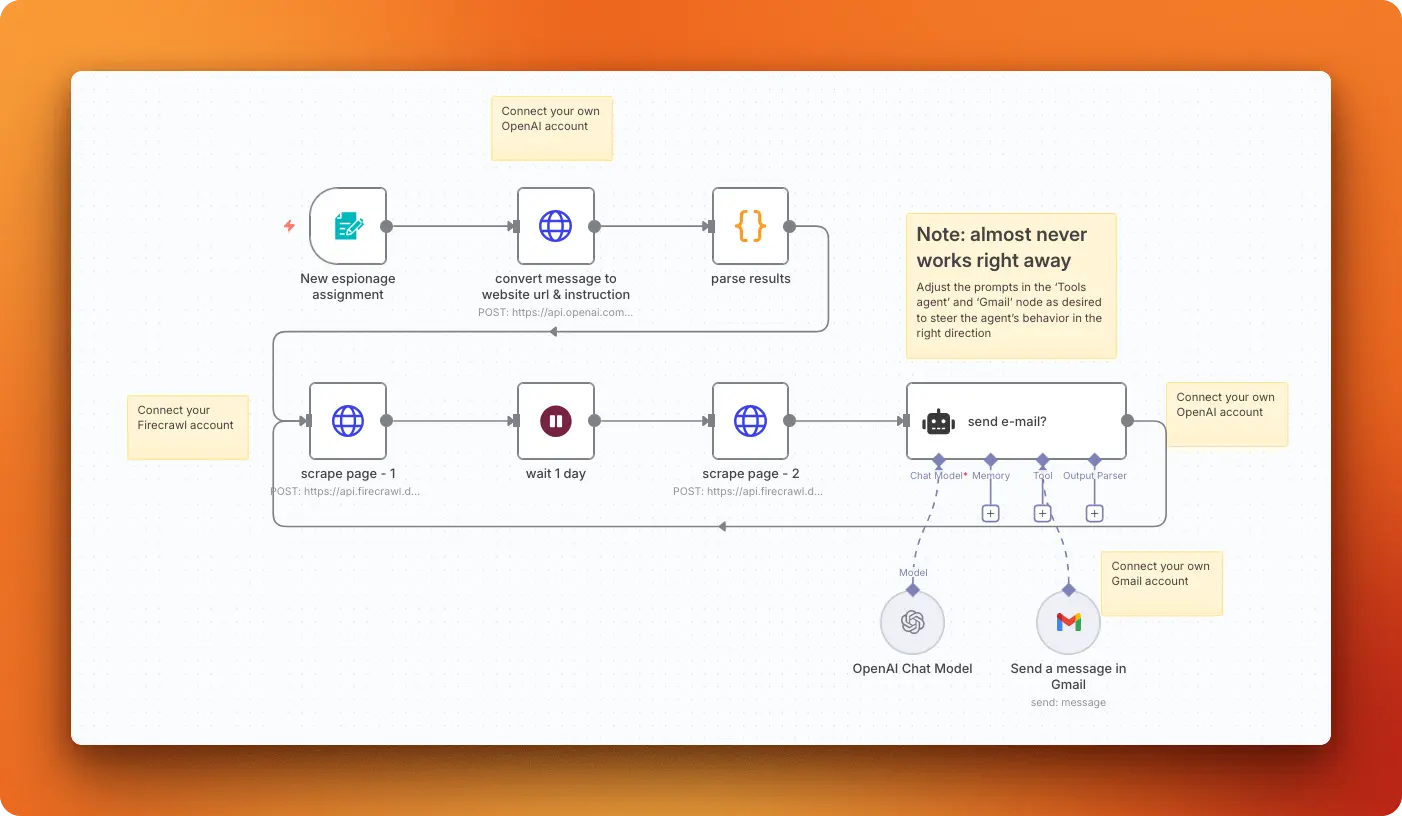
This workflow monitors competitor websites for content changes by taking natural language instructions, scraping the target site twice with a 24-hour gap, and using AI to analyze differences before sending email alerts when relevant changes occur. You submit instructions like "monitor TechCorp's pricing page for price changes" and the system handles URL extraction, daily monitoring, and intelligent change detection.
