Introducing web-scale /monitor - always-on search that pings your agent the moment something comes online. Read the docs →
Blog
Firecrawl Blog
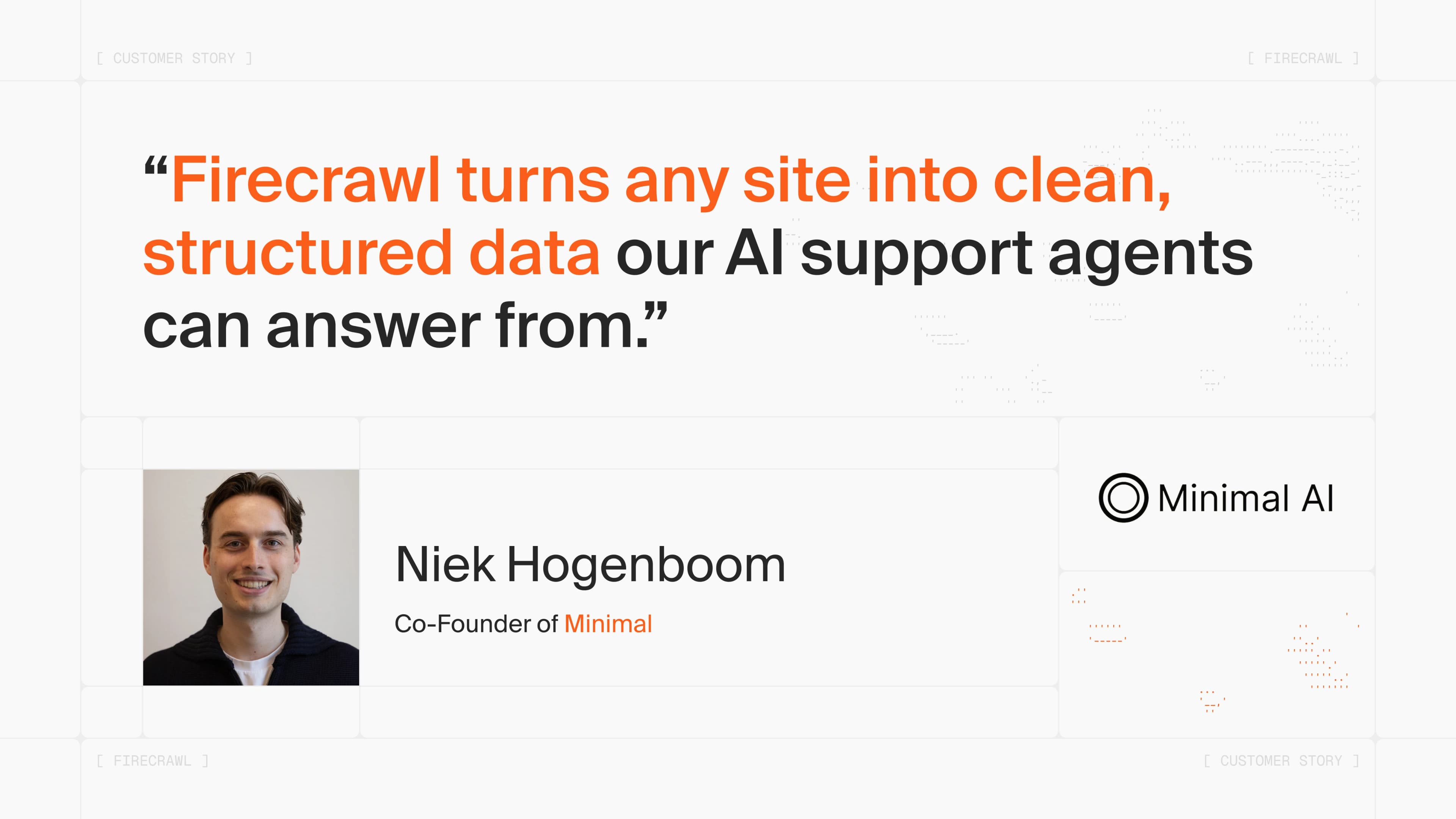
How Minimal Builds AI Support Agents That Know Every Merchant's Store
How Minimal uses Firecrawl to process nearly six million storefront pages a month, turning live product and policy content into data for AI support agents.
