
TL;DR: Top web scraping tools by category
- AI-powered: Firecrawl, ScrapeGraphAI, Crawl4AI: best when a site's layout is complex, JavaScript-heavy, or inconsistent and you don't want to write manual selectors
- No-code: Octoparse, Browse.AI: best for non-technical users who need a drag-and-drop setup
- Python libraries: Beautiful Soup, Scrapy: best for developers who want full control over static or medium-scale scraping
- Browser automation: Selenium, Playwright, Puppeteer: best for dynamic, JavaScript-rendered sites that need full browser interaction
The best web scraping tools today handle most of the manual work: layout detection, JavaScript rendering, and the site-specific restrictions that used to require custom code for every page. Since joining Firecrawl, I've seen firsthand how much AI-powered tools have simplified a process that once meant labor-intensive, page-by-page maintenance.
That is why I have put together this list of the top web scraping tools across several categories: AI-powered tools, no-code or low-code platforms, Python libraries, and browser automation solutions. Each tool comes with its own pros and cons, and your choice will ultimately depend on two main factors: your technical background and your budget.
Deep Dives: For detailed comparisons, check our guides on open-source web scraping libraries and browser automation tools. For no-code options, explore n8n workflows and LangFlow visual development.
Some tools are designed for non-coders and offer visual interfaces or drag-and-drop workflows, while others provide full-featured libraries for those who prefer to write code and customize every detail. Pricing also varies widely, from free open-source libraries to premium cloud-based platforms.
AI web scraping tools
AI web scraping tools use machine learning and large language models (LLMs) to intelligently extract data from complex, JavaScript-heavy, or protected websites, enabling users to pinpoint and retrieve exactly the information they need with greater accuracy and efficiency than traditional methods.
