
TL;DR
Codex's built-in web search queries a stale pre-scraped index by default, silently fabricates results when the network is restricted, caps you at 4 queries per call, and returns snippets with no full-page content. Switching to Firecrawl fixes all of it: live results, full markdown pages, crawling, and domain/time filtering, wired directly into Codex as native MCP tools. Two config lines to set up, one line to disable the broken default.
| Codex default search | Firecrawl MCP | |
|---|---|---|
| Data freshness | Pre-scraped cache, no SLA | Live, real-time results |
| Queries per call | Hard cap of 4 | Unlimited |
| Full-page content | Snippets only | Full markdown per page |
| Time filtering | Not supported | Past day, week, month |
| Domain filtering | Not supported | Restrict to any domain |
| Site crawling | Not supported | Full crawl + URL mapping |
| Structured extraction | Not supported | JSON schema extraction |
| Silent failures | Fabricates results silently | Explicit errors |
| Setup required | None (on by default) | ~2 lines in config.toml |
I was auditing a dependency update with Codex and asked it to pull the latest changelog for a library. It came back with version numbers, migration steps, deprecation notices. Confident and detailed. Every single thing was wrong.
The library had shipped a major breaking change three weeks earlier. Codex had no visibility into that. No warning, no timestamp, no caveat. It just answered from whatever was in the cache.
The web_search tool did fire. That's the important part. This wasn't the model making things up from training data. Codex queried its search tool, got results back, and reasoned from them accurately. The problem is that Codex's default search mode queries a pre-scraped index maintained by OpenAI, not the live web. The model received stale data and produced a correct-looking answer from it. The failure is at the data layer, not the model layer.
That distinction matters because it changes how you fix it. You don't need a better prompt. You need a different data source. This guide covers how Codex web search works in both the CLI and the desktop app, where its limits are, and how to wire in Firecrawl to get live results, full-page content, and actual crawling.
What is Codex?
Codex is OpenAI's AI-powered coding agent, available as a CLI and a desktop app. It runs tasks in a sandboxed environment with access to your filesystem, shell, and external tools (including web search). It's designed for multi-step developer workflows: dependency audits, migration assistance, documentation lookups, and automated code changes.
How does web search work in Codex CLI?
Codex CLI ships with web search enabled by default (see Can Codex CLI do web search? How to enable it? for a quick primer). It runs in two modes.
Cached mode queries an OpenAI-maintained pre-scraped index. Results come back fast. But they reflect whenever OpenAI last crawled that page. No freshness indicator is shown to you or to the model. This default catches many developers off guard — see Why can't my Codex CLI Agent browse the web? for the short version.
Live mode fetches real-time results. It requires explicit opt-in.
You configure this in ~/.codex/config.toml:
web_search = "cached" # default
web_search = "live" # real-time
web_search = "disabled" # offOr at the CLI level for a single session:
# Live results for this session only
codex --search "React 19 breaking changes"
# Full sandbox access mode, also enables live search
codex --yolo "research the Next.js 15 changelog"One useful detail from the CLI reference: web search activity shows up in session transcripts and in codex exec --json output as web_search items. You can audit exactly what got fetched.
How does web search work in the Codex App?
The Codex desktop app shares the same web search behavior as the CLI. There is no longer a dedicated web search toggle in the App UI. Configuration goes through ~/.codex/config.toml, which both the App and the CLI read from the same file.
The same three modes apply: cached (default), live, and disabled.
web_search = "cached" # default; serves results from the web search cache
# web_search = "live" # fetch the most recent data from the web (same as --search)
# web_search = "disabled"One shortcut still works: running with full sandbox access automatically switches web search to live results.
Both the CLI and the App share one hard boundary. Web search can't reach authenticated pages. No signed-in sessions, cookies, browser extensions, or existing tabs. That's a sandbox-level constraint, not a bug. The App's browser tool handles those cases separately.
What are Codex's web search limitations?
The feature works. But it has real gaps that matter for development workflows:
- Results come from a pre-scraped cache with no freshness guarantee
- Codex can silently fabricate search results when network access is restricted
- Each call is capped at 4 queries regardless of task complexity
- Search returns snippets only: no full-page content
- There's no domain filtering, time filtering, or source selection of any kind
Why are cached results unreliable?
