
TL;DR
- Best overall web search API for AI: Firecrawl - web context APIs built for AI agents: Search finds fresh, full-content results from the live web; Scrape, Parse, and Interact handle the rest of the Find → Extract → Clean → Use workflow
- Best for semantic/research search: Exa - neural search trained on link prediction, ideal for RAG and AI agents
- Best for citation-ready results: Tavily - source-first discovery with LangChain/LlamaIndex integration
- Best for evidence-backed research agents: Parallel AI - multi-agent retrieval with provenance on every result; 47% on HLE benchmark
- Best traditional SERP API: SerpAPI - 40+ engines, enterprise-grade reliability
- Best budget SERP option: Serper - affordable Google search access
- Best privacy-focused: Brave Search API - independent index, no tracking, $5/1k queries
The web search API market has been changing dramatically with AI applications driving demand for smarter search capabilities. With Microsoft's decision to retire Bing Search APIs in August 2025, developers are evaluating web search API alternatives and discovering new platforms built specifically for AI workflows.
Our web search API comparison examines both traditional SERP APIs and AI-native search engines that power modern applications. Whether you need a search API for RAG systems, semantic search for AI agents, or reliable data extraction for business intelligence, choosing the right platform affects performance, functionality, and costs.
This guide covers the best web search APIs for developers in 2026, including detailed analysis of pricing, capabilities, and ideal use cases. We'll compare everything from enterprise-grade SerpAPI alternatives to specialized platforms like Firecrawl search, Exa, and Tavily that target specific AI workflows. By the end, we hope you find the best web search API for you and your applications.
What is a Web Search API?
A web search API provides programmatic access to search engine results through HTTP requests, returning structured data in JSON or other machine-readable formats instead of visual web interfaces that we use for day-to-day web browsing.
What are web search APIs used for?
- AI and machine learning applications consume search results to train models, power chatbots, or enable retrieval-augmented generation systems with clean, structured data that LLMs process efficiently
- Business intelligence tools use search APIs to monitor brand mentions, track competitor content, or analyze market trends across thousands of queries daily
- SEO and marketing platforms automate rank tracking, keyword research, and content gap analysis by querying search engines programmatically
- Research applications gather data from academic sources, news sites, or industry publications at scale
For the sake of this blog, we consider the web search API market as divided into two distinct categories: AI and traditional.
AI-native search APIs like Firecrawl, Exa, and Tavily use neural networks, semantic understanding, or integrated content extraction to deliver information specifically formatted for LLM consumption and AI workflows. These platforms understand context and meaning beyond simple keyword matching. You'll want to use them for RAG systems, AI agents, and applications requiring semantic search capabilities. For multi-step agent workflows that combine live web retrieval with iterative reasoning, see the guide on agentic search for architecture patterns and real-world implementation examples. For a side-by-side feature comparison of the top options, see the guide to best search tools for AI agents.
Traditional SERP APIs including SerpAPI, ScrapingDog, Serper, and Brave focus on extracting and formatting search engine results from established platforms like Google and Bing (or in the case of Brave, using their own index). These services provide familiar search results for applications that need structured access to traditional search engine data that aren't focused on advanced AI capabilities.
