TL;DR
- LLMs hallucinate because pretraining optimizes for fluency not truth, training data encodes the web's noise, benchmarks reward guessing over honesty, and RLHF bakes in agreeableness. Bigger models shift where failures occur, not how often.
- Two hallucination types matter for agents: stale-data (the model's snapshot is outdated) and confabulation (the model invents plausible detail to fill a gap). Both are reduced by real-time retrieval.
- Static RAG goes stale between re-indexing runs and is limited to ingested content. Live web retrieval fetches at query time, across the open web, with no corpus to maintain.
- Retrieval quality determines whether grounding actually works. Intent-matching search returns excerpts already filtered to the question. Dense, token-efficient output reduces context noise that pushes models toward training-data fallback. Freshness controls ensure "live" retrieval is actually live.
- Web-grounded systems show 25 to 40 percentage point accuracy improvements on SimpleQA and FRAMES over ungrounded baselines.
- Firecrawl's
/searchendpoint finds sources and returns token-efficient Markdown from live pages in one call.
I was an hour late to an interview because I relied on an LLM to convert time. It was March, and I searched "11 am EST to Nigerian time." The model returned 5 pm. I blocked my calendar and showed up an hour late.
The US had already switched to EDT. The model didn't know. This is an example of stale-data hallucination, where the model retrieved something that was once true but no longer is.
Developers experience this at scale when agents need live data: stock prices, exchange rates, seasonal data, and job listings. Without grounding, hallucination rates on factual queries run between 15 and 25 percent. At that rate, roughly one in six answers to a factual question is wrong enough to matter. Real-time web data reduces this risk, but only if the agent knows when to search, what to search for, and how to ground it.
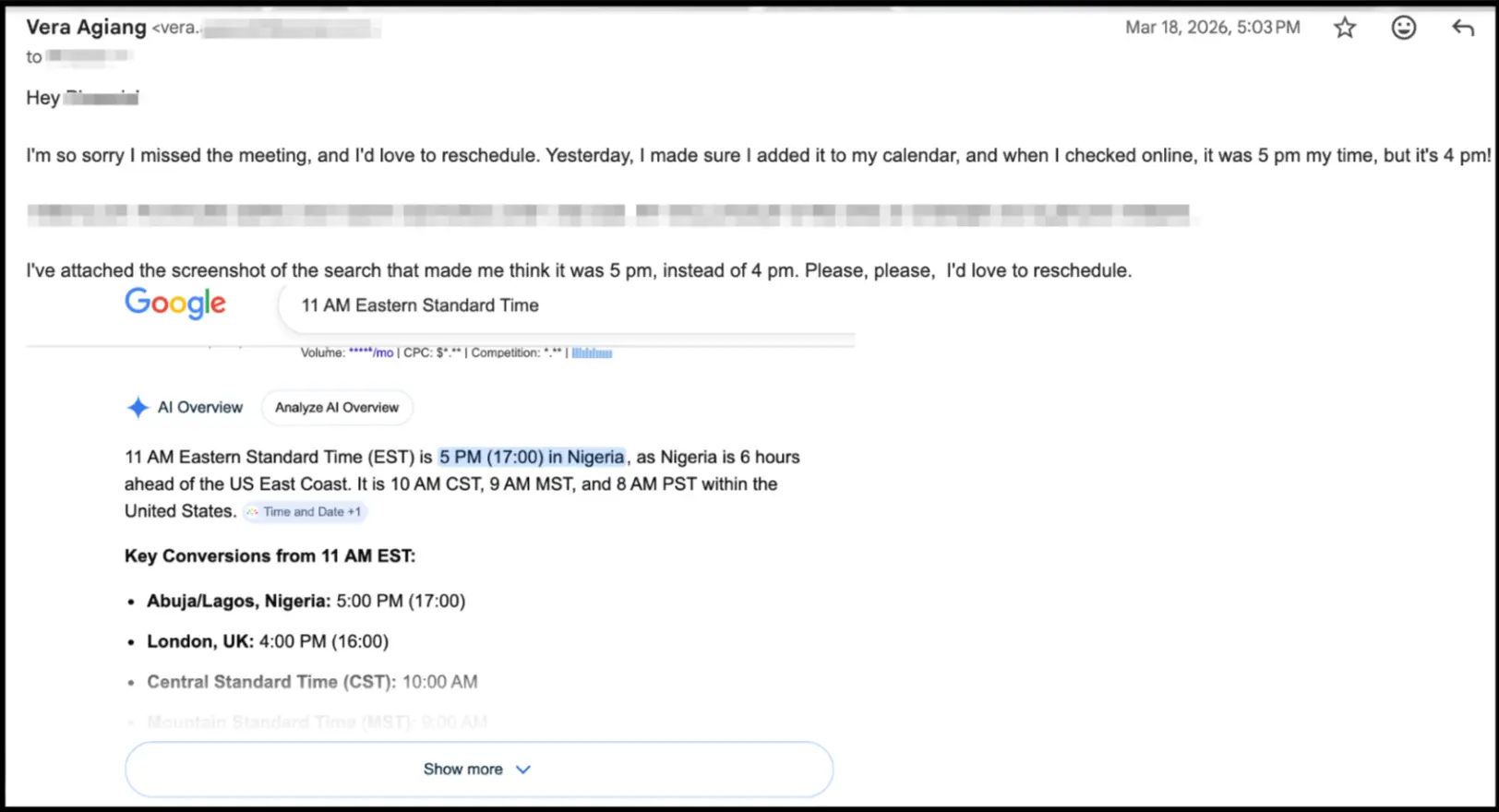
Google's AI Overview confidently returned 5 PM Nigeria time for 11 AM EST in March 2026. The US had already moved to EDT, making the correct answer 4 PM. The model answered accurately for the wrong timezone.
Why LLMs and AI agents hallucinate
LLMs do not recall facts. They generate statistically plausible text. That distinction between retrieval and generation is the origin of nearly every hallucination.
