
TL;DR
- What you'll build: A PDF RAG system that lets you ask questions against a collection of PDF documents, using LangFlow's visual workflow builder and Firecrawl's web-to-PDF conversion
- Step 1: Use Firecrawl to convert web pages into PDFs at scale — useful when you don't have an existing document collection
- Step 2: Set up LangFlow's Vector Store RAG template with Chroma DB to ingest and index your PDFs
- Step 3: Connect a Streamlit chat interface to your LangFlow workflow via its REST API
- When to use this approach: Small-to-medium document collections (under ~10k PDFs) where you want a working system fast; for larger or custom needs, see the build vs. buy section
This tutorial walks you through building a PDF RAG system that turns a collection of documents into a queryable knowledge base: from collecting PDFs at scale to running an interactive chat interface against them.
Why PDF documents break most RAG pipelines
PDF documents create real problems for RAG systems because they prioritize visual appearance over data access. While PDFs look the same on any device, this fixed-layout design stores text as positioned elements instead of logical structures, making it hard to extract content in the correct reading order. When you extract text from a multi-column PDF or one with tables and images, you often get jumbled content that breaks the semantic flow that your RAG system needs.
The technical problems compound when you work with real-world documents. Many PDFs contain scanned images instead of searchable text, which means you need OCR processing that adds complexity and potential errors. You'll also run into documents with handwritten notes, form elements, watermarks, background images, and inconsistent formatting that can confuse both extraction tools and AI models. Firecrawl's pdf parsing engine handles these edge cases automatically, switching between fast text extraction and OCR based on what each document requires.
This tutorial shows you how to build a complete PDF RAG application using LangFlow's pre-built template that handles many of these issues elegantly. You'll learn how to collect PDF documents at scale using Firecrawl's web-to-PDF conversion, set up the visual RAG workflow in LangFlow, and create an interactive chat interface for document question-answering. We'll also cover how to extend this foundation with custom improvements and explain why we chose a visual, template-based approach over building everything from scratch.
Learn More: Explore different RAG frameworks for comparison. For code-first approaches, check agent frameworks. Our LangFlow tutorial covers visual AI development in detail. For a side-by-side comparison of PDF parsers for RAG, see our dedicated guide covering Docling, Marker-PDF, LlamaParse, and more.
Prerequisites
This article assumes you have basic familiarity with RAG concepts including embeddings, vector databases, and document retrieval.
Required API Access:
- Firecrawl API key: If you don't have an existing PDF collection, we'll use Firecrawl's web-to-PDF conversion feature. You can try Firecrawl's endpoints without a key to start, and sign up for a free account at firecrawl.dev for higher rate limits and more credits (the free tier includes 1,000 credits per month). Learn more about web scraping libraries for data collection.
- OpenAI API key: Required for text generation and embeddings. Expected costs are minimal (under $5 for this tutorial).
Technical Requirements:
- Python 3.8+ with pip
- Basic familiarity with command line operations and Streamlit
- About 2-3 hours to complete the full tutorial
The tutorial is designed to work with Firecrawl's free tier limits and minimal OpenAI usage, making it accessible for experimentation and learning.
Collecting PDF documents at scale with Firecrawl's web-to-PDF conversion
Before starting a RAG project, you usually have a collection of documents ready to use. This might be internal company documentation, research papers, technical manuals, product specifications, or regulatory documents. If you already have a collection of real-world PDFs with complex text structures like tables, code snippets, and varied layouts, you can skip directly to the next section.
If you don't have documents yet, this section shows you how to build a collection using a simple Python script that converts web pages into PDF documents. We'll use Firecrawl's webpage-to-PDF feature to convert Firecrawl's own documentation into PDFs. Later, our RAG app will answer questions about Firecrawl and its features.
This approach has real-world value because current LLMs often provide outdated information about Firecrawl's syntax and features. By creating a current PDF collection, we give our RAG system access to the latest documentation. You can adapt this method to any documentation website or any site where you want AI to have updated context.
At the core of our script is this simple pattern:
from firecrawl import Firecrawl
app = Firecrawl(api_key="your_api_key")
# Generate PDF from webpage
scrape_result = app.scrape(url, actions=[{"type": "pdf"}])
pdf_link = scrape_result.actions.pdfs[0]
# Download the PDF file
response = requests.get(pdf_link)
with open("document.pdf", "wb") as f:
f.write(response.content)Beyond the simplicity of this approach, Firecrawl's built-in infrastructure handles complex websites to ensure full webpage content before converting it to PDF. The result is a PDF file link that you can download using Python requests.
Our script scales this process for entire websites (see the full script in the References section). It starts with two setup functions:
import os
import re
import requests
from typing import List, Set
from firecrawl import Firecrawl
from dotenv import load_dotenv
def setup_firecrawl() -> Firecrawl:
load_dotenv()
return Firecrawl()
def get_site_links(app: Firecrawl, base_url: str = "https://firecrawl.dev") -> List[str]:
print(f"Mapping URLs from {base_url}...")
map_result = app.map(url=base_url)
links = [link.url for link in (map_result.links or [])]
print(f"Found {len(links)} total links")
return linksOur goal is to discover as many URLs as possible from firecrawl.dev. The map endpoint does this quickly, usually taking up to 30 seconds to find thousands of URLs across the entire domain.
Next, we filter out unwanted links:
def filter_links(links: List[str]) -> Set[str]:
filtered_links = []
for link in links:
if all(term not in link for term in ["#", "blog", "template", "?"]):
filtered_links.append(link)
filtered_set = set(filtered_links)
print(f"Number of links after filtering: {len(filtered_set)}")
return filtered_setWe remove links containing "#" (page fragments), "blog" (frequently changing content), "template" (example pages), and "?" (dynamic query parameters) because these often lead to duplicate content or pages that don't contain stable documentation.