A Comparison of Web Search APIs
| Feature | Firecrawl | Exa | Tavily | Parallel AI | SerpAPI | ScrapingDog | Serper | Brave |
|---|---|---|---|---|---|---|---|---|
| Pricing | $83/100k credits | $1.50/1k searches | $8/1k requests | Pay per query (not listed) | $75+/5k searches | $0.29-1.00/1k | $0.30-1.00/1k | $5/1k queries |
| Free Tier | Yes | 1,000/month | 1,000/month | None | 250/month | 1,000 credits | None | None |
| Output Formats | JSON, Markdown, HTML, Screenshots | JSON, Structured Data | JSON, Citations | JSON with provenance | JSON, Rich Metadata | JSON | JSON | JSON |
| Content Extraction | Full page + custom schemas | Page summaries | Key content extraction | Evidence-backed sourced results | Metadata only | Metadata only | Metadata only | Metadata only |
| AI Integration | Native LLM optimization | Neural semantic search | Citation-ready responses | Multi-agent evidence-based | Structured parsing only | Basic JSON output | Basic JSON output | Basic JSON output |
| Search Approach | AI + Traditional | Neural networks | Source-first discovery | Multi-agent agentic research | Multi-engine SERP | Google SERP | Google SERP | Independent index |
| Integrated Search + Scrape | Yes (single operation) | No | No | Task API (multi-step) | No | No | No | No |
| LangChain Support | Yes | Yes | Yes | Limited | Yes | Limited | Yes | Yes |
AI-Native Search APIs
Web Context APIs Built for AI Agents
Best for: AI agents that need fresh, full-content results from the live web — not noisy crawl output
Firecrawl is the context API to search, scrape, and interact with the web at scale — Search, Scrape, Parse, Crawl, Map, and Interact in one platform. Search is the front door: it finds fresh, relevant sources from the live web so your agent can extract, clean, and use them. Fresh, deep, no slop.
While most search APIs pass whatever they crawled straight to your agent, Firecrawl focuses on signal over noise: news, research, finance, and government. It monitors how often each source updates, so it knows exactly when to refresh. Your agents get current, full-content results — not a 2015 article passed off as the latest.
Authoritative sources, not raw crawl
Most search APIs pass whatever they crawled straight to your agent — including noise, AI slop, and stale content. Firecrawl focuses on signal over noise and monitors source update frequency to keep results fresh.
Unified search and extraction
Where other tools return links and snippets that need post-processing, Firecrawl finds the pages and extracts their full content in a single call at one flat credit per page — fewer API calls, simpler code, predictable costs.
Context-aware queries
Firecrawl supports a context parameter so agents can describe what they're actually trying to do, not just fire off a keyword query. Search bars were built for humans. Agents have more to say, and Firecrawl lets them.
Firecrawl's search capabilities span multiple content types and specialized categories. The platform supports filtering by source type (web, news, images) and specialized categories including github for repository searches, research for academic papers (arXiv, Nature, IEEE, PubMed), and pdf for document searches.
Advanced filtering includes time-based searches (past hour, day, week, month, or custom date ranges), location-based targeting by country, and HD image searches with dimension filtering using Google Images operators like imagesize:1920x1080 or larger:2560x1440.
While other tools require a two-step workflow where you search for pages then separately scrape each URL, Firecrawl lets you optionally go from search query to clean, LLM-ready content without additional infrastructure or API chaining.
For teams with strict compliance requirements, the /search endpoint also supports Zero Data Retention (ZDR) via the enterprise parameter. End-to-end ZDR (enterprise: ["zdr"]) ensures neither Firecrawl nor its upstream search provider retains any query or result data - at 10 credits per 10 results. Anonymized ZDR (enterprise: ["anon"]) provides full anonymization on Firecrawl's side at the standard 2 credits per 10 results. If you pair search with content scraping, you can combine search ZDR with scrape ZDR (zeroDataRetention: true in scrapeOptions) for end-to-end data protection across the entire pipeline.
Firecrawl is developer-friendly, and you can get started quickly to test it out. With only a few lines, you can start running web searches in minutes.
# Install the Firecrawl Python SDK
# pip install firecrawl-py
from firecrawl import Firecrawl
# Initialize with your API key
firecrawl = Firecrawl(api_key="fc-YOUR-API-KEY")
# Basic search - just metadata (titles, URLs, descriptions)
results = firecrawl.search(
query="AI agent frameworks",
limit=5
)
# Advanced search with content extraction
results = firecrawl.search(
query="AI agent frameworks",
limit=5,
scrape_options={
"formats": ["markdown", "links"]
}
)
# Category-specific search (GitHub repositories)
results = firecrawl.search(
query="web scraping python",
categories=["github"],
limit=10
)
# Time-based search (past 24 hours)
results = firecrawl.search(
query="AI news",
sources=["news"],
tbs="qdr:d",
limit=5
)Pricing transparency: Search costs 2 credits per 10 results. If you enable scraping, standard scraping costs apply (1 credit per page, with additional costs for PDF parsing). This pay-for-what-you-use model ensures you only pay for the features you actually need.