Firecrawl's /monitor now covers this pattern directly when you want the monitoring layer outside n8n: enter a URL, describe what to track in plain English, and let /monitor configure the URLs, schema, and schedule. When meaningful changes occur, it can fire a signed webhook to your agent or send an email with the diff in the body.
Import link: Monitor competitors websites for changes with OpenAI and Firecrawl
Key features
- Natural language setup: Describe what you want to monitor in plain English rather than technical configurations
- AI-powered analysis: Only sends alerts for meaningful changes, not minor website updates or formatting tweaks
- 24-hour monitoring cycle: Automatically scrapes, waits a day, then compares to detect real changes
- Intelligent filtering: Uses AI to determine if detected changes match your specific monitoring criteria
Technical details
Scraping strategy: You start with a Form Trigger that accepts natural language assignment instructions, then OpenAI's gpt-4o-2024-08-06 model extracts the target URL and monitoring criteria from your input. Two separate Firecrawl API calls to /v1/scrape collect website content in Markdown format with a 24-hour wait between scrapes.
Data processing: The workflow parses the AI response to extract the website url and monitoring instructions, then stores both scraping results for comparison.
AI processing: A LangChain agent compares the old and new content using your custom monitoring instructions. The AI analyzes content differences and determines whether changes match your monitoring criteria before triggering notifications.
Output format: When relevant changes are detected, Gmail sends a plain text email with the subject "Relevant changes on [website_url]" providing contextual descriptions of the detected changes.
Business value
This workflow helps teams get automated competitor intelligence with AI-powered filtering that only sends alerts for meaningful changes rather than minor updates. You can monitor pricing strategies, content updates, job postings, or policy changes (see our guide on automated competitor price scraping for a deeper look at that pattern) while saving time on manual competitive research. If you want Firecrawl to handle the monitoring loop natively — sending a signed webhook to your n8n workflow when meaningful changes occur — see the /monitor endpoint launch post.
Implementation tips
- Write clear monitoring instructions: Be specific about what types of changes matter to avoid false alerts.
- Start with important pages: Begin monitoring key competitor pages like pricing, product features, or team pages.
- Review AI accuracy: Check the first few alerts to ensure the AI correctly identifies relevant changes for your criteria.
7. Google Maps business scraper
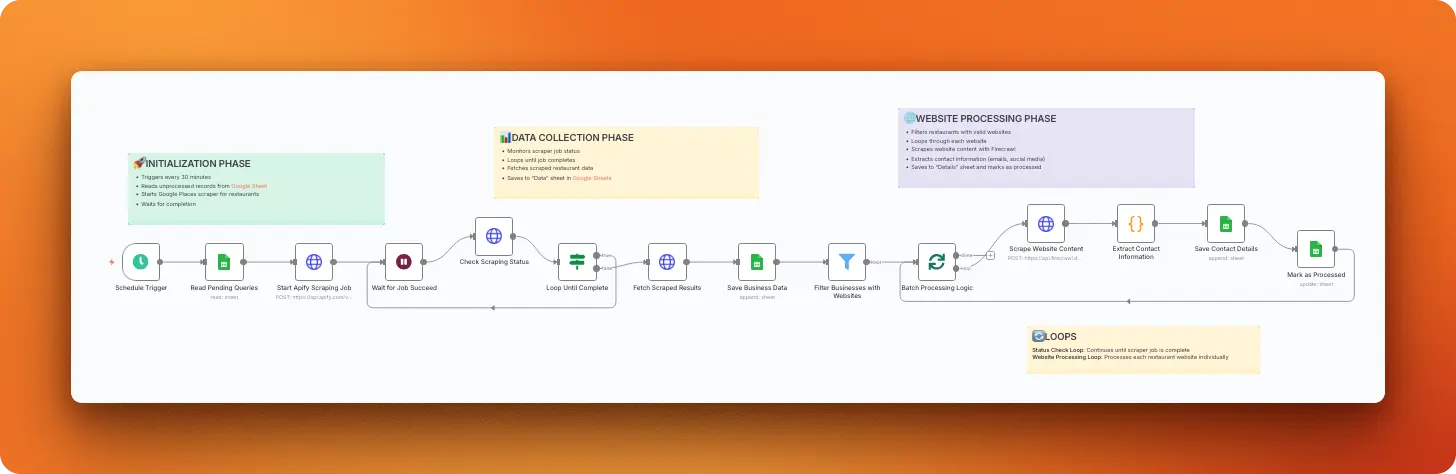
This workflow discovers local businesses from Google Maps using Apify's scraper, then extracts detailed contact information from each business website using Firecrawl. It handles the complete pipeline from search queries to structured contact data, including emails, social media profiles, and business details stored in organized Google Sheets.
