
Introduction
Finding the perfect job can feel like searching for a needle in a haystack. As a developer, you might spend hours scanning through job boards, trying to determine if each position matches your skills and experience. What if we could automate this process using AI?
In this tutorial, we'll build a sophisticated job matching system that combines several powerful technologies:
- Firecrawl for intelligent web scraping of job postings and resume parsing
- Claude 3.5 Sonnet for job matching analysis
- Supabase for managing job sources and tracking
- Discord for when there is a matching job
- Streamlit for a user-friendly web interface
Our application will:
- Automatically scrape user-provided job boards at regular intervals
- Parse your resume from a PDF
- Use AI to evaluate each job posting against your qualifications
- Send notifications to Discord when strong matches are found
- Provide a web interface for managing job sources and viewing results
By the end of this tutorial, you'll have a fully automated job search assistant that runs in the cloud and helps you focus on the opportunities that matter most. Whether you're actively job hunting or just keeping an eye on the market, this tool will save you countless hours of manual searching and evaluation.
If this project sounds interesting, you can start using it straight away by cloning its GitHub repository. The local setup instructions are provided in the README.
On the other hand, if you want to understand how the different parts of the project work together, continue reading!
Overview of the App
Before diving into the technical details, let's walk through a typical user journey to understand how the app works.
The process starts with the user adding web pages with job listings. Here are examples of acceptable pages:
https://datacamp.com/jobshttps://openai.com/careers/search/https://apply.workable.com/huggingface
As you can probably tell from the example URLs, the app doesn't work with popular job platforms like Indeed or Glassdoor. This is because these platforms already have sophisticated job matching functionality built into their systems. Instead, this app focuses on company career pages and job boards that don't offer automated matching - places where you'd normally have to manually review each posting. This allows you to apply the same intelligent matching to opportunities that might otherwise slip through the cracks.
Each job listings source is added to a Supabase database under the hood for persistence and displayed in the sidebar (you have the option to delete them). After the user inputs all job sources, they can add their PDF link in the main section of the app.
The app uses Firecrawl, an AI-powered scraping engine that extracts structured data from webpages and PDF documents. To parse resumes, Firecrawl requires a direct file link to the PDF.
After parsing the resume, the app crawls all job sources using Firecrawl to gather job listings. Each listing is then analyzed against the resume by Claude to determine compatibility. The UI clearly shows whether a candidate is qualified for each position, along with Claude's reasoning. For matching jobs, the app automatically sends notifications to the user's Discord account via a webhook.
The app automatically rechecks all job sources weekly to ensure you never miss a great opportunity.
The Tech Stack Used in the App
Building a reliable job matching system requires careful selection of tools that can handle complex tasks while remaining maintainable and cost-effective. Let's explore the core technologies that power our application and why each was chosen:
1. Firecrawl for AI-powered web scraping
At the heart of our job discovery system is Firecrawl, the context API to search, scrape, and interact with the web at scale. Unlike traditional scraping libraries that rely on brittle HTML selectors, Firecrawl uses natural language understanding to identify and extract content. This makes it ideal for our use case because:
- It can handle diverse job board layouts without custom code for each site
- Maintains reliability even when websites update their structure
- Handles JavaScript-rendered content out of the box
- Provides clean, structured data through Pydantic schemas
2. Claude 3.5 Sonnet for job matching
For the critical task of evaluating job fit, we use Claude 3.5 Sonnet through the LangChain framework. This AI model excels at understanding both job requirements and candidate qualifications in context. We chose Claude because:
- Handles complex job requirements effectively
- Offers consistent and reliable evaluations
- More cost-effective than GPT-4 for this use case
- Integrates seamlessly with LangChain for structured outputs
3. Supabase for data management
To manage job sources and tracking, we use Supabase as our database backend. This modern database platform offers:
- PostgreSQL database with a generous free tier
- Real-time capabilities for future features
- Simple REST API for database operations
- Built-in authentication system
- Excellent developer experience with their Python SDK
4. Discord for Notifications
When a matching job is found, our system sends notifications through Discord webhooks. This might seem like an unusual choice, but Discord offers several advantages:
- Free and widely adopted
- Rich message formatting with embeds
- Simple webhook integration
- Mobile notifications
- Supports dedicated channels for job alerts
- Threading for discussions about specific opportunities
5. Streamlit for user interface
The web interface is built with Streamlit, a Python framework for data applications. We chose Streamlit because:
- It enables rapid development of data-focused interfaces
- Provides built-in components for common UI patterns
- Handles async operations smoothly
- Offers automatic hot-reloading during development
- Requires no JavaScript knowledge
- Makes deployment straightforward
6. GitHub Actions for automation
To ensure regular job checking, we use GitHub Actions for scheduling. This service provides:
- Free scheduling for public repositories
- Built-in secret management
- Reliable cron scheduling
- Easy maintenance and modifications
- Integrated version control
- Comprehensive logging and monitoring
This carefully selected stack provides a robust foundation while keeping costs minimal through generous free tiers. The combination of AI-powered tools (Firecrawl and Claude) with modern infrastructure (Supabase, Discord, GitHub Actions) creates a reliable and scalable job matching system that can grow with your needs.