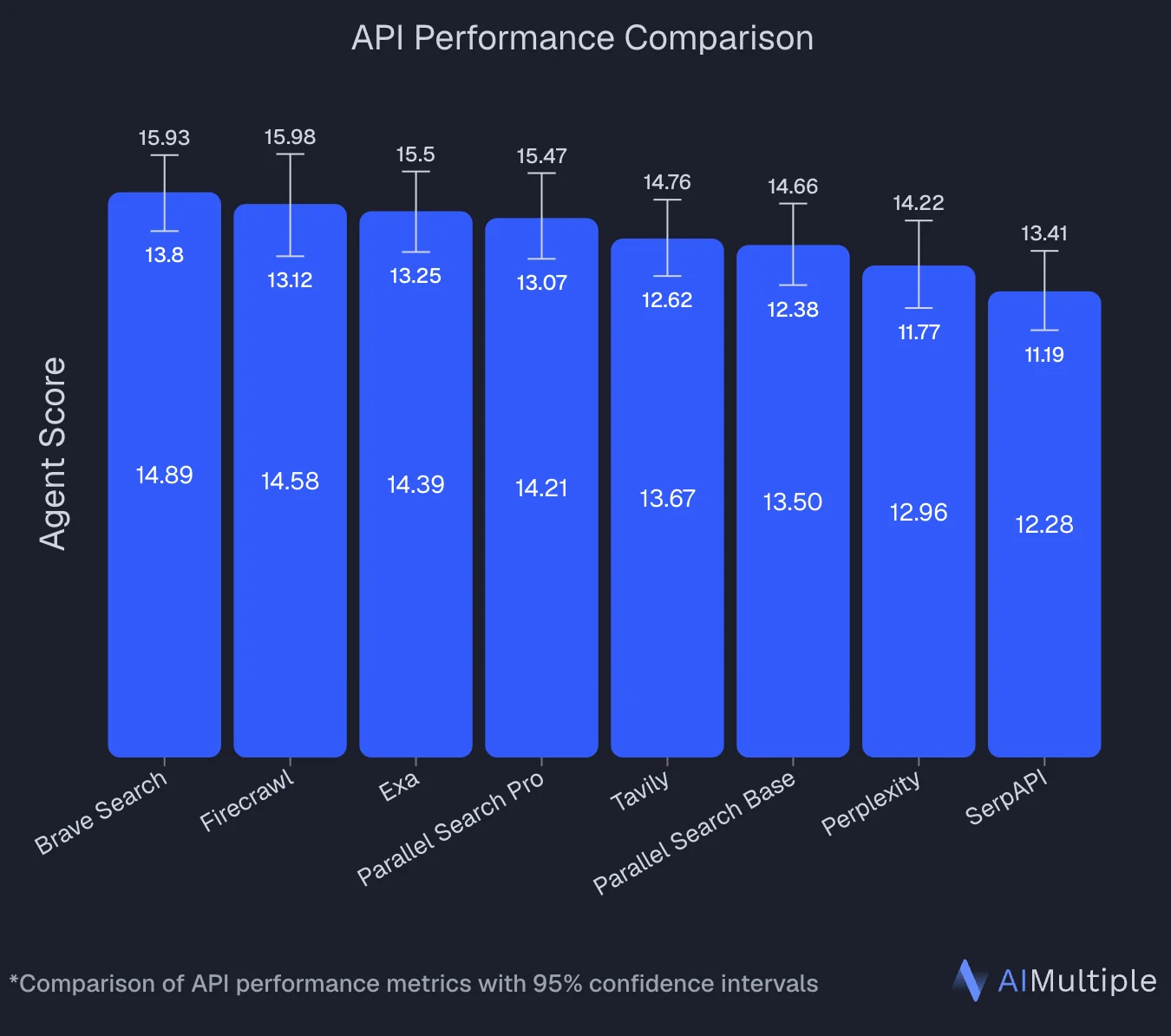
An independent benchmark by AIMultiple evaluated 8 search APIs across 100 real-world AI/LLM queries and ranked Firecrawl second overall with an Agent Score of 14.58, statistically tied with the top performer (Brave Search at 14.89). Firecrawl posted the highest mean relevant score in the benchmark (4.30 out of 5) and performed best on deep content retrieval tasks — where full-page context determines answer quality.