Import link: Google Maps business scraper with contact extraction via Apify and Firecrawl
Key features
- Automated business discovery: Finds local businesses from Google Maps based on your search criteria and location
- Complete contact extraction: Gathers emails, phone numbers, and social media profiles from business websites
- Organized data storage: Stores all information in structured Google Sheets for easy access and follow-up
- Scheduled operation: Runs every 30 minutes to continuously build your business database
Technical details
Scraping strategy: You use Apify's compass~crawler-google-places actor through HTTP POST requests to /v2/acts/compass~crawler-google-places/runs with parameters like searchStringsArray: ["restaurant"], locationQuery: "New York, USA", and maxCrawledPlacesPerSearch: 15. After initiating the job, the workflow polls the status endpoint every 30 seconds until completion, then fetches results from the dataset.
Data processing: A Filter node identifies businesses with valid websites, then processes each business individually to avoid API rate limits. The workflow extracts contact information using regex patterns for emails, LinkedIn URLs, Facebook pages, Instagram profiles, and Twitter handles from the scraped HTML content.
Output format: Results are stored in two separate Google Sheets tabs: "Data" contains basic business information (title, address, phone, website, category name) while "Details" stores extracted contact information (emails, Linkedin, Facebook, Instagram, Twitter). Each processed business gets marked to prevent duplicate processing in future runs.
Business value
This workflow helps sales teams get automated lead generation with complete contact profiles from local businesses without manual research or data entry. You can build comprehensive databases for targeted outreach campaigns, competitive analysis, or market research while saving hours of manual prospecting work.
Implementation tips
- Define search criteria: Use the business type and location parameters to match your target market or industry focus.
- Customize contact fields: Modify the extraction patterns to include additional social platforms or contact methods relevant to your outreach strategy.
8. Ideal customer profile generation
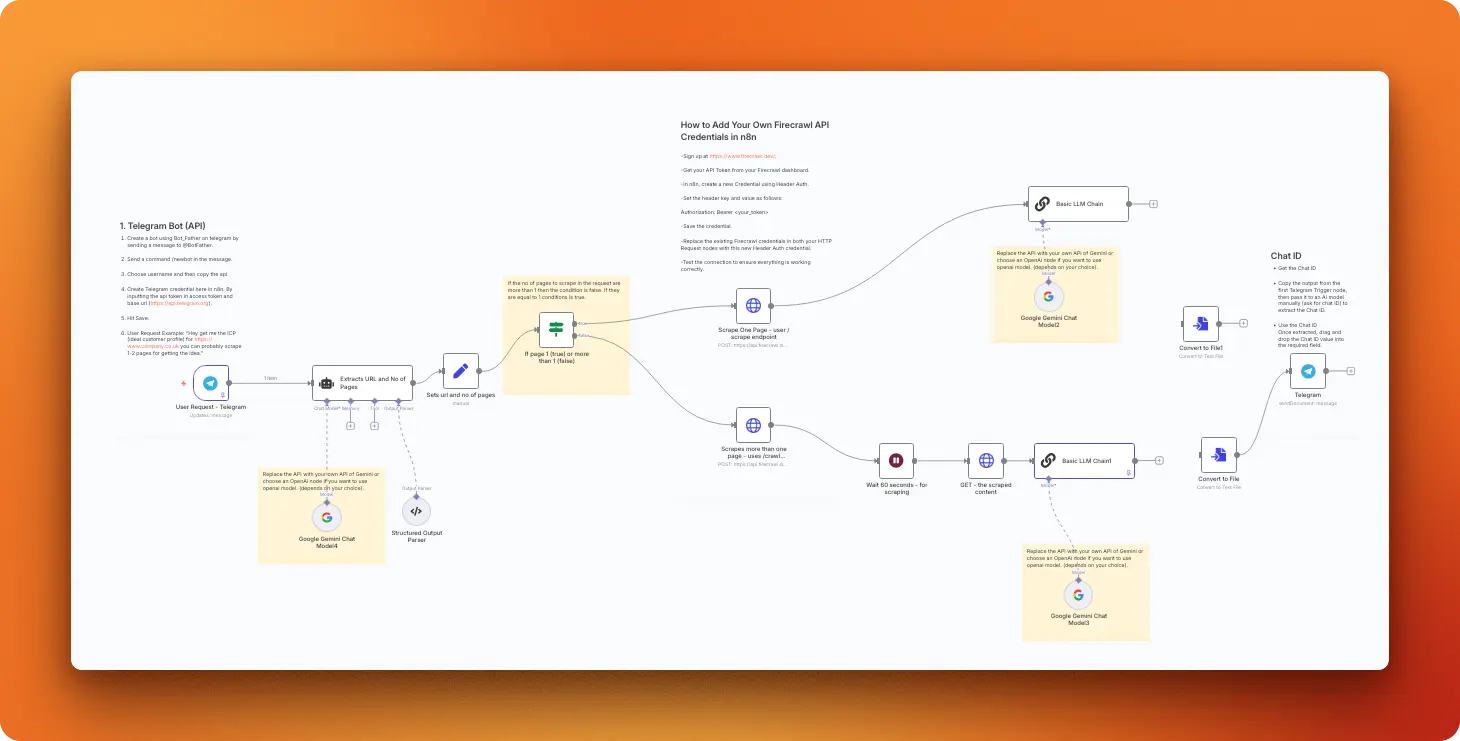
Note: This workflow is priced at $10 by its creator, unlike the other free templates, due to its advanced AI processing capabilities.
