5 Best Perplexity Alternatives for AI Developers Building Research Tools in 2026

TL;DR - Best Perplexity alternatives
| Tool | Best for | Standout feature | Free tier |
|---|---|---|---|
| Firecrawl | Full web data stack for AI agents | Search, Scrape, Interact, Crawl — find sources, extract clean context, ship | 1,000 credits/month |
| Exa | Semantic research | Embedding-based search and "Find Similar" | 1,000 requests/month |
| Brave Search | Privacy-first high-volume search | Independent 30B+ page index, SOC 2 certified | 2,000 queries/month |
| Google Gemini | Multimodal research + Google ecosystem | Deep Research with NotebookLM and multimodal input | Free tier (limited) |
| ChatGPT | Conversational flexibility + integrations | MCP servers, voice/image input, iterative deep research | Free tier (limited) |
Perplexity delivers conversational AI search with citations, excelling at human-readable research summaries.
Developers building AI agents, RAG systems, and data pipelines often need structured data extraction, schema control, and predictable costs at scale. This guide explores five Perplexity alternatives built for developers who need structured extraction, autonomous research, and flat-rate pricing.
What is Perplexity: Quick overview
Perplexity is an AI-powered answer engine that synthesizes information from multiple sources into conversational responses with citations. Instead of returning search result links, it delivers direct answers optimized for human readability.
Main APIs:
- Search API: Raw web search results ($5 per 1,000 requests)
- Sonar API: Lightweight to advanced search models with grounding (Sonar, Sonar Pro, Sonar Reasoning Pro)
- Sonar Deep Research: Automated research reports ($0.41-$1.32 per query)
- Agent API: Access OpenAI, Anthropic, Google, and xAI models with web search tools
- Embeddings API: High-quality text embeddings for semantic search and RAG pipelines
Pricing: Dual pricing model combines token costs ($1-$15 per 1M tokens) with per-request fees ($5-$22 per 1,000 requests depending on search context and features).
Perplexity's conversational design and citation quality make it strong for human-facing AI applications. Developers building data pipelines, RAG systems, or AI agents often need alternatives that provide structured output formats, schema-based extraction, and predictable costs at scale.
What are the best Perplexity alternatives in 2026?
1. Firecrawl: Web context APIs for AI agents
Firecrawl searches, scrapes, and cleans the web for AI agents. It's built AI-first from the ground up — every output format, every endpoint, and every default is designed for what agents actually need, not retrofitted from a human-facing product.
While Perplexity synthesizes web results into conversational answers optimized for humans, Firecrawl returns full content from the live web. Agents get the raw material to reason on, not a pre-digested summary. With over a million developers using it and 130K+ GitHub stars, it's the default web data stack for production AI agents and workflows.
| Feature | Firecrawl | Perplexity |
|---|---|---|
| Primary use case | Web context APIs: Search, Scrape, Interact, Crawl | Conversational AI answers with citations |
| Output format | Token-efficient markdown, JSON (Pydantic/Zod) | JSON via response_format parameter |
| Schema support | Native Pydantic/Zod schema definitions | JSON Schema via response_format (with limitations) |
| Pricing model | Flat-rate: 1 credit = 1 page | Dual pricing: tokens + per-request fees |
| Best for | RAG systems, data pipelines, AI agents | Human-readable research summaries |
| Browser interact | Yes (/interact endpoint) | No |
| CLI | Yes (built-in Claude skill) | No |
What Firecrawl does differently
Full content, not snippets
Most search APIs return links and snippets that still need post-processing before they're useful in an agent context. Firecrawl's Search finds the relevant pages and returns their full content — clean, token-efficient markdown or structured JSON ready to use immediately.
Beyond standard web results, Search supports specialized source types: news for fresh coverage, github for repository and code searches, research for academic papers from arXiv and PubMed, and pdf for document searches — all returning full content in a single call.
Context-aware queries
Firecrawl supports a context parameter so agents can describe what they're actually trying to do, not just fire off a keyword query. Search bars were built for humans. Agents have more to say, and Firecrawl lets them.