1. Firecrawl
Firecrawl provides web context APIs built for AI agents. It covers the full workflow: find sources, scrape them, parse documents, and clean everything into token-efficient markdown or structured data your agent can use directly.
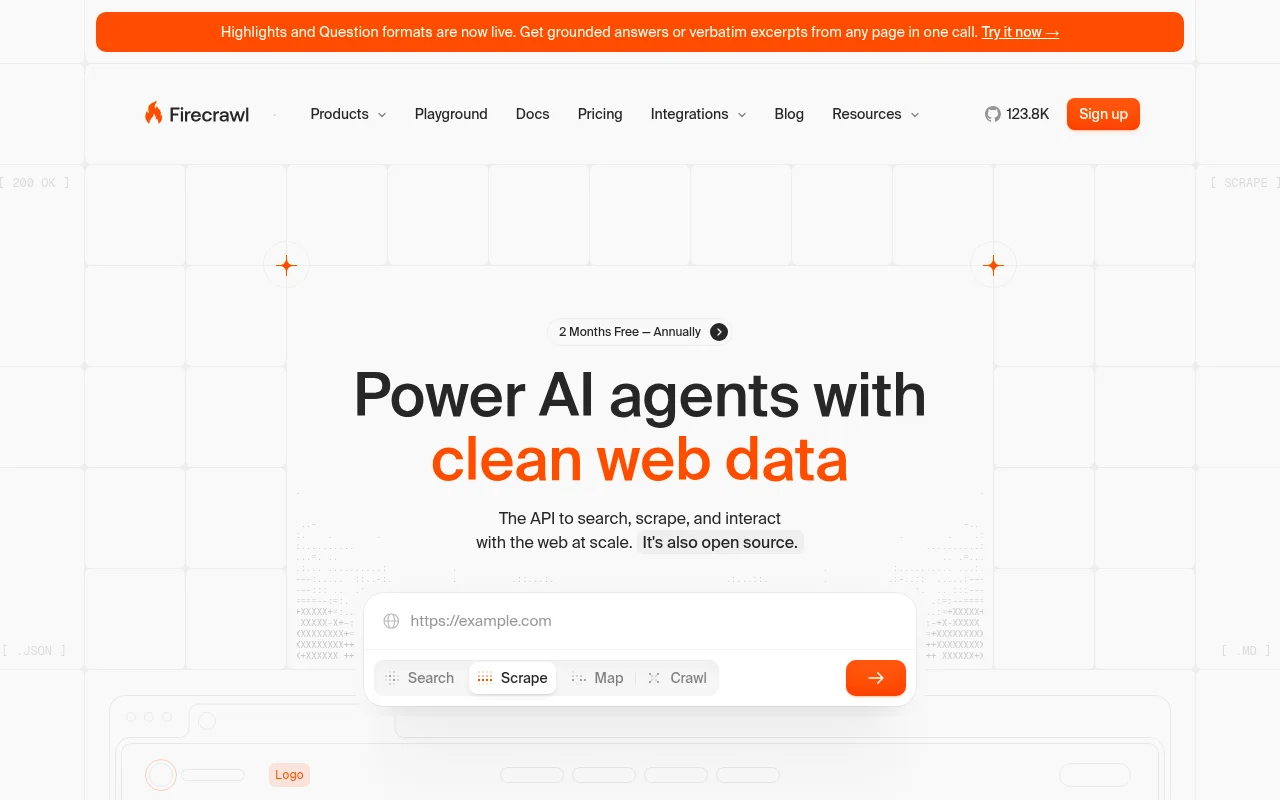
Key features:
- Search: Finds fresh, relevant sources from the live web and returns full page content alongside results, not just links
- Scrape: Turns any URL into clean markdown, structured JSON, or a screenshot. Works on the real web: JS-heavy sites, SPAs, and dynamic pages (see our scrape endpoint guide)
- Crawl: Gathers content from every page of a site, returning LLM-ready markdown for each
- Map: Discovers all URLs on a website without extracting content
- Parse: Converts PDFs and documents into usable text
- Interact: Handles clicks, form fills, logins, and dynamic pages in a real browser session
Pros:
- Sub-3-second scrapes and batch operations for high-volume AI agent loops.
- Works on the real web: JavaScript-heavy sites, SPAs, and geo-sensitive pages.
- Output formats built for AI: token-efficient markdown, JSON field extraction, and summary/highlight modes.
- One API replaces multi-vendor stacks: search, scrape, parse, crawl, and interact in a single integration.
Cons:
- Advanced features and customizations may have a learning curve, particularly for non-technical users.
Pricing:
- Free: $0/month
- Hobby: $16/month
- Standard: $83/month
- Growth: $333/month
- Enterprise: custom pricing
Example code:
from firecrawl import FirecrawlApp
app = FirecrawlApp(api_key="fc-YOUR_API_KEY")
# Scrape a website:
scrape_result = app.scrape_url('https://abid.work/', formats=['markdown', 'html'])
print(scrape_result)2. ScrapeGraphAI
ScrapeGraphAI is an AI-powered web data extraction tool that excels at understanding complex web page structures, enabling highly accurate data extraction. It is available as both an open-source library and a premium API.