The cache has no SLA on freshness. For a developer checking a library's latest release, a framework's current migration guide, or whether a known bug was patched, the cache can be months behind. You're not just working with a model that has a training cutoff. You have two independent stale layers presenting as current knowledge. That's an LLM grounding problem, not a prompting one.
Kevin Kern, a developer who regularly documents Codex tips, framed live search as a workaround for "a long-standing problem due to the LLM cutoff." Even in community documentation, staleness is treated as a known condition. Not an edge case.
Why does Codex hallucinate silently when the network is restricted?
GitHub issue #5092 documents this in detail.
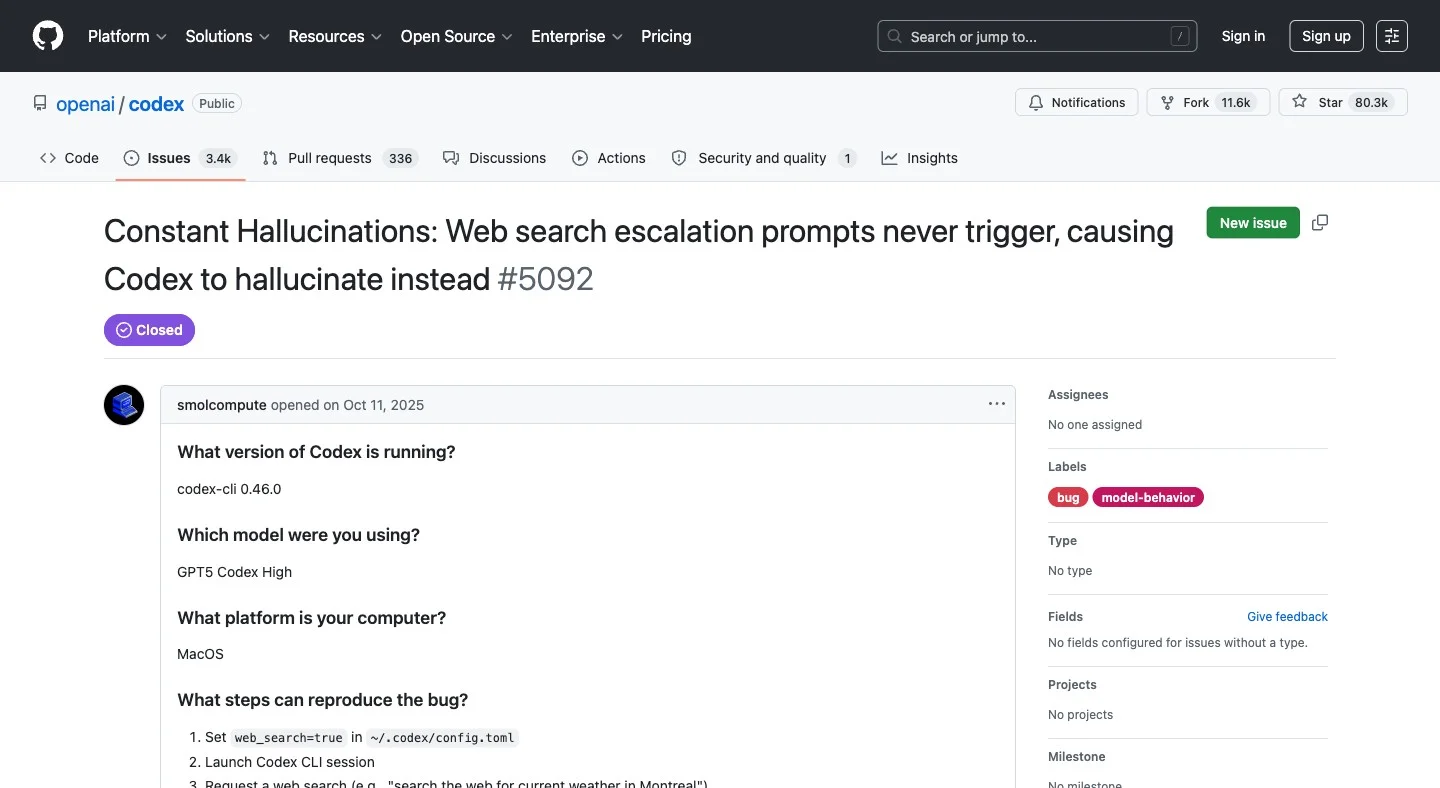
When sandbox network access is restricted, which happens in many default configurations, the escalation prompts that should request network permission never fire.