Most importantly, this stack minimizes maintenance overhead - a crucial factor for any automated system. The AI-powered components adapt to changes automatically, while the infrastructure services are managed by their respective providers, letting you focus on finding your next great opportunity rather than maintaining the system.
Breaking Down the App Components
When you look at the GitHub repository of the app, you will see the following file structure:
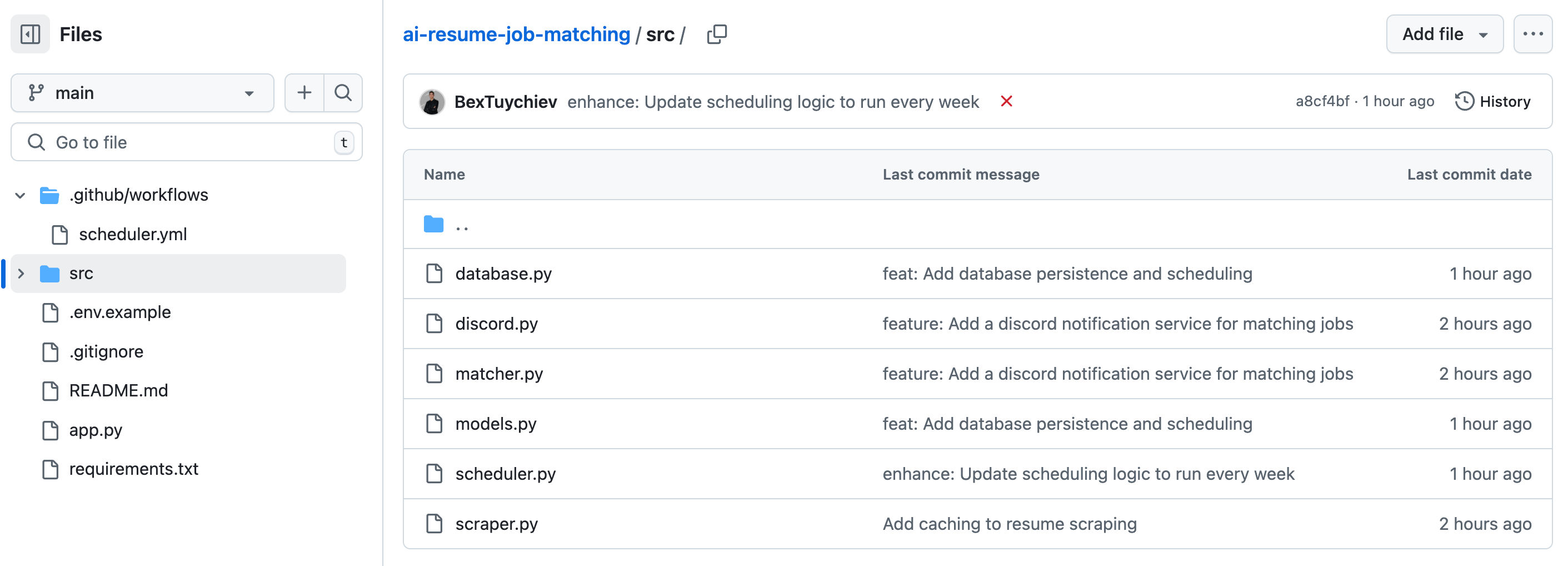
Several files in the repository serve common purposes that most developers will recognize:
.gitignore: Specifies which files Git should ignore when tracking changesREADME.md: Documentation explaining what the project does and how to use itrequirements.txt: Lists all Python package dependencies needed to run the project
Let's examine the remaining Python scripts and understand how they work together to power the application. The explanations will be in a logical order building from foundational elements to higher-level functionality.