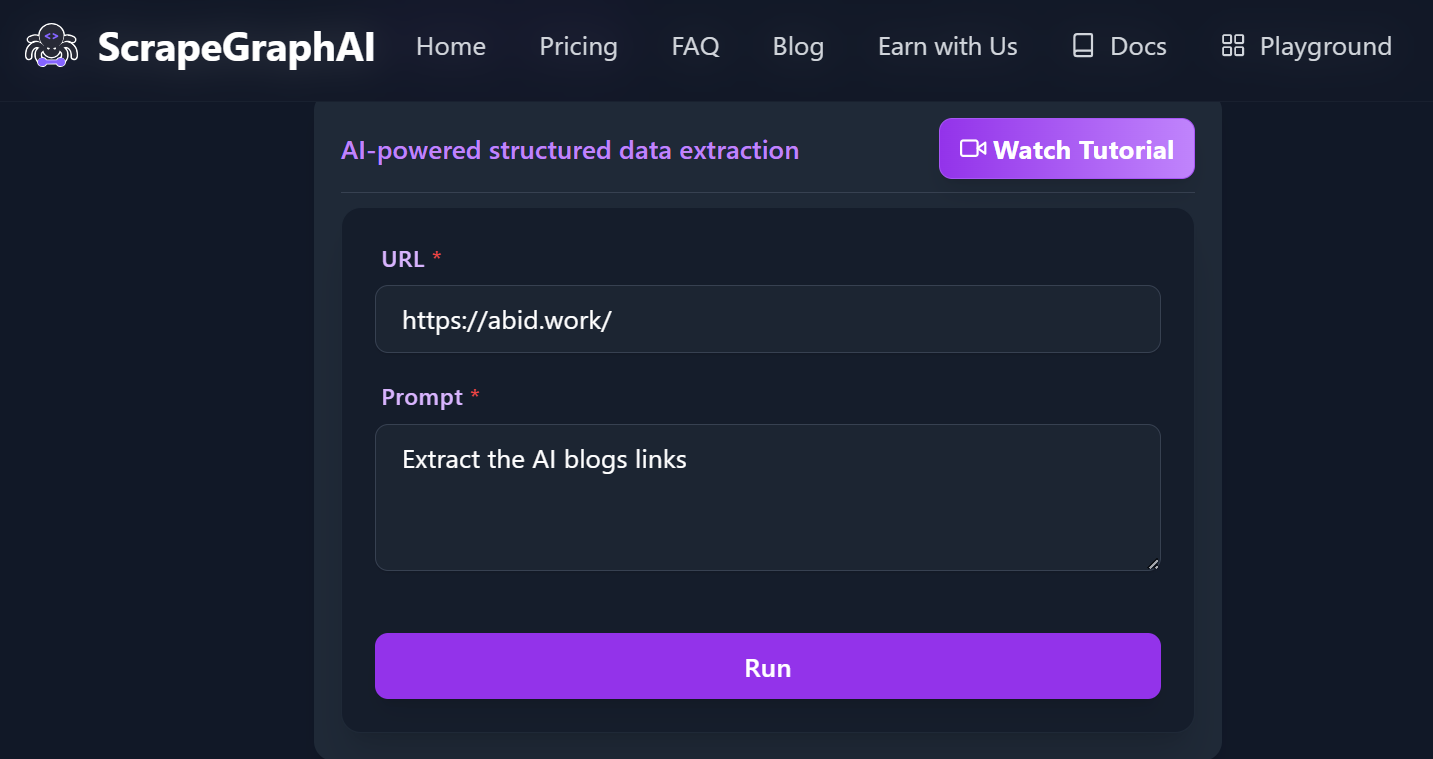
Key features:
- SmartScraper: AI-driven extraction for any webpage, requiring only a user prompt and input source.
- SearchScraper: LLM-powered web search service.
- SmartCrawler: Crawls and extracts data from multiple pages.
- Markdownify: Converts website content into Markdown format.
Pros:
- AI-powered extraction reduces the need for manual HTML analysis
- Extremely flexible and adaptable, handling a wide range of web structures and content types.
- Open-source with MIT license.
Cons:
- Performance and accuracy can vary depending on the complexity of the target website and the quality of AI prompts.
- Support and feature set may be less extensive than some large commercial competitors.
- Results may sometimes need manual validation or post-processing.