Native structured output with schema control
While Perplexity supports structured output through the response_format parameter with JSON Schema constraints, Firecrawl is built schema-first. Define your data structure using Pydantic (Python) or Zod (Node), and Firecrawl's extraction engine returns clean JSON without additional configuration.
from firecrawl import Firecrawl
from pydantic import BaseModel, Field
from typing import List, Optional
app = Firecrawl(api_key="fc-YOUR_API_KEY")
class Founder(BaseModel):
name: str = Field(description="Full name")
role: Optional[str] = Field(None, description="Position")
background: Optional[str] = Field(None, description="Background")
class FoundersSchema(BaseModel):
founders: List[Founder]
result = app.scrape(
"https://anthropic.com/about",
formats=["json"],
json_options={"schema": FoundersSchema.model_json_schema()}
)
# Returns: {"founders": [{"name": "...", "role": "...", "background": "..."}]}The schema-first design means no manual JSON Schema construction, no concerns about recursive schema limitations, and extraction optimized for structured data from the ground up.
Multiple output formats
Firecrawl's Scrape endpoint returns content in the format your pipeline needs: markdown, html, json, links, screenshot, summary, or image. One call, your choice — no post-processing required.
Four endpoints that work together
- Search: Search the live web and get full content back immediately
- Scrape: Convert any URL into clean markdown or JSON
- Interact: Automate browser actions — click buttons, fill forms, navigate multi-step flows
- Crawl: Navigate entire sites without sitemaps
Firecrawl is also an official Claude plugin, integrating directly into Claude for AI-powered web research. The Firecrawl CLI, with a built-in Claude skill, is ideal for terminal-based workflows. It also integrates with no-code tools like Lovable and n8n — now with a native n8n Cloud integration for one-click connection.
Performance in independent benchmarks
An independent agentic search benchmark by AIMultiple evaluated 8 search APIs across 100 real-world AI/LLM queries, scoring 4,000 results for relevance, quality, and noise. Firecrawl ranked #2 with an Agent Score of 14.58. Perplexity ranked #7 at 12.96 — and with an average latency of 11+ seconds, it's a poor fit for interactive agent loops where response time compounds across multi-step tasks.
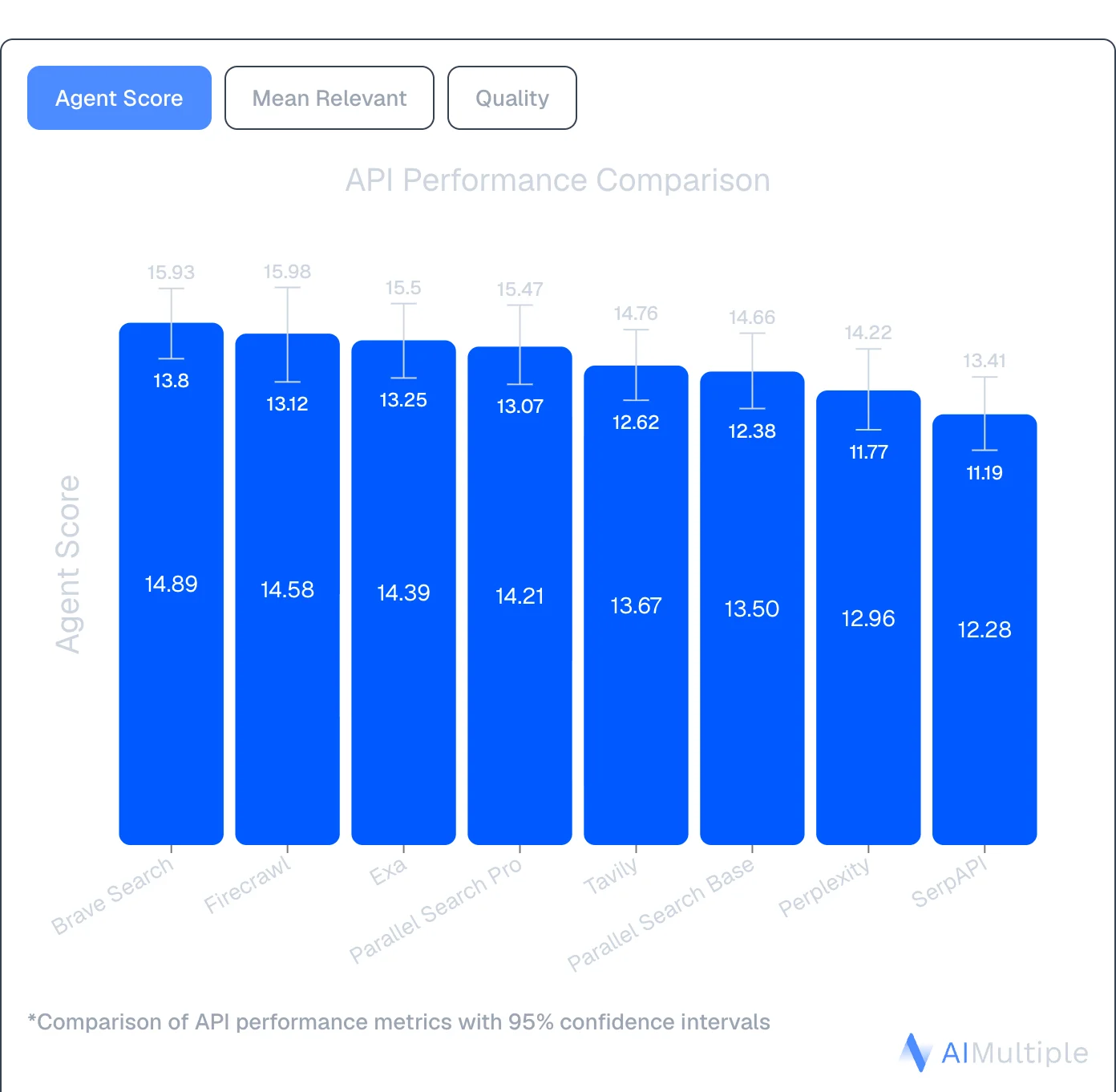
Source: AIMultiple Agentic Search Benchmark 2026
When to choose Firecrawl over Perplexity