1. Core data structures - src/models.py
At the heart of our job matching system are three Pydantic models that define the core data structures used throughout the application. These models not only provide type safety and validation but also serve as schemas that guide Firecrawl's AI in extracting structured data from web pages.
class Job(BaseModel):
title: str = Field(description="Job title")
url: str = Field(description="URL of the job posting")
company: str = Field(description="Company name")The Job model represents an individual job posting with three essential fields:
title: The position's nameurl: Direct link to the job postingcompany: Name of the hiring organization
This model is used by both the scraper to extract job listings and the Discord notifier to format job match notifications. The Field descriptions guide the Firecrawl's AI to better locate the HTML/CSS components containing the relevant information.
class JobSource(BaseModel):
url: str = Field(description="URL of the job board")
last_checked: Optional[datetime] = Field(description="Last check timestamp")The JobSource model tracks job board URLs and when they were last checked:
url: The job board's web addresslast_checked: Optional timestamp of the last scraping attempt
This model is primarily used by the database component to manage job sources and the scheduler to track when sources need to be rechecked.
class JobListings(BaseModel):
jobs: List[Job] = Field(description="List of job postings")Finally, the JobListings model serves as a container for multiple Job objects. This model is crucial for the scraper component, as it tells Firecrawl to extract all job postings from a page rather than just the first one it finds.
These models form the foundation of our application's data flow:
- The scraper uses them to extract structured data from web pages
- The database uses them to store and retrieve job sources
- The matcher uses them to process job details
- The Discord notifier uses them to format notifications
By defining these data structures upfront, we ensure consistency throughout the application and make it easier to modify the data model in the future if needed.
2. Database operations - src/database.py
The database component handles persistence of job sources using Supabase, a PostgreSQL-based backend service. This module provides essential CRUD (Create, Read, Update, Delete) operations for managing job board URLs and their check history.
class Database:
def __init__(self):
url = os.getenv("SUPABASE_URL")
key = os.getenv("SUPABASE_KEY")
self.client = create_client(url, key)
def save_job_source(self, url: str) -> None:
"""Save a job source to the database"""
self.client.table("job_sources").upsert(
{"url": url, "last_checked": None}
).execute()The Database class initializes a connection to Supabase using environment variables and provides four key methods:
-
save_job_source: Adds or updates a job board URL in the database. Theupsertoperation ensures no duplicate entries are created. -
delete_job_source: Removes a job source from tracking:
def delete_job_source(self, url: str) -> None:
self.client.table("job_sources").delete().eq("url", url).execute()get_job_sources: Retrieves all tracked job sources:
def get_job_sources(self) -> List[JobSource]:
response = self.client.table("job_sources").select("*").execute()
return [JobSource(**source) for source in response.data]update_last_checked: Updates the timestamp when a source was last checked:
def update_last_checked(self, url: str) -> None:
self.client.table("job_sources").update({"last_checked": "now()"}).eq(
"url", url
).execute()This database component is used by:
- The Streamlit interface (
app.py) for managing job sources through the sidebar - The scheduler (
scheduler.py) for tracking when sources were last checked - The automated GitHub Action workflow for persistent storage between runs
By using Supabase, we get a reliable, scalable database with minimal setup and maintenance requirements. The JobSource model we defined earlier ensures type safety when working with the database records throughout the application.
3. Scraping with Firecrawl - src/scraper.py
The scraper component handles all web scraping operations using Firecrawl, the context API to search, scrape, and interact with the web at scale. This module is responsible for parsing resumes and extracting job listings from various sources.
@st.cache_data(show_spinner=False)
def _cached_parse_resume(pdf_link: str) -> str:
"""Cached version of resume parsing"""
app = FirecrawlApp()
response = app.scrape_url(url=pdf_link)
return response["markdown"]
class JobScraper:
def __init__(self):
self.app = FirecrawlApp()The JobScraper class initializes a Firecrawl connection and provides three main methods:
parse_resume: Extracts text content from a PDF resume. Uses Streamlit's caching to avoid re-parsing the same resume:
async def parse_resume(self, pdf_link: str) -> str:
"""Parse a resume from a PDF link."""
return _cached_parse_resume(pdf_link)scrape_job_postings: Batch scrapes multiple job board URLs using theJobListingsschema to guide Firecrawl's extraction:
async def scrape_job_postings(self, source_urls: list[str]) -> list[Job]:
response = self.app.batch_scrape_urls(
urls=source_urls,
params={
"formats": ["extract"],
"extract": {
"schema": JobListings.model_json_schema(),
"prompt": "Extract information based on the schema provided",
},
},
)
jobs = []
for job in response["data"]:
jobs.extend(job["extract"]["jobs"])
return [Job(**job) for job in jobs]If you want to understand Firecrawl's syntax better, refer to our separate guide on its /scrape endpoint.
scrape_job_content: Retrieves the full content of a specific job posting for detailed analysis:
async def scrape_job_content(self, job_url: str) -> str:
"""Scrape the content of a specific job posting."""
response = self.app.scrape_url(url=job_url)
return response["markdown"]This entire scraper component is used by:
- The Streamlit interface (
app.py) for initial resume parsing and job discovery - The scheduler (
scheduler.py) for automated periodic job checks - The matcher component for detailed job content analysis
The use of Firecrawl's AI capabilities allows the scraper to handle diverse webpage layouts without custom selectors, while Streamlit's caching helps optimize performance by avoiding redundant resume parsing.
