
Update (as of 4th Feb, 2026): Introducing Agent: The Next Evolution of Extract. We’re launching /agent — the successor to /extract. It’s faster, more reliable, and doesn’t require URLs. Just describe what you need and let the AI agent find and extract the data for you. Try Agent now.
Welcome to Day 6 of Firecrawl's Launch Week! We're excited to introduce v1 support for LLM Extract.
Introducing the Extract Format
LLM extraction is now available in v1 under the extract format. To extract structured from a page, you can pass a schema to the endpoint or just provide a prompt.
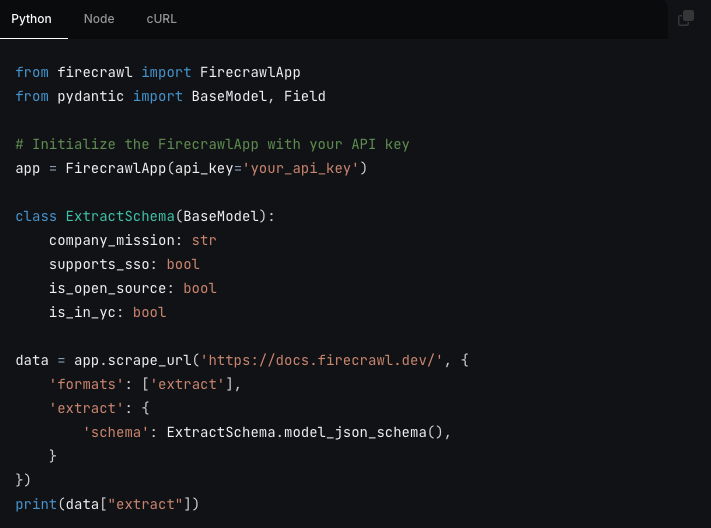
Output
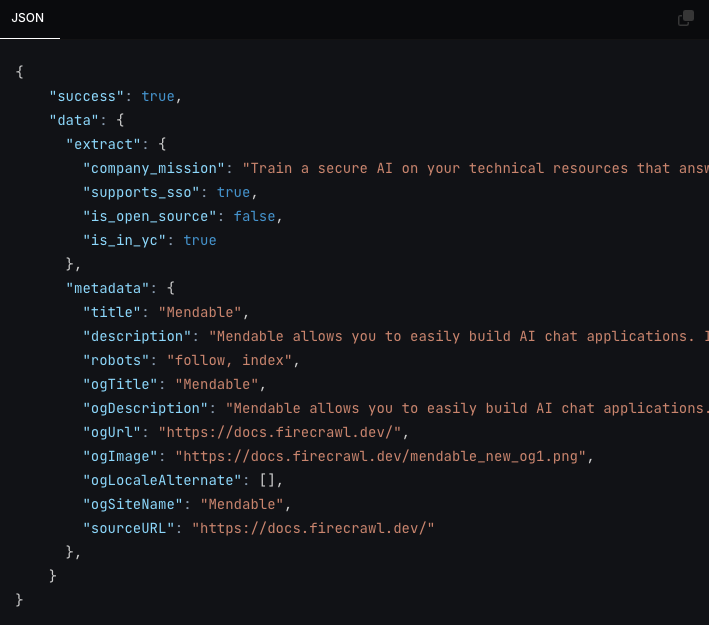
Extracting without schema (New)
You can now extract without a schema by just passing a prompt to the endpoint. The LLMs choose the structure of the data.
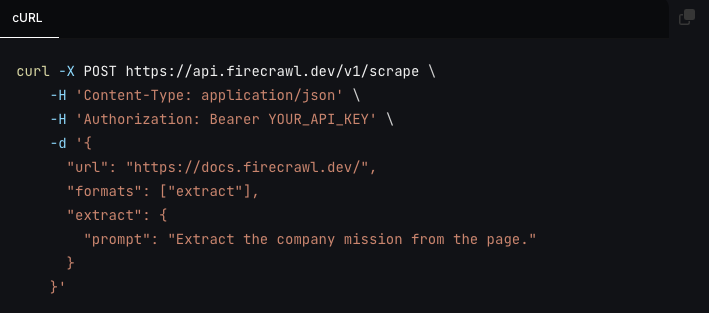
Learn More
Learn more about the extract format in our documentation.