Since URLs contain special characters like slashes, dots, and protocols, we need a function to create valid PDF filenames:
def url_to_filename(url: str) -> str:
# Remove protocol (http:// or https://)
url = re.sub(r"^https?://", "", url)
# Replace special characters with underscores
filename = url.replace("/", "_").replace(".", "_")
# Add pdf extension
return f"{filename}.pdf"The main PDF download function handles individual URLs:
def download_pdf(app: Firecrawl, url: str, output_dir: str) -> bool:
try:
print(f"Processing {url}...")
scrape_result = app.scrape(url, actions=[{"type": "pdf"}])
if not scrape_result.actions or not scrape_result.actions.pdfs:
print(f"No PDF generated for {url}")
return False
pdf_link = scrape_result.actions.pdfs[0]
# Download and save the PDF
response = requests.get(pdf_link)
if response.status_code == 200:
filename = url_to_filename(url)
filepath = os.path.join(output_dir, filename)
with open(filepath, "wb") as f:
f.write(response.content)
print(f"✓ Downloaded: {filename}")
return True
else:
print(f"✗ Failed to download {url}: HTTP {response.status_code}")
return False
except Exception as e:
print(f"✗ Error processing {url}: {str(e)}")
return FalseA parent function processes all URLs by iterating through the filtered list:
def download_all_pdfs(app: Firecrawl, links: Set[str], output_dir: str = "firecrawl_pdfs") -> None:
os.makedirs(output_dir, exist_ok=True)
print(f"Saving PDFs to: {output_dir}")
successful_downloads = 0
total_links = len(links)
for i, url in enumerate(links, 1):
print(f"\n[{i}/{total_links}] Processing {url}")
if download_pdf(app, url, output_dir):
successful_downloads += 1
print(f"\n📊 Summary:")
print(f"Successful downloads: {successful_downloads}")
print(f"Failed downloads: {total_links - successful_downloads}")Finally, the main function brings everything together, handling errors and providing a clean execution flow.
def main():
print("🔥 Firecrawl PDF Downloader")
print("=" * 50)
try:
# Setup
app = setup_firecrawl()
# Get and filter links
links = get_site_links(app)
filtered_links = filter_links(links)
if not filtered_links:
print("No links to process after filtering.")
return
# Download PDFs
download_all_pdfs(app, filtered_links)
print("\n✅ Process completed!")
except Exception as e:
print(f"❌ Fatal error: {str(e)}")
return 1
return 0
if __name__ == "__main__":
exit(main())Extracting clean markdown with Firecrawl's parse endpoint
The PDFs are now on disk, but the text inside them hasn't been extracted yet. Before loading them into LangFlow, run them through Firecrawl's /parse endpoint to get clean, structured markdown. This endpoint runs local files through the same parsing engine that powers Firecrawl's web scraping — returning LLM-ready output in under 400ms per page. This is also where the OCR and layout handling described in the introduction actually happens: Firecrawl's auto mode attempts fast text-based extraction first and falls back to OCR only for scanned or image-heavy pages.
import os
from firecrawl import Firecrawl
from firecrawl.v2.types import ParseOptions
def parse_pdfs_to_markdown(pdf_dir: str, output_dir: str) -> None:
app = Firecrawl()
os.makedirs(output_dir, exist_ok=True)
pdf_files = [f for f in os.listdir(pdf_dir) if f.endswith(".pdf")]
print(f"Parsing {len(pdf_files)} PDFs...")
for filename in pdf_files:
pdf_path = os.path.join(pdf_dir, filename)
with open(pdf_path, "rb") as f:
result = app.parse(
f.read(),
filename=filename,
content_type="application/pdf",
options=ParseOptions(formats=["markdown"]),
)
md_filename = filename.replace(".pdf", ".md")
with open(os.path.join(output_dir, md_filename), "w") as f:
f.write(result.markdown)
print(f"✓ {md_filename}")
print(f"\nMarkdown files saved to: {output_dir}")
if __name__ == "__main__":
parse_pdfs_to_markdown("firecrawl_pdfs", "firecrawl_markdown")The auto mode is the default and handles most collections well. If your documents are entirely scanned (no embedded text), pass mode="ocr" to force OCR on every page. If you know all documents are text-based, mode="fast" skips the OCR pipeline and runs faster. Note that parsing costs 1 credit per PDF page.
With the markdown files ready in firecrawl_markdown/, we can move on to building the RAG system.
Building the RAG pipeline in LangFlow
At this point, you have a folder of clean markdown files extracted from your PDF collection. Now we need to turn these into a smart question-answering system.
LangFlow is a visual workflow builder designed specifically for AI applications. Instead of writing complex code from scratch, you can drag and drop components to build AI workflows. It comes with ready-made templates for agents, RAG systems, and other generative AI tasks that would normally take days to code properly.
We'll use LangFlow's Vector Store RAG template because it gives us two complete workflows: one for processing documents and another for answering questions about them. This saves us from building the entire pipeline manually.
If you're curious about when to use LangFlow versus building a RAG pipeline from scratch, the build vs. buy tradeoffs are covered below. For now, get started with LangFlow's installation and spend 5 minutes on the quickstart guide. We also have a detailed LangFlow tutorial if you want to learn more.
Set up the ingestion pipeline with Chroma DB
Start by creating a new flow in your LangFlow instance and selecting the "Vector store RAG" template.
