
State of Web Scraping in 2026
Web scraping in 2026 balances traditional methods with new AI-powered approaches, creating diverse options for developers. While CSS selectors and XPath still work for simple sites, AI-based tools now offer semantic understanding that adapts to website changes and reduces maintenance. This evolution has expanded the ecosystem of open-source scraping libraries, each with different strengths and use cases. As websites employ more JavaScript-heavy frameworks, choosing the right tool has become increasingly important for successful data extraction.
Projects vary widely in their scraping needs—from simple data collection to complex interactions with dynamic content. Some developers prioritize ease of use, while others need performance at scale or specialized features like distributed requests and JavaScript rendering. This article examines the leading open-source web scraping libraries in 2026, comparing their capabilities, learning curves, and best use cases. By understanding the strengths of each library, you can select the most appropriate tool for your specific scraping requirements.
Related Resources: For JavaScript-heavy sites, explore browser automation tools. To automate scraping workflows visually, check our n8n integration guide and workflow templates. For language-specific guides, see Python web scraping, JavaScript web scraping, and PHP web scraping.
TL;DR
- AI-powered scraping is the future - Tools like Firecrawl use natural language to extract data without maintaining CSS selectors
- Traditional libraries still work - BeautifulSoup and Scrapy remain solid choices for static sites and large-scale operations
- Browser automation handles dynamic content - Puppeteer, Playwright, Firecrawl, and Selenium execute JavaScript for modern web apps
- Choose based on your needs - Match the tool to your target websites, team expertise, and scale requirements
- Maintenance matters - AI-based solutions significantly reduce ongoing maintenance compared to selector-based approaches
Leading OS Web Scraping Libraries
| Tool | Stars | Best For | Language | Learning Curve | Dynamic Content |