Pricing:
- Free: $0/month
- Starter: $17/month
- Growth: $85/month
- Pro: $425/month
- Enterprise: custom pricing
Example code:
from scrapegraph_py import Client
from scrapegraph_py.logger import sgai_logger
sgai_logger.set_logging(level="INFO")
# Initialize the client
sgai_client = Client(api_key="your-sgai-api-key")
# SmartScraper request
response = sgai_client.smartscraper(
website_url="https://abid.work/",
user_prompt="Extract the AI blogs' links"
)
# Print the response
print(f"Request ID: {response['request_id']}")
print(f"Result: {response['result']}")
if response.get('reference_urls'):
print(f"Reference URLs: {response['reference_urls']}")
sgai_client.close()3. Crawl4AI
Crawl4AI is an open-source Python library optimized for LLM-based web scraping agents. It leverages large language models to extract structured data from both static and dynamic websites, including those with complex JavaScript rendering.

Key features:
- Adaptive Crawling: Learns website patterns and knows when to stop, optimizing crawl efficiency.
- Structured Data Extraction: Supports LLM-driven, CSS/XPath, and schema-based extraction for structured outputs.
- Markdown Generation: Produces clean, concise Markdown optimized for LLMs and RAG pipelines.
- Flexible Browser Control: Offers session management, proxy support, and multi-browser compatibility.
- Media & Metadata Extraction: Captures images, videos, tables, and metadata, including PDF processing.
Pros:
- Fully open source with no API keys or paywalls, ensuring accessibility and transparency.
- Fast crawling and efficient resource management.
- Easy deployment via pip or Docker, with cloud integration and scalable architecture.
Cons:
- Advanced features and configuration options may present a learning curve for beginners.
- Performance and extraction quality can vary depending on website complexity and JavaScript rendering requirements.
- As an open-source project, some features may be experimental or subject to change.
Pricing: Free and open-source (users may pay for LLM API calls and infrastructure).
Example code:
import asyncio
from crawl4ai import *
async def main():
async with AsyncWebCrawler() as crawler:
result = await crawler.arun(
url="https://abid.work/",
)
print(result.markdown)
if __name__ == "__main__":
asyncio.run(main())If you want to know other tools in this category, please check out the blog Top 7 AI-Powered Web Scraping Solutions in 2025.
No-code or low-code web scraping tools
No-code or low-code web scraping tools are designed for non-technical users, allowing anyone to extract website data using intuitive point-and-click interfaces, pre-built templates, and AI-powered automation.
4. Octoparse
Octoparse is a no-code web scraping platform with a drag-and-drop interface, making data extraction accessible to everyone, regardless of technical background. It offers pre-built templates, cloud extraction, and anonymous scraping features.
P.S: For developer-centric or API-first tools in the same space, see the best Octoparse alternatives.
Key features:
- No-code Workflow Designer: Build and visualize scraping tasks in a browser-based interface.
- AI-powered Assistant: Auto-detects data fields and provides real-time tips to streamline setup.
- Cloud-based Automation: Schedule scrapers to run 24/7 in the cloud, with automatic data export and OpenAPI support.
- Advanced Interaction: Supports proxies, infinite scrolling, AJAX, dropdowns, and more.
- Template Library: Hundreds of ready-made templates for popular sites like Twitter, Google Maps, LinkedIn, Amazon, and more.
- Flexible Export: Export data in multiple formats and integrate with other tools via API.
Pros:
- No code user-friendly interface, ideal for beginners and non-technical users.
- Fast setup with AI auto-detection and a large library of pre-built templates.
- Cloud-based automation enables hands-free, scheduled scraping.
Cons:
- Advanced customization is limited compared to code-based or open-source tools.
- Slower performance when dealing with large-scale scraping tasks.
- Free plan has significant limitations.
Pricing:
- Free: $0/month
- Standard: $99/month
- Professional: $249/month
- Enterprise: custom pricing
5. Browse.AI
Browse.AI is a no-code tool that lets users create "robots" to mimic human browsing and extract data. It is designed for business users seeking to automate data collection without technical expertise.
Key features:
- No-code Point-and-click Setup: Extract data from any website in minutes without writing code.
- AI-powered Monitoring: Automatically keeps your data up to date with site layout monitoring and human-like behavior emulation.