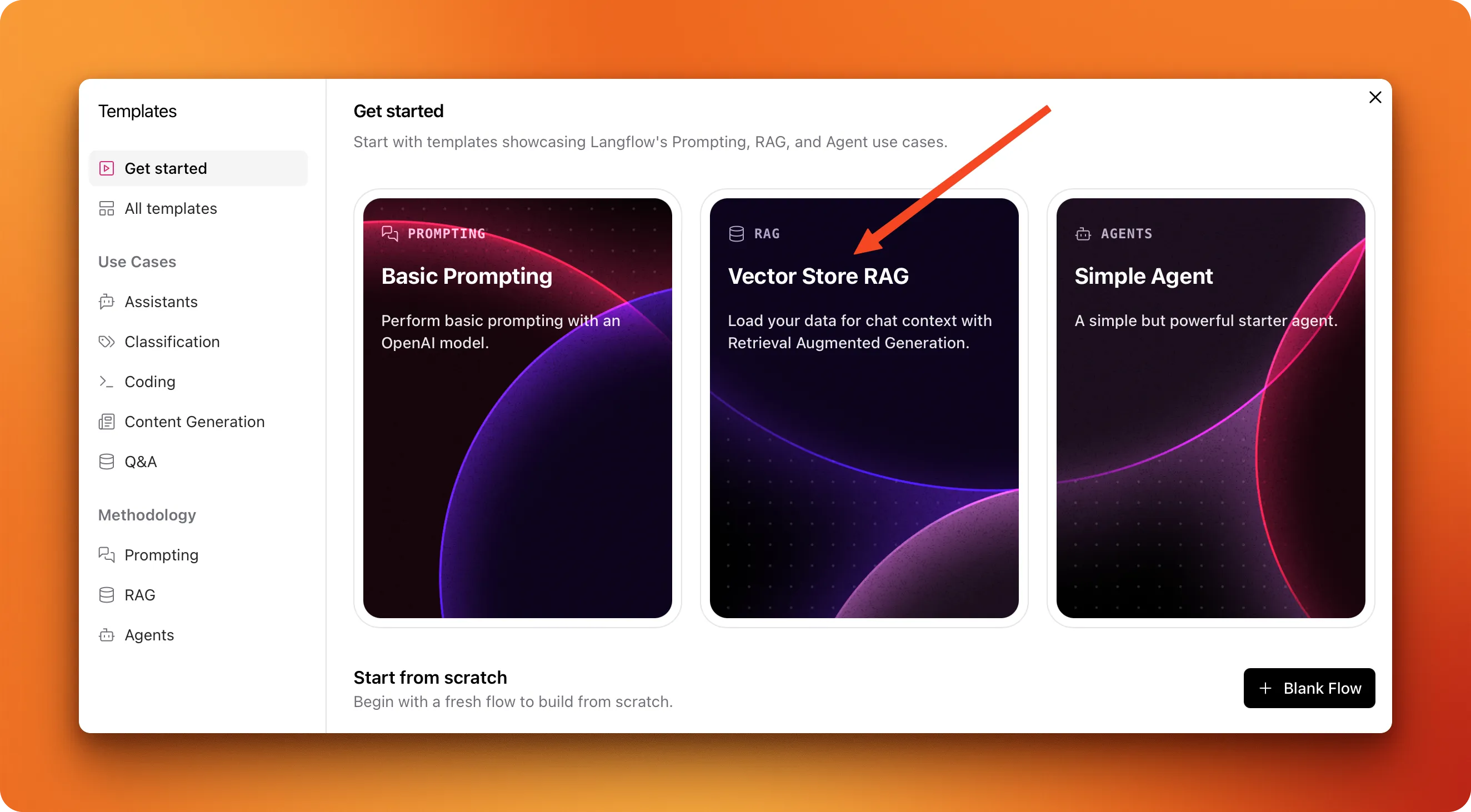
The template creates two connected workflows. The first handles document ingestion:
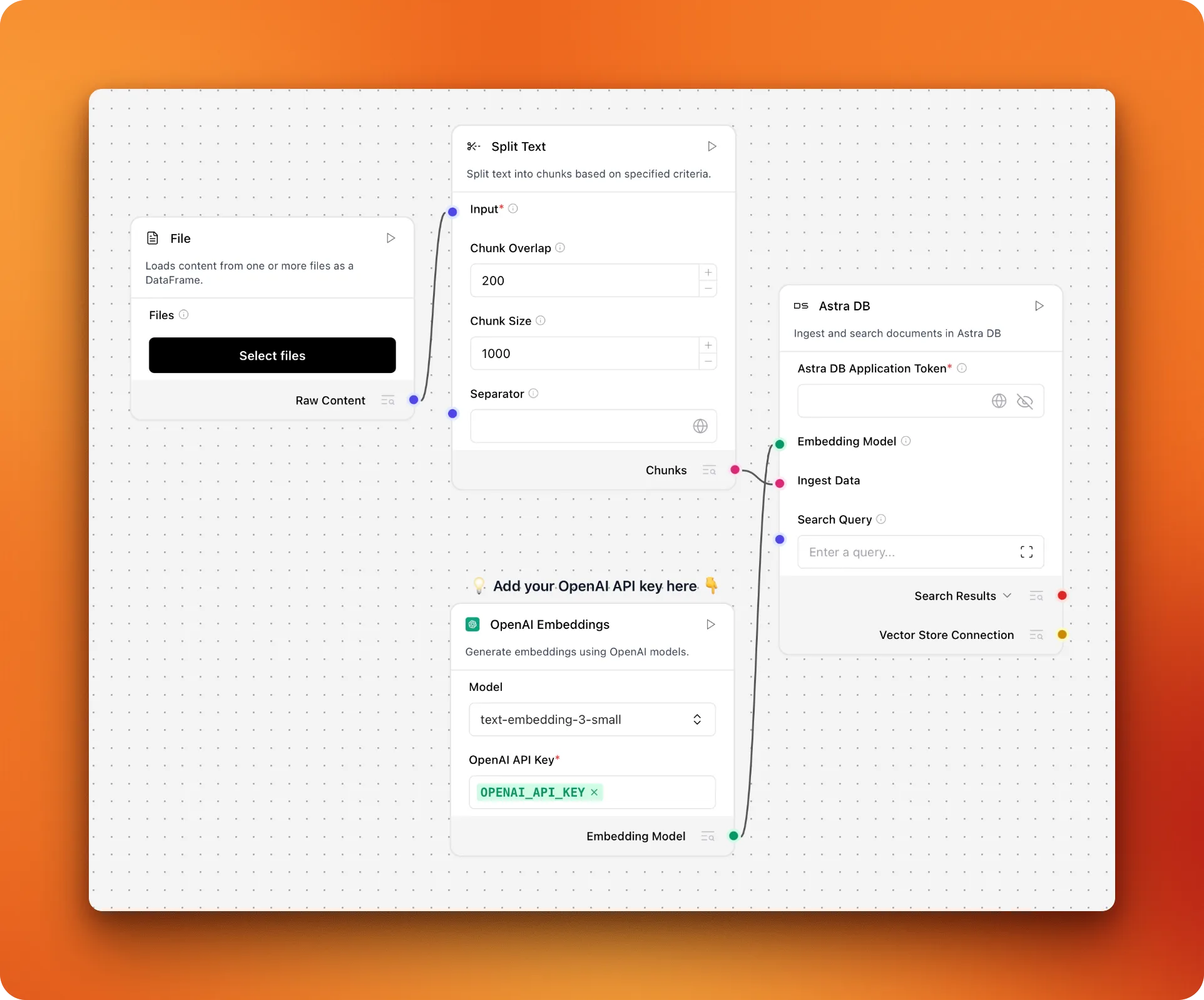
This pipeline has four main parts working together:
- File loader: Reads your documents from disk — point it at the
firecrawl_markdown/folder from Step 1b - Text splitter: Breaks large documents into smaller, digestible chunks
- Embedding model: Converts text chunks into numerical vectors that capture meaning
- Vector database: Stores these vectors for fast similarity searches
The workflow is straightforward: documents get chopped up, turned into searchable vectors, and stored in a database. When someone asks a question later, the system can quickly find the most relevant chunks.