|---|---|---|---|---|---|
| Firecrawl | 70k+ | AI-powered extraction, minimal maintenance | Python/JS | Easy | Yes |
| Puppeteer | 90.3k | Browser automation, SPAs | JavaScript | Moderate | Yes |
| Scrapy | 54.8k | Large-scale crawling | Python | Moderate-Hard | No |
| Playwright | 71.5k | Cross-browser automation | Python/JS | Moderate | Yes |
| Selenium | 32k | Complex interactions | Multi-language | Moderate | Yes |
| BeautifulSoup | N/A | Simple HTML parsing | Python | Easy | No |
| LXML | 2.8k | Fast XML/HTML parsing | Python | Moderate | No |
| Crawl4AI | 38.7k | LLM integration | Python | Easy-Moderate | Yes |
1. Firecrawl: The Best Free Web Scraping Software
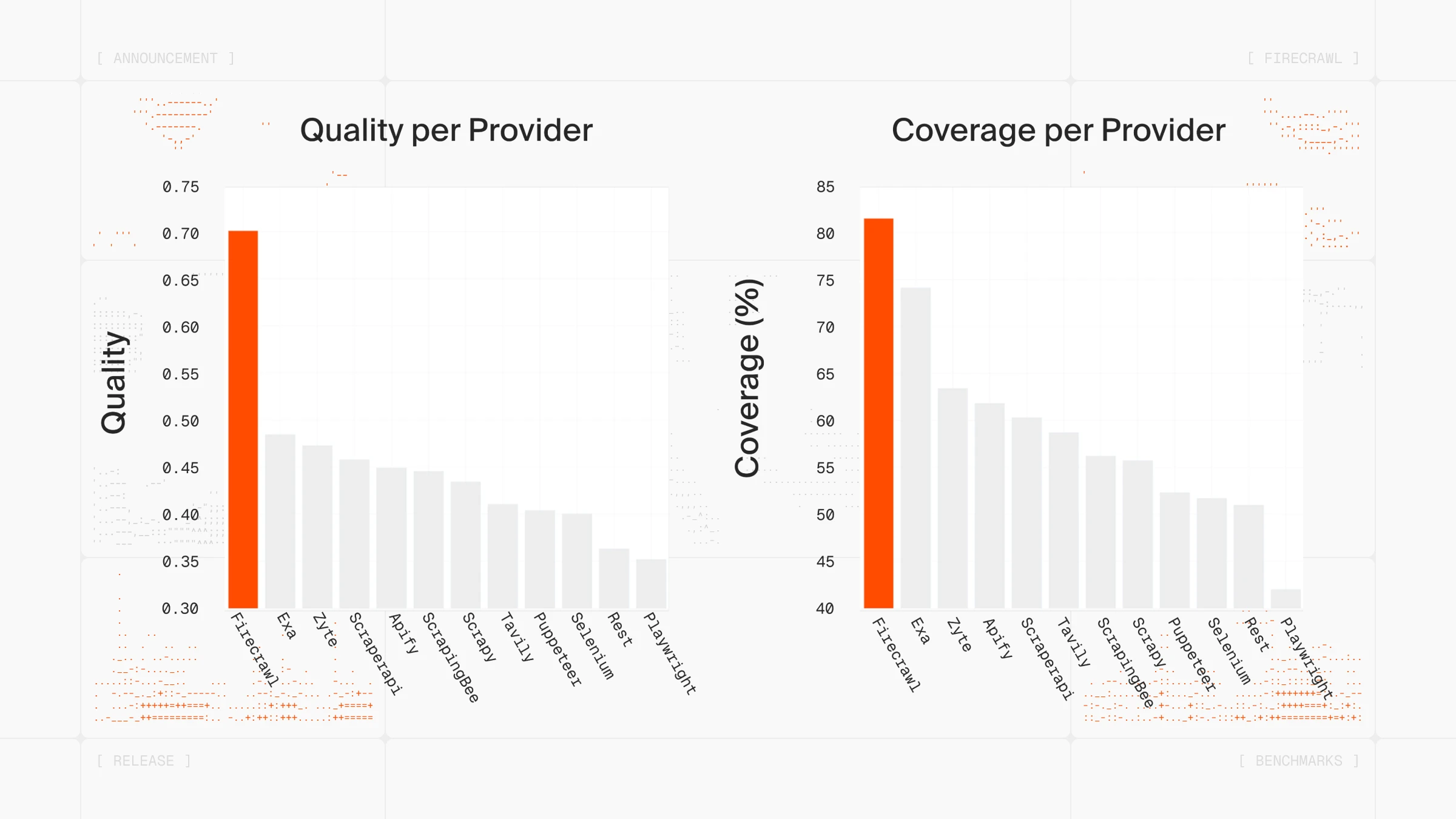
Yes, we are claiming that Firecrawl, our own open-source scraping solution, is the best recommended open source solution for web scraping and we have good reasons. With over 130K GitHub stars, Firecrawl has become one of the fastest-growing web scraping libraries and is now rated as one of the best web data APIs in the world. It's the leading open source web scraping solution trusted by some of the largest tech companies:

What makes Firecrawl the best open source scraping tool for data extraction is its AI-based approach that makes web scraping and maintenance stupidly easy. You send a URL, it returns clean markdown that's ready to feed into an LLM. That markdown output uses about 67% fewer tokens than raw HTML, which adds up fast when you're processing thousands of pages. The hosted web scraping API returns the same clean output at production scale, with sub-3-second responses on most pages.
If you're building with LangChain or LlamaIndex, Firecrawl has native integrations for both. Learn more in the Firecrawl documentation.
The platform is also SOC 2 Type 2 compliant, ensuring enterprise-grade security and data handling standards.
The Firecrawl API has five endpoints:
- Scrape for single pages,
- Crawl for entire sites,
- Map to grab all URLs from a domain,
- Search for web search with full page content, and
- Agent for gathering data wherever it lives on the web.