Read how you can build apps with Firecrawl agent and Claude Opus 4.6.
For workflows where you need to go deeper into a specific search result, the /interact endpoint extends scraping with a session-based interaction model: scrape a page to get its initial content, then call /interact on the same scrapeId to take actions on it. Describe what you want in natural language ("click the next page button and extract the product prices") or write code directly using Playwright or the agent-browser CLI. The session preserves state between calls, so you can chain multiple interactions - navigate pagination, submit forms, extract content that only appears after user actions - all within the same browser session. You can also pass a profile to persist login state across separate scrapes, making it straightforward to access authenticated content at scale. This is the targeted alternative to Browser Sandbox when your workflow follows the pattern: find a page via search, then interact with it to get what's behind the surface.
Learn more about Firecrawl's search endpoint and how it simplifies web data workflows. For developers looking to learn about Firecrawl's other endpoints, check out our guides on Firecrawl's scrape endpoint and crawl endpoint.
Pros:
- Flexible architecture: use as pure search API or enable integrated content extraction as needed
- Parse endpoint converts PDFs and documents into clean text — no separate processing step for document-heavy workflows
- Browser Sandbox for agents to handle pagination, auth flows, and form fills in isolated, parallel sessions
/interactendpoint for session-based interaction on scraped pages: navigate deeper, fill forms, and extract dynamic content using natural language prompts or Playwright/agent-browser code- Multiple specialized search categories including GitHub repositories, research papers, and PDFs
- Advanced filtering: time-based searches, location targeting, and HD image dimension filtering
- Zero Data Retention (ZDR) options for compliance-sensitive deployments, combinable with scrape ZDR for full pipeline coverage
- Clean markdown output optimized specifically for LLM consumption and RAG workflows
- Advanced schema extraction using natural language prompts for structured data
- Production-ready infrastructure that serves major enterprise customers
- Transparent, usage-based pricing - pay only for features you use
Cons:
- Newer platform compared to established alternatives
- Advanced capabilities might be unnecessary overhead for simple search-only applications
The Neural Semantic Search Engine
Best for: AI agents requiring semantic discovery and research dataset curation when searching for AI research content
Exa provides a unique and innovative AI-forward web search for researchers. When searching for AI research, they trained neural networks on link prediction to understand how humans actually connect ideas across the internet, and as a result, their search engine grasps semantic relationships.
The difference shows up in results quality. Ask for "breakthrough AI research" and Exa's neural search surfaces top papers by understanding research significance, not just term frequency. Their system learns from how researchers actually link to each other's work, creating a search experience that feels almost intuitive for complex queries.
Exa offers advanced AI-driven search and semantic data extraction capabilities requiring some configuration. These features, while powerful, add layers of complexity compared to straightforward search.
Response times stay under a second even for complex semantic queries, and their real-time indexing adds fresh content within hours. As a research-oriented company, they focus on source quality over volume, so their results may miss commercial or news sources that broader applications need.