- The full workflow in one API: Search finds fresh sources, Scrape turns them into token-efficient context, Interact handles dynamic pages, Crawl goes deep across sites — Find → Extract → Clean → Use
- RAG systems that need clean markdown or JSON for vector databases
- AI agents that need full-content results from the live web — no snippets, no pre-digestion
- Data pipelines that extract specific fields at scale (pricing, contacts, features)
- Training datasets that require structured, high-quality web data
- Production applications where budget predictability and API reliability matter
Independent benchmarks show Firecrawl's 80.9% coverage and 0.68 F1 score outperform alternatives, delivering cleaner data with less noise. For teams that need extraction depth, schema control, and cost certainty, Firecrawl eliminates the parsing overhead.
2. Exa
Exa is a semantic search engine built specifically for AI applications. Unlike keyword-based search, Exa uses neural embeddings to understand meaning and context, making it strong for discovery-oriented research where phrasing varies and relevant sources may not contain exact query terms.
| Feature | Exa | Perplexity |
|---|---|---|
| Search method | Neural embeddings-based semantic search | LLM-powered synthesis with web search |
| Unique capability | Find Similar for discovering related content | Deep Research for comprehensive reports |
| Pricing model | Variable credit consumption | Dual pricing: tokens + requests |
| Best for | Content discovery, research exploration | Human-readable summaries |
What Exa does differently
Semantic search for AI agents
Exa pioneered embeddings-based search that understands meaning rather than matching keywords. This approach excels when you need to discover conceptually similar content, even when sources use different terminology.
The platform offers three search modes:
- Auto: Intelligently switches between neural and keyword search
- Neural: Semantic understanding for context-based discovery
- Fast: Quick responses for straightforward queries
Find Similar for discovery workflows
Exa's Find Similar API lets you provide one URL and discover 20 semantically related pages. This is particularly useful for AI agents building knowledge graphs or exploring research topics by following conceptual connections rather than explicit links.
Pricing considerations
Exa uses a credit-based model where consumption varies by query complexity. The pricing structure includes:
- Free tier: $10 in credits
- Research tier: $5 per 1,000 operations
- Pro tier: $10 per 1,000 page reads
For developers processing high volumes, the variable credit model can make cost forecasting challenging compared to flat-rate alternatives.