This workflow generates detailed ideal customer profiles (ICPs) for any business by analyzing their website content through AI-powered extraction and comprehensive buyer persona analysis. Users send a Telegram message with a company URL, and the system scrapes the website, analyzes the business offering, and creates a detailed customer profile answering nine targeted questions about the dream buyer's habits, motivations, and behaviors. For a more general-purpose Telegram-connected agent with Firecrawl capabilities, see our OpenClaw guide.
Import link: Ideal customer profile generation
Key features
- Conversational interface: Request ICPs by simply messaging a Telegram bot with a company URL and page count
- Intelligent scraping: Automatically chooses single-page scraping or multi-page crawling based on your request
- Comprehensive analysis: Generates detailed profiles answering nine specific questions about customer behavior and preferences
- Professional delivery: Returns structured ICP documents via Telegram for immediate use in marketing strategies
Technical details
Scraping strategy: You use conditional scraping based on user input, employing Firecrawl's /v1/scrape endpoint for single pages or /v1/crawl endpoint for multiple pages with parameters like onlyMainContent: true, formats: ["markdown"], and removeBase64Images: true. A 60-second wait ensures crawl jobs complete before fetching results via GET request to the job URL.
Data processing: A Google Gemini-powered agent extracts the target URL and page count from natural language Telegram messages using structured output parsing. The workflow determines the scraping method: single page scraping for requests of 1 page or less, multi-page crawling for 2-3 pages (capped at 3 for cost control).
AI processing: The workflow uses Google Gemini 2.0-flash models to analyze scraped content and generate comprehensive ICPs following a detailed prompt template. The AI answers nine specific questions covering where buyers congregate, information sources, frustrations, desires, fears, communication preferences, language patterns, daily routines, and happiness triggers. The final output includes a narrative summary resembling professional buyer personas.
Output format: Results are converted to text files and delivered via Telegram as document attachments containing the complete ICP analysis. The response includes both detailed answers to each buyer persona question and a narrative summary that reads like a professional marketing document.