Pretraining optimizes for fluency, not truth
The core training process for large language models is next-token prediction: given a sequence of text, predict what comes next. The training signal is fluency. There are no labels in the training data distinguishing true statements from false ones.
Kalai, Nachum, Vempala, and Zhang (2025) frame this as a binary classification failure at pretraining. The model sees only positive examples of fluent text; there are no labels marking statements as false. For arbitrary, low-frequency facts (a specific person's birthday, a niche regulatory requirement, the output of a rarely-cited study), the model cannot learn the answer from distributional patterns. It generates something plausible, and at a predictable rate, that something is wrong.
Hallucinations on well-documented, high-frequency facts improve with scale. Hallucinations on specific, verifiable, low-frequency facts are persistent and scale-resistant: bigger models shift where failures occur, not how often.
Training data encodes the web's noise
The model can only reproduce what it learned, and what it learned came from the open web. Web-scale training corpora are not curated for accuracy. Academic papers and primary sources sit alongside Reddit threads, opinion blogs, and content that was written to rank rather than to inform. The model has no mechanism to assess source credibility or weigh conflicting claims.
Duke University researchers describe this as the GIGO problem applied to LLMs. When a false claim circulates widely enough across the training corpus, the model learns to reproduce it with the same statistical confidence it applies to well-documented facts.
This compounds in specialized domains. Medical misinformation, outdated legal interpretations, and superseded regulatory guidance all exist in abundance on the public web. Without domain-specific curation or retrieval from authoritative sources at query time, a model absorbs that noise alongside reliable content.
Benchmarks reward guessing over honesty
Even if training data were clean, evaluation incentives would still drive models toward hallucination. This is the central finding of Kalai et al. (2025), co-authored with OpenAI researchers: most benchmarks measure accuracy, the percentage of questions answered correctly, without distinguishing confident wrong answers from honest admissions of uncertainty. That asymmetry rewards guessing.
