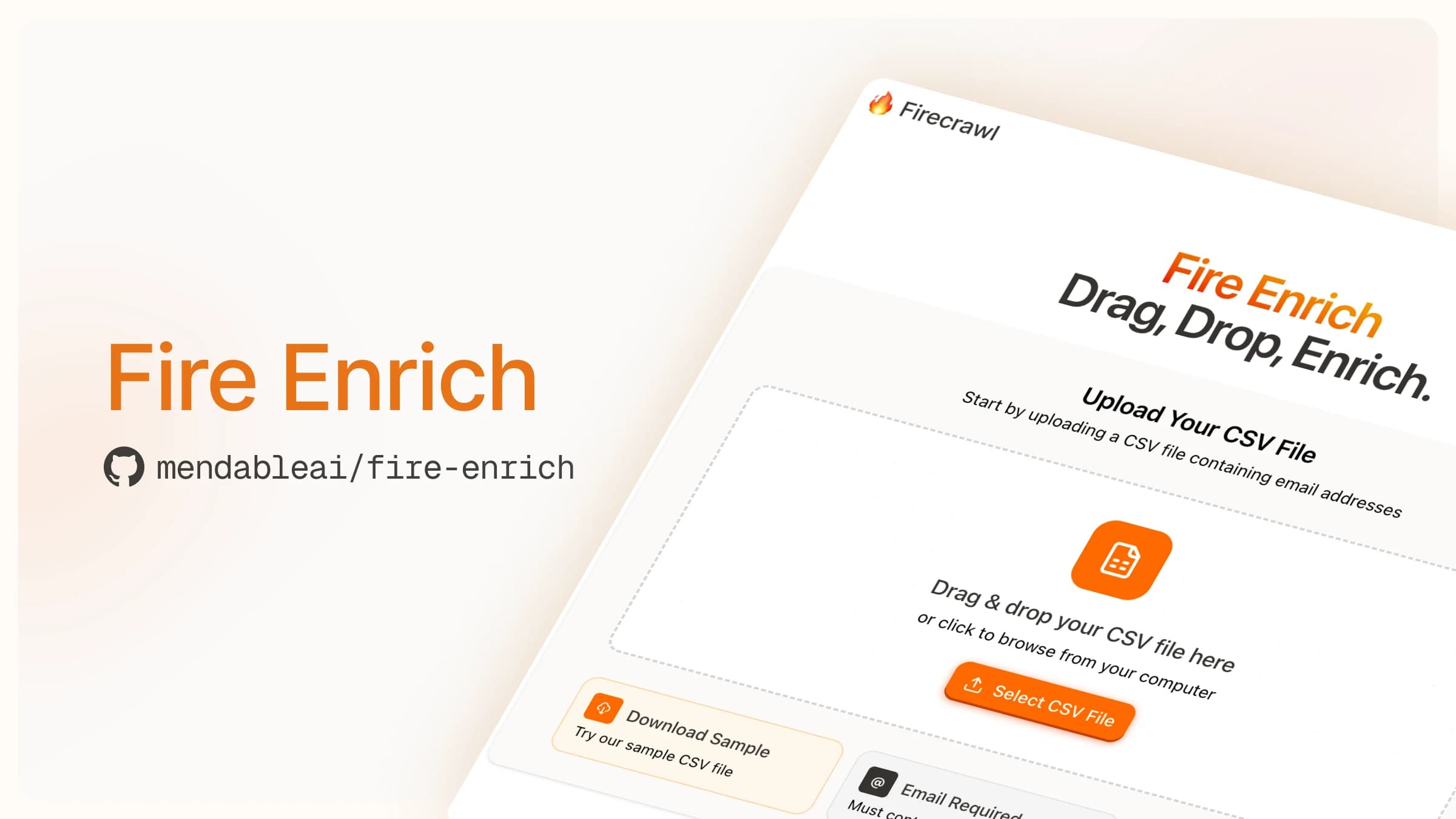
Fire Enrich: What You Need to Know About Our Open Source Data Enrichment Tool
Every sales, marketing, and data team knows the struggle. You have a list of leads - a simple CSV with emails - but it's just the tip of the iceberg..
To do your job effectively, you need context. What does their company do? How big is it? What industry are they in?