Performance benchmarks
In independent scrape-evals, Exa achieved:
- Coverage: 76.3%
- F1 score: 0.53
While Exa excels at semantic discovery, its extraction quality shows room for improvement when building datasets that require complete, clean data.
When to choose Exa over Perplexity
Choose Exa when your workflow centers on content discovery and semantic exploration rather than direct answer generation. It's particularly suited for:
- Research discovery where you need to find related papers or articles
- Semantic search applications that benefit from meaning-based ranking
Exa's semantic search capabilities complement tools like Firecrawl - use Exa to discover relevant URLs, then feed them to extraction APIs for structured data gathering. For projects requiring deep data extraction or predictable costs at scale, consider pairing Exa's discovery strengths with dedicated extraction tools.
Read our detailed Exa alternatives comparison for more.
3. Brave Search
Brave Search is a privacy-first search engine built on an independent index of 30+ billion pages. Unlike search engines that rely on Google or Bing, Brave crawls and ranks the web itself, making it particularly suited for developers building privacy-focused applications or high-volume search systems.
| Feature | Brave Search | Perplexity |
|---|---|---|
| Search index | Independent (30B+ pages) | Aggregated from multiple sources |
| Privacy | SOC 2 Type II, no tracking or profiling | Standard data handling |
| Pricing | $3-$5 per 1,000 requests | $5-$22 per 1,000 requests (plus token costs) |
| Rate limits | Up to 50 requests/second | 5 requests/second |
| Best for | High-volume queries, privacy-centric apps | Research summaries with citations |
What Brave Search does differently
Independent index with privacy guarantees
Brave Search doesn't build user profiles, track queries, or sell data. SOC 2 Type II certification provides verifiable privacy guarantees - important for applications handling sensitive queries in healthcare, legal, or financial domains.
Search Goggles for custom ranking
The Goggles feature lets developers create custom ranking filters to modify search results. Build tailored search experiences for specific domains or user needs without forking an entire search engine.
When to choose Brave Search over Perplexity
Choose Brave Search when privacy, transparency, and high-volume capacity matter more than conversational synthesis. It's particularly suited for:
- Privacy-centric applications requiring verifiable data handling guarantees
- High-volume search workloads (1000+ queries/day) needing predictable costs
- Custom search experiences using Goggles for domain-specific ranking
For developers needing raw search results rather than synthesized answers, Brave Search's independent index and privacy architecture offer a compelling alternative at a lower cost structure.
4. Google Gemini
Google Gemini is Google's multimodal AI platform that natively understands text, images, audio, video, and code. Developed by Google DeepMind, Gemini 3 (launched November 2025) combines deep research capabilities with creative and analytical workflows.
| Feature | Google Gemini | Perplexity |
|---|---|---|
| Research feature | Deep Research with NotebookLM | Deep Research with citations |
| Model options | Fast (2.5 Flash) and Thinking (3 Pro) | Sonar, Sonar Pro, Deep Research |
| Output formats | Text, images, videos, presentations | Text with citations |
| Pricing | Free; Pro $20/month; Ultra $124.99/month | Free; Pro from $17/month; Max from $167/month |
What Gemini does differently
Multimodal research workflows
Gemini processes and generates across text, images, audio, and video - not just text. Upload documents or images alongside queries for analysis that combines visual understanding with web search grounding.
NotebookLM for source-based research
NotebookLM lets developers upload sources and generate citation-backed insights, summaries, and study guides. The platform converts sources into audio overviews, mind maps, flashcards, and presentations - useful for educational or training applications.
Google Search integration
Native Google Search grounding provides real-time web data with inline citations linking claims to source articles.
