
TL;DR
- Web indexes are pre-built snapshots - Every search engine and AI agent reads from a structured catalog assembled in advance
- Indexing is a four-stage pipeline - Crawling, parsing, storage, and ranking each introduce distinct failure modes that compound downstream
- Hybrid retrieval beats either approach alone - BM25 wins on exact matches; dense vectors win on semantics; hybrid wins in production on mixed workloads
- Chunking quality sets the RAG ceiling - Noisy extraction and bad chunk boundaries silently collapse retrieval before the LLM sees any content
- AI indexing and search indexing are different problems - What Google ranks highly and what a RAG pipeline retrieves accurately are optimized by different signals with different tradeoffs
- Build with Firecrawl /search - Query a web index built for agents and get back clean, structured results without managing crawl and extraction infrastructure
With the introduction of Google AI Overviews, 60% of Google searches now end without a click. No page visit. No human reading. The Google search index answers the question directly.
When you type a query into Google, it never fetches any live URLs. It queries a structured snapshot of the web built hours, days, or weeks before your search. That snapshot is the index. The same logic applies to every AI agent that "knows" something about the web. It's not reading the live web in real time. It's reading from an index built in advance.
If you're building AI products, this distinction matters more than it ever did for traditional SEO. The quality, structure, and freshness of the index your agent reads from set the quality ceiling for everything your agent can answer.
Website indexing isn't just an SEO concern anymore. It's a systems design concern.
What is a web index?
A web index is a structured, queryable catalog of web content built from crawled and processed pages, designed for fast retrieval.
Think of a library catalog versus the books themselves. When you search Google, it never touches the live web. It queries a snapshot assembled hours, days, or weeks earlier. The index points to the content; retrieval is near-instant.
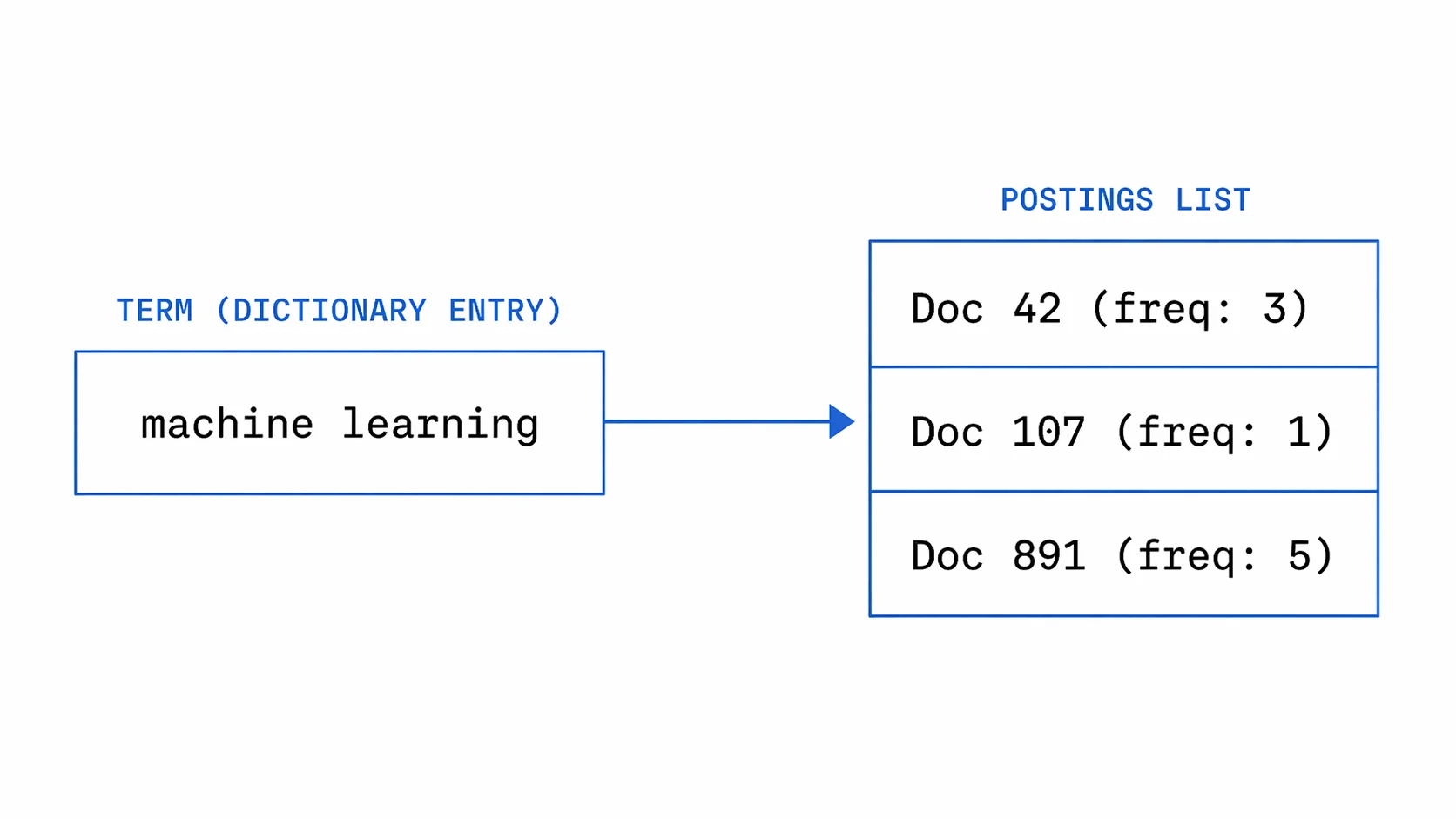
The core data structure is the inverted index: every unique word in the corpus maps to a sorted list of document IDs where it appears, along with term frequency and position data. Instead of asking "what words are in this document?", you ask "which documents contain this word?" That inversion is what makes sub-millisecond lookup possible across billions of pages.