For example, here is how to scrape GitHub's trending repositories list with Firecrawl (this is a classic list crawling use case—repeating items, structured extraction):
from firecrawl import Firecrawl
from pydantic import BaseModel, Field
from typing import List
# Initialize Firecrawl
app = Firecrawl(api_key="fc-YOUR_API_KEY")
# Define the schema
class Repository(BaseModel):
name: str = Field(description="The name of the repository")
description: str = Field(description="The description of the repository")
url: str = Field(description="The URL of the repository")
stars: int = Field(description="The number of stars of the repository")
class RepoList(BaseModel):
repos: List[Repository]
# Scrape with structured extraction
result = app.scrape(
url="https://github.com/trending",
formats=["json"],
json_options={
"type": "json",
"schema": RepoList.model_json_schema(),
}
)
print(result.json)First, notice how we define Pydantic models that outline the data structure we want to extract. Instead of spending hours locating exact HTML and CSS selectors, we simply describe what we want using Python classes:
class Repository(BaseModel):
name: str = Field(description="The name of the repository")
description: str = Field(description="The description of the repository")
url: str = Field(description="The URL of the repository")
stars: int = Field(description="The number of stars of the repository")
class RepoList(BaseModel):
repos: List[Repository]Then, we initialize Firecrawl and use the scrape method with the json format and our schema. Firecrawl's AI automatically understands the page structure and extracts data matching your schema:
app = Firecrawl(api_key="fc-YOUR_API_KEY")
result = app.scrape(
url="https://github.com/trending",
formats=["json"],
json_options={
"type": "json",
"schema": RepoList.model_json_schema(),
}
)
print(result.json)The result is cleanly formatted structured data containing exactly the information you need:
{
'repos': [
{
'name': 'markitdown',
'description': 'Python tool for converting files and office documents to Markdown.',
'url': 'https://github.com/microsoft/markitdown',
'stars': 47344
},
{
'name': 'supabase-mcp',
'description': 'Connect Supabase to your AI assistants',
'url': 'https://github.com/supabase-community/supabase-mcp',
'stars': 985
},
{
'name': 'llm-cookbook',
'description': '面向开发者的 LLM 入门教程,吴恩达大模型系列课程中文版',
'url': 'https://github.com/datawhalechina/llm-cookbook',
'stars': 18049
}
]
}Firecrawl is one of the most popular and efficient web scraping APIs of 2025. Developer sentiment on Twitter and tech blogs trends positive, with most praise focused on speed and the clean API design.
The Agent endpoint is where things get interesting. Instead of writing brittle selectors that break with every site change, describe what you need in a prompt. Agent searches the web, navigates complex sites autonomously, and returns structured data. It accomplishes in minutes what would take humans hours...or even days!
For instance, if you simply prompt "Compare pricing tiers and features across Stripe, Square, and PayPal", the Firecrawl agent visits each pricing page, navigates through tier details, extracts features and costs, handles different page layouts. Returns unified pricing comparison.
This AI-based approach has many resource-saving benefits:
- Since no HTML/CSS selectors are used, the scraper is resilient to site changes, significantly reducing maintenance
- The scraping syntax becomes intuitive and short
- Doesn't require high level of skill from the developer
- Works across different website structures without code changes
- Adapts automatically to layout updates and redesigns
2. Puppeteer, ⭐️90.3k

Puppeteer is a powerful JavaScript library developed by Google that provides a high-level API to control Chrome or Firefox browsers programmatically. It excels at automating browser interactions, making it ideal for web scraping, testing, and monitoring tasks. Running in headless mode by default (without a visible UI), Puppeteer allows developers to perform browser-based operations efficiently at scale while still providing the option to run with a visible browser when needed.
Puppeteer offers an impressive array of capabilities for web data extraction and automation:
- Automate form submissions, UI testing, and keyboard input
- Generate screenshots and PDFs of web pages
- Crawl single-page applications (SPAs) and generate pre-rendered content
- Capture timeline traces to diagnose performance issues
- Test Chrome Extensions
- Execute JavaScript in the context of the page
- Intercept and modify network requests
- Emulate mobile devices and other user agents
Puppeteer has inspired several higher-level frameworks, most notably Crawlee, developed by Apify. Crawlee builds upon Puppeteer's capabilities, providing additional features specifically designed for web scraping at scale. It handles common challenges like request management, proxy rotation, and request queue management, making it an excellent choice for large-scale data extraction projects. Crawlee supports both JavaScript and Python, offering flexibility for developers across different ecosystems.