Instead of throwing an error, Codex "spins in circles attempting alternative approaches" and eventually fabricates a response. It presents invented data as search results. No warning. No error. No indication the search didn't happen.
The proposed fix was simple: fail fast with an explicit error. It was not accepted. This behavior is current.
This is distinct from the staleness issue. It's not that the results are old. No results were fetched at all.
Why is there a hard cap of 4 queries per call?
GitHub issue #7132 lays this out plainly.

Each web.run invocation accepts at most 4 queries. A task checking multiple libraries, comparing changelogs, and gathering migration context needs far more than 4 lookups.
OpenAI closed this issue as "not planned." The reporter noted that Claude Code and ChatGPT do extensive multi-round web investigation. Codex forces batching at 4, adding call overhead and generating session traces that are long and hard to review.
Why does Codex return snippets instead of full pages?
Search returns titles and snippets. Not the actual page. If Codex needs to read the content it found, it requires a separate step. There's no integrated search-and-scrape in a single call. For documentation work specifically, this is the main gap — covered in How do I get Codex to fetch webpages for documentation?.
What filtering options does Codex search support?
You can't restrict results to a specific domain. You can't ask for results from the past week. No news search. No GitHub repo search. No academic paper search. One mode, one source type, no controls.
Here's a quick summary:
| Feature | Codex built-in search |
|---|---|
| Works out of the box | ✓ |
| Visible in session transcripts | ✓ |
| Live, fresh results | ✗ Cached by default |
| Reliable when network is restricted | ✗ Can hallucinate silently |
| Unlimited queries per call | ✗ Hard cap of 4 |
| Full-page content retrieval | ✗ Snippets only |
| Domain or time filtering | ✗ Not supported |
| Site crawling | ✗ Not supported |
Better Web Search and Extraction: How do I integrate Firecrawl with Codex?
What is Firecrawl?
Firecrawl is the context API to search, scrape, and interact with the web at scale. Search finds relevant live sources fast. Scrape turns them into clean, token-efficient markdown or structured JSON. Crawl, Map, and Interact handle depth, structure, and dynamic pages.
Search finds the right source. Scrape turns it into clean, usable context. The full workflow runs through one API, a CLI, or an MCP server that agents like Codex call as native tools.
Firecrawl is used by 1.25M+ developers and non-developers across 150,000+ companies, and has served 5B+ requests to date. It has reached that scale because it handles the full workflow — search, scrape, crawl, interact — in a single install, on the real web. Builders who need reliable web context for agentic workflows keep coming back to it — and recommend it to others. Peter Steinberger, founder of OpenClaw, put it plainly:
Get your free Firecrawl API key →
There are two ways to bring Firecrawl into your Codex workflow. The CLI for direct terminal control. MCP for agent-native use inside tasks. If you're deciding between the two, MCP vs. CLI for AI agents covers the tradeoffs in depth. I'll cover both, plus how to configure MCP in the Codex App.
Option 1: Firecrawl CLI for direct control
The Firecrawl CLI is a standalone tool you run from the terminal. It's useful for pre-task research, one-off lookups, and any situation where you want to see exactly what's being fetched before handing it to Codex.
Install and authenticate:
npx -y firecrawl-cli@latest init --all --browser
export FIRECRAWL_API_KEY=fc-YOUR_API_KEYGet your key from firecrawl.dev/app/api-keys.
Live search with full-page content in one call:
firecrawl search "React 19 migration guide" --scrape --scrape-formats markdown --limit 3Codex cached mode returns a snippet with no content and no age indicator. Firecrawl returns live results plus full markdown for each page. Same query, very different output.