Business value
This workflow helps marketing and sales teams get professional-grade customer personas without hiring expensive consultants or spending weeks on manual research. You can quickly understand target customers directly from competitor websites, create more effective ad campaigns, and develop content that resonates with your audience.
Implementation tips
- Choose representative websites: Target competitor or similar business websites that serve your ideal customer base.
- Limit page count strategically: Use 2-3 pages for comprehensive analysis while managing API costs effectively.
Conclusion
These eight n8n workflows demonstrate how modern web scraping has evolved beyond traditional coding approaches. Each template addresses real business needs—from competitor monitoring to lead generation—using visual automation combined with AI-powered data extraction. Teams can import these workflows immediately and customize them without writing scraping code.
The combination of n8n's visual workflow builder and Firecrawl's extraction engine forms the technical backbone that makes these automations work reliably across different websites and data formats. Firecrawl handles JavaScript rendering and data structuring so your workflows can focus on business logic rather than technical hurdles.
Whether you're monitoring competitors, generating leads, or tracking market intelligence, these workflow patterns provide a foundation for building robust data collection systems.
Expand your toolkit
- Build AI agents with collected data using agent frameworks
- Enhance workflows with RAG frameworks for intelligent data processing
- Convert scraped content to llms.txt files for LLM training
- Integrate with MCP servers for development workflows
- Compare low-code AI workflow automation tools including n8n, Zapier, Make, Cursor Automations, and Claude Routines
Start with Firecrawl's documentation to build similar automations for your specific data collection needs.
Frequently Asked Questions
What is the Firecrawl native n8n integration?
Firecrawl is now a native node on n8n Cloud. You install it from the Nodes Panel and click Connect to Firecrawl during setup. n8n creates your Firecrawl account automatically using your email — no separate sign-up, no API keys to track. If you already have a Firecrawl account, a new team linked to n8n is created and the promotional credits are applied there.
How do I connect Firecrawl to n8n?
On n8n Cloud, search for the Firecrawl node in the Nodes Panel, add it to your workflow, and click Connect to Firecrawl. You will be asked for your email to create your Firecrawl account. That is all — you are connected and your 10,000 free credits are ready. On self-hosted n8n, an admin must enable community nodes and install the Firecrawl node via the Admin Panel first.
What is included in the current n8n Cloud credit offer?
The launch offer that included a free Hobby plan and 100,000 credits has expired. The current offer gives you 10,000 free credits when you connect Firecrawl through n8n Cloud. Scraping costs 1 credit per page, search costs 2 credits per 10 results, and browser interaction costs 2 credits per minute. The 10,000 promotional credits are a one-time allotment and do not reset monthly.
Do I need to know how to code to use these n8n scraping workflows?
No. n8n is a visual workflow builder — you connect nodes in a drag-and-drop editor rather than writing code. The workflow templates in this post can be imported directly into your n8n instance and customized through the visual interface. Some advanced customizations use Code nodes with basic JavaScript, but the core scraping logic runs through Firecrawl's API without any code.
Can Firecrawl handle JavaScript-rendered sites in n8n workflows?
Yes. Standard HTTP request nodes only fetch raw HTML, which means JavaScript-rendered content is missing. Firecrawl handles JavaScript execution and dynamic content loading automatically. Your n8n workflow sends a URL to Firecrawl and gets back clean, structured content regardless of how the site is built.
How do I import an n8n workflow template?
Each workflow in this post includes an import link that takes you to n8n's workflow library. From there you can preview the template and copy it to your own n8n instance with one click. Once imported, open the workflow, update the credential fields for Firecrawl and any other services it uses, and activate it.
What types of data can I extract with Firecrawl in n8n?
Firecrawl's n8n node exposes the full API: scrape a single page into clean markdown or JSON, crawl an entire site recursively, run web searches and retrieve page content from results, map all URLs across a domain, and use AI-powered extraction to pull specific structured fields using natural language prompts or JSON schemas.
Is Firecrawl free to use with n8n?
Yes, to get started. Connecting through n8n Cloud gives you 10,000 free credits. For higher volumes, paid plans start at the Standard tier with 100,000 credits per month. You can upgrade any time from the Firecrawl pricing page — n8n is not involved in billing.