Google's index covers roughly 400 billion documents drawn from over one trillion discovered URLs, not all of which make the cut. The index spans petabytes, distributed across thousands of machines via Bigtable and Colossus. Common Crawl, the open-source alternative, captures over 3 billion pages per crawl stored as WARC files on AWS S3.
Inverted indexes aren't the only kind. For AI systems, there are three types worth knowing:
- Keyword (inverted) indexes map terms to documents: fast, exact, and interpretable. Google, Elasticsearch, and Lucene are built on them.
- Vector (dense) indexes store numeric embeddings and support approximate nearest-neighbor search for semantic matching. Pinecone, Weaviate, and Qdrant are built around them.
- Hybrid indexes combine both: keyword search for precision, semantic search for coverage. As of 2025, dense retrieval leads BM25 by 15–25% NDCG@10 on the BEIR benchmark, but hybrid still wins on most mixed-query workloads.
How does web indexing work?
Web indexing is a four-stage pipeline:
| Stage | What it does |
|---|---|
| Crawling | Bots follow links and sitemaps to discover pages and download raw HTML |
| Parsing and normalization | Raw HTML is stripped of noise, deduplicated, and split into clean chunks |
| Storage and indexation | Processed content is stored in inverted and/or vector indexes for fast lookup |
| Ranking and retrieval | Scoring models decide what surfaces for a given query, using keyword, semantic, or hybrid signals |
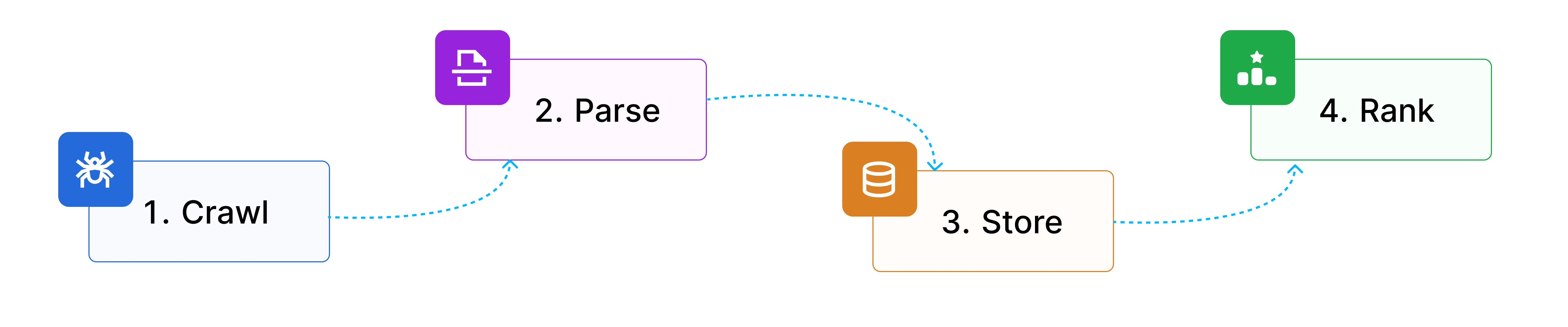 How indexing works
How indexing works
Each stage transforms raw URLs into queryable, ranked content. Each stage also has its own failure modes.
Stage 1: crawling
Crawling is discovery. Bots follow links and read sitemaps to find pages, download the raw HTML, and pass it downstream.