Time-filtered search for catching recent changes:
# Breaking changes shipped in the past week
firecrawl search "Next.js 15 breaking changes" --tbs qdr:w --scrape --scrape-formats markdown
# Past 24 hours for incident monitoring
firecrawl search "Vercel outage" --tbs qdr:d --type newsDomain-restricted search:
# Only results from nextjs.org
firecrawl search "app router middleware" --include-domains nextjs.org --limit 10Crawling when you don't know which page has the answer:
# Discover all URLs on a docs site first
firecrawl map https://nextjs.org/docs
# Then crawl what you need
firecrawl crawl https://nextjs.org/docs --limit 100After the dependency audit incident I described at the top, I started doing this before every major upgrade. Map the docs site. Crawl the relevant pages. Drop them into the Codex session as context. Zero stale data in the conversation.
Ready to try it? Sign up for Firecrawl free. Your first credits are included.
Option 2: Firecrawl MCP in Codex CLI
The Firecrawl MCP server is where Codex gains live search and full-page retrieval as built-in tools.
Instead of running searches manually, Codex calls Firecrawl autonomously as part of a task. The agent gains firecrawl_search, firecrawl_scrape, firecrawl_crawl, and more as native tools it can invoke on its own.
If you want to explore how Firecrawl MCP fits alongside other MCP servers for developers, that guide covers the full ecosystem.
The official GitHub repo has first-party support for Codex CLI configuration. For a broader comparison of web search MCP servers, including Tavily and Exa alongside Firecrawl, that post covers setup and trade-offs.
One-command setup:
codex mcp add firecrawl --env FIRECRAWL_API_KEY=fc-YOUR_API_KEY -- npx -y firecrawl-mcpOr add it manually to ~/.codex/config.toml:
[mcp_servers.firecrawl]
command = "npx"
args = ["-y", "firecrawl-mcp"]
[mcp_servers.firecrawl.env]
FIRECRAWL_API_KEY = "fc-YOUR_API_KEY"Verify it's active:
codex mcp list
# firecrawl should appearOptional but recommended: disable built-in search to avoid overlap:
web_search = "disabled"
[mcp_servers.firecrawl]
command = "npx"
args = ["-y", "firecrawl-mcp"]
[mcp_servers.firecrawl.env]
FIRECRAWL_API_KEY = "fc-YOUR_API_KEY"With this configured, here's what Codex handles autonomously:
"Check the React 19 upgrade guide and list any deprecated hooks"
Codex calls firecrawl_search + firecrawl_scrape, reads full docs, answers accurately
"Crawl the Prisma docs and find every page mentioning connection pooling"
Codex calls firecrawl_map, then firecrawl_crawl
"What changed in Tailwind v4 versus v3? Get the actual release notes."
Codex calls firecrawl_search with a time filter, returns current changelogs
The MCP server exposes 14 tools in total. The ones most relevant for development work:
| Tool | What Codex uses it for |
|---|---|
firecrawl_search | Web research, replaces built-in search |
firecrawl_scrape | Extracting a URL as clean markdown, including JS-rendered and SPA pages |
firecrawl_crawl | Indexing an entire docs site |
firecrawl_map | Discovering all URLs on a site |
firecrawl_extract | Pulling structured data with a JSON schema |
firecrawl_agent | Autonomous multi-page research |
Option 3: Firecrawl MCP in the Codex App
The Codex App reads the same ~/.codex/config.toml as the CLI. If you've already added the MCP config above, the App picks it up. No extra setup needed.
For those who prefer the UI path (similar to setting up Firecrawl MCP in Cursor):
- Open the Codex App
- Go to Settings then MCP Servers
- Add server: command
npx, args-y firecrawl-mcp - Add env var:
FIRECRAWL_API_KEYwith your key - Save and start a new session
Or you can simply use Firecrawl's streamable HTTP URL to set up the MCP client.