When to choose Gemini over Perplexity
Choose Gemini when research involves multimodal content or requires Google Workspace integration. Best for:
- Multimodal AI applications processing images, videos, and documents
- Google ecosystem integration (Gmail, Docs, Drive)
5. ChatGPT
ChatGPT is OpenAI's conversational AI platform, first launched in November 2022. With GPT-5 powering the latest models, ChatGPT offers deep research capabilities, web browsing, and multimodal interactions across text, images, and voice.
| Feature | ChatGPT | Perplexity |
|---|---|---|
| Research feature | Deep Research (multi-step, iterative reports) | Deep Research (comprehensive reports) |
| Multimodal | Text, image, voice input/output | Text-based |
| Integration | MCP servers, Apps SDK, third-party plugins | API access |
| Pricing | Free; Plus $20/month; Pro $200/month | Free; Pro from $17/month; Max from $167/month |
What ChatGPT does differently
Multimodal interactions
Upload images or speak questions and receive unified responses across modalities - useful for applications requiring visual analysis alongside text research.
ChatGPT Atlas browser integration
Introduced October 2025, ChatGPT Atlas embeds AI assistance directly into web browsing, summarizing content and incorporating context from past conversations.
MCP servers and extensibility
Native support for MCP servers and the Apps SDK enables integration with third-party services, useful for developers building AI agents that interface with external tools.
When to choose ChatGPT over Perplexity
Choose ChatGPT when conversational flexibility and ecosystem integrations matter more than specialized research features. Best for:
- Multimodal applications requiring image/voice alongside text
- Third-party integrations using MCP servers or Apps SDK
- Familiar developer experience with established OpenAI ecosystem
Conclusion: Choosing your Perplexity alternative
Perplexity excels as a deep research API at conversational answers with citations.
If you need the full web data stack, Firecrawl delivers fresh, full-content results from the live web — not pre-digested summaries. Built AI-first with over a million developers and 130K+ GitHub stars, it covers Search, Scrape, Interact, and Crawl in one API at $83 for 100K pages.
Try Firecrawl free with 1,000 credits per month (no card required) or explore the docs.
For semantic discovery, privacy-first search, or multimodal workflows, the alternatives above provide specialized capabilities. Choose based on whether you need structured data extraction, conversational synthesis, or semantic exploration — and the cost model that aligns with your production volume. For a broader comparison of all leading search tools for AI agents — including Serper, SERP API, and Perplexity Sonar side by side — see the full guide. If you're building specifically with Claude, the Anthropic web search alternatives guide covers Claude-specific search integrations.
Frequently Asked Questions
What's the main difference between Perplexity and its alternatives?
Perplexity focuses on conversational answers with citations, optimized for human readability. Alternatives specialize in different areas: Firecrawl for the full web data stack (Search, Scrape, Interact, Crawl) built AI-first, Exa for semantic search and discovery, Brave Search for privacy-first high-volume queries, and Gemini/ChatGPT for multimodal capabilities.
Why look for Perplexity alternatives?
The main reasons are output type, search quality, and pricing. Perplexity synthesizes answers for humans — developers building agents and pipelines often need full-content results, schema-based extraction, and predictable flat-rate costs. Firecrawl returns full-content results from the live web so agents get signal-rich content rather than pre-digested summaries. Perplexity's dual pricing model (tokens + requests) also makes budgeting harder at scale.
Can these alternatives handle structured data extraction?
Yes. Firecrawl is built specifically for structured extraction with native Pydantic/Zod schema support, returning clean JSON without manual parsing. Perplexity supports structured output through the `response_format` parameter with JSON Schema configuration, though subject to the same truncation issues documented in community forums.
Which alternative is best for RAG applications?
Firecrawl is a strong choice for RAG: it pulls full-content results from the live web, so the context going into your pipeline is fresh and signal-rich rather than pre-synthesized summaries. Native schema support (Pydantic/Zod), 80.9% coverage and 0.68 F1 in benchmarks, LangChain and LlamaIndex integrations, and flat pricing make it purpose-built for high-volume ingestion workflows.
Do these alternatives offer free tiers?
Yes. Firecrawl offers 1,000 free credits per month. Brave Search provides 2,000 queries monthly. Exa includes $10 in free credits. Gemini and ChatGPT offer free tiers with limited features. Perplexity also has a free tier with limited Pro searches.
Which tools support native AI framework integration?
Firecrawl, Exa, and Brave Search all offer integrations with LangChain and other AI frameworks. Firecrawl provides native adapters for both LangChain and LlamaIndex, making implementation straightforward for existing AI applications.