Every crawler operates under constraints. Googlebot enforces a 2MB page limit; anything beyond that gets truncated. Crawl budget governs how much of your site gets visited per day, and as Gary Illyes of Google has confirmed, it's not a fixed number. It's the product of how fast a site can be crawled without degrading performance and how much Google wants to crawl based on quality signals. Low-quality pages drain budget; high-quality pages earn more crawl frequency.
Robots.txt controls which paths crawlers can access, but the rules have quirks worth knowing. Googlebot ignores the Crawl-delay directive entirely, while Bingbot and Yandex respect it, a common misconfiguration. Rules are also case-sensitive: Disallow: /Admin/ does not block /admin/.
The crawler landscape has shifted. Cloudflare data from 2025 shows AI crawlers now account for 20% of all verified bot traffic, versus 40% for traditional search crawlers. The assumption of "one crawler per engine" no longer holds.
GPTBot, ClaudeBot, and PerplexityBot each behave differently. Bingbot now serves double duty as the index behind both Bing Search and Microsoft Copilot. Perplexity drew scrutiny in 2024 when Cloudflare documented their stealth crawlers using undeclared user-agents to bypass robots.txt.
You can explore the full directory of known bots at bot.fyi, a public registry maintained by Vercel.
Stage 2: parsing and normalization
Crawling fetches raw HTML. Parsing turns it into usable content: stripping boilerplate, extracting main text, detecting language, deduplicating content across URLs, and normalizing encoding. HTML cleaning and boilerplate removal is particularly critical for LLM training pipelines, where noisy input directly degrades model quality.
The boilerplate problem is bigger than it looks. A naive approach to stripping HTML tags yields 40–60% noise on typical web pages: navigation, ads, footers, and cookie banners all mixed with the actual content. For keyword search, this is manageable. For AI retrieval, it's toxic: noisy chunks produce poor embeddings, poor embeddings surface irrelevant results, and the model generates a confident-looking answer from content that was never relevant to begin with.
Open-source extraction tools vary significantly in how well they handle this. Trafilatura reaches approximately 95% precision on news articles, Mozilla Readability hits around 85%, and Newspaper3k comes in at 70–75% with higher error rates on malformed HTML. For production pipelines processing diverse page types, that spread is meaningful.
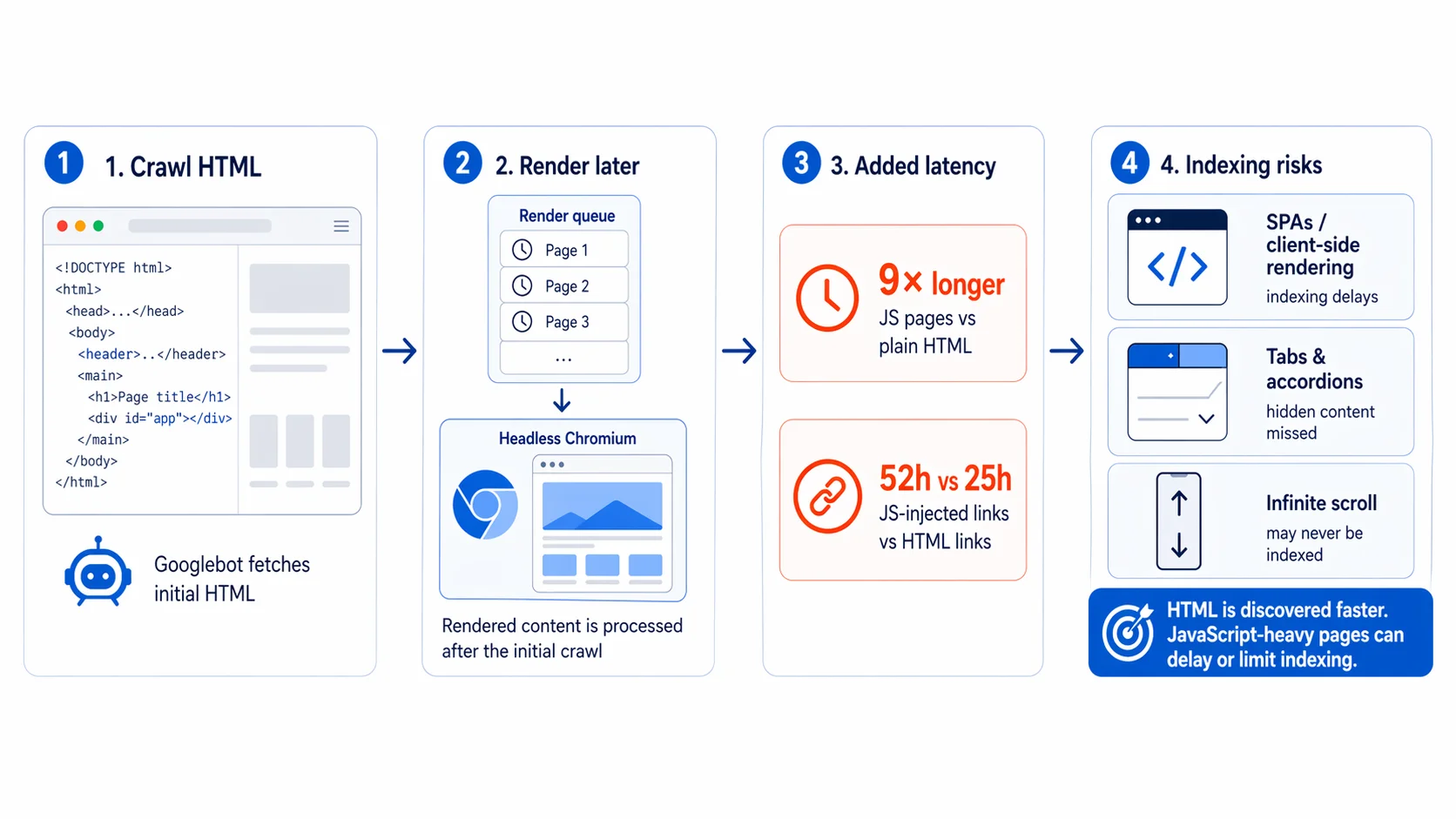
JavaScript rendering adds another layer of complexity. Googlebot processes JS pages through the Web Rendering Service, but rendering is asynchronous: pages enter a separate render queue after the initial HTML crawl, so raw HTML gets indexed first and rendered content follows later.
