Introducing Firecrawl Research Index: a specialized index for agentic AI/ML research
AI/ML research moves fast, and the work that matters is split between new papers and the code that implements them. Most search providers omit or misrank key papers, leaving you to review sources by hand without ever being sure you've caught everything.
Today we're launching Firecrawl Research Index, a specialized index for agents pushing the frontier of AI/ML research. It gives agents the entire AI/ML literature and the code behind it, plus the tools to turn them into answers — agents retrieve the right papers, verify claims against full text, and pull code for implementation autonomously.
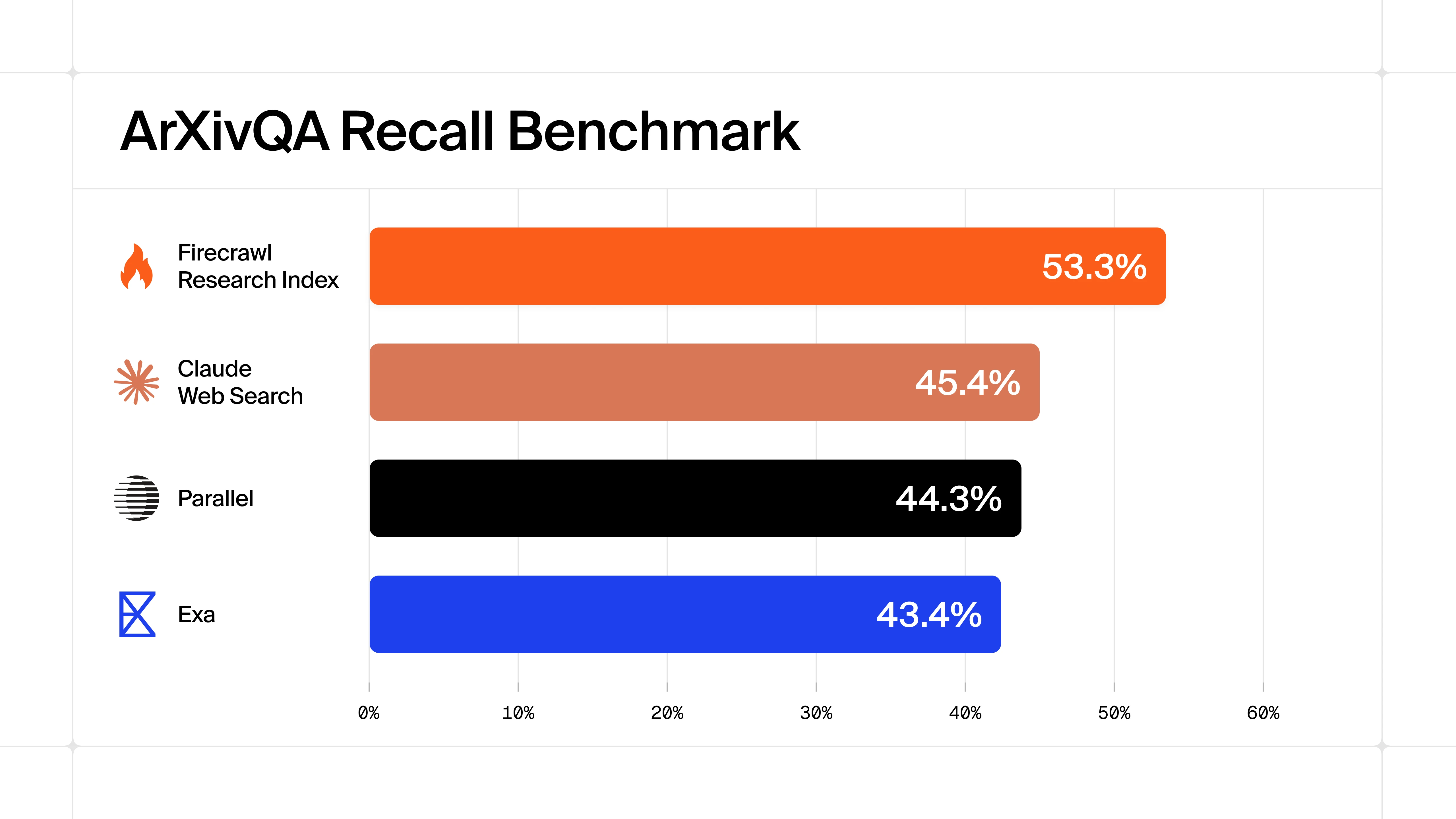
On arXivQA, the index has state-of-the-art recall, 18% above the next best provider at similar cost. It also scores 0.750 MRR, meaning the correct paper lands in the top two results.
How the Firecrawl Research Index makes agentic deep research easier
Highest recall, at comparable cost
On arXivQA, the index hits 53.3% recall at $0.32 per task, against 45.4% for the next best provider. Your agent works from a fuller set of papers without paying a premium.
Aemon (YC W26), which builds autonomous AI research engineers, saw the same pattern in their own benchmark of scientific and technical retrieval systems:
Aemon is building autonomous AI research engineer that solve hard scientific and technical problems. To do that, our systems must continuously learn from the frontier of research—papers, implementations, benchmarks, and technical discussions across the web.
We use Firecrawl Research as part of the retrieval stack behind Aemon. In our internal benchmark of scientific and technical retrieval systems, it delivered the strongest recall of any provider we tested, particularly at deeper search depths where comprehensive coverage is critical. Firecrawl consistently surfaced relevant scientific and technical sources that would otherwise have been missed.
— Ray Xu, Co-Founder, Aemon (YC W26)
Surface the right source first
On arXivQA, the index scores 0.750 MRR, meaning the correct paper lands in the top two results. Higher MRR means fewer wasted tokens before an agent finds what it actually needs.
Search millions of papers alongside their code
The index includes all 3M+ arXiv papers, plus GitHub artifacts from top research repos (issues, merged PRs, READMEs), refreshed daily so agents always stay current.
A complete toolset for research loops
The built-in toolset lets agents run research end-to-end — retrieving the right papers, verifying claims against full text, and pulling code. Agents can go from literature to implementation in one query, with no manual filtering, cross-referencing, or review required.
What you can use it for
- Power your research platform's search: Plug in the index, and your platform ships state-of-the-art search across millions of papers and the code behind them.
- Autonomous research agents: Your agent finds the most relevant papers and code for its problem, follows citations, and verifies against full text before it builds on them. An agent tuning a training run overnight could pull an optimizer from a recent paper and a stability fix from a related GitHub issue, then test both in its next experiment.
- Literature reviews and discovery: Find the relevant work on any topic, including papers published this week. Then start from your best hit and surface its references, citers, and related work, reaching papers a keyword search misses.
Methodology
We benchmarked on roughly 200 queries from alphaXiv's ArXivQA, each labeled with up to 10 ground-truth arXiv IDs. To measure recall, we let Opus 4.8 run each provider through its MCP and SKILL.md, then scored the papers it surfaced against those labels.
Availability
Firecrawl Research Index is available now in the API via /search/research, plus the CLI, MCP, and SDKs. It plugs into any harness you already run, including Codex, Claude Code, and Grok Build.