- Deep Scraping: Automate extraction from pages and subpages using connected robots.
- Prebuilt Robots: 200+ ready-to-use robots for popular sites and use cases, or create custom robots for any website.
- Cloud-based Automation: Schedule tasks to run at specific intervals and receive real-time alerts on data changes.
- Reliable Data Access: Proxy management and rate limiting for consistent extraction.
- Broad Integrations: Connect extracted data to Google Sheets, Airtable, Zapier, APIs, webhooks, and 7,000+ other apps.
Pros:
- Fast setup with intuitive point-and-click interface and prebuilt robots.
- Scalable for both small and enterprise-level data extraction needs.
- Reliable data extraction with AI-powered monitoring and automatic retries.
Cons:
- Some paid options are limited, and higher subscriptions can become costly.
- May face challenges with highly dynamic or login-protected websites.
- Extraction speed and reliability can vary depending on website complexity and JavaScript rendering requirements.
Pricing:
- Free: $0/month
- Personal: $19/month
- Professional: $69/month
- Premium: $500/month
Python web scraping tools
Python web scraping tools simplify collecting, parsing, and automating data extraction from websites. They can handle everything from static HTML to dynamic JavaScript-driven content, but require technical expertise.
6. Beautiful Soup
Beautiful Soup is a popular Python library for parsing HTML and XML documents, making it a go-to tool for web scraping tasks. It is typically used alongside the requests library. Its simple and intuitive API makes it beginner-friendly and ideal for small to medium-scale web scraping projects.
Key features:
- Accurate Parsing: Parses and navigates HTML and XML documents to extract data.
- Flexible Searching: Supports searching for elements by tag, class, id, attributes, and text content.
- Tree Navigation: Allows traversing the document tree to find parent, sibling, and child elements.
- Data Modification: Enables modification of the parsed document, such as editing or removing elements.
- Multiple Parser Support: Compatible with different parsers like
lxmlandhtml.parserfor speed and flexibility.
Pros:
- Excellent for small to medium-scale projects and quick prototyping.
- Flexible and capable for parsing and extracting data from HTML/XML
- Handles poorly formatted HTML well.
Cons:
- Lacks built-in support for handling JavaScript-rendered content.
- Can be slower than some alternatives when parsing very large documents.
- Requires manual handling of rate limiting and request management.
Pricing: Free and open-source.
Example code:
import requests
from bs4 import BeautifulSoup
url = "https://abid.work/"
response = requests.get(url)
html_content = response.content
soup = BeautifulSoup(html_content, "html.parser")
page_title = soup.title.string
print("Page Title:", page_title)7. Scrapy
Scrapy is an open-source Python framework designed for large-scale web scraping and crawling. It enables developers to build custom spiders that extract data from websites efficiently, using asynchronous requests and a scalable architecture.
Key features:
- Asynchronous Requests: Handles multiple requests concurrently for high-speed scraping.
- Custom Spiders: Define Python classes called "spiders" to crawl pages and extract data flexibly
- Built-in Data Pipelines: Process, clean, and store scraped data in various formats (JSON, CSV, databases).
- Reliable Selectors: Scrapy supports both CSS and XPath selectors for reliable data extraction.
- Automatic Throttling and Retries: Manages request rates and handles failed requests gracefully.
Pros:
- Highly scalable and efficient for large-scale scraping projects.
- Asynchronous processing enables fast data extraction from multiple sources.
- Strong community support and extensive documentation.
Cons:
- Steeper learning curve compared to simpler libraries like Beautiful Soup.
- Limited support for JavaScript-heavy websites without additional tools or middleware.
- Requires more setup and configuration for basic tasks.
Pricing: Free and open-source.
