
Introduction
Retrieval-Augmented Generation (RAG) has become crucial in enterprises to create generative AI applications with their data. By 2025, the adoption of RAG platforms increased dramatically, with 73.34% of implementations happening in large organizations. These systems guide how companies build AI applications that generate accurate and contextually relevant responses by retrieving information more effectively from the knowledge base. The market is expanding based on the need for solutions that bring the capability of AI with the data security expected in enterprise systems.
Organizations may choose an enterprise RAG solution over an open-source alternative because they seek production-ready infrastructure with dependable support. These are well-developed platforms that provide high security and compliance features, along with integration into existing systems. Enterprise RAG platforms allow the scalability and performance necessary to handle large document repositories and multiple users at a time. Most of the time, this type of investment has a quicker time to market and less operational risk than a custom-built solution.
This article will examine the top ten pre-built enterprise RAG platforms available in 2025. We will evaluate the platforms on various criteria and readers will gain insight into which RAG solution can be ideal for their use case. For open-source alternatives, see our open-source RAG frameworks comparison. To optimize RAG performance, explore best chunking strategies for RAG. For vector database options, check our best vector databases guide.
Enterprise RAG Platform Evaluation Methodology
Our evaluation methodology builds on data from the Roots Analysis's market report and several industry analyses of RAG tools published in early 2025. We assessed platforms based on their documented enterprise features, security capabilities, integration options, and proven implementation cases. We acknowledges the limitations in available adoption data, relying on industry insights and platform presence mentioned across multiple independent sources. Our assessment prioritizes factual information from official documentation and verified case studies rather than speculative performance claims.
The platforms are presented in order of their presumed market adoption, though these patterns vary by industry sector. For each solution, we examined technical documentation, published case studies, and enterprise implementation examples to determine suitability for different organizational needs. We considered key factors including security features, scalability characteristics, and documented enterprise use cases. This approach provides a balanced overview of the current enterprise RAG landscape while recognizing the constraints of publicly available market data.
Firecrawl: Enhancing Enterprise RAG With Quality Web Data
Following the evaluation methodology process, let's briefly shift our focus to obtaining quality web data. Firecrawl is the context API to search, scrape, and interact with the web at scale, collecting and organizing web data to improve RAG systems.
Its key features for RAG data collection are:
- LLMs.txt generation: Converts entire websites into single text files for language models
- Intelligent crawling: Navigates websites while handling JavaScript and access restrictions
- Natural language extraction: Defines data collection using plain English instead of technical selectors
- Deep research API capabilities: Builds comprehensive knowledge bases on specific topics

Firecrawl the new LLMs.txt standard, which converts websites into a format friendly for LLMs. When Firecrawl processes a website, it generates a single text file containing all content from the original website in markdown. This processing approach resolves the context window limitations that enterprise RAG applications often face when analyzing large websites, which is just one of many data challenges that degrade RAG performance.
In addition to context limitations, enterprise RAG applications struggle with authentication requirements, regulatory compliance requirements, and data extraction from structured/unstructured formats from multiple sources. Firecrawl helps to resolve these issues using ethical scraping, custom extraction of target formats, and clean structured fields for AI search and RAG that are universal for all enterprise RAG applications.
The platform leverages a structured markdown format that follows the proposed standard with clear titles, descriptions, and organized links in the completion to optimize retrieval for RAG.
Firecrawl integrates with enterprise RAG platforms through both API and Python SDK. For examples of real-world implementations and integration techniques, visit the Firecrawl blog.
Top 10 Pre-Built Enterprise RAG Platforms
Based on our evaluation methodology and market research, we've identified the following platforms as the top enterprise RAG solutions in 2025. These platforms have demonstrated strong adoption rates, robust feature sets, and proven track records in enterprise environments. Let's examine Elastic Enterprise Search to start our list.
1. Elastic Enterprise Search
Elastic Enterprise Search stands as one of the most widely adopted RAG platforms, offering enterprise-grade search capabilities powered by the industry's most-used vector database. The platform excels at combining traditional search with AI capabilities, providing robust Retrieval Augmented Generation workflows that enhance generative AI experiences with proprietary data. Elastic's comprehensive approach spans multiple use cases from knowledge management to customer support, with a flexible architecture that scales from development to production environments.