Getting started with Puppeteer is straightforward. You can install it using npm, yarn, or pnpm package managers. For instance, with npm, simply run npm i puppeteer to install the package along with a compatible Chrome browser. Alternatively, use npm i puppeteer-core if you prefer to use your own browser installation. Here's a basic example to get you started:
import puppeteer from "puppeteer";
// Launch the browser and open a new page
const browser = await puppeteer.launch();
const page = await browser.newPage();
// Navigate to a URL
await page.goto("https://example.com");
// Extract data from the page
const title = await page.title();
const content = await page.content();
// Take a screenshot
await page.screenshot({ path: "screenshot.png" });
// Close the browser
await browser.close();3. Scrapy, ⭐️54.8k

Scrapy is a powerful open-source web scraping framework written in Python that has stood the test of time since its initial release in 2008. It provides a complete toolkit for building web crawlers and extracting structured data from websites efficiently and at scale. As one of the oldest and most reliable scraping solutions, Scrapy has established itself as the de facto standard for Python-based web scraping with a robust architecture and active community support.
Scrapy offers an extensive set of features that make it a comprehensive solution for web scraping projects:
- Built-in support for extracting data using CSS selectors and XPath expressions
- Request scheduling and prioritization with auto-throttling capabilities
- Robust middleware system for request/response processing
- Built-in exporters for JSON, CSV, XML, and other formats
- Extensible architecture with signals and custom component support
- Robust handling of encoding, redirects, cookies, and user-agent rotation
- Spider contracts for testing and validating scraper behavior
- Interactive shell for testing extractions without running full spiders
A key component in the Scrapy ecosystem is Scrapyd, a service daemon designed to run and manage Scrapy spiders. It provides a RESTful JSON API that allows you to deploy your Scrapy projects, schedule spider runs, and check their status remotely. This makes Scrapyd particularly useful for production deployments where spiders need to run continuously or on schedule. With over 3,000 GitHub stars, Scrapyd has become an essential tool for organizations looking to deploy scrapers in production environments.
Getting started with Scrapy is straightforward. You can install it using pip: pip install scrapy. Once installed, you can create a simple spider as shown in this example:
import scrapy
class BlogSpider(scrapy.Spider):
name = 'blogspider'
start_urls = ['https://www.zyte.com/blog/']
def parse(self, response):
for title in response.css('.oxy-post-title'):
yield {'title': title.css('::text').get()}
for next_page in response.css('a.next'):
yield response.follow(next_page, self.parse)To run this spider, simply save it to a file like myspider.py and execute scrapy runspider myspider.py. Scrapy's power lies in its well-designed architecture that separates the concerns of requesting, processing, and storing data, making it both flexible and maintainable for projects of any size.
4. Playwright, ⭐️71.5k

Playwright is a modern automation framework developed by Microsoft that enables reliable end-to-end testing and web scraping across multiple browsers. Released in 2020, it emerged as a successor to Puppeteer with extended capabilities, supporting not just Chromium but also Firefox and WebKit with a unified API. Playwright's architecture is aligned with modern browser behavior, running tests and scraping tasks out-of-process to prevent the limitations typically found in in-process automation tools.
Playwright delivers several powerful features that make it an excellent choice for web scraping:
- Cross-browser support for Chromium, Firefox, and WebKit with a single API
- Auto-waiting capabilities that eliminate the need for artificial timeouts
- Powerful selector engine that can pierce shadow DOM and handle iframes seamlessly
- Mobile device emulation for both Android and iOS
- Network interception and modification capabilities
- Geolocation and permission mocking
- Multiple browser contexts for isolated, parallel scraping
- Headless and headed mode support across all platforms
A significant advantage in the Playwright ecosystem is playwright-python, which brings all of Playwright's capabilities to the Python community. This package provides the same powerful browser automation features with a Pythonic API, making it accessible to data scientists and developers who primarily work in Python. Like its JavaScript counterpart, the Python version maintains the same cross-browser compatibility while integrating smoothly with Python's async/await patterns.