Consider a model that does not know someone's birthday. Guessing "September 10" yields a 1-in-365 chance of being right. Saying "I don't know" guarantees zero. Across thousands of benchmark questions, the guessing model climbs the leaderboard. Benchmark rankings, which directly shape which models get deployed, reward it for hallucinating.
OpenAI published empirical data from SimpleQA evaluations that makes this explicit:
| Model | Abstention rate | Accuracy | Error rate |
|---|---|---|---|
| gpt-5-thinking-mini | 52% | 22% | 26% |
| o4-mini | 1% | 24% | 75% |
o4-mini almost never abstains and achieves a marginally higher accuracy score. Its error rate is 75%: nearly three-quarters of its responses are wrong. gpt-5-thinking-mini abstains when uncertain and cuts the error rate to 26%, at a minor accuracy cost. On an accuracy-based leaderboard, o4-mini ranks higher. On the metric that matters to users (whether the answer is actually correct), it is far worse. Without evaluation systems that reward "I don't know," models default to generation over honesty, and confidence scores give users no reliable signal about when to trust the output.
RLHF trains for agreeableness, not accuracy
After pretraining, models are refined using reinforcement learning from human feedback (RLHF). Human evaluators rate responses, and the model learns to produce outputs humans prefer. The problem: humans consistently rate confident, direct, agreeable responses higher than hedged or uncertain ones, even when the confident answer is wrong. When ChatGPT-4o launched, OpenAI had to roll back an update after widespread criticism that the model validated users' ideas even when clearly incorrect. The mechanism is not model-specific: RLHF encodes whatever preference signal it receives, and that signal consistently rewards sounding helpful over being accurate.
The result is a model shaped to give direct answers, sound certain, and agree rather than correct. When faced with a factual question it cannot reliably answer from training, it generates something plausible and confident, not because it is deceiving you, but because that is what the training pipeline selected for.
Knowledge cuts off and thins out
Every LLM's knowledge freezes at its training cutoff, often months before release. Grounding addresses this directly by injecting live context at query time, but poor grounding creates its own failure modes:
- Retrieval returns a handful of documents and misses relevant data spread across hundreds of others
- Vector search surfaces results that look similar but do not actually answer the query
- When no useful evidence exists, the model generates anyway instead of refusing
Each failure produces the same output: a confident, plausible, wrong answer.
The cutoff is a temporal problem. There is a separate domain problem that is harder to see. Web-scale training data is not uniformly distributed: high-traffic content dominates, and specialized industry domains, regional regulatory frameworks, and niche technical standards are underrepresented from the start. A model with a recent cutoff still hallucinates on long-tail topics, not because the knowledge is stale, but because it was never well-covered in training. Larger models reason better over knowledge they have; they cannot recover knowledge that was absent.
These require different mitigations. Temporal staleness is addressed by live retrieval. Domain staleness requires retrieval from authoritative sources in that domain, or fine-tuning on domain-specific data.
What are the two main types of agent hallucinations?
Every agent hallucination has a root: either the model is working from outdated information, or it is filling a gap with something it invented. Most reliability problems in production trace back to one of these two.
Stale-data hallucinations
The model "knows" the answer. It learned it during training, but the world has moved on. Prices change, APIs deprecate parameters, documentation gets updated, events resolve. The model does not know any of that. It answers from the snapshot it was given.
The opening example is a stale-data hallucination. The model correctly knew the EST-to-Nigeria offset. It did not know the US had switched to EDT. It answered with full confidence and was wrong by exactly one hour.
This shows up everywhere agents touch live data:
- A pricing agent quotes a plan that was discontinued last quarter
- A developer agent suggests an API parameter that was removed in the latest SDK version
- A research agent cites a study that has since been retracted
- A booking agent confirms availability for a date the system now shows as blocked
The fix is retrieval: replace the model's frozen snapshot with live information fetched at query time. Stale-data hallucinations are straightforwardly solvable once the agent has access to current sources.