Key enterprise features include:
- Vector database and semantic search - Built-in vector capabilities with multiple retrieval methods including BM25, kNN, and hybrid search using reciprocal rank fusion
- Enterprise-grade security - Document-level security controls with robust authentication and authorization mechanisms
- Flexible deployment options - Available as serverless, self-managed, or fully-managed Elastic Cloud deployments
- Real-time data handling - Low-latency querying optimized for time-sensitive applications
- Multiple integration options - Native clients for popular programming languages and comprehensive APIs
Elastic Enterprise Search includes security features like encryption, access controls, and compliance certifications necessary for enterprise RAG deployments. The platform offers pricing tiers from consumption-based serverless to resource-based options for cloud and self-managed deployments. Most organizations can implement basic RAG workflows within weeks, regardless of their size or existing infrastructure. Elastic provides documentation, developer resources, and professional services to help teams quickly set up and optimize their RAG systems.
2. Pinecone

Pinecone is a vector database built for production-scale AI applications with efficient retrieval capabilities. The platform is widely used for enterprise RAG implementations, with a serverless architecture that scales automatically based on demand. Pinecone's cascading retrieval system combines dense and sparse vector search with reranking, improving search performance by up to 48% compared to standard approaches.
Key enterprise features include:
- Hybrid search capabilities - Support for both dense semantic embeddings and sparse keyword-based retrieval
- Auto-scaling infrastructure - Serverless architecture that adjusts based on workload demands
- Enterprise-grade security - SOC 2, GDPR, ISO 27001, and HIPAA compliance with data encryption
- Hosted embedding models - Pre-configured models for text embedding and reranking
- Extensive integrations - Compatibility with major AI frameworks and cloud providers
Pinecone operates across AWS, GCP, and Azure with separate write and read paths to maintain consistent performance. The platform supports real-time indexing and includes namespaces for tenant isolation in multi-tenant environments. Implementation requires minimal configuration as the serverless architecture handles scaling and maintenance automatically, allowing teams to focus on application development rather than infrastructure.
3. Weaviate
Weaviate is an AI-native vector database that combines search and storage capabilities for enterprise knowledge applications. The platform helps developers build applications that understand both semantic meaning and exact matches in data. Weaviate specializes in hybrid search that merges vector, keyword, and multimodal techniques to deliver more accurate search results.
Key enterprise features include:
- Hybrid search capabilities - Combines vector search with keyword (BM25) techniques to leverage both semantic context and exact matching
- Flexible deployment options - Available as Serverless Cloud, Enterprise Cloud, or Bring Your Own Cloud
- Multimodal support - Handles text, images, audio, and video in a unified system
- Built-in vectorization - Includes pre-configured models and integrations with LLM frameworks
- Security-focused architecture - Keeps data within your own environment through self-hosting or VPC options
Weaviate's RAG implementation focuses on reducing hallucinations in generative AI applications while maintaining data privacy. The system allows quick testing of different LLMs through simple code changes, helping teams find the best configuration for their needs. At scale, Weaviate maintains performance by optimizing vector operations and includes practical features like multi-tenancy, filtering, and compression to manage costs.
4. Milvus

Milvus is an open-source vector database built for generative AI applications with a focus on high-performance vector search at scale. The platform offers multiple deployment models from lightweight local installations to fully distributed systems that can handle billions of vectors. Milvus specializes in multimodal search capabilities, allowing organizations to find similar images, videos, audio files, and text using the same underlying architecture.
Key enterprise features include:
- Multimodal search capabilities - Supports embedding and searching across various data types including text, images, audio, and video
- Flexible deployment options - Available as Milvus Lite for prototyping, Standalone for production, and Distributed for enterprise-scale operations
- Kubernetes integration - Designed for cloud-native environments with horizontal scaling capabilities
- Hardware acceleration - Utilizes various compute capabilities including AVX512, Neon, and GPU support for optimized performance
- Extensive index support - Includes over 10 index types like HNSW, IVF, and Product Quantization for tuning accuracy and performance
Milvus architecture separates storage from compute, allowing independent scaling of different components based on workload requirements. The system's tunable consistency model lets organizations balance query performance against data freshness for different use cases. Integration with popular AI frameworks including LangChain, LlamaIndex, and OpenAI simplifies implementation in existing RAG workflows. For organizations requiring managed options, Zilliz Cloud provides a fully-managed version with reported performance improvements.
5. Redis (RedisAI + Vector Search)

Redis for AI combines in-memory processing with vector search capabilities for real-time AI applications. The platform performs well in vector database benchmarks with high throughput and low latency. Redis extends beyond vector storage by providing memory management and caching specifically designed for AI workloads.