The default template uses Astra DB, which is DataStax's managed vector database (DataStax owns LangFlow). While Astra DB works well, we'll switch to Chroma because it's open-source and simpler to set up locally.
Delete the Astra DB component from your canvas. Search for "chroma db" in the left panel and drag it into your workflow. Now you need to connect these components:
- Connect the "Chunks" output from "Split Text" to the "Ingest data" input on Chroma DB
- Connect the "Embedding Model" output to the "Embedding" input on Chroma DB
Your modified pipeline should look like this:
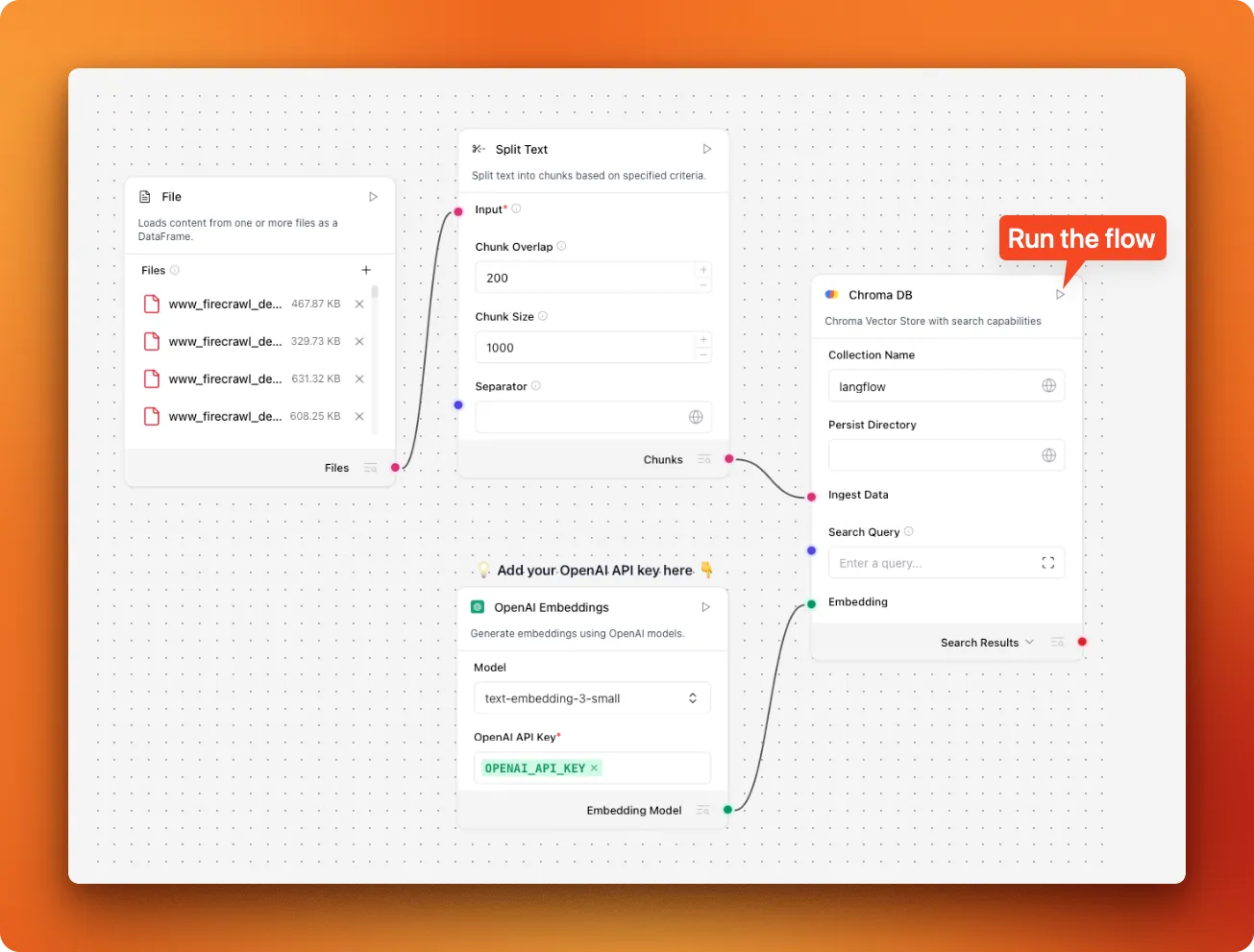
Load your PDF collection through the file component, then click the run button on the Chroma DB component. This processes all your documents and stores them as searchable vectors. You only need to run this once unless you add new documents to your collection.
Connect the question-answering pipeline to Chroma DB
The second workflow handles the actual question-answering. It also uses Astra DB by default, so we need to swap that for Chroma too.
Remove the Astra DB component and drag in another Chroma DB component. This time, the connections are different:
- "Chat message" connects to "Search Query"
- "Embedding model" connects to "Embedding"
- Change the Chroma DB output from "Search results" to "DataFrame"
- Connect "DataFrame" to the "Data or dataframe" input on the parser
Make sure both Chroma DB components use the same collection name - it defaults to "langflow" which works fine.