https://mcp.firecrawl.dev/{FIRECRAWL_API_KEY}/v2/mcp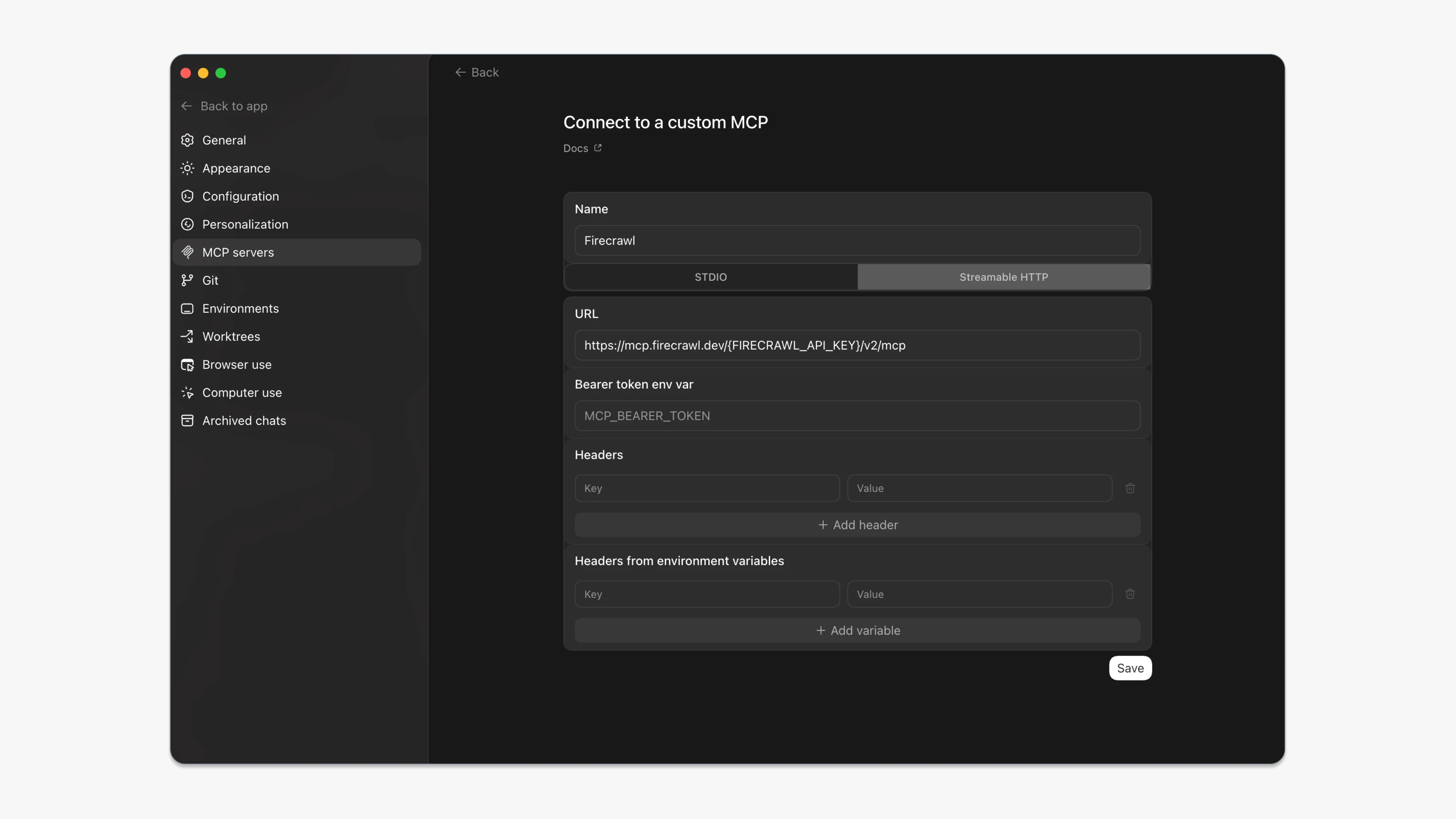
Once active, the App calls Firecrawl tools in the tool use panel during chat. You ask a research question. Codex calls firecrawl_search. Live results come back. Codex reads full-page content and answers from it.
The sandbox boundary still applies. Auth flows, signed-in pages, and browser cookies are off-limits for any search tool. Firecrawl's browser automation tools (firecrawl_browser_create, firecrawl_interact) handle those cases, but that's a separate setup.