Key enterprise features include:
- Real-time vector search - In-memory architecture for fast retrieval in RAG workflows
- Short and long-term memory - Storage for AI agent conversation history and context
- Semantic caching - LangCache reduces LLM calls by storing frequent query meanings
- Semantic routing - Directs queries to appropriate tools based on meaning rather than keywords
- Flexible deployment - Available as Redis Cloud, self-managed software, or within existing infrastructure
Redis for AI works with frameworks like LangChain and LlamaIndex, allowing integration into existing development workflows. Organizations like Axis Bank use Redis to speed up transaction processing by 76%. The platform supports applications requiring fast responses such as fraud detection and customer support while using familiar Redis commands to simplify implementation.
6. LangChain
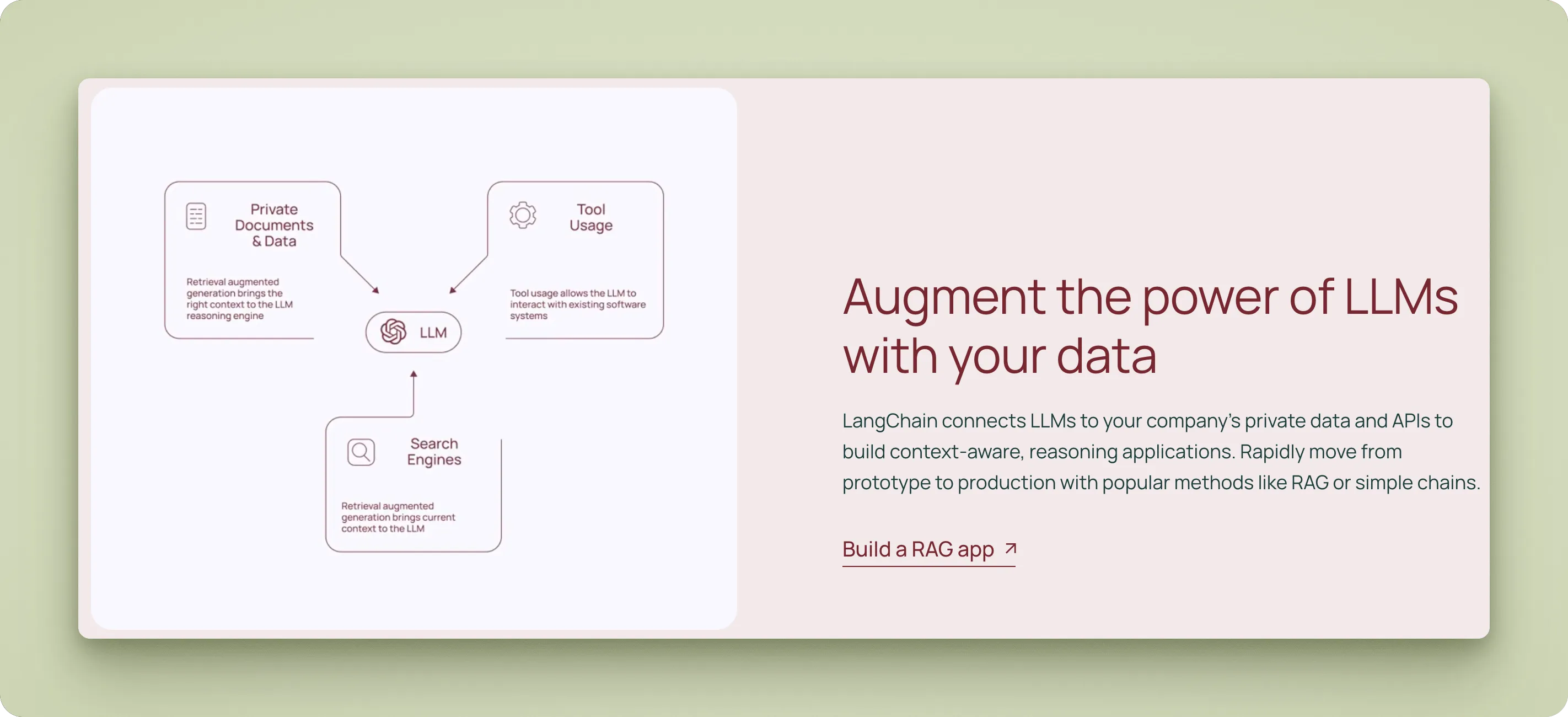
LangChain is a framework for building applications with large language models that has expanded into a platform for enterprise RAG implementations. The ecosystem includes the core LangChain framework for LLM apps, LangGraph for orchestrating agentic workflows, and LangSmith for monitoring performance. This suite offers both open-source components and enterprise-grade managed services.