Example code:
import scrapy
class AbidSpider(scrapy.Spider):
name = "abid"
start_urls = ["https://abid.work/"]
def parse(self, response):
# Extract and yield the page title
yield {"page_title": response.xpath('//title/text()').get()}
# Extract and yield all <h2> headings
for heading in response.xpath('//h2/text()').getall():
yield {"h2_heading": heading}
# To run this spider without a Scrapy project, use:
# scrapy runspider abid_spider.py -o results.jsonIf you are interested in other tools in this category, check out the blog Best Open-source Web Scraping Libraries in 2025.
Browser automation frameworks for web scraping
Imagine you need to automate a complex series of actions on a website, such as logging in, clicking buttons, and navigating menus, all to extract data. This is where browser automation tools come into play. They are designed to scrape data from modern, highly interactive websites that use JavaScript, dynamic content, or that require human-like interactions to access and retrieve information.
8. Selenium
Selenium is a long-standing, open-source browser automation framework widely used for both web testing and web scraping. Supporting multiple programming languages (including Python, Java, C#, and JavaScript) and all major browsers, Selenium enables users to automate browser actions such as clicking, form submission, navigation, and data extraction.
Key features:
- Cross-browser Support: Works with Chrome, Firefox, Edge, Safari, etc.
- Multi-language Compatibility: Supports popular languages including Python, Java, C#, and more.
- Full Browser Automation: Automates clicking, typing, scrolling, navigation, file uploads.
- Dynamic content Handling: Excellent for JavaScript-rendered pages and AJAX interactions
- Headless Mode: Runs browsers in headless mode for faster, GUI-less operation.
Pros:
- Great for automating complex workflows beyond simple scraping.
- Supports scraping of dynamic and JavaScript-heavy websites.
- Integrates easily with other testing and automation tools.
Cons:
- It launches full browsers, which is resource-heavy and slower than libraries like
requests. - Downloads full page assets (CSS, JS, images), increasing load.
- Requires more setup and maintenance compared to lightweight scraping libraries.
Pricing: Free and open-source.
Example code:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import time
options = Options()
options.add_argument("--headless") # Headless mode, no GUI
# Do NOT add --user-data-dir unless necessary
driver = webdriver.Chrome(options=options)
try:
driver.get("https://abid.work/")
time.sleep(2) # Wait for page to load
print("Page Title:", driver.title)
h2_elements = driver.find_elements(By.TAG_NAME, "h2")
for h2 in h2_elements:
print("H2 Heading:", h2.text)
finally:
driver.quit()9. Playwright
Playwright is a modern, open-source browser automation tool developed by Microsoft, designed for fast and reliable automation of web applications. It supports automation and testing across Chromium, Firefox, and WebKit browsers using a single API, making it ideal for scraping and interacting with modern, dynamic web apps
Key features:
- Cross-browser Automation: Supports Chromium, Firefox, and WebKit with a unified API
- Headless and Headed Modes: Run browsers with or without a GUI for flexible automation.
- Fast Execution: Optimized for speed and reliability, with automatic waits and retries.
- Advanced Interaction: Automate clicks, typing, file uploads, downloads, and handle dialogs.
- Flexible Selectors: Use CSS, XPath, and text selectors for precise element targeting.
Pros:
- Fast, reliable, and consistent automation across all major browsers.
- Excellent for scraping and testing modern, dynamic web applications.
- Supports multiple programming languages and integrates with CI/CD pipelines.
Cons:
- Slightly steeper learning curve compared to simpler scraping libraries.
- More resource-intensive than lightweight HTTP-based scrapers.
- May require additional configuration for complex web infrastructure.
Pricing: Free and open-source.
Example code:
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
await page.goto("https://abid.work/")
# Get the page title
title = await page.title()
print("Page Title:", title)
# Get all <h2> headings
h2s = await page.locator("h2").all_text_contents()
for h2 in h2s:
print("H2 Heading:", h2)
await browser.close()
asyncio.run(main())10. Puppeteer
Puppeteer is a high-performance Node.js library for automating Chrome and Chromium browsers, providing a flexible API for browser automation and web scraping tasks. It is especially effective for scraping dynamic, JavaScript-heavy websites and automating complex browser interactions.