Eric Ciarla
Jul 14, 2026
Video
How to Use WebMCP with a Headless Agent (Claude Code) Using Firecrawl
WebMCP lets a site expose developer-defined tools to an AI agent, but only inside a live browser tab. Firecrawl's interact endpoint runs a real browser in the cloud, so headless agents like Claude Code can call those tools too.
Richard Oliver Bray
Jul 17, 2026
Video
How to Monitor a Website (or the Entire Web) for Changes with Firecrawl
Firecrawl's monitor endpoint scrapes a page on a schedule, diffs it against the last snapshot, and uses an AI judge to only notify you when a change is actually meaningful.
Richard Oliver Bray
Jul 16, 2026
Video
How to Scrape a Paginated Website with Firecrawl
Most agents grab page one of a paginated site and call it done. Here's how to walk every page with the Firecrawl SDK and know exactly when to stop.
Richard Oliver Bray
Jul 15, 2026
Best AI Tools for Research in 2026: From Answer Engines to Research Agents
The best AI for research in 2026, from real-time answer engines to peer-reviewed literature search to the retrieval infrastructure powering research agents. Verified capabilities, honest tradeoffs, and where each of these top AI tools for research fits in a modern stack.
Hiba Fathima
Jul 08, 2026
How do you convert PDF files to JSON? (2026)
Docling, PyMuPDF, pdf2json, pdf-parse, and Firecrawl compared for converting PDF files to structured JSON.
Jacob Nulty
Jul 07, 2026
10 OpenCode Skills Worth Installing in 2026
The best OpenCode skills for extending Anomaly's model-agnostic coding agent, from live web context with Firecrawl to multi-agent orchestration with Superpowers and codebase understanding with knowledge graphs.
Hiba Fathima
Jul 06, 2026
5 Best Nimbleway Alternatives in 2026
Looking for the best Nimbleway alternatives in 2026? Compare Firecrawl, Bright Data, Oxylabs, Apify, and Zyte on pricing, output format, and AI features.
Ninad Pathak
Jul 06, 2026
Introducing web-scale /monitor: Always-on search across the entire web
Firecrawl /monitor now watches the entire web, pinging you or your agent the moment something relevant comes online.
Eric Ciarla
Jul 01, 2026
What Is AI Agent Architecture? Components and Patterns (2026)
AI agent architecture is an LLM wrapped in a harness of tools, memory, a knowledge base, and orchestration. These components turn a model into an agent.
Jacob Nulty
Jun 30, 2026
The 5 AI Assistants Worth Your Time in 2026: A Builder's Shortlist
A builder's shortlist of the five AI assistants worth using in 2026: Vellum, Manus, Claude Cowork, OpenClaw, and Hermes Agent, scored on real work rather than demos.
Hiba Fathima
Jun 30, 2026
9 Best Hermes Tools and Plugins to Install in 2026
The Hermes Agent plugins worth installing in 2026: Firecrawl for live web context, Composio for app connectivity, Honcho and Hindsight for memory, Langfuse for observability, and the Kanban dashboard for multi-agent work.
Hiba Fathima
Jun 30, 2026
How to Build a Competitor Monitoring System Using Firecrawl Monitor
Build a competitor monitoring system with Firecrawl Monitor: schedule scrapes, diff changelog and pricing pages, and get AI-filtered alerts in one API.
Ninad Pathak
Jun 29, 2026
What Is a Web Crawler and How Do They Work?
A web crawler is a program that follows links to discover and collect web pages. Here is how the crawl loop works, the policies that govern it, and how to run one for an AI agent.
Bex Tuychiev
Jun 28, 2026
Vercel eve Tutorial: Build a Slack AI Agent with eve and Firecrawl
Build a Slack AI agent with eve, Vercel's filesystem-first framework, and wire in Firecrawl web search for cited answers in any thread.
Hiba Fathima
Jun 25, 2026
Video
Claude Code Just Got 16 New Powers You Should Be Using
Firecrawl skills give Claude Code and other agents new abilities, not just a new personality: search, scrape, market research, SEO audits, and design system cloning from one sentence.