Key enterprise features include:
- Composable architecture - Modular design for connecting data sources, models, and tools
- Agent orchestration - Control flows for multi-agent systems and human-in-the-loop workflows
- Enterprise observability - Visibility into LLM calls and reasoning paths for debugging
- Evaluation framework - Tools to assess model outputs and measure accuracy
- Vendor flexibility - Support for multiple LLM providers with easy model switching
LangChain has been adopted by enterprises including Klarna, Rakuten, and Replit for production applications. The framework integrates with existing systems while maintaining control over data privacy. LangChain's documentation and integrations with other tools make it suitable for teams implementing custom RAG solutions without building everything from scratch.
7. Vespa

Vespa is an open-source platform for building AI applications that combines search, recommendation, and real-time data processing capabilities. The system specializes in real-time indexing and enterprise search features with strong support for both traditional and vector search approaches. Vespa includes distributed machine learning model inference directly where data is stored, enabling complex ranking operations without moving data between systems.
Key enterprise features include:
- Real-time indexing - Documents become searchable immediately after ingestion with no indexing delay
- Hybrid search capabilities - Combines lexical, vector, and structured search in a single query
- Advanced ranking flexibility - Supports multi-phase ranking with custom ML models at each phase
- On-node inference - Evaluates ML models where data resides to reduce latency
- Scalable architecture - Handles billions of documents with automated horizontal scaling
Vespa powers search and recommendation systems for major organizations including Spotify, Yahoo, and Farfetch with proven performance at scale. The platform offers both self-hosted open-source and fully-managed cloud options with continuous deployment and upgrades. Vespa's architecture is designed for both high query volumes and large data collections while maintaining sub-100ms response times, with special modes for personal data that reduce costs compared to standard indexing approaches.
Enterprise RAG implementation strategies
Implementing enterprise RAG solutions requires strategic decisions about development approach, data handling, and performance measurement. These considerations impact both initial deployment and long-term success.
Planning and preparation
The initial phase of RAG implementation involves critical decisions about technology approach and data readiness.
Build vs buy decision: Organizations must choose between building custom solutions or purchasing pre-built platforms. Building custom solutions provides greater control but requires technical expertise and higher development costs. Buying pre-built platforms offers faster deployment with built-in security features, though with less flexibility. When making this assessment, several factors should be weighed carefully:
- Available technical resources and expertise
- Time-to-market requirements
- Integration needs with existing systems
Beyond the initial technology approach, data preparation workflow forms the foundation of successful RAG implementations. This process typically includes collecting data, extracting content from various formats, chunking text into appropriate segments, creating vector embeddings, and storing in specialized databases. Without proper data preparation, even the most sophisticated RAG architecture will underperform.
Research from GigaSpaces AI and the Couchbase Blog provides detailed guidance on these initial planning stages.
Implementation and evaluation
Once planning is complete and data is prepared, organizations must address technical implementation approaches and establish clear performance metrics to ensure success.
Hybrid retrieval techniques: Combining multiple retrieval methods enhances system performance and accuracy. By integrating vector-based semantic search with keyword matching and structured queries, organizations can better handle diverse query types and content formats. Implementation patterns include parallel retrieval paths and cascading retrieval with weighted scoring, improving the system's ability to find relevant information across varied contexts.
While technical performance is important, measuring business impact determines the true value of RAG implementations. Organizations should establish clear metrics to quantify ROI across multiple dimensions:
- Efficiency metrics: Time saved, reduced handling time, operational cost savings
- Quality metrics: Accuracy improvements, reduced hallucinations, customer satisfaction
- Business outcomes: Case studies like LinkedIn's 28.6% reduction in support resolution times
By establishing these measurement frameworks, organizations can connect technical performance to tangible business value, providing quantifiable evidence to justify continued investment in RAG technologies. This approach ensures that RAG solutions deliver measurable benefits aligned with organizational goals rather than remaining technical experiments without clear business impact.
Decision Matrix: choosing the right enterprise RAG platform
Selecting the optimal RAG platform requires evaluating multiple factors against your organization's specific requirements. The following comparison provides a framework for assessing enterprise RAG solutions based on key criteria.