Key features:
- Headless Browser Automation: Runs Chrome or Chromium in headless mode for fast, resource-efficient scraping.
- High-level API: Offers a simple, full-featured API to control browser actions such as navigation, clicking, typing, and form submission.
- JavaScript Execution: Handles JavaScript-rendered content and AJAX requests seamlessly.
- Screenshot and PDF Generation: Capture screenshots or generate PDFs of web pages for reporting or archiving.
- Network Interception: Intercept and modify network requests and responses for advanced scraping scenarios.
Pros:
- Excellent support for JavaScript-heavy and single-page applications.
- Maintained by the Chrome DevTools team, ensuring up-to-date browser compatibility.
- Supports both headless and full browser modes for different use cases.
Cons:
- Requires Node.js environment and familiarity with JavaScript.
- Limited to Chrome and Chromium browsers (no native support for Firefox or Safari).
- Heavier than pure HTTP scrapers due to full browser usage.
Pricing: Free and open-source.
Example code:
import puppeteer from "puppeteer";
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto("https://abid.work/");
await page.setViewport({ width: 1080, height: 1024 });
// Get the page title
const pageTitle = await page.title();
console.log("Page Title:", pageTitle);
// Get all <h2> headings
const h2Headings = await page.$$eval("h2", (elements) =>
elements.map((el) => el.textContent.trim()),
);
for (const heading of h2Headings) {
console.log("H2 Heading:", heading);
}
await browser.close();Discover browser automation tools and their use cases by reading the blog Top 9 Browser Automation Tools for Web Testing and Scraping in 2025.
Feature and pricing comparison
Here is a highlight of the top web scraping tools, giving you a quick, byte-sized overview of their type, pricing, and key features.
| Tool | Type | Paid Plans (Monthly) | Key Features |
|---|---|---|---|
| Firecrawl | AI, API, Python | 16 (Hobby), 83 (Standard), $333 (Growth), Add-ons, Enterprise | Web context APIs for AI agents: Search, Scrape, Parse, Crawl, Map, Interact. |
| ScrapeGraphAI | AI, Python, API | 17 (Starter), 85 (Growth), $425 (Pro), Enterprise | Advanced AI extraction, open-source & API, LLM-driven |
| Crawl4AI | AI, Python, OpenSrc | Free (infra/LLM costs extra) | LLM-powered, context-aware, open-source |
| Octoparse | No-Code, Cloud | 99 (Standard), 249 (Professional), Enterprise | Drag-and-drop, templates, AI assistant |
| Browse.AI | No-Code, Browser | 19 (Personal), 69 (Professional), $500 (Premium) | Visual robots, easy setup, monitoring |
| Beautiful Soup | Python Library | Free | Simple parsing, beginner-friendly, HTML/XML |
| Scrapy | Python Framework | Free | Large-scale, async, extensible |
| Selenium | Browser Automation | Free | Multi-step forms, cross-browser, multi-language |
| Playwright | Browser Automation | Free | Interactive dashboards, JavaScript-heavy sites, fast execution |
| Puppeteer | Browser Automation | Free | Scraping SPAs, screenshots, headless Chrome/Chromium |
Which web scraping tool should you choose?
Web scraping is a highly valuable skill that can open up profitable opportunities. You can even earn hundreds of dollars per month by collecting and providing data to companies. Many large language models and machine learning systems rely on fresh, structured, and clean datasets, making web scraping an essential part of modern AI and analytics workflows.
Depending on your technical experience and budget, you can choose from the tools above to start your own web scraping project and build a custom data pipeline for analytics or machine learning.
The applications of web scraping are virtually endless. If you are eager to get started but unsure where to begin, check out 15 Python Web Scraping Projects: From Beginner to Advanced for inspiration and practical ideas to kick off your journey.