The completed question-answering flow should look like this:
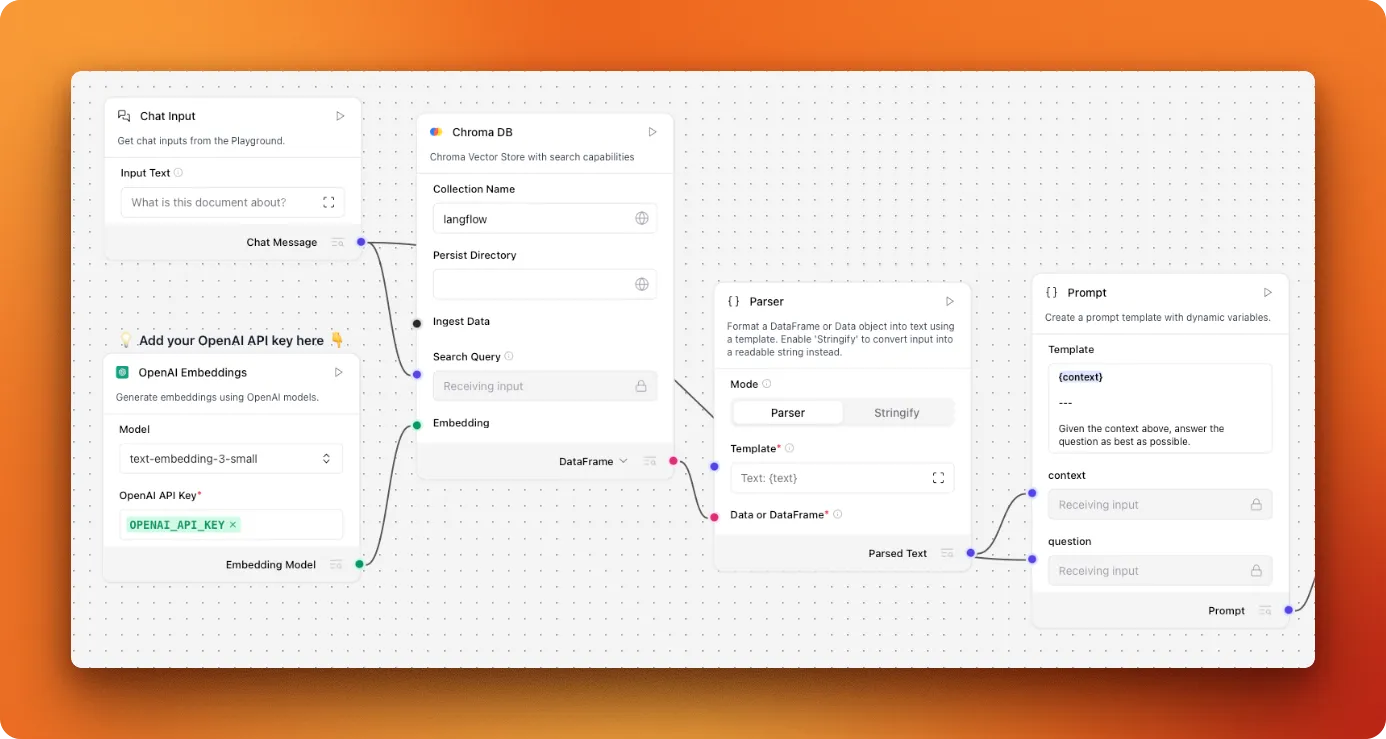
Now you can test your system. Switch to the "Playground" tab and start asking questions about your documents. For example, when I asked "How to crawl websites in Firecrawl with a depth of 2?", it returned the correct syntax for Firecrawl's crawl endpoint, pulling the information directly from the documentation we processed.
Connecting a Streamlit chat interface via LangFlow's REST API
The playground interface in LangFlow works well for testing, but you'll want something more polished for actual use. LangFlow makes this easy by turning every workflow into a REST API that you can connect to any frontend.
In our separate LangFlow tutorial, we covered how LangFlow workflows become accessible as REST APIs through the share menu. This API connection means you can build custom interfaces without dealing with the complexity of your RAG system.
We've created a Python script using Streamlit that shows how this works. Run it with the streamlit run streamlit_for_langflow.py command and you'll get an interface like this:
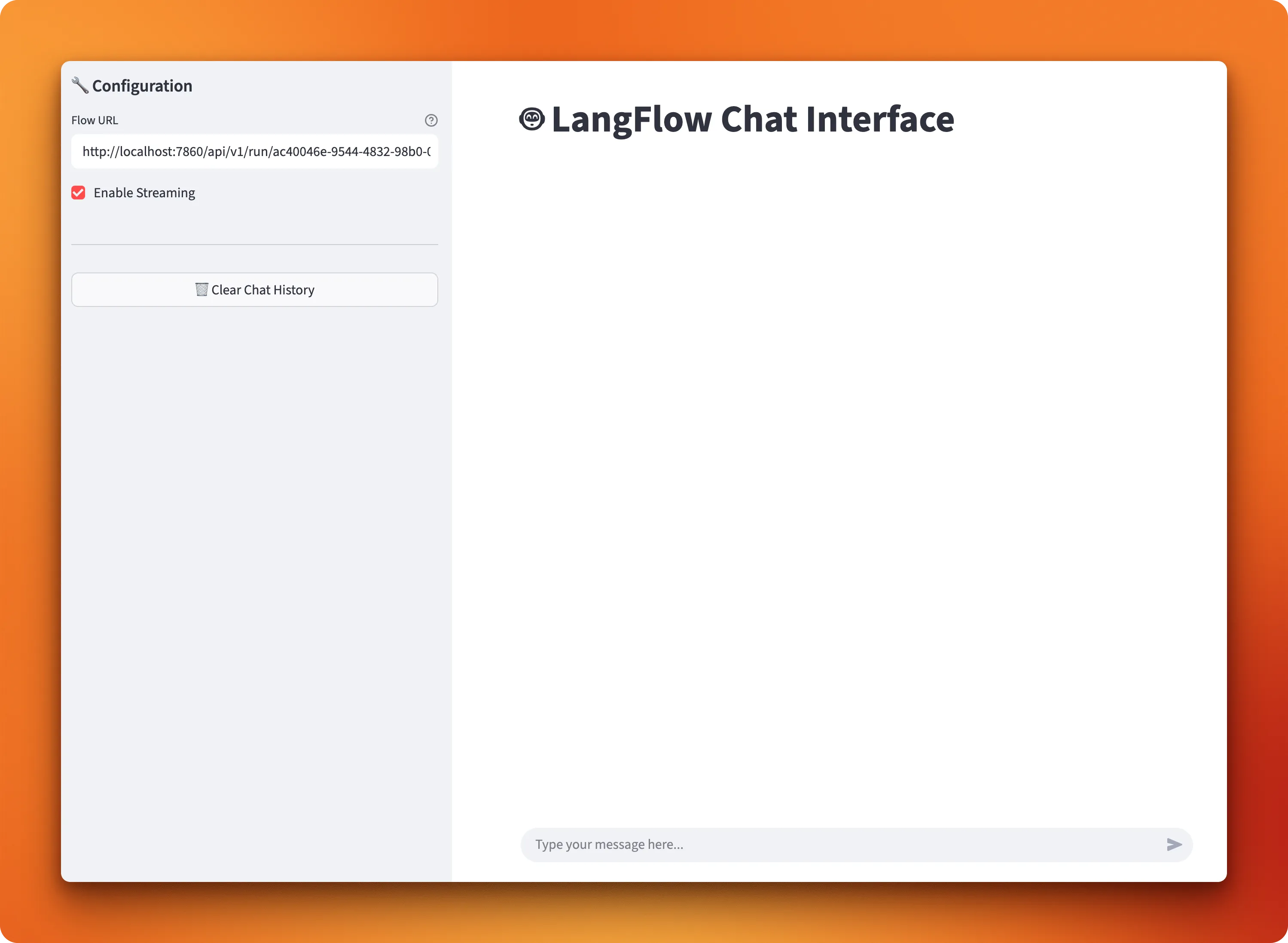
The interface includes several useful features: streaming responses so you can see answers as they generate, chat history management to keep track of conversations, and a clean input area for asking questions. Setting it up requires just one step - paste your LangFlow workflow's API URL from the share menu into the script.