Pros:
- Neural networks trained on link prediction deliver true semantic understanding
- AI-native architecture with responses formatted specifically for LLM consumption
- Authoritative source curation emphasizing research-grade content quality
- Sub-second response times with real-time indexing of new content
- Understands research significance and contextual relationships between sources
Cons:
- Exa generally requires more initial setup work than Firecrawl's simpler search API experience
- Smaller search index means less comprehensive coverage than APIs like Firecrawl
- Neural search effectiveness varies unpredictably across different domains and query types
- Limited traditional SERP features for teams expecting conventional search results
Check out our Exa alternatives guide and our detailed Firecrawl vs. Exa comparison to see how these platforms stack up.
The Citation-First Search API
Best for: RAG pipelines and AI agents requiring trustworthy source discovery with built-in credibility assessment when searching for AI citations
Tavily, another AI web searcher, focuses on surfacing high-quality, citable sources that can immediately ground LLM responses. Think of them as the research librarian of search APIs, prioritizing source authority and citation quality over complete web coverage or advanced semantic matching.
Their architecture centers around what they call "source-first discovery." When you query for recent developments in gene editing, Tavily returns peer-reviewed articles, authoritative news sources, and industry publications with concise summaries and metadata ready for citation.
Unlike integrated platforms like Firecrawl, Tavily focuses purely on search and source discovery. The API provides structured JSON output with citation metadata, but workflows typically require additional processing to extract full content from the discovered sources.
Tavily offers 1,000 free searches monthly, then charges $0.008 per request on a pay-as-you-go basis with no volume minimums. While the per-request pricing is transparent, teams may find the lack of bundled plans less predictable for budgeting than competitors with monthly tiers.
Pros:
- Source credibility assessment built into search results for trustworthy citations
- Fast response times of 0.4-1.2 seconds with high reliability for production workflows
- LangChain and LlamaIndex integrations with comprehensive RAG workflow documentation
- Citation-ready output format with metadata and source provenance for explainable AI
Cons:
- Limited semantic search capabilities compared to neural search engines like Exa or Firecrawl
- Smaller search index means less comprehensive coverage than alternatives
- Focus on source discovery rather than content extraction requires additional tools for full workflows
- Response format optimized for citations rather than full data analysis
Check out our Tavily alternatives guide and our detailed Firecrawl vs. Tavily comparison.
Parallel AI
Agentic Web Research at Scale
Best for: Research-heavy agents that need high-accuracy outputs with clear sourcing, particularly for enterprise or compliance-sensitive workflows
Parallel AI (officially Parallel Web Systems) is a newer entrant building web infrastructure specifically for AI agents. It raised a $100M Series A in early 2025 with the thesis that existing search infrastructure wasn't built for AI as a first-class user.
The core differentiator is accuracy. Parallel benchmarks itself at 47% on the HLE (Humanity's Last Exam) benchmark, compared to Exa at 24%, Tavily at 21%, and Perplexity at 30%. Every result includes provenance and evidence — not raw links or ranked snippets.
Its product suite covers four main use cases:
- Search API: Real-time web queries optimized for agent consumption with sourced, evidence-backed results
- Task API (Deep Research): Multi-step research that reasons across sources rather than just returning links
- Find All: Dataset building at scale for teams that need comprehensive domain coverage
- Web Enrichment and Monitor API: Enrich records with live web data and track changes over time
Pros:
- Evidence-backed results with full provenance on every output
- 47% HLE benchmark accuracy, ahead of Exa (24%), Tavily (21%), and Perplexity (30%)
- Pay-per-query pricing (not per token) for predictable cost scaling
- Multi-step research via Task API for complex agent workflows
- SOC 2 Type II certified
Cons:
- Newer platform — ecosystem integrations, SDKs, and community resources still maturing
- No public pricing listed
- No free tier for testing before committing
- Less proven in production at scale compared to more established alternatives
Traditional Web Search APIs
The Google-Powered SERP Specialist
Best for: Applications requiring comprehensive Google search coverage with reliable data extraction

ScrapingDog operates as a specialized intermediary between your application and Google's search results. Rather than building their own search index or developing AI-native capabilities, they focus entirely on one thing: reliably extracting Google's SERP data and delivering it in clean, structured JSON format. You get access to Google's massive search coverage, rich result types, and familiar ranking algorithms without dealing with proxy rotation, rate limiting, or HTML parsing complexities.