Research from Onely shows Googlebot needs 9 times longer to process JavaScript pages than plain HTML, and JavaScript-injected links take a median of 52 hours to be followed versus 25 hours for HTML links. SPAs that depend on client-side rendering face real indexing delays, and content behind tabs, accordions, or infinite scroll may never be indexed at all.
For AI-specific pipelines, this is also where chunking happens. Documents get split into retrievable units, and the strategy matters more than most teams realize.
Research from Jina AI showed that naive fixed-size chunking loses inter-chunk context: in one test, a sentence referencing "Berlin" (mentioned only in an earlier chunk) scored 0.7084 for semantic similarity with naive chunking, while late chunking (which preserves surrounding context using pooled token embeddings) raised that score to 0.8249. Across the BEIR benchmark, late chunking improved retrieval by 2–4% with no additional training.
The failure mode with a name is chunking drift: tiny formatting changes in HTML or a PDF silently shift chunk boundaries, overlaps become inconsistent, and semantic units split mid-thought. The Hacker News consensus is blunt: "the single biggest source of retrieval collapse is chunking, and it's usually invisible." Most teams never version their chunking logic.
There's a sharp irony in this. In January 2026, Google's Danny Sullivan warned content creators against pre-fragmenting their pages into bite-sized chunks for LLMs. At the same time, if you're building a RAG pipeline, you have to chunk documents to make retrieval work at all. The right chunk boundaries for Google and the right chunk boundaries for a RAG index are different problems with different answers.
Stage 3: storage and indexation
Once content is parsed and normalized, it gets stored in a structure optimized for fast retrieval. That structure determines both query speed and the kinds of questions the index can answer.
For keyword search, the core structure is the inverted index: each term maps to a postings list, a sorted list of document IDs, term frequencies, and positional data. For a query like "machine learning," the index intersects the postings list for "machine" with the one for "learning." That intersection runs in O(m+n) time, and skip pointers cut it further. As the Stanford IR textbook describes, for a list of 1,000 entries with 32 skip pointers placed at intervals, comparisons drop from 1,000 to roughly 64.
Lucene and Elasticsearch implement this with an immutable segment architecture: new writes create new segments, which merge periodically in the background. The term dictionary uses Finite State Transducers to share character prefixes across millions of terms and fit in minimal RAM. Document IDs are delta-encoded and compressed with FOR (Frame-of-Reference) encoding, which cuts storage and improves disk I/O. Relevance scoring uses BM25, weighting term rarity (IDF), term frequency with saturation (k1=1.2 by default), and document length normalization (b=0.75 by default).