Confabulation
Confabulation is harder. The model has no answer: the fact was sparse in training data, too recent, or too niche. So it generates something plausible to fill the gap. It does not signal uncertainty. It produces a coherent, confident, wrong answer.
Examples in agent contexts:
- Citing a paper that does not exist, with a plausible title, journal, and year
- Inventing a feature flag that sounds real, using the product's naming conventions
- Describing an API method that the library never shipped
- Filling in specific numbers (success rate, latency, pricing) that no source ever stated
Confabulation is harder to detect than stale data because the output looks correct. The structure is right, the style matches, and the detail is specific enough to seem authoritative. It fails only when checked against an authoritative source.
Real-time retrieval gives the model an answer to work from rather than a gap to fill: when a source exists, the model extracts rather than invents. When no source is found, a pipeline that blocks generation on missing results turns confabulation into an explicit "I don't know."
Web search APIs as a grounding layer for LLMs and AI agents
Static training data is the root of most agent hallucinations on factual queries. Web search replaces that static snapshot with live retrieval at query time. But connecting an agent to a search API is not the same as grounding it. Retrieval introduces its own failure modes: wrong sources, noisy context, truncated evidence, and unverified citations.
Firecrawl is the context API to search, scrape, and interact with the web at scale: Search, Scrape, Interact, Map, Crawl, and Parse. They handle the Find → Extract → Clean step: finding sources, pulling content, and returning it as clean, structured context. All outputs are token-efficient Markdown, stripped of navigation, ads, and boilerplate, so agents work with denser, more useful context per token compared to raw HTML.
Static RAG vs. live web retrieval
Static LLM grounding via RAG works well for stable, controlled data: internal documentation, product manuals, and policy documents are good candidates. For agents that need current or external information, it has three specific limitations:
- Freshness: Your indexed content goes stale between re-indexing runs. A model answering questions about pricing, regulatory changes, or competitor features is reasoning over a snapshot, not current state.
- Coverage: You can only retrieve what you have already ingested. Anything outside your corpus is invisible to the agent.
- Maintenance: Someone has to curate, update, and re-index that corpus. The burden compounds as the domain grows.
Live web retrieval solves all three by fetching content at query time across the open web. You trade millisecond vector queries for 1-3 second search latency and add the need to filter out irrelevant or low-quality results. For queries where freshness or coverage is the constraint, that tradeoff is straightforwardly worth it.
| Static RAG | Live Web Retrieval | |
|---|---|---|
| Freshness | Stale between re-index runs | Current at query time |
| Coverage | Limited to ingested content | Open web |
| Latency | Milliseconds | 1-3 seconds |
| Maintenance | High (corpus curation) | Low (search infrastructure) |
| Noise filtering | Controlled by corpus quality | Required at retrieval time |
Most production agents use a hybrid approach: a pre-indexed store for stable internal content, live web retrieval for anything time-sensitive or external. The routing decision between them is the first thing to get right.
What retrieval quality actually determines
Not all retrieval reduces hallucinations equally. What matters is how results are matched, what format they come in, and whether they are actually current.
A search API built for agents takes a natural-language objective and returns excerpts already filtered to the question. Traditional keyword search finds pages containing the terms; semantic search finds pages that answer the underlying question. That distinction determines the quality of what enters the model's context.
Context quality matters as much as retrieval itself. Stuffing full pages into context adds noise: navigation, ads, boilerplate. When noise crowds out the relevant signal, the model falls back on training data to fill gaps and fabricates. Token-efficient Markdown strips that out, so each token carries more useful signal.
The third variable is freshness. A search API can return a page cached three months ago, reintroducing the same staleness that live retrieval is meant to solve. For pricing, regulatory changes, or breaking events, freshness filtering by publish date and live-crawl options are what make "live retrieval" actually live.