4. Job matching with Claude - src/matcher.py
The matcher component uses Claude 3.5 Sonnet through LangChain to evaluate whether a candidate's resume matches a job posting. This module provides intelligent job fit analysis with structured outputs.
class JobMatcher:
def __init__(self):
self.llm = ChatAnthropic(model="claude-3-5-sonnet-20241022", temperature=0)
self.response_schemas = [
ResponseSchema(
name="is_match",
description="Whether the candidate is a good fit for the job (true/false)",
),
ResponseSchema(
name="reason",
description="Brief explanation of why the candidate is or isn't a good fit",
),
]The JobMatcher class initializes with two key components:
-
A Claude instance configured for consistent outputs (temperature=0)
-
Response schemas that define the structure of the matching results:
is_match: Boolean indicating if the candidate is qualifiedreason: Explanation of the matching decision
self.prompt = ChatPromptTemplate.from_messages([
(
"system",
"You are an expert job interviewer with decades of experience. Analyze the resume and job posting to determine if the candidate is a good fit. Be critical in your assessment and accept only applicants that meet at least 75% of the requirements.",
),
(
"human",
"""
Resume:
{resume}
Job Posting:
{job_posting}
Determine if this candidate is a good fit and explain why briefly.
{format_instructions}
""",
),
])
self.output_parser = StructuredOutputParser.from_response_schemas(
self.response_schemas
)Note: The system prompt significantly affects how jobs are matched. You can make it more relaxed or strict when evaluating candidates. Use a looser prompt if you want to apply to more jobs, or a stricter one if you're being more selective.
The class also sets up:
- A prompt template that positions Claude as an expert interviewer and sets a high bar for matches (75% of requirements)
- An output parser that ensures responses follow the defined schema
async def evaluate_match(self, resume: str, job_posting: str) -> Dict:
"""Evaluate if a candidate is a good fit for a job."""
formatted_prompt = self.prompt.format(
resume=resume,
job_posting=job_posting,
format_instructions=self.output_parser.get_format_instructions(),
)
response = await self.llm.ainvoke(formatted_prompt)
return self.output_parser.parse(response.content)The evaluate_match method:
- Takes a resume and job posting as input
- Formats the prompt with the provided content
- Sends the request to Claude
- Parses and returns the structured response
This entire matcher component is used by:
- The Streamlit interface (
app.py) for real-time job matching - The scheduler (
scheduler.py) for automated matching checks - The Discord notifier to determine when to send alerts
By using Claude with structured outputs, we ensure consistent and reliable job matching that can be easily integrated into the broader application workflow.
5. Sending notifications with Discord - src/discord.py
The Discord component handles sending notifications when matching jobs are found. It uses Discord's webhook functionality to deliver rich, formatted messages about job matches.
class DiscordNotifier:
def __init__(self):
self.webhook_url = os.getenv("DISCORD_WEBHOOK_URL")First, we initialize the notifier with a Discord webhook URL from environment variables. This URL is where all notifications will be sent.