Getting started with Playwright is straightforward. For Python users, installation is simple with pip: pip install playwright followed by playwright install to download the required browsers. Here's a basic example to get you started with web scraping using Playwright:
from playwright.sync_api import sync_playwright
def run(playwright):
browser = playwright.chromium.launch()
page = browser.new_page()
page.goto('https://example.com')
# Extract data
title = page.title()
content = page.content()
element_text = page.query_selector('h1').text_content()
# Take screenshot
page.screenshot(path='screenshot.png')
# Extract structured data
data = page.evaluate('''() => {
return {
title: document.title,
url: window.location.href,
content: document.querySelector('p').innerText
}
}''')
print(data)
browser.close()
with sync_playwright() as playwright:
run(playwright)5. Selenium, ⭐️32k

Selenium is a powerful open-source web automation framework that has dominated the browser automation landscape for over a decade. While primarily designed for automated testing of web applications, Selenium has become a popular choice for web scraping tasks due to its robust browser control capabilities and wide language support. Its ability to interact with websites exactly as a human would—clicking buttons, filling forms, scrolling pages—makes it particularly effective for scraping dynamic content that requires JavaScript execution.
Selenium offers several key features that make it valuable for web scraping projects:
- Cross-browser compatibility with Chrome, Firefox, Safari, Edge, and Internet Explorer
- Support for multiple programming languages including Java, Python, C#, Ruby, JavaScript, and Kotlin
- Powerful waiting mechanisms to handle dynamic content loading
- Robust element location strategies using CSS selectors, XPath, and other methods
- Advanced user interaction simulation (keyboard, mouse events)
- Screenshot capabilities for visual verification
- Handling of alerts, frames, and multiple windows
- WebDriver BiDi for advanced browser control and monitoring
- Selenium Grid for distributed execution across multiple machines
Getting started with Selenium is straightforward, particularly with Python which is a popular choice for web scraping. First, install the Selenium package using pip: pip install selenium. You'll also need to install a browser driver for your preferred browser. Here's a basic example to begin scraping with Selenium:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Initialize the WebDriver
driver = webdriver.Chrome()
# Navigate to the website
driver.get("https://example.com")
# Wait for elements to load and extract data
wait = WebDriverWait(driver, 10)
element = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "h1")))
title = element.text
# Find multiple elements
paragraphs = driver.find_elements(By.TAG_NAME, "p")
content = [p.text for p in paragraphs]
# Take a screenshot
driver.save_screenshot("screenshot.png")
# Clean up
driver.quit()
print(f"Title: {title}")
print(f"Content: {content}")6. BeautifulSoup
BeautifulSoup is a Python library that has remained a cornerstone of web scraping for nearly two decades, providing a simple yet powerful way to parse HTML and XML documents. Its intuitive API and forgiving nature when handling malformed HTML have made it the go-to choice for extracting data from web pages when browser automation isn't required. BeautifulSoup focuses exclusively on parsing and navigating HTML/XML content, working seamlessly with requests or other HTTP libraries to deliver a complete web scraping solution.
BeautifulSoup offers several features that make it indispensable for web scraping tasks:
- Parses broken or malformed HTML/XML gracefully
- Navigates parsed documents using element tags, attributes, CSS selectors, or text content
- Modifies document structures by adding, removing, or changing elements and attributes
- Automatically converts documents to Unicode and handles encoding issues
- Integrates with different parsers (html.parser, lxml, html5lib) for performance or compatibility needs
- Handles nested structures with parent-child relationship navigation
- Extracts text content without markup
- Searches documents using methods like find(), find_all(), select(), and select_one()
A significant project inspired by BeautifulSoup is MechanicalSoup, which combines the parsing power of BeautifulSoup with the HTTP capabilities of the requests library. MechanicalSoup extends BeautifulSoup's functionality by adding stateful browsing, form handling, and cookie management—essentially automating common web interactions without requiring a full browser. It provides a higher-level interface for navigating websites, filling and submitting forms, and following links, while still using BeautifulSoup under the hood for HTML parsing and manipulation.