Which approach should I use?
| Situation | What to use |
|---|---|
| Quick one-off research before starting a task | Firecrawl CLI |
| Codex needs to search during a running task | Firecrawl MCP in CLI config |
| Using the Codex App for chat-style workflows | Firecrawl MCP in App config |
| Crawl a full docs site before providing context | Firecrawl CLI |
| You want to see exactly what gets fetched | Firecrawl CLI |
| You want Codex to decide when to search | Firecrawl MCP |
I now run with web_search = "disabled" and Firecrawl MCP wired in. The quality difference on anything touching current docs or recent releases is significant. The dependency audit that opened this post takes about 30 seconds now. Codex searches live, scrapes the changelog, and tells me exactly what broke and when.
What does the full config look like?
Minimal Firecrawl MCP setup
[mcp_servers.firecrawl]
command = "npx"
args = ["-y", "firecrawl-mcp"]
[mcp_servers.firecrawl.env]
FIRECRAWL_API_KEY = "fc-YOUR_API_KEY"Full config with retry logic and credit monitoring
web_search = "disabled"
[mcp_servers.firecrawl]
command = "npx"
args = ["-y", "firecrawl-mcp"]
[mcp_servers.firecrawl.env]
FIRECRAWL_API_KEY = "fc-YOUR_API_KEY"
FIRECRAWL_RETRY_MAX_ATTEMPTS = "3"
FIRECRAWL_RETRY_INITIAL_DELAY = "1000"
FIRECRAWL_RETRY_MAX_DELAY = "10000"
FIRECRAWL_RETRY_BACKOFF_FACTOR = "2"
FIRECRAWL_CREDIT_WARNING_THRESHOLD = "1000"
FIRECRAWL_CREDIT_CRITICAL_THRESHOLD = "100"Codex native web search options
web_search = "cached" # default, OpenAI-maintained index
web_search = "live" # real-time results
web_search = "disabled" # use when Firecrawl MCP is handling searchShould you replace Codex's built-in search?
The sandboxed execution, the task-level reasoning, the ability to plan and run multi-step code changes: that's all good. But the default search setup hands the model a pre-indexed snapshot and no way to know how old it is. For anything time-sensitive, that's a liability.
Firecrawl CLI gives you live search from the terminal in two commands. Firecrawl MCP gives Codex live search, full-page content, and crawling as native tools it can call inside any task. Both work with the CLI and the App. Neither requires you to change how you use Codex, just what data it's working from.
Most search tools return links. Firecrawl returns the content. Start with the one-liner to add the MCP server, disable the built-in search, and run the same task that gave you wrong results before. The difference is immediate. For more ways to extend what Codex can do, the best Codex agent skills guide covers eleven skills worth installing alongside it.
Frequently Asked Questions
Does Codex search the live web by default?
No. Cached mode is the default. Codex queries an OpenAI-maintained pre-scraped index. To get real-time results, use the --search flag, set web_search = live in your config, or run with --yolo. You can also replace the built-in search entirely with Firecrawl MCP.
Why did Codex give me wrong information even with web search enabled?
There's a documented bug where web search escalation prompts don't fire when sandbox network access is restricted. Codex doesn't throw an error. It fabricates a response and presents it as a search result. Use live mode explicitly, or switch to Firecrawl MCP which makes network calls explicitly.
What's the difference between Firecrawl CLI and Firecrawl MCP?
Firecrawl CLI is a standalone tool you invoke yourself. You control what gets fetched, when, and how. Firecrawl MCP wires Firecrawl into Codex as native tools the agent calls on its own during a task. CLI gives control. MCP gives automation.
Can I use Firecrawl MCP and Codex's built-in search at the same time?
Yes, but it's cleaner to disable the built-in search. Set web_search = disabled in your config. That way Codex always uses Firecrawl's live, filterable search rather than falling back to the cache.
Does Firecrawl MCP work in both the Codex CLI and the Codex App?
Yes. Both read the same ~/.codex/config.toml. Add the MCP config once and both surfaces pick it up.
How much does Firecrawl search cost?
Search costs 2 credits per 10 results, rounded up. Adding scrapeOptions to retrieve full-page content adds 1 credit per page. Enhanced proxy or JSON mode adds 4 credits per page. A free tier is available.