Their Google Search API handles the full spectrum of SERP features including organic results, People Also Ask sections, featured snippets, local results, and shopping data.
What sets ScrapingDog apart is their infrastructure focus, rather than algorithm or AI innovation. That means it doesn't have capabilities like semantic search or LLM-optimized outputs. You'll need developers to build additional processing layers for modern AI workflows.
Pros:
- Google search coverage with advanced search parameter support like complex operators and filters
- Competitive pricing from $0.29 to $1.00 per 1,000 searches with generous free tier
- Proven infrastructure handling 400+ million monthly requests
Cons:
- No AI-native capabilities or semantic understanding beyond Google's algorithm
- Only JSON output (requires additional processing)
- Complete dependency on Google's search results (and its terms and conditions) without independent relevance improvements
- Limited to SERP data extraction without full content scraping like other web search API offerings
The Multi-Engine Enterprise Solution
Best for: Large organizations requiring maximum reliability and comprehensive search engine coverage across multiple platforms
SerpAPI operates as the wrapper service for search engine data, providing unified access to over 40 different search engines and platforms through a single integration. Rather than building separate connections to Google, Bing, Yahoo, DuckDuckGo, Baidu, Yandex, Amazon, Yelp, and dozens of other services, developers can access all of them through SerpAPI's standardized JSON interface.
However, SerpAPI's scope doesn't cover the full needs for modern AI applications. The service returns only search result metadata including titles, snippets, and links rather than full page content. If you need content for LLM processing, you'll have to build additional infrastructure to fetch URLs, convert HTML to text, and handle content extraction separately.
SerpAPI is also very expensive compared to all the alternatives. Combined with premium pricing starting at $75 monthly for 5,000 searches and scaling to $275 for 30,000 searches, the service targets enterprise customers who value reliability guarantees, multi-engine flexibility, and premium cost customer support.
Pros:
- Enterprise-grade reliability with 99.9% uptime SLA and verified real-time data delivery
- High-performance architecture supporting up to 100 requests per second with global infrastructure
- Exceptional customer support with responsive technical assistance through in-product chat
Cons:
- Premium pricing that's 10-50x more expensive than focused search API alternatives
- Requires additional development to build content extraction pipeline for LLM workflows
- Multi-engine complexity may be overkill for applications needing only basic Google search
- Limited to predefined SERP formats rather than comprehensive web data extraction capabilities
The Affordable SERP Middle Ground
Best for: Developers seeking cost-effective Google search access without enterprise complexity
Serper positions itself between budget and premium SERP API options, offering straightforward Google search results through a clean REST API. Rather than competing on advanced features or multi-engine support, they focus on delivering reliable Google search data at volume-friendly pricing that scales with usage. The service targets developers who need more than basic SERP scraping but don't require the larger feature sets of enterprise tools.
Serper emphasizes partnerships and framework integrations over direct developer outreach. For example, their documentation appears less accessible than some competitors (serper.dev/docs doesn't exist). Serper has lots of AI integrations, such as LangChain, so you might have an easier time accessing it through those partner tools.