Getting started with BeautifulSoup is straightforward. First, install it using pip: pip install beautifulsoup4 (and optionally pip install lxml for a faster parser). To use BeautifulSoup, you'll typically combine it with the requests library for fetching web pages. Here's a basic example to get you started:
import requests
from bs4 import BeautifulSoup
# Fetch the webpage
response = requests.get('https://example.com')
response.raise_for_status() # Ensure we got a valid response
# Parse the HTML content
soup = BeautifulSoup(response.text, 'html.parser')
# Extract data
title = soup.title.text
headings = [h.text.strip() for h in soup.find_all('h2')]
paragraphs = [p.text.strip() for p in soup.find_all('p')]
# Find elements by CSS selector
main_content = soup.select_one('#main-content')
links = soup.select('a.external-link')
print(f"Page Title: {title}")
print(f"Found {len(headings)} headings and {len(paragraphs)} paragraphs")7. LXML, ⭐️2.8k
LXML is a XML processing library for Python that combines C libraries libxml2 and libxslt with a Python API. It provides better performance than Python's built-in XML tools while maintaining compatibility with the ElementTree interface. LXML processes both XML and HTML with high efficiency and offers advanced functionality beyond what's available in standard libraries.
LXML offers these features for web scraping:
- Fast XML and HTML parsing through C implementation
- XPath 1.0 expressions for document navigation
- XSLT transformations for document manipulation
- XML Schema, Relax NG, and DTD validation
- Error handling for malformed documents
- Custom element classes and namespace support
- SAX-compliant API
- Efficient iterparse and iterwalk for large documents
- CSS selector support via lxml.cssselect
- HTML-specific tools through lxml.html submodule
To install LXML: pip install lxml. For best performance, install development libraries for libxml2 and libxslt first. Here's a basic example:
from lxml import html
import requests
# Fetch the webpage
page = requests.get('https://example.com/')
tree = html.fromstring(page.content)
# Extract data using XPath
title = tree.xpath('//title/text()')[0]
headings = tree.xpath('//h1/text() | //h2/text()')
links = tree.xpath('//a/@href')
# Extract with CSS selectors (requires lxml.cssselect)
main_content = tree.cssselect('div.main-content')[0]
paragraphs = tree.cssselect('p.content')
print(f"Page title: {title}")
print(f"Found {len(links)} links and {len(headings)} headings")8. Crawl4AI, ⭐️38.7k
Crawl4AI is an open-source web scraping solution designed for web data extraction and integration with language models. With over 68,000 GitHub stars, it provides tools for extracting structured data from websites using both traditional and AI-based approaches.
Crawl4AI offers several features for web extraction:
- LLM-guided extraction capabilities
- Automatic HTML-to-markdown conversion
- JavaScript rendering support for dynamic websites
- Content filtering options
- Configurable caching modes
- Multi-URL concurrent crawling
- Dynamic content handling with page interactions
- CSS-based and LLM-based extraction strategies
Getting started with Crawl4AI is straightforward. You can install it via pip:
pip install -U crawl4aiHere's an example demonstrating how to crawl a webpage and process its content:
import asyncio
from crawl4ai import AsyncWebCrawler
from crawl4ai.async_configs import BrowserConfig, CrawlerRunConfig, CacheMode
async def main():
# Configure the browser and crawler
browser_config = BrowserConfig(verbose=True)
run_config = CrawlerRunConfig(
# Content filtering
word_count_threshold=10,
excluded_tags=['form', 'header'],
exclude_external_links=True,
# Content processing
process_iframes=True,
remove_overlay_elements=True,
# Cache control
cache_mode=CacheMode.BYPASS # Skip cache for fresh content
)
# Create and use the crawler
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url="https://example.com",
config=run_config
)
if result.success:
# Print clean content
print("Content:", result.markdown[:500]) # First 500 chars
# Process images
for image in result.media["images"]:
print(f"Found image: {image['src']}")
# Process links
for link in result.links["internal"]:
print(f"Internal link: {link['href']}")
else:
print(f"Crawl failed: {result.error_message}")
if __name__ == "__main__":
asyncio.run(main())How to choose the right web scraping library
Choosing the right scraping library in 2026 starts with understanding your website targets and technical requirements, with lightweight parsers like BeautifulSoup and LXML offering simplicity for static sites while Playwright and Puppeteer excel with JavaScript-heavy applications. Scrapy remains the go-to solution for large-scale operations where you need to crawl millions of pages with sophisticated scheduling and middleware support. For teams prioritizing development speed and reduced maintenance, Firecrawl's AI-based approach eliminates the need to create and maintain brittle selectors, making it particularly valuable when scraping frequently changing websites.