Richard Oliver Bray
Jun 25, 2026
Grok Just Launched Plugins. Here Are the 10 Best Grok Plugins
The Grok plugins worth installing in 2026: Firecrawl for live web context, Composio for app integrations, Vercel for deploys, Sentry for production errors, and Matt Pocock's skill pack for engineering judgment.
Hiba Fathima
Jun 24, 2026
Puppeteer vs Selenium: Which Browser Automation Tool Should You Choose in 2026?
Puppeteer is a Chrome-focused Node library that drives the browser over the DevTools Protocol. Selenium is the cross-browser, multi-language WebDriver standard. Here is how they differ, the same task built in both, and how to pick.
Bex Tuychiev
Jun 23, 2026
The Agent Framework Moment: Why Flue and Eve Look so Much Alike
Flue (Astro/Cloudflare) and Eve (Vercel) are new agent frameworks that converged on the same shape. Plus how to add Firecrawl web search to each.
Hiba Fathima
Jun 21, 2026
5 Best ScrapingBee Alternatives for Web Scraping in 2026
Which ScrapingBee alternative fits depends on the use case: AI-ready output, proxy scale, marketplace coverage, or no-code scraping. Five tools compared.
Ninad Pathak
Jun 21, 2026
Cursor Automations 101: How to Build AI Workflows with Firecrawl
Cursor Automations deploy AI agents to the cloud with one toggle. Here's how to wire one up with Firecrawl for live web access.
Jacob Nulty
Jun 20, 2026
Introducing Firecrawl Research Index: a specialized index for agentic AI/ML research
Firecrawl Research Index gives agents the entire AI/ML literature and the code behind it, with SOTA recall on arXivQA — 18% above the next best provider at comparable cost.
Eric Ciarla
Jun 17, 2026
What Is a Web Search API? An AI Developer's Guide for 2026
A web search API gives your AI agent a programmatic way to query the live web and get back structured, LLM-ready results. Here's how it works, what to look for, and how to call one.
Hiba Fathima
Jun 17, 2026
Introducing Firecrawl Keyless: Search, scrape, and interact without an API key
Firecrawl is now keyless. Get 1,000 free credits a month to search, scrape, and interact with the web. No account, no setup, no key rotation.
Eric Ciarla
Jun 16, 2026
What Are the Best Codex Plugins to Install in 2026
The Codex plugins worth installing in 2026 — from Firecrawl for live web context to Composio for app integrations, Context7 for fresh docs, Superpowers for agent workflows, and RTK for token compression.
Eric Ciarla
Jun 11, 2026
Loop Engineering: Should You Stop Prompting Agents and Start Designing Loops
Loop engineering is the shift from prompting coding agents one turn at a time to designing the system that prompts them. Here's what a loop actually is, the parts it needs, and how to build one that halts.
Hiba Fathima
Jun 11, 2026
What is a CLI and Why AI Agents Prefer It
Why AI agents prefer the CLI: the token math, Terminal-Bench data, and the Unix tools (git, gh, ripgrep, curl) agents reach for.
Hiba Fathima
Jun 11, 2026
Best AI Coding Agents in 2026: Harness, Cost, and Accuracy Compared
A sourced comparison of the 8 best AI coding agents in 2026, ranked on harness depth, remote agents, token cost, and benchmark accuracy.
Hiba Fathima
Jun 10, 2026
Multi-Agent Orchestration With Codex
How to run multiple Codex agents in parallel using subagents, custom TOML agents, git worktrees, and Symphony — with a runnable three-agent review workflow.
Hiba Fathima
Jun 08, 2026
Top 4 Parallel AI Alternatives for Web Search and Data Extraction in 2026
Explore the best Parallel AI alternatives for AI web search and data extraction. Compare Firecrawl, Exa, Tavily, and Linkup across accuracy, pricing, and capabilities.
Hiba Fathima
Jun 07, 2026
12 Ways to Cut Token Consumption in Claude Code
How to cut Claude Code token consumption by 77-91%: verified benchmarks on CLAUDE.md trimming, path-scoped rules, model routing, MCP overhead control, and clean web data via Firecrawl.
Hiba Fathima
Jun 05, 2026
Claude Code vs Codex: Which AI Coding Agent Should You Use in 2026?
Claude Code has the deepest harness and fastest terminal. Codex covers more surfaces at a lower price. Compared on pricing, sandboxing, benchmarks, and community verdict.