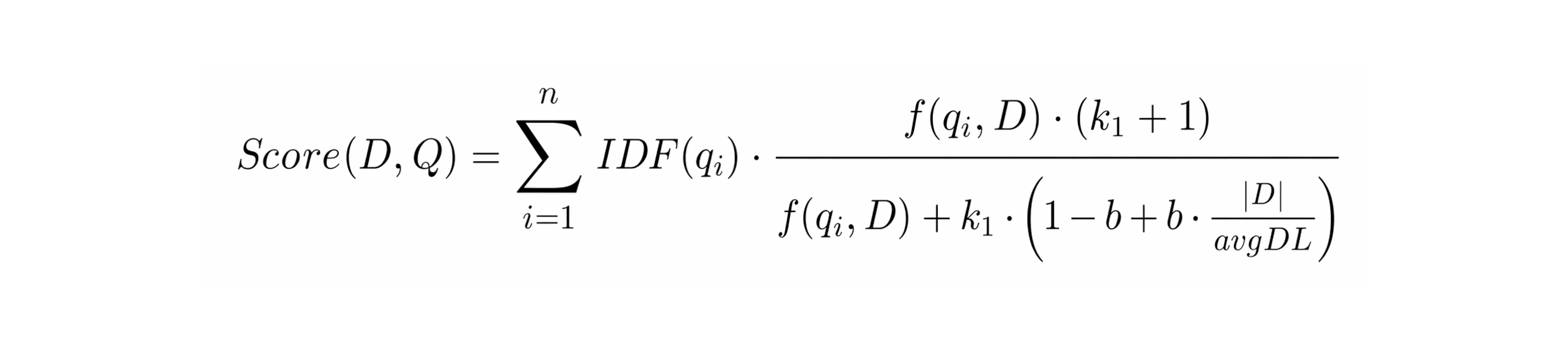
For AI retrieval, content also gets embedded into dense vectors and stored in a vector database. Comparing a query against every vector in the index does not scale at billions of entries, so systems use approximate nearest-neighbor search instead. HNSW handles this by building a layered graph that progressively narrows the search, trading a small amount of recall for dramatically faster lookup. At very large scale, compressed approaches like IVF-PQ cut memory 8-16x at the cost of some accuracy.
Production systems typically run both indexes together. Weaviate, Qdrant, and Pinecone all support hybrid search: keyword matching for precision, semantic vectors for coverage, merged into a single ranked result via Reciprocal Rank Fusion. Keyword search misses synonyms and intent. Semantic search misses exact strings like version numbers or product codes. Hybrid covers both, which is why it dominates in production.
Stage 4: ranking and retrieval
The final stage takes what is stored and decides what gets surfaced for a given query. The signals used to make that decision differ significantly between traditional search and AI retrieval.
For traditional search, ranking layers multiple signals on top of BM25. Since 2015, RankBrain has applied machine learning to handle the 15% of queries that are novel and lack historical signal. Since 2019, BERT has been integrated into Google Search to understand query context beyond keyword matching. The 2024 Google ranking leak confirmed that NavBoost, which tracks user engagement quality across 13 months of data (dwell time, good clicks, bounce rate), is one of the most important signals in production. The ranking stack is deep, and most of it is behavioral.
For AI retrieval, none of that applies. There are no click signals, no dwell time, no authority derived from inbound links. AI search systems have to build relevance from the content itself.
The practical tradeoff between sparse and dense retrieval comes down to what you are searching for. BM25 is unbeatable on exact matches: product codes, version numbers, proper nouns, specific identifiers. Dense retrieval wins on semantic queries where the words in the question do not appear in the answer. Hybrid wins in production where both query types are present. The BEIR benchmark bears this out: by 2025, dense models had pulled ahead of BM25 by 15-25% NDCG@10 on average, but hybrid still wins on mixed workloads, which is why virtually every production retrieval system uses both.
Why website indexing matters for search and AI agents
How web indexing shapes search visibility
If a page isn't indexed, it doesn't exist. That's still the baseline. You submit an XML sitemap, use rel="canonical" to consolidate duplicate URLs, keep important pages within 1-3 clicks of the homepage, and add JSON-LD structured data so parsers don't have to guess what the content means. Get that right and the crawler finds you. Get it wrong and you're invisible regardless of how good the content is.
But being indexed has gotten more complicated. Google integrated the Helpful Content System into core ranking in 2024, and the December 2025 core update pushed this further. The target across seven confirmed 2025 updates was consistent: high-volume, low-originality content that looks comprehensive but lacks real expertise. SpamBrain doesn't flag AI-written content as a category. It flags quality patterns and manipulation signals. The method of production doesn't matter; the result does.
The harder shift is that being indexed is now a different problem from being cited. AI Overviews pull from pages that don't necessarily rank in the top organic results. The selection signals are different: semantic completeness, entity density, verifiable cross-referenced facts, and self-contained passages that answer a question without requiring context from the surrounding page.