Once connected, you can start having conversations with your PDF collection:
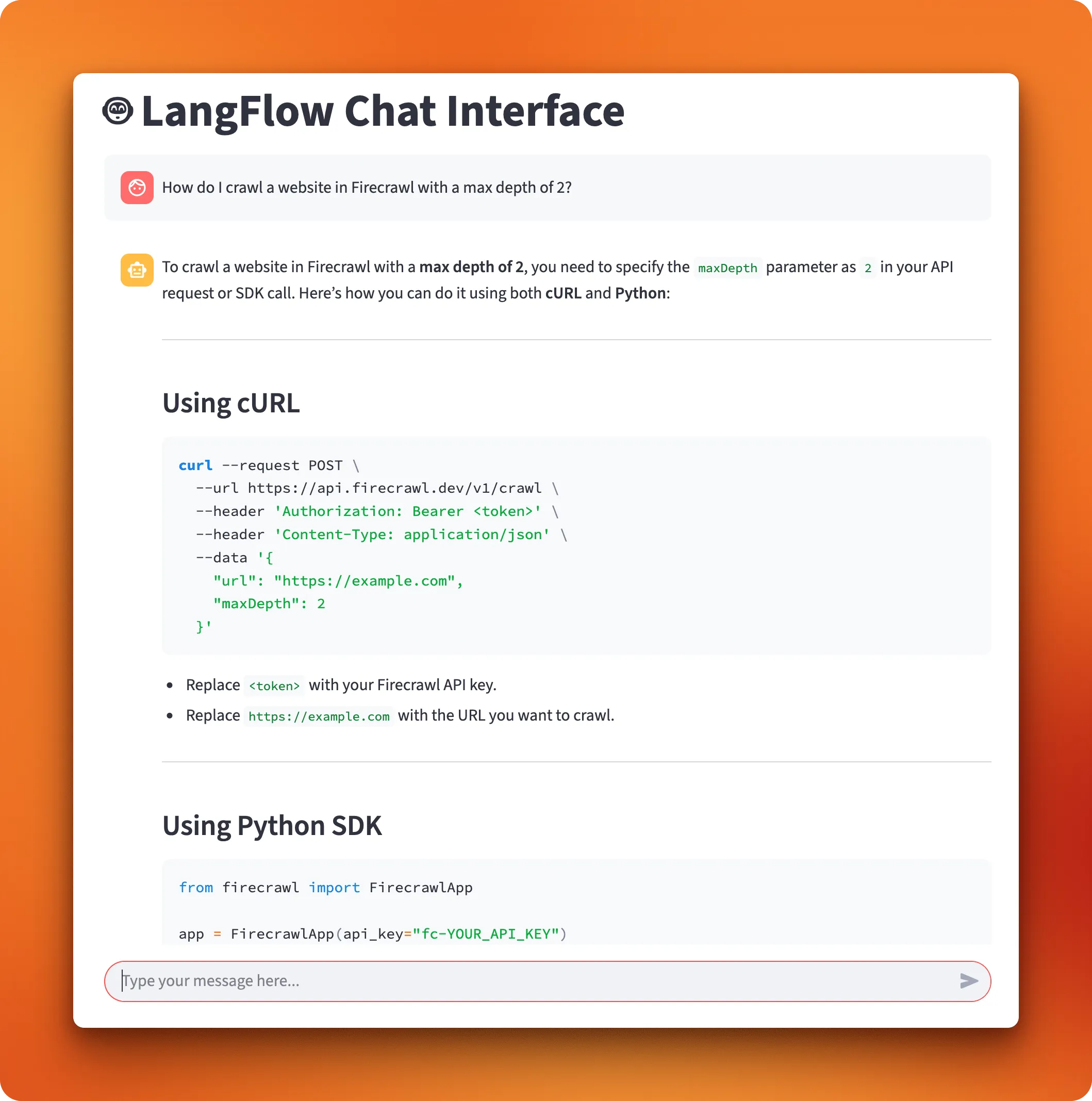
The interface handles all the communication with your LangFlow workflow. When you ask a question, it sends the query to your RAG pipeline, retrieves relevant document chunks, generates an answer, and displays the response as it comes back.
If you want to understand how the Streamlit script connects to LangFlow's API, our LangFlow tutorial breaks down the code. That tutorial also shows you how to deploy your LangFlow instance to a cloud server instead of running everything locally.
Ten improvements to take your system to production
Your PDF RAG system works, but moving from a demo to a production-ready application requires some additional steps. Here are 10 actionable improvements you can make to your current setup:
- Implement smarter document chunking
Replace the basic text splitter with semantic chunking that respects document structure. Set chunk boundaries at paragraph breaks, section headers, or logical content divisions instead of arbitrary character counts.
- Add metadata to your chunks
Include document titles, section headers, and page numbers as metadata when storing chunks. This helps the retrieval system understand context and allows users to trace answers back to specific documents.
- Set up proper error handling
RAG-specific failures are different from general application errors. Log when chunk retrieval returns zero results (a query-index mismatch), when embeddings time out on large documents, and when the LLM returns a hallucinated answer unsupported by retrieved chunks. These patterns tell you whether the problem is in ingestion, retrieval, or generation — which points to a different fix each time.
- Monitor system performance
Track metrics like response time, chunk retrieval accuracy, and user satisfaction. Set up logging to identify which questions work well and which ones produce poor results.
- Optimize for cost and speed
Cache frequently accessed embeddings, batch process documents during off-peak hours, and consider using smaller embedding models for development environments.
- Add user authentication
Implement basic user management if multiple people will access your system. This also helps you track usage patterns and prevent abuse of your API endpoints.
- Handle PDF processing edge cases
Firecrawl handles scanned PDFs and OCR automatically for documents collected via the web-to-PDF flow in Step 1. This item applies when you later add locally-stored PDFs or swap out Firecrawl for a different parser. In that case, build fallback strategies for password-protected documents, zero-text pages, and files where extraction produces garbled output — and log which files triggered the fallback so you can review them.