To get this data, one might typically turn to expensive data enrichment services. Platforms like Clay and others are great, but their pricing can be a significant barrier for startups, indie developers, or teams just looking to run a quick analysis. They can also feel like a black box, where data goes in and enriched data comes out, with little transparency into the process.
We saw this and asked ourselves: What if we could build a powerful, transparent, and open source alternative?
This is the story of Fire Enrich.
Drag, drop, enrich. Simple.
Fire Enrich is the first tool we're highlighting from our new open source AI toolbox. It's a deceptively simple application:
- Upload a CSV containing email addresses
- Choose the fields you want to find (e.g., company description, industry, employee count, etc.)
- Watch it work in real time as it populates your table with fresh, relevant data
But behind this simple UI is a sophisticated system designed to mimic the research process of a human analyst, powered by Firecrawl for web scraping and OpenAI for intelligent data extraction.
How it works: A team of AI specialists
Fire Enrich isn't just running a simple search-and-extract script. It deploys a team of specialized AI agents, each an expert in its domain.
When you ask for "industry" and "funding stage," you're not just sending one prompt to an AI. You're activating:
- The Company Research Agent: Tasked with finding fundamentals like industry, location, and company size
- The Fundraising Intelligence Agent: Programmed to hunt for funding rounds, investment amounts, and key investors
- The People & Leadership Agent: To identify founders and key executives
- The Product & Technology Agent: To uncover the company's tech stack and main products
This multi-agent system enables more accurate, domain-specific searches and higher-quality data extraction. You can see the entire process, including the source URLs for every piece of data, offering full transparency.
Real-time processing with complete transparency
Unlike competitors that rely on static databases, Fire Enrich researches each company fresh when you need the data. This approach offers several advantages:
Live updates: The platform streams results as they're discovered using server-sent events. You watch each field populate in real-time.
Source attribution: Every piece of data includes the source URL where it was found. You can verify any data point and meet compliance requirements.
Fresh data: We find recent funding announcements, leadership changes, and updated company information that static databases miss.
According to recent survey data, companies report 11-30% increases in conversion rates after implementing data enrichment.
Built for transparency and extensibility
Professional data enrichment services are expensive for a reason. Building and maintaining these systems is complex. Our goal with Fire Enrich isn't to replicate every feature of mature platforms overnight.
Instead, we want to build a powerful, open source foundation that anyone can use, understand, and contribute to.
Open source advantage: Fire Enrich is open source on GitHub with over 1,100 stars. You can inspect the code, modify agents for specific use cases, and contribute improvements.
No limits when self-hosted: The public demo limits you to 15 rows and 5 columns to manage costs. When you run Fire Enrich locally, these restrictions disappear.
Cost comparison:
| Tool | Starting Price | Approach |
|---|---|---|
| Clay | $149/month | Multi-source aggregator, requires separate subscriptions |
| Apollo | $59/user/month | Built-in database, limited customization |
| Fire Enrich | Free (self-hosted) | Real-time research, only pay API costs |
When self-hosting, you only pay for OpenAI API usage (typically $0.01-0.05 per enrichment).
Fire Enrich continues to evolve
This is just the start. The version you see in this repository is our first major step. It works, it provides value, but we know there's room to grow. By open sourcing it, we're inviting the community to join us on this journey.
- Want to add a new specialized agent? Fork the repo and show us what you've got
- Think the data extraction prompt can be improved? Open a pull request
- Have an idea for a new feature? Start a discussion in the issues
We believe that by building in public, we can create a tool that is not only accessible and affordable but also robust and adaptable, largely owing to the collective intelligence of the open source community.
We built Fire Enrich with extensibility at its core. Whether you want to swap in your own services, integrate different APIs, or customize the data extraction logic, we've made it easy to adapt the tool to your specific needs.
Get started today
We invite you to explore Fire Enrich. See what it can do, and then dive into the code to see how it's done.
- Try the tool: Fire Enrich Demo
- Explore the code: View on GitHub
Self-hosting setup:
git clone https://github.com/firecrawl/fire-enrich.git
cd fire-enrich
npm install
npm run devYou'll need OpenAI and Firecrawl API keys, plus Node.js 18+.
Real-world applications:
- Sales teams enrich trade show leads with company data and key contacts
- Marketing teams score inbound leads with firmographic information
- Consulting firms analyze competitive landscapes with industry data