async def send_match(self, job: Job, match_reason: str):
"""Send a job match notification to Discord"""
if not self.webhook_url:
return
webhook = DiscordWebhook(url=self.webhook_url)
embed = DiscordEmbed(
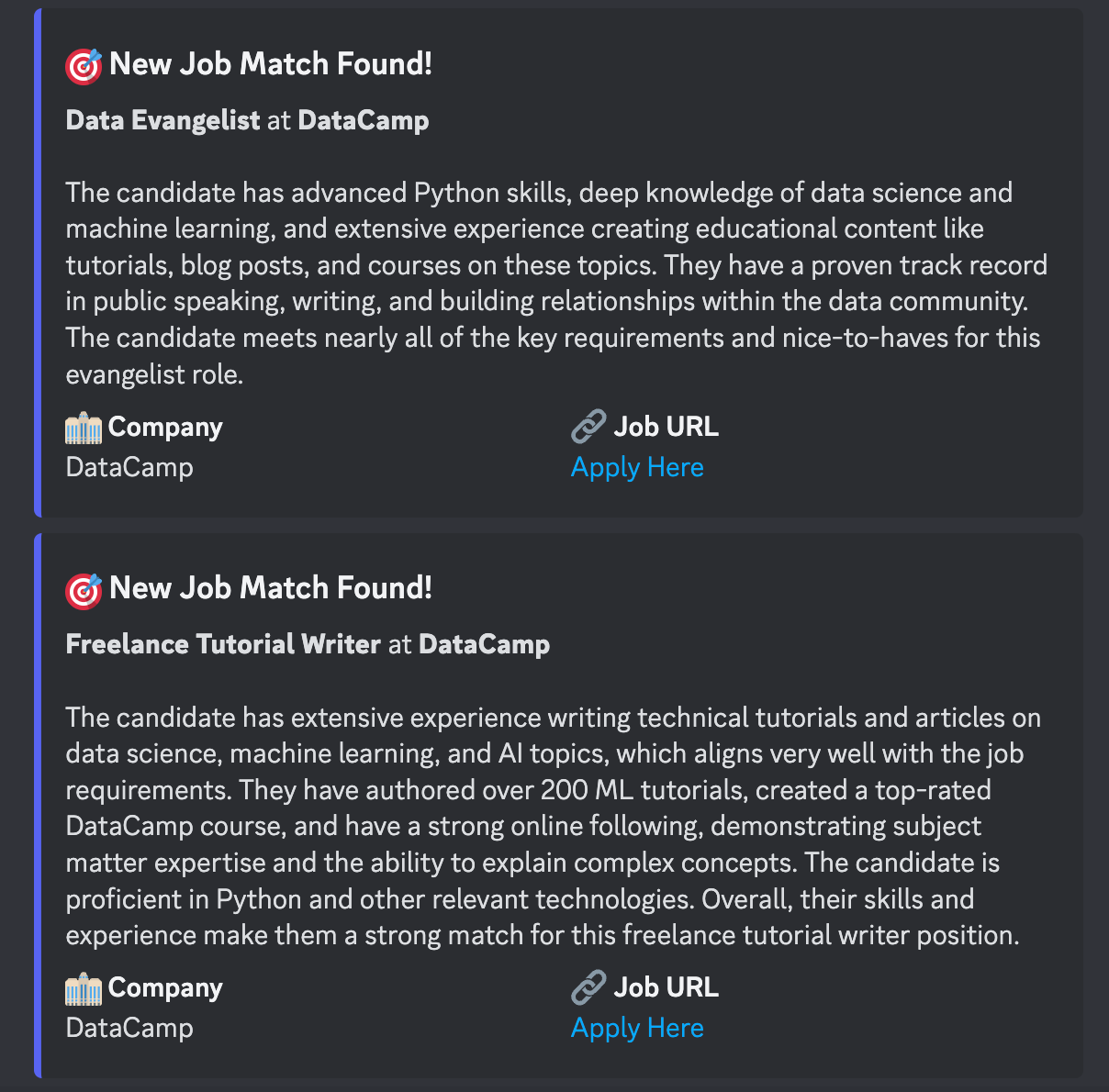
title=f"🎯 New Job Match Found!",
description=f"**{job.title}** at **{job.company}**\n\n{match_reason}",
color="5865F2", # Discord's blue color scheme
)The send_match method creates the notification:
- Takes a
Jobobject and the AI's matching reason as input - Creates a webhook connection to Discord
- Builds an embed message with:
- An eye-catching title with emoji
- Job title and company in bold
- The AI's explanation of why this job matches
# Add fields with job details
embed.add_embed_field(name="🏢 Company", value=job.company, inline=True)
embed.add_embed_field(
name="🔗 Job URL", value=f"[Apply Here]({job.url})", inline=True
)
webhook.add_embed(embed)
webhook.execute()Finally, the method:
- Adds structured fields for company and job URL
- Uses emojis for visual appeal
- Creates a clickable "Apply Here" link
- Sends the formatted message to Discord
This component is used by:
- The matcher component when a job match is found
- The scheduler for automated notifications
- The Streamlit interface for real-time match alerts
The use of Discord embeds provides a clean, professional look for notifications while making it easy for users to access job details and apply links directly from the message.