This has measurable traffic consequences. Seer Interactive analyzed 25.1 million impressions across 42 organizations and found organic CTR dropped 61% for queries that trigger AI Overviews. Ahrefs found a 58% lower average CTR for top-ranking pages when AI Overviews appear. The index is still the foundation. But citation is the new visibility layer.
How AI agents depend on index quality
Here the stakes are higher. For a search engine, the index is one component in a system that returns links. For an AI agent, the index is the knowledge base. Everything the agent says is downstream of what the index contains and how it is structured.
The original RAG paper from Lewis et al. framed this clearly. RAG combines parametric memory (knowledge baked into model weights) with non-parametric memory (a dense vector index queried at inference time). The model generates more specific, factual, and diverse outputs when it can retrieve from an up-to-date index. Without retrieval, the model relies on its training data. Training data has a cutoff. The web doesn't.
Three failure modes appear in production systems:
Stale index, wrong answers. A research agent answering "what are the current requirements for X?" from an index that is six months old returns the old requirements. The model has no way to know the information is stale. It answers confidently. For legal, compliance, and pricing use cases, this is a real liability. You.com's architecture uses streaming ingestion for exactly this reason. News that breaks at 2 PM appears in the index by 2:05. Batch crawls would make that impossible.
Noisy index, hallucinations. A chunk containing 40% boilerplate (navigation, ads, cookie banners) produces a poor embedding. Poor embeddings surface irrelevant results. The LLM extrapolates from those results. It produces a confident-sounding answer that is not grounded in any real content. A 20% difference in extraction accuracy compounds to a 30-40% difference in downstream retrieval quality.
For a complete walkthrough of the LLM grounding pipeline — using live web data to anchor model responses in verifiable facts — see the dedicated guide.
Bad chunks, retrieval collapse. The right answer is in the index. But the chunk that contains it was split mid-sentence and its context was lost. The embedding does not match the query. The retrieval step returns something plausible but wrong. The model never surfaces the correct answer. Simon Willison noted in April 2025 that 2023-era AI search had a strong tendency to hallucinate details not present in the retrieved content. The improvement in 2025 came from deeper integration between search and reasoning: o3 and o4-mini now run retrieval as part of chain-of-thought reasoning before producing a final answer, not after.
The structural difference between search indexing and AI indexing isn't subtle. Traditional search engines optimize for click-through on a top-10 list. AI agents need top-k chunks that are complete, accurate, and self-contained enough to answer a question without the model having to read around them. The same page can score excellently for Google and produce poor retrieval for a RAG pipeline.
Indexed for Google doesn't mean indexed for AI.
What are the core components of web indexing?
Document URLs and canonical signals
The same content often lives at multiple URLs: trailing slashes, HTTP vs HTTPS, www vs non-www, query parameters. Without deduplication, crawlers waste budget re-indexing identical content and authority signals get split across versions. A rel="canonical" tag tells crawlers which URL is definitive. Pages that look healthy in content audits can still be invisible in search if canonicalization is misconfigured.
Link graph and authority signals
Hyperlinks form a graph. Search engines use that graph to infer authority: a page linked by many high-quality sources outranks an identical isolated one. This is the core of PageRank and still one of the most significant ranking inputs. For AI indexes, link graph data also surfaces relationships between documents, useful for multi-hop queries that require reasoning across several sources.
Content embeddings and structured metadata
Indexes store representations of meaning, not just text. Semantic embeddings let a query about "affordable laptops" surface pages using "budget notebooks." Schema.org markup tells the index what kind of thing a page is — product, recipe, news article — so it can apply type-specific ranking logic. For AI retrieval, this reduces ambiguity: the model doesn't have to guess whether it's reading a review or a spec sheet.
Provenance and freshness signals
Indexes record where content came from and when it was last updated. For traditional search, this sets recency weighting. For AI agents, it's more critical: a model retrieving a chunk has no native sense of whether it's six hours or six years old. An index that tracks publication timestamps and source authority lets you filter before retrieval, not after.
What use cases do web indexes enable?
Different agents make different demands on the index. The table below maps the main agent types to what they actually need from the underlying index infrastructure.
| Agent type | What it needs from the index |
|---|---|
| Conversational QA agents | Fast top-k results, short coherent snippets, citation support |
| Research and analyst agents | Deep retrieval, deduplication, structured outputs, multi-hop support |
| Monitoring agents | Streaming or scheduled updates, change detection |
| Extraction agents | Clean page text or markdown, stable parsing, structured field extraction |
| Coding agents | Up-to-date docs, package contents, version-aware content |
Most RAG failure modes trace back to a mismatch between what the agent needs and what the index actually provides. A monitoring agent querying a batch-crawled index will miss changes between crawls. A conversational QA agent querying a noisy index will hallucinate. A coding agent querying a vector-only index will miss exact version strings that BM25 would have caught.