Pros:
- Volume-friendly pricing scaling from $1.00 to $0.30 per 1,000 searches for large users
- Simple API structure with clean REST endpoints and standard search parameters
- Google search results with familiar SERP data including organic results and metadata
- Focus on reliability over feature complexity appeals to straightforward use cases
Cons:
- No free tier for testing compared to generous trial offers from competitors
- Limited publicly accessible documentation creates integration uncertainty
- Fewer advanced features compared to comprehensive platforms like SerpAPI
- Google dependency creates potential service disruptions if Google's policies change
The Privacy-Focused Alternative
Best for: Research applications, business intelligence monitoring
Brave Search API runs on an independent search index that doesn't rely on Google's infrastructure or tracking systems. The company, known and loved for their commitment to user privacy, built their own web crawler and search algorithms to give developers access to search results without the use of surveillance-based business models. Brave Search doesn't collect data during API usage, so it can be useful for healthcare applications, financial research, government projects, or any scenario where query confidentiality is important.
Brave does have some notable limitations, however. It has a smaller search index than Google or others, which means less comprehensive results for niche topics or very recent content. Unlike AI-native platforms like Exa or Firecrawl, Brave Search focuses on traditional keyword-based search without semantic understanding or LLM-optimized outputs.
See Firecrawl vs Brave Search API for a direct feature and use-case comparison.
Pros:
- No user tracking or data collection during API usage
- Independent search index free from Google dependency
- $5 per 1,000 queries pricing for AI applications
Cons:
- Removed free tier - Brave Search API no longer offers a free plan, making it harder to test before committing
- Smaller search index means less coverage than Google-powered APIs
- Limited relevance for niche topics or very recent content
- Rate limits may be restrictive for high-volume applications (1 req/sec baseline)
How do you choose a web search API?
Consider the following criteria when choosing your web search API:
Search approach and data quality: The web search API should align with your application's needs. Traditional SERP APIs tend to deliver Google's familiar ranking algorithms, which is good for applications requiring specific SERP features like Knowledge Graph data. AI-native search APIs excel at semantic understanding or research discovery but may have smaller indices or different relevance models than users expect from Google-powered results.
Integration complexity: APIs with strong LangChain support reduce implementation complexity for AI developers, so teams can prototype faster and switch between search providers without rewriting all of their integration code. Conversely, platforms requiring custom infrastructure or complicated authentication can slow teams down. See our guide to building web scraping agents with LangGraph and Firecrawl for a practical example.
Vendor lock-in risks: Independent search APIs provide protection against sudden platform changes or forced migrations to pricey and bloated enterprise ecosystems. When choosing a tool, check whether it could restrict access, change pricing models, or force you into using specific platforms in the future.
Content extraction capabilities: Some APIs return only search metadata, while integrated platforms combine search discovery with content extraction get rid of this complexity. Consider the needs of your entire workflow rather than just the search functionality component.
Data for AI agents: If you're building autonomous agents, search is only part of the picture. Your API needs to feed agents with data they can act on - not just links and snippets. Look for platforms that support agentic workflows end-to-end: autonomous browsing for multi-step tasks, parallel processing across sources, and clean structured output that agents can reason over without additional preprocessing. An API that works well for a simple RAG pipeline may become a bottleneck when your agent needs to navigate, extract, and synthesize across dozens of pages in a single task.
Takeaways
When it comes to web search APIs, integrated platforms have clear advantages over traditional search-then-scrape approaches, and AI-native platforms are increasingly outpacing traditional SERP APIs for modern development workflows.
Choose platforms that align with where AI development is going rather than trying to adapt legacy search approaches to modern requirements. If you're building AI agents or RAG systems, you have to be even choosier with your search API.
Firecrawl delivers fresh, full-content results from the live web — not whatever a crawler grabbed. Teams that were running a SERP API, a separate scraper, and a PDF parser replace all three with one API. Its combination of Search, Scrape, Parse, Interact, and an autonomous /agent endpoint covers the full Find → Extract → Clean → Use workflow, at pricing that typically beats assembling the same stack from separate services.
Open-source agent runtimes like Hermes already ship Firecrawl as their default web backend, routing both web_search and web_extract calls through it automatically.