6. Automated source checking script - src/scheduler.py
The scheduler component handles automated periodic checking of job sources, coordinating between all other components to continuously monitor for new matching positions.
class JobScheduler:
def __init__(self):
self.scraper = JobScraper()
self.matcher = JobMatcher()
self.notifier = DiscordNotifier()
self.db = Database()
self.resume_url = os.getenv("RESUME_URL")
self.check_interval = int(os.getenv("CHECK_INTERVAL_MINUTES", "15"))
self.processed_jobs = set()
logger.info(f"Initialized scheduler with {self.check_interval} minute interval")The JobScheduler class initializes with:
- All necessary components (scraper, matcher, notifier, database)
- Resume URL from environment variables
- Configurable check interval (defaults to 15 minutes)
- A set to track processed jobs and avoid duplicates
- Logging setup for monitoring operations
async def process_source(self, source):
"""Process a single job source"""
try:
logger.info(f"Processing source: {source.url}")
# Parse resume
resume_content = await self.scraper.parse_resume(self.resume_url)
# Get jobs from source
jobs = await self.scraper.scrape_job_postings([source.url])
logger.info(f"Found {len(jobs)} jobs from {source.url}")The process_source method starts by:
- Logging the current operation
- Parsing the user's resume
- Scraping all jobs from the given source
# Process new jobs
for job in jobs:
if job.url in self.processed_jobs:
logger.debug(f"Skipping already processed job: {job.url}")
continue
job_content = await self.scraper.scrape_job_content(job.url)
result = await self.matcher.evaluate_match(resume_content, job_content)
if result["is_match"]:
logger.info(f"Found match: {job.title} at {job.company}")
await self.notifier.send_match(job, result["reason"])
self.processed_jobs.add(job.url)For each job found, it:
- Skips if already processed
- Scrapes the full job description
- Evaluates the match against the resume
- Sends a Discord notification if it's a match
- Marks the job as processed
async def run(self):
"""Main scheduling loop"""
logger.info("Starting job scheduler...")
while True:
try:
sources = self.db.get_job_sources()
logger.info(f"Found {len(sources)} job sources")The run method starts the main loop by:
- Getting all job sources from the database
- Logging the number of sources found
for source in sources:
if not source.last_checked or (
datetime.utcnow() - source.last_checked
> timedelta(minutes=self.check_interval)
):
await self.process_source(source)
else:
logger.debug(
f"Skipping {source.url}, next check in "
f"{(source.last_checked + timedelta(minutes=self.check_interval) - datetime.utcnow()).total_seconds() / 60:.1f} minutes"
)
await asyncio.sleep(60) # Check every minuteFor each source, it:
- Checks if it needs processing (never checked or interval elapsed)
- Processes the source if needed
- Logs skipped sources with time until next check
- Waits a minute before the next iteration
except Exception as e:
logger.error(f"Scheduler error: {str(e)}")
await asyncio.sleep(60)Error handling:
- Catches and logs any exceptions
- Waits a minute before retrying
- Ensures the scheduler keeps running despite errors
This component is used by:
- The GitHub Actions workflow for automated checks
- The command-line interface for manual checks
- The logging system for monitoring and debugging