Web indexing, search, and extraction: why all three steps matter
Most discussions of "web data for AI" collapse three distinct operations into one. They're not the same thing.
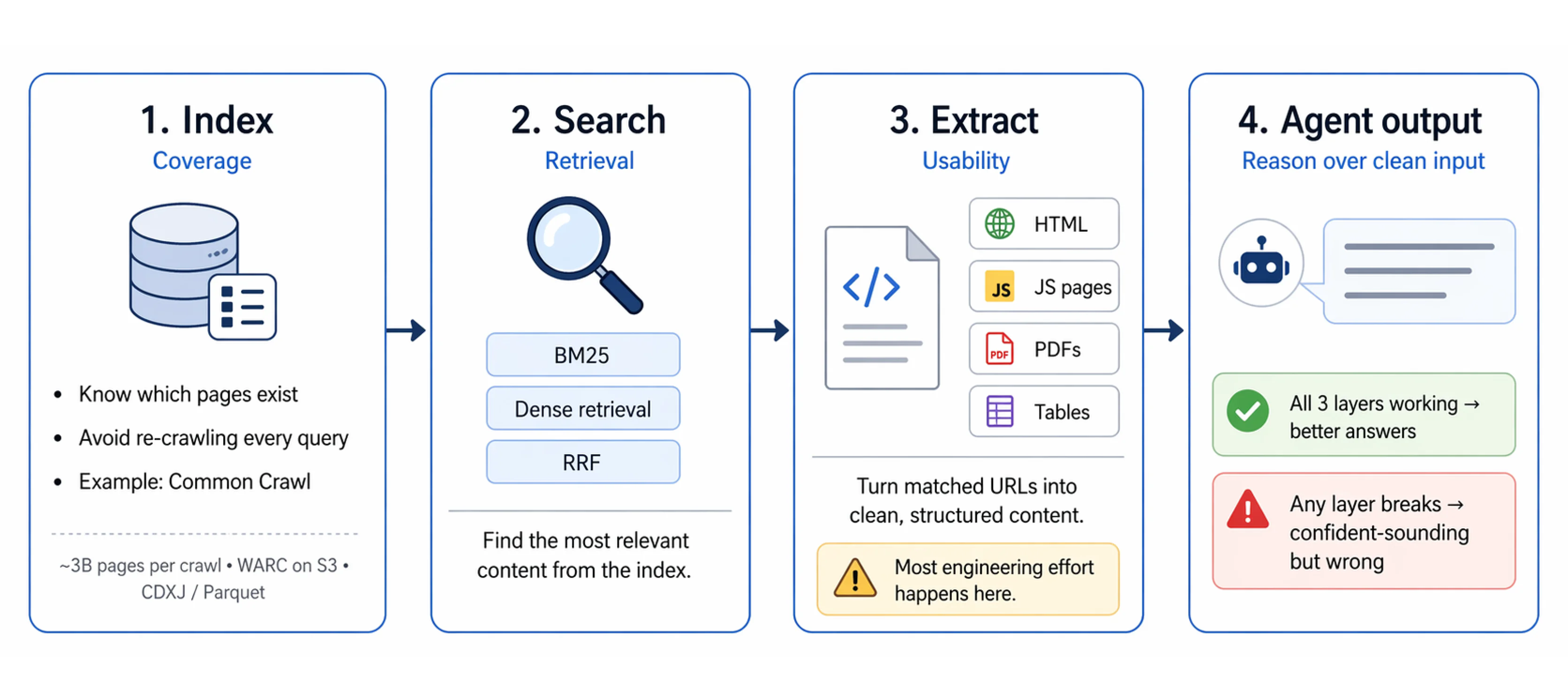
Index is about coverage. Which pages exist? Where are they? An index lets you search without crawling from scratch on every query. Without a good index, you either miss content entirely or waste compute re-crawling the same pages repeatedly. Common Crawl provides an open baseline: 3 billion pages per crawl, stored as WARC files on S3, queryable via CDXJ index files or Apache Parquet for SQL-style analytics.
Search is about retrieval. Given a query, which content in the index is most relevant? This is the step where hybrid scoring matters. BM25 for exact matches. Dense retrieval for semantic queries. RRF to merge both ranked lists cleanly. Getting search right means a well-indexed corpus actually surfaces the right content for each query.
Extract is about usability. A URL isn't the same as usable content. Raw HTML contains noise. JavaScript-rendered pages need a headless browser. PDFs need a parser. Tables and structured data need special handling. The extracted content has to be clean, well-structured, and in a format the model can reason over.