Traditional SERP APIs remain viable for specific scenarios but require additional development overhead that AI-focused platforms take care of by default. The cost savings of metadata-only APIs disappear when factoring in the infrastructure needed for content extraction that AI workflows typically require (and in the case of SerpAPI, you're already paying premium prices just to search!).
The future of infrastructure is AI-first, and your web search partner should be too.
Sign up for Firecrawl and start searching the web for free.
Frequently Asked Questions
What's the difference between SERP APIs and Search APIs?
SERP APIs specifically scrape and reformat data from existing search engines like Google or Bing - they act as middleman services that parse SERPs and return structured JSON. Search APIs is the broader category that includes both SERP scrapers and independent search engines. Firecrawl goes beyond both: it searches across the live web — news, research, finance, government — with freshness monitoring, combines search with full content extraction, and supports autonomous multi-step research via the /agent endpoint - all in one platform. Other examples include Exa's neural semantic search and Brave's privacy-focused independent index. All SERP APIs are Search APIs, but not all Search APIs are SERP APIs.
How do AI-native search APIs work differently from traditional search?
Traditional search APIs match keywords and return results based on text similarity and popularity signals. AI-native search APIs like Exa and Tavily use neural networks to understand semantic meaning and context - they can find relevant information even when it doesn't contain your exact search terms, and they format results specifically for AI consumption rather than human browsing.
What happened to Bing Search APIs in 2025?
Microsoft shut down Bing Search APIs on August 11, 2025, pushing users toward their Azure AI Agents platform with 'Grounding with Bing Search.' Developers should consider independent search providers that aren't subject to sudden platform changes from major tech companies.
Do web search APIs return full page content or just snippets?
It depends on the provider. Traditional SERP APIs (SerpAPI, Serper, ScrapingDog) return only search metadata - titles, URLs, and short snippets of 150–300 characters. AI-native platforms like Firecrawl solve this by combining search and full content extraction in a single API call, returning clean markdown that LLMs can process directly. Tavily and Exa offer content summaries but typically require an additional scraping step for full page text.
How much do web search APIs actually cost in production?
The advertised per-query price is rarely the full picture. Factor in: token processing fees, volume tiers, premium features billed separately (PDF parsing), and rate limit overages. Firecrawl's search costs 2 credits per 10 results. Tavily charges $0.008 per request. SerpAPI starts at $75/month for 5,000 searches - 10–50x more expensive than alternatives at comparable volume. Always prototype with free tiers and run cost projections before committing.
Which web search API is best for RAG systems and LLM grounding?
Firecrawl is a strong choice for RAG: it pulls full-content results from the live web, so the context going into your pipeline is fresh and signal-rich rather than noisy crawl output. It also has native LangChain and LlamaIndex integrations and goes from query to markdown in a single request — no extra scraping step. Exa is a strong alternative for semantic search that surfaces conceptually relevant sources; Tavily for citation-ready structured output with source credibility scoring. Firecrawl is also the strongest choice for autonomous search — its /agent endpoint handles multi-step research tasks in parallel, making it ideal for agentic RAG pipelines.
How do I integrate a web search API with LangChain or other AI frameworks?
Most modern web search APIs provide native integrations with LangChain, LlamaIndex, and MCP (Model Context Protocol) servers. Firecrawl, Exa, Tavily, SerpAPI, and Serper all have official LangChain tools you can import directly. For MCP-based agentic workflows, look for providers that expose MCP server support. Check whether packages are officially maintained by the provider - these are far less likely to break when frameworks update.
Are there web search APIs with strong privacy guarantees?
Brave Search API is the standout option for privacy-sensitive use cases - it runs on an independent index and doesn't collect or log API query data, making it suitable for healthcare, legal, and financial applications. Note that Brave recently removed its free tier, so you'll need a paid plan to get started. For GDPR-compliant deployments, verify any provider has a Data Processing Agreement (DPA) available. Most AI-native APIs (Firecrawl, Exa, Tavily) don't sell query data, but review privacy policies carefully if regulatory compliance is a hard requirement.