The extensive logging helps track operations and diagnose issues, while the modular design allows for easy maintenance and updates.
7. User interface with Streamlit - app.py
The Streamlit interface provides a user-friendly way to manage job sources and run manual job matching checks. Let's break down each component:
- First, we set up the necessary imports and helper functions:
import streamlit as st
import asyncio
from dotenv import load_dotenv
from src.scraper import JobScraper
from src.matcher import JobMatcher
from src.discord import DiscordNotifier
from src.database import Database
load_dotenv()
async def process_job(scraper, matcher, notifier, job, resume_content):
"""Process a single job posting"""
job_content = await scraper.scrape_job_content(job.url)
result = await matcher.evaluate_match(resume_content, job_content)
if result["is_match"]:
await notifier.send_match(job, result["reason"])
return job, resultThe process_job function handles the core job matching logic for a single posting:
-
Scrapes the full job content using the provided URL
-
Evaluates if the resume matches the job requirements
-
Sends a notification if there's a match
-
Returns both the job and match result for further processing
-
The main application setup and sidebar for managing job sources:
async def main():
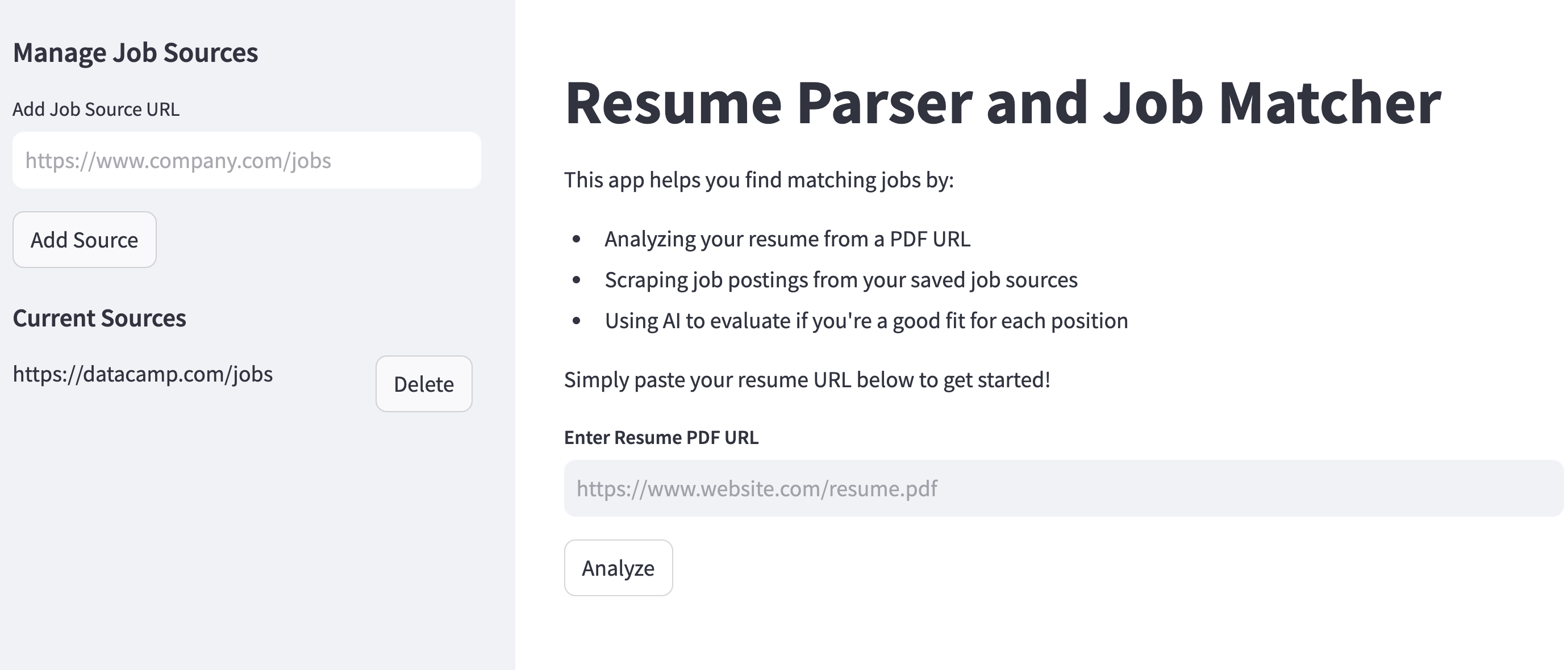
st.title("Resume Parser and Job Matcher")
# Initialize services
scraper = JobScraper()
matcher = JobMatcher()
notifier = DiscordNotifier()
db = Database()
# Sidebar for managing job sources
with st.sidebar:
st.header("Manage Job Sources")
new_source = st.text_input("Add Job Source URL")
if st.button("Add Source"):
db.save_job_source(new_source)
st.success("Job source added!")The main() function sets up the core Streamlit application interface:
- Creates a title for the app
- Initializes the key services (scraper, matcher, notifier, database)
- Adds a sidebar with controls for managing job source URLs
- Provides a text input and button to add new job sources
- Saves valid sources to the database
The sidebar allows users to maintain a list of job boards and company career pages to monitor for new postings.
- The source management interface:
# List and delete existing sources
st.subheader("Current Sources")
for source in db.get_job_sources():
col1, col2 = st.columns([3, 1])
with col1:
st.text(source.url)
with col2:
if st.button("Delete", key=source.url):
db.delete_job_source(source.url)
st.rerun()This section displays the list of current job sources and provides delete functionality:
- Shows a "Current Sources" subheader
- Iterates through all sources from the database
- Creates a two-column layout for each source
- First column shows the source URL
- Second column has a delete button
- When delete is clicked, removes the source and refreshes the page
The delete functionality helps users maintain their source list by removing outdated or unwanted job boards. The rerun() call ensures the UI updates immediately after deletion.
- The main content area with instructions and resume input:
st.markdown(
"""
This app helps you find matching jobs by:
- Analyzing your resume from a PDF URL
- Scraping job postings from your saved job sources
- Using AI to evaluate if you're a good fit for each position
Simply paste your resume URL below to get started!