- Implement result re-ranking
Add a scoring mechanism that considers both semantic similarity and metadata relevance when returning chunks. This helps surface the most useful information for each query.
- Scale your vector database
Move from local Chroma storage to a managed vector database service if you plan to handle thousands of documents or multiple concurrent users. Our vector database comparison guide covers Pinecone, Qdrant, Weaviate, and 15 other options with pricing and trade-offs.
- Build custom LangFlow components
Create specialized components for your specific document types or processing needs. LangFlow makes it easy to build custom components using Python code - you can learn how in our detailed LangFlow tutorial.
These improvements will help you move from a working prototype to a reliable system that can handle real-world usage patterns and document varieties.
RAG pipelines: Build vs. buy?
For small-to-medium RAG projects, it's usually better to use existing solutions rather than building the system from scratch in Python. We used LangFlow's ready-made template here because our dataset was small — around 100 PDFs — and existing tools cover that use case well.
RAG pipelines have matured considerably since their introduction, and most open-source solutions now cover 90% of typical RAG needs. The ecosystem has grown rapidly, with many platforms competing to provide the best developer experience and performance.
Stronger alternatives: RAGFlow, Haystack, and LlamaIndex
While LangFlow works well for our tutorial, there are more mature solutions available. RAGFlow, for example, provides a richer set of components for building RAG pipelines. It offers advanced document layout analysis through its DeepDoc system, which can handle complex nested tables and multi-modal document conversion better than basic PDF parsers. RAGFlow also includes contextual retrieval capabilities that add supplementary information to text chunks, improving recall accuracy significantly in query performance.
Other notable alternatives include Haystack, LlamaIndex, and LangChain with custom implementations. Each brings different strengths - Haystack works well for production deployments, LlamaIndex offers excellent document processing capabilities, and LangChain provides the most extensive ecosystem of integrations.
You can check out the Awesome RAG GitHub repository for a comprehensive list of RAG-related tools and frameworks.
Decision framework: When to build vs. buy
Here's a practical framework to help you decide:
| Factor | Existing Solutions (Buy) | Custom Build | Hybrid Approach |
|---|---|---|---|
| Dataset Size | Under 10,000 documents | Large-scale or specialized datasets | Start small, scale custom components |
| Timeline | Need to ship within weeks | Can invest months in development | Iterate from working prototype |
| Team Expertise | Limited RAG experience | Strong AI engineering team | Mix of existing tools + custom code |
| Document Types | Standard PDFs, text, basic tables | Proprietary or unusual formats | Standard base + custom processors |
| Performance Requirements | Standard response times acceptable | Sub-100ms response times needed | Optimize bottlenecks as identified |
| Security Needs | Standard compliance requirements | Highly sensitive data, custom security | Secure foundation + custom controls |
| Budget Priorities | Favor operational costs over dev time | Development investment acceptable | Balanced approach |
| Competitive Advantage | RAG is supporting functionality | RAG system is core differentiator | Build advantages incrementally |
Start with existing tools, customize as your needs grow
Most successful RAG implementations follow a progression: start with existing tools to prove the concept and understand your requirements, then gradually add custom components where needed. This approach lets you deliver value quickly while building the expertise needed for more advanced customizations.
For our tutorial's scope - processing documentation PDFs and answering questions about them - LangFlow's template approach hits the sweet spot of simplicity and capability. But as your needs grow, you'll have a solid foundation to build upon.
Conclusion
You now have a complete PDF RAG system that converts static documents into an interactive knowledge base. This tutorial covered the entire process: collecting PDFs at scale with Firecrawl's web-to-PDF conversion, building the RAG pipeline using LangFlow's visual workflow builder, and creating a polished chat interface for question-answering. The approach saves you weeks of development time compared to writing all the code yourself, while still giving you a foundation that can grow with your needs.
The real value comes from having a working system you can immediately use and improve over time. Whether you're building internal documentation assistants, customer support tools, or research applications, this foundation handles the complex parts of PDF processing and vector search. As your requirements evolve, you can add the custom components and improvements we discussed, turning your prototype into a production-ready application that serves real users and real business needs.
Check out our related articles on RAG:
References
1. PDF downloader script full code:
#!/usr/bin/env python3
"""
PDF Downloader Script
This script uses Firecrawl to map URLs from firecrawl.dev, filter them,
and download PDFs for each page using Firecrawl's PDF generation feature.
"""
import os
import re
import requests
from typing import List, Set
from firecrawl import Firecrawl
from dotenv import load_dotenv
def setup_firecrawl() -> Firecrawl:
"""Initialize Firecrawl app with environment variables."""
load_dotenv()
return Firecrawl()
def get_site_links(
app: Firecrawl, base_url: str = "https://firecrawl.dev"
) -> List[str]:
"""
Map all URLs from the given base URL including subdomains.
Args:
app: Firecrawl instance
base_url: Base URL to map (default: https://firecrawl.dev)
Returns:
List of discovered URLs
"""
print(f"Mapping URLs from {base_url}...")
map_result = app.map(url=base_url)
links = [link.url for link in (map_result.links or [])]
print(f"Found {len(links)} total links")
return links
def filter_links(links: List[str]) -> Set[str]:
"""
Filter out unwanted links containing '#', 'blog', 'template', or '?'.
Args:
links: List of URLs to filter
Returns:
Set of filtered URLs
"""
filtered_links = []
for link in links:
if all(term not in link for term in ["#", "blog", "template", "?"]):
filtered_links.append(link)
filtered_set = set(filtered_links)
print(f"Number of links after filtering: {len(filtered_set)}")
return filtered_set
def url_to_filename(url: str) -> str:
"""
Convert URL to a safe filename for PDF storage.
Args:
url: URL to convert
Returns:
Safe filename with .pdf extension
"""
# Remove protocol (http:// or https://)
url = re.sub(r"^https?://", "", url)
# Replace special characters with underscores
filename = url.replace("/", "_").replace(".", "_")
# Add pdf extension
return f"{filename}.pdf"
def download_pdf(app: Firecrawl, url: str, output_dir: str) -> bool:
"""
Download PDF for a single URL using Firecrawl.