How much does grounding actually reduce hallucinations?
The accuracy gains from grounding are measurable. On SimpleQA (factual recall on direct questions) and FRAMES (multi-hop reasoning across sources), web-grounded systems show 25 to 40 percentage point accuracy improvements over ungrounded baselines. The gains are largest on queries that require current information or cross-referencing multiple facts, exactly the cases where training data alone is most likely to produce a confident wrong answer.
Stanford AI Playground uses Firecrawl's Search and Scrape endpoints to ground LLM responses with live web data for the Stanford University community. Before live retrieval, responses were bounded by training cutoffs. Now the system processes around 800 real-time sources daily across 10,000+ domains, scholarship databases, news outlets, government resources, and academic repositories, with no scraping infrastructure to maintain.
Coverage grew from 293 URLs in September 2025 to over 13,000 by February 2026, a 46x increase in six months. Search latency averages 1.5 seconds and scrape latency 2.6 seconds, enabling real-time augmentation rather than relying on stale training data.
That is what replacing a training cutoff with a grounding pipeline actually looks like.
Frequently Asked Questions
Can you ever eliminate hallucinations completely?
No. Hallucinations are a consequence of how LLMs are built; they optimize for probability, not truth, and must always generate something. The goal is not elimination but containment: design pipelines that detect, constrain, and correct hallucinations before they reach users or trigger actions.
Why do agents work in demos but break in production?
Demos use clean inputs and happy-path queries. Production brings blocked pages, weak retrieval, stale cache, conflicting sources, and multi-agent drift. The gap is not the model; it is the pipeline. Retrieval quality, source injection, and validation are rarely stress-tested in a demo environment. Firecrawl's Scrape and Interact endpoints handle the real-web conditions production exposes: JS rendering and dynamic pages that demos never exercise.
Can an agent hallucinate even with good retrieved content?
Yes. Retrieval improves access to information. It does not guarantee correct reasoning over it. The agent can still confabulate, blend retrieved content with training knowledge, or draw the wrong conclusion from accurate evidence. Grounding requires structured source injection, a prompt that guides the model in using the evidence, and a validation layer.
What is the difference between stale-data hallucinations and confabulation?
Stale-data hallucinations happen when the model answers from its training snapshot and the world has changed: the answer was once correct but is no longer. Confabulation happens when the model has no answer at all and generates something plausible to fill the gap. Both produce confident, fluent output. Stale-data hallucinations are fixed by live retrieval. Confabulation is reduced by retrieval but also requires a pipeline that blocks generation when no source is found.
Why doesn't retrieval always fix hallucinations?
Retrieval fixes the knowledge problem, not the reasoning problem. An agent can retrieve accurate sources and still confabulate, blend retrieved content with training knowledge, or draw the wrong conclusion from accurate evidence. Retrieval quality also matters: keyword-matched results, raw HTML, and cached pages all introduce noise that pushes the model back toward training-data fallback. Effective grounding requires intent-matching search, token-efficient output, and freshness controls, not just a search API call. Firecrawl Search handles all three: semantic matching over keywords, token-efficient Markdown output, and live page fetches rather than cached results.
Does using a search API guarantee fresh results?
No. Search APIs can return cached pages from weeks or months ago, which reintroduces the stale-data problem you were trying to solve. Freshness filtering by publish date and live-crawl options for time-critical queries are the controls that make retrieval actually current. For stable reference content, a cached result is usually fine. For pricing, regulations, or breaking events, enforce freshness at retrieval time. Firecrawl fetches live pages at query time by default, which removes the cached-content problem for time-sensitive queries.
Is web search enough for regulated industries like healthcare or finance?
Web search handles freshness. It does not handle compliance. Regulated industries need citation validation, audit trails, deterministic guardrails, and human review for high-stakes actions. Grounding is one layer inside a broader compliance architecture.