This is where most developer time goes in practice. Crawling and indexing are solvable infrastructure problems. Clean extraction at scale across diverse page types is an ongoing engineering challenge. The quality of your agent's input is determined here. Every step downstream of extraction is constrained by what extraction produced.
Firecrawl handles search, interact, and extraction through a single API, giving agents access to a web index built for accurate, verifiable retrieval: current, low-noise, and structured for the kinds of queries production AI systems actually run.
Your agent is only as smart as your index: build with Firecrawl /search
If you're building AI products, your agent's quality ceiling is the quality of the index it reads from. Freshness, structure, noise level, and chunking strategy all set constraints that no amount of prompt engineering can overcome. The pipeline that matters isn't model selection. It's data quality at the index level.
The easiest way to start is with Firecrawl's Search API: query a web index built for agents, get back clean, structured results your model can actually use, and skip the infrastructure work of crawling, parsing, and chunking yourself.
Frequently Asked Questions
What is the difference between crawling and indexing?
Crawling is the discovery step. A bot follows links, downloads pages, and passes raw content downstream. Indexing is the processing step: content is parsed, normalized, stored in a data structure that supports fast retrieval, and made queryable. They run as separate, asynchronous stages in production systems. You can crawl without indexing (a one-time scrape) and re-index without re-crawling (re-embedding previously downloaded text with a new embedding model).
How long does it take Google to index a new page?
Anywhere from a few hours to several weeks. The main factors are crawl budget, whether the URL is in a sitemap, how many internal links point to it, and the site's historical crawl frequency. You can request indexing via Google Search Console. AI-generated content is indexed at an average of 36 days based on 2025 data, treated on the same timeline as any other content.
Can JavaScript-rendered content be indexed?
Googlebot renders JavaScript, but with a documented delay. Light sites wait minutes to hours. Heavy SPAs can wait days to weeks. Content that only appears after user interaction (clicking tabs, scrolling, expanding accordions) may never be rendered at all because Googlebot does not interact with pages. For AI agent pipelines, headless browser rendering via Playwright or Puppeteer is the reliable solution for JS-heavy content.
What is the difference between a search index and a vector index?
A search index (inverted index) maps terms to documents for fast keyword lookup. A vector index stores dense embeddings and supports approximate nearest-neighbor search: find documents whose meaning is closest to this query. Inverted indexes are faster and more interpretable. Vector indexes handle paraphrase, synonyms, and conceptual similarity. Production AI retrieval systems use both in a hybrid configuration, merging BM25 scores and vector similarity scores via Reciprocal Rank Fusion to get precision from keywords and coverage from semantics.
How do AI agents use web indexes?
AI agents use web indexes through the RAG (Retrieval-Augmented Generation) pattern. Given a query, the agent retrieves the top-k most relevant chunks from the index and injects them into the model's context. The model generates a response grounded in retrieved content. Advanced agents run multiple retrieval passes: 3-6 LLM calls for query decomposition and 2-4 retrieval passes for iterative refinement. Index quality sets the ceiling. Freshness, noise level, chunk quality, and embedding model all determine what the agent can accurately answer.
Does Google penalize AI-generated content?
No. Google evaluates all content on the same criteria: quality, helpfulness, and E-E-A-T, regardless of how it was produced. What Google targets is Scaled Content Abuse: high-volume, low-originality, unedited content created to manipulate rankings. SpamBrain detects quality signals and manipulation intent, not AI origin. Well-crafted AI content with genuine value is treated the same as human-written content.
What does freshness mean for a web index, and why does it matter more for AI?
Freshness is how recently the index reflects the current state of a page. For traditional search, slightly stale content is tolerable. Users see the date and can judge. For AI agents, staleness is invisible. The model produces a confident-sounding answer from six-month-old data with no indication that the data is outdated. For use cases involving pricing, compliance, availability, or recent events, a stale index does not just produce a worse result. It produces a wrong one that looks right.
What causes a page to not get indexed?
The most common causes: blocked by robots.txt, carries a noindex directive, no inbound links and not in any sitemap, content is behind a login or paywall, duplicate content that was canonicalized away, requires JavaScript that the crawler does not execute, or crawl budget was exhausted before the page was reached. For AI-specific pipelines, rate limiting and dynamic content are additional challenges that headless browsers must handle.
Why does my AI agent give wrong answers even when the right information is online?
Almost always an index quality problem, not a model problem. The three most common causes: the page exists but the crawler never reached it (coverage gap); the page was crawled but extraction left it noisy with boilerplate, which produced a bad embedding that never surfaces in retrieval (noise problem); or the page was chunked at a boundary that split the answer across two chunks, neither of which scores high enough on its own (chunking problem). Prompt engineering does not fix any of these. The answer is earlier in the pipeline.