"""
)
resume_url = st.text_input(
"**Enter Resume PDF URL**",
placeholder="https://www.website.com/resume.pdf",
)- The job analysis workflow:
if st.button("Analyze") and resume_url:
with st.spinner("Parsing resume..."):
resume_content = await scraper.parse_resume(resume_url)
sources = db.get_job_sources()
if not sources:
st.warning("No job sources configured. Add some in the sidebar!")
return
with st.spinner("Scraping job postings..."):
jobs = await scraper.scrape_job_postings([s.url for s in sources])- Parallel job processing and results display:
with st.spinner(f"Analyzing {len(jobs)} jobs..."):
tasks = []
for job in jobs:
task = process_job(scraper, matcher, notifier, job, resume_content)
tasks.append(task)
for coro in asyncio.as_completed(tasks):
job, result = await coro
st.subheader(f"Job: {job.title}")
st.write(f"URL: {job.url}")
st.write(f"Match: {'✅' if result['is_match'] else '❌'}")
st.write(f"Reason: {result['reason']}")
st.divider()
st.success(f"Analysis complete! Processed {len(jobs)} jobs.")This section creates tasks to analyze multiple jobs simultaneously by comparing them against the user's resume. As each analysis completes, it displays the results including job title, URL, match status and reasoning. The parallel approach makes the processing more efficient than analyzing jobs one at a time.
The interface provides:
- A sidebar for managing job sources
- Clear instructions for users
- Real-time feedback during processing
- Visual indicators for matches (✅) and non-matches (❌)
- Detailed explanations for each job evaluation
- Parallel processing for better performance
This component ties together all the backend services into a user-friendly interface that makes it easy to manage job sources and run manual checks.
8. GitHub Actions workflow - .github/workflows/scheduler.yml
The GitHub Actions workflow automates the job checking process by running the scheduler at regular intervals. Let's break down the configuration:
- First, we define the workflow name and triggers:
name: Job Matcher Scheduler
on:
push:
branches: [main]
schedule:
- cron: "0 0 * * 1" # Run every Monday at midnightThis configuration:
- Names the workflow "Job Matcher Scheduler"
- Triggers on pushes to the main branch (for testing)
- Runs automatically every Monday at midnight using cron syntax
- 0: Minute (0)
- 0: Hour (0 = midnight)
- *: Day of month (any)
- *: Month (any)
- 1: Day of week (1 = Monday)
- Define the job and its environment:
jobs:
check-jobs:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: "3.10"This section:
- Creates a job named "check-jobs"
- Uses the latest Ubuntu runner
- Checks out the repository code
- Sets up Python 3.10
- Install dependencies:
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt- Set up environment variables and run the scheduler:
- name: Run job checker
env:
FIRECRAWL_API_KEY: ${{ secrets.FIRECRAWL_API_KEY }}
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
DISCORD_WEBHOOK_URL: ${{ secrets.DISCORD_WEBHOOK_URL }}
RESUME_URL: ${{ secrets.RESUME_URL }}
SUPABASE_URL: ${{ secrets.SUPABASE_URL }}
SUPABASE_KEY: ${{ secrets.SUPABASE_KEY }}
CHECK_INTERVAL_MINUTES: 15
run: |
python -m src.schedulerThis final step:
- Sets up all necessary environment variables from GitHub Secrets
- Configures the check interval
- Runs the scheduler script
The workflow provides:
- Automated weekly job checks
- Secure handling of sensitive credentials
- Consistent environment for running checks
- Detailed logs of each run
- Easy modification of the schedule
To use this workflow, you need to:
- Add all required secrets to your GitHub repository
- Ensure your repository is public (for free GitHub Actions minutes)
- Verify the workflow is enabled in your Actions tab
The weekly schedule helps stay within GitHub's free tier limits while still regularly checking for new opportunities.
Conclusion
We've built a powerful automated job matching system that combines several modern technologies into a cohesive solution. By integrating Firecrawl for web scraping, Claude AI for intelligent matching, Discord for notifications, GitHub Actions for scheduling, and Supabase for storage, we've created a practical tool that automates the tedious parts of job searching. This allows job seekers to focus their energy on more important tasks like preparing for interviews and improving their skills.
Next Steps
The modular design of this system opens up many possibilities for future enhancements. You could expand support to additional job boards, implement more sophisticated matching algorithms, or add alternative notification methods like email. Consider building a mobile interface or adding analytics to track your application success rates. The foundation we've built makes it easy to adapt and enhance the system as your needs evolve. Feel free to fork the repository and customize it to match your specific job search requirements.