Comparative table with all platforms
| Platform | Key Strengths | Vector Search | Hybrid Retrieval | Deployment Options | Security Features | Primary Use Cases |
|---|---|---|---|---|---|---|
| Elastic Enterprise Search | Text analytics, comprehensive indexing | Built-in | BM25 + vector | Cloud, self-hosted | Document-level security | Enterprise search, knowledge bases |
| Pinecone | Specialized vector operations | High-performance | Cascading retrieval | Managed service (serverless) | SOC 2, GDPR compliant | AI recommendations, semantic search |
| Weaviate | Semantic understanding | Multi-model support | BM25 + vector | Cloud, self-hosted | Data encryption, access controls | Knowledge management, hybrid search |
| Milvus | Scalable performance | Multiple indexes | Flexible search | Cloud, self-hosted | Role-based access | Multimodal search, large collections |
| Redis | Real-time processing | In-memory | Semantic routing | Cloud, self-hosted | Authentication, encryption | Real-time applications, caching |
| LangChain | Workflow orchestration | Framework integration | Customizable chains | Framework-based | Integration-dependent | Custom RAG applications, agents |
| Vespa | Real-time indexing | Advanced ranking | Multi-phase ranking | Cloud, self-hosted | Access controls | Search, recommendations |
Implementation considerations
Organization and industry requirements significantly influence platform selection decisions. Financial services and healthcare organizations typically prioritize security and compliance features, requiring solutions with strong encryption, access controls, and regulatory certifications like HIPAA. E-commerce businesses often value real-time performance and personalization capabilities for customer-facing applications. Research from Evidently AI demonstrates how different industries leverage RAG capabilities to address specific challenges.
Deployment models also impact implementation complexity and ongoing management. According to GigaSpaces AI, self-hosted solutions provide maximum control but require infrastructure expertise and maintenance resources. Fully-managed services reduce operational burden but may limit customization options. Some platforms offer hybrid approaches, providing flexibility as needs evolve. Consider your IT capabilities, security requirements, and scalability needs when evaluating these deployment options to ensure alignment with your organization's infrastructure strategy.
Operational factors
Cost structures vary significantly across platforms and affect total cost of ownership. AIMultiple notes that solutions like Pinecone use consumption-based pricing (charging for data storage and queries), while others employ subscription models or open-source options with infrastructure costs. When comparing platforms like Pinecone and Elasticsearch, Estuary highlights performance trade-offs that impact operational expenses. Factor in initial implementation expenses, ongoing operational costs, scaling requirements, and potential optimizations to determine the most cost-effective solution for your usage patterns.
Integration capabilities determine how effectively a RAG platform works with your existing technology stack. Evaluate each platform's API quality, available SDKs, and compatibility with frameworks like LangChain and LlamaIndex. Consider integration with your preferred LLM providers, data sources, and analytics tools to ensure smooth data flow. Platforms with extensive integration options reduce development complexity and accelerate implementation timeframes, making them particularly valuable for organizations with diverse technology ecosystems. The right integration approach can significantly reduce maintenance costs while maximizing the value of your existing technology investments.
Conclusion
The enterprise RAG platform landscape has evolved to address diverse retrieval, security, and scalability requirements. Leading platforms like Elastic Enterprise Search, Pinecone, and Weaviate offer unique approaches to solving challenges in enterprise knowledge management and AI-driven search. The decision between specialized vector databases and comprehensive search platforms depends on organizational needs, with factors like data volume, query patterns, and security requirements influencing the optimal choice.
Data quality remains critical for RAG implementation success, with Firecrawl providing specialized capabilities for enhancing data collection and processing. The platform generates structured, LLM-friendly content from websites and external sources to help organizations overcome context limitations and data integration challenges. Adding quality external data to enterprise knowledge bases improves answer accuracy while maintaining the security and compliance standards required in enterprise environments.
For organizations planning to implement enterprise RAG, we recommend:
- Start with a pilot project focused on a specific use case with measurable outcomes before scaling to enterprise-wide deployment
- Evaluate platforms based on your industry requirements, prioritizing security in regulated industries and real-time capabilities for customer-facing applications
- Consider hybrid approaches that combine multiple retrieval methods for both semantic understanding and precision
- Establish clear performance metrics aligned with business objectives to quantify ROI and justify investment
- Regularly update your knowledge base to maintain data freshness and relevance as information evolves