Args:
app: Firecrawl instance
url: URL to scrape and convert to PDF
output_dir: Directory to save the PDF
Returns:
True if successful, False otherwise
"""
try:
# Get PDF link using Firecrawl
print(f"Processing {url}...")
scrape_result = app.scrape(url, actions=[{"type": "pdf"}])
if not scrape_result.actions or not scrape_result.actions.pdfs:
print(f"No PDF generated for {url}")
return False
pdf_link = scrape_result.actions.pdfs[0]
# Download the PDF
response = requests.get(pdf_link)
if response.status_code == 200:
# Create filename based on URL
filename = url_to_filename(url)
filepath = os.path.join(output_dir, filename)
# Save the PDF
with open(filepath, "wb") as f:
f.write(response.content)
print(f"✓ Downloaded: {filename}")
return True
else:
print(f"✗ Failed to download {url}: HTTP {response.status_code}")
return False
except Exception as e:
print(f"✗ Error processing {url}: {str(e)}")
return False
def download_all_pdfs(
app: Firecrawl, links: Set[str], output_dir: str = "firecrawl_pdfs"
) -> None:
"""
Download PDFs for all provided links.
Args:
app: Firecrawl instance
links: Set of URLs to process
output_dir: Directory to save PDFs (default: firecrawl_pdfs)
"""
# Create output directory if it doesn't exist
os.makedirs(output_dir, exist_ok=True)
print(f"Saving PDFs to: {output_dir}")
successful_downloads = 0
total_links = len(links)
for i, url in enumerate(links, 1):
print(f"\n[{i}/{total_links}] Processing {url}")
if download_pdf(app, url, output_dir):
successful_downloads += 1
print(f"\n📊 Summary:")
print(f"Total links processed: {total_links}")
print(f"Successful downloads: {successful_downloads}")
print(f"Failed downloads: {total_links - successful_downloads}")
print(f"PDFs saved in: {output_dir}")
def main():
"""Main execution function."""
print("🔥 Firecrawl PDF Downloader")
print("=" * 50)
try:
# Setup
app = setup_firecrawl()
# Get and filter links
links = get_site_links(app)
filtered_links = filter_links(links)
if not filtered_links:
print("No links to process after filtering.")
return
# Download PDFs
download_all_pdfs(app, filtered_links)
print("\n✅ Process completed!")
except Exception as e:
print(f"❌ Fatal error: {str(e)}")
return 1
return 0
if __name__ == "__main__":
exit(main())2. Streamlit interface full code
import streamlit as st
import requests
import json
import uuid
from typing import Iterator, Dict, Any
def setup_streamlit_page():
st.set_page_config(
page_title="LangFlow Chat Interface", page_icon="🤖", layout="wide"
)
st.title("🤖 LangFlow Chat Interface")
def initialize_session_state():
if "messages" not in st.session_state:
st.session_state.messages = []
if "session_id" not in st.session_state:
st.session_state.session_id = str(uuid.uuid4())
if "flow_config" not in st.session_state:
st.session_state.flow_config = {
"url": "http://localhost:7868/api/v1/run/bdb3c53c-3529-4793-8eb6-9bc9fb41127d",
"stream": True,
}
def show_sidebar():
with st.sidebar:
st.header("🔧 Configuration")
# Flow URL input
flow_url = st.text_input(
"Flow URL",
value=st.session_state.flow_config["url"],
help="Your LangFlow API endpoint URL",
)
# Streaming toggle
enable_streaming = st.checkbox(
"Enable Streaming", value=st.session_state.flow_config["stream"]
)
# Update session state
st.session_state.flow_config = {"url": flow_url, "stream": enable_streaming}
st.divider()
# Clear chat button
if st.button("🗑️ Clear Chat History", use_container_width=True):
st.session_state.messages = []
st.session_state.session_id = str(uuid.uuid4())
st.rerun()
def stream_langflow_response(url: str, payload: Dict[str, Any]) -> Iterator[str]:
"""Stream response from LangFlow API"""
stream_url = f"{url}?stream=true"
headers = {"Content-Type": "application/json"}
try:
response = requests.post(
stream_url, json=payload, headers=headers, stream=True, timeout=60
)
response.raise_for_status()
previous_text = ""
for line in response.iter_lines():
if line:
try:
event_data = json.loads(line.decode("utf-8"))
if event_data.get("event") == "add_message":
# Only process messages from the assistant, not user echoes
if event_data["data"]["sender"] == "Machine":
current_text = event_data["data"]["text"]
if len(current_text) > len(previous_text):
new_chunk = current_text[len(previous_text) :]
previous_text = current_text
yield new_chunk
elif event_data.get("event") == "end":
return
except json.JSONDecodeError:
continue
except requests.exceptions.RequestException as e:
yield f"Error: {str(e)}"
def make_langflow_request(url: str, payload: Dict[str, Any]) -> str:
"""Make non-streaming request to LangFlow API"""
headers = {"Content-Type": "application/json"}
try:
response = requests.post(url, json=payload, headers=headers, timeout=60)
response.raise_for_status()
result = response.json()
# Extract message from LangFlow response structure
if "outputs" in result and result["outputs"]:
output = result["outputs"][0]
if "outputs" in output and output["outputs"]:
output_data = output["outputs"][0]
if "results" in output_data and "message" in output_data["results"]:
return output_data["results"]["message"]["text"]
return "No response received"
except requests.exceptions.RequestException as e:
return f"Error: {str(e)}"
def handle_user_input(user_message: str):
# Add user message to history
st.session_state.messages.append({"role": "user", "content": user_message})
# Display user message
with st.chat_message("user"):
st.markdown(user_message)
# Prepare API payload
payload = {
"input_value": user_message,
"output_type": "chat",
"input_type": "chat",
"session_id": st.session_state.session_id,
}
# Display assistant response with streaming
with st.chat_message("assistant"):
if st.session_state.flow_config["stream"]:
response_placeholder = st.empty()
full_response = ""
for chunk in stream_langflow_response(
st.session_state.flow_config["url"], payload
):
full_response += chunk
response_placeholder.markdown(full_response + "▌")
response_placeholder.markdown(full_response)
else:
# Handle non-streaming response
response = make_langflow_request(
st.session_state.flow_config["url"], payload
)
st.markdown(response)
full_response = response
# Add assistant response to history
st.session_state.messages.append({"role": "assistant", "content": full_response})
def main():
setup_streamlit_page()
initialize_session_state()
show_sidebar()
# Display conversation history
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# Chat input
if user_input := st.chat_input("Type your message here..."):
handle_user_input(user_input)
if __name__ == "__main__":
main()