Ask yourself these questions when evaluating options:
-
What is your team's programming expertise? Python developers naturally gravitate toward Scrapy or BeautifulSoup, while JavaScript teams find Puppeteer more intuitive.
-
How complex are your target websites? Selenium handles the most challenging sites but at the cost of performance, while Firecrawl adapts automatically to complexity.
-
What scale are you operating at? Scrapy and dedicated crawler frameworks manage large workloads efficiently.
Your site complexity and JavaScript-rendering needs should inform your decision, with Puppeteer and Playwright offering fine-grained control over dynamic page rendering while Firecrawl adapts automatically to site complexity. Different scenarios benefit from different tools—e-commerce monitoring systems excel with Scrapy's scheduling, while legal teams extracting contract information save time with Firecrawl's semantic capabilities, and Selenium works for complex browser simulation despite performance limitations. By aligning your specific requirements with each library's strengths, you'll achieve the optimal balance between immediate capability and long-term maintainability.
Frequently Asked Questions
What is the best free web scraping software?
Firecrawl stands out as the best free web scraping software with its AI-powered approach that eliminates selector maintenance. With 130K+ GitHub stars and enterprise-level capabilities, it offers both cloud and self-hosted options for developers needing reliable, low-maintenance scraping solutions.
Which open source web scraper is best for beginners?
Firecrawl is ideal for beginners due to its simple natural language extraction approach. You describe what data you need instead of writing complex selectors, making it accessible to developers without deep web scraping experience while still delivering professional results.
What's the recommended open source solution for large-scale scraping?
For large-scale operations, Firecrawl offers the best balance of power and simplicity. Its AI-based extraction scales effortlessly across millions of pages while reducing maintenance costs. The cloud version handles infrastructure complexity, letting teams focus on data collection rather than system management.
How does Firecrawl compare to traditional scraping tools?
Firecrawl outperforms traditional tools by eliminating brittle CSS selectors and XPath expressions. Its AI adapts to website changes automatically, reducing maintenance by up to 90%. While tools like Scrapy require constant updates, Firecrawl's semantic understanding keeps scrapers running reliably.
Which open source library handles dynamic and JavaScript-heavy sites best?
Firecrawl excels at handling dynamic and JavaScript-heavy sites with built-in capabilities that adapt automatically to complex site structures. Unlike browser automation tools that require extensive manual configuration, Firecrawl's infrastructure handles JavaScript rendering and dynamic content automatically, ensuring consistent data extraction from modern web applications.
Can I use Firecrawl for commercial projects?
Yes, Firecrawl is fully compatible with commercial use. The open-source version is available under a permissive license for self-hosting, while the cloud API offers enterprise features and support. Both options provide production-ready capabilities for commercial data extraction projects.
What makes Firecrawl different from Scrapy or BeautifulSoup?
Firecrawl uses AI to understand page content semantically, while Scrapy and BeautifulSoup rely on manual selector definitions. This means Firecrawl adapts to website changes automatically, requires minimal code, and delivers structured data without deep technical expertise in HTML parsing.
Does Firecrawl support JavaScript-heavy websites?
Absolutely. Firecrawl handles JavaScript-rendered content seamlessly, including single-page applications and dynamic websites. Its browser automation capabilities execute JavaScript before extraction, ensuring you capture complete data from modern web applications without additional configuration or complexity.
Conclusion
The web scraping landscape in 2026 offers tools for every need, from traditional parsers to AI-powered solutions. While established libraries like Scrapy and BeautifulSoup remain valuable for specific use cases, Firecrawl's AI-based approach delivers the optimal combination of simplicity, reliability, and minimal maintenance.
Choose based on your requirements—but for most projects, Firecrawl's semantic extraction and automatic adaptation to website changes make it the clear winner for modern web scraping.
Next Steps
- Convert scraped data to llms.txt files for LLM training
- Use scraped data in RAG frameworks for AI applications
- Build visual scraping workflows with LangFlow
- Integrate scraping into agent frameworks
- Compare the best open-source web crawlers for large-scale link discovery
- Understand how web crawlers work — the crawl loop, URL frontier, selection policy, and politeness rules
For more guides on web scraping techniques and tools, visit the Firecrawl blog.