Hiba Fathima
Jun 03, 2026
OpenClaw vs Hermes Agent: Which one should you actually run?
OpenClaw vs Hermes Agent compared on architecture, memory, file handling, security, and deployment, tested side by side in isolated Docker containers on the same model.
Ninad Pathak
Jun 03, 2026
4 Anthropic Web Search Alternatives for AI Agents in 2026
Anthropic's web_search billed 232,015 input tokens in a single turn. Four tested alternatives: Firecrawl, Brave, Exa, and Parallel, with install commands and live test results.
Mostafa Ibrahim
Jul 06, 2026
Best Low-Code AI Workflow Automation Tools in 2026
The best low-code AI workflow automation tools in 2026: n8n, Cursor Automations, Claude Routines, Zapier, Make, Gumloop, and Vellum. Visual builders and AI-native platforms for teams who want to build AI pipelines without heavy coding.
Hiba Fathima
Jun 02, 2026
Best Search Tools for AI Agents in 2026
Compare six search APIs for AI agents on latency, pricing, and built-in content extraction: Firecrawl, Brave, Exa, Tavily, Perplexity Sonar, and Serper.
Ninad Pathak
Jun 02, 2026
How to Build an AI SDR that Researches Companies in Real Time
AI SDR tutorial on how to build a Python agent that researches any company live with Firecrawl web search, pulls structured intel from its site, writes a specific outreach message, then scales across a list.
Bex Tuychiev
Jun 01, 2026
Claude Code vs OpenCode: Which Terminal AI Coding Agent Should You Use?
Claude Code is managed and model-locked; OpenCode is open-source and model-agnostic. Compare cost, terminal UX, harness depth, and the current state of the subscription block.
Hiba Fathima
Jun 01, 2026
Introducing /monitor: Notify AI agents when the web changes
Firecrawl Monitoring watches pages for you and notifies your agent the moment something changes. Use up to 90% fewer LLM tokens by only ingesting what actually changes on a page.
Eric Ciarla
May 27, 2026
Best Trending GitHub Repositories for AI Developers to Star in 2026
The best GitHub repos for AI developers in 2026. Ten repositories covering supply chain scanning, web context APIs, LLM training fundamentals, CSS design skills, and more.
Hiba Fathima
May 26, 2026
Firecrawl is now live on the Vercel Marketplace
Firecrawl is now a native integration on the Vercel Marketplace. One-click install, API key auto-injected into your project environment, billed through Vercel.
Eric Ciarla
May 26, 2026
Reduce LLM & Agent Hallucinations With Real-Time Web Search
LLM agents hallucinate from stale data and knowledge gaps. Why hallucinations persist despite smarter models, and how real-time web search reduces them.
Vera Agiang
May 26, 2026
Build a Finance Research Agent with Live Web Search + Scraping Using Firecrawl
A finance research agent that scrapes SEC filings, IR pages, and financial news live with Firecrawl, then passes clean data to an LLM for analysis. Full TypeScript code included.
Hiba Fathima
May 25, 2026
Best Codex Skills That Add the Most Value in 2026
The best Codex skills for extending what OpenAI's coding agent can do, from live web context with Firecrawl to PR automation, MCP server scaffolding, and more.
Hiba Fathima
Jun 03, 2026
Video
Firecrawl 101: Web Context APIs for AI Agents
Firecrawl covers Search, Scrape, Crawl, Map, Interact, and Parse. Here's which endpoint to reach for and how to compose them in an agent workflow.
Hiba Fathima
May 18, 2026
Mastering Firecrawl's interact endpoint: a complete guide
/interact keeps a browser session alive between API calls. Drive it in plain English or code to handle logins, multi-step flows, and lazy-loaded data. Covers prompt mode, code mode, and named profiles.
Bex Tuychiev
May 18, 2026
Best Document Parsing APIs to Try in 2026
A practical comparison of the best document parsing APIs for developers building AI pipelines, RAG systems, and document automation workflows in 2026.
Hiba Fathima
May 17, 2026
7 Best Investment Research APIs for AI-First Use Cases in 2026
The best investment research APIs in 2026 for alternative data, fundamental analysis, real-time market feeds, and news sentiment. Tested and compared.
Hiba Fathima
May 14, 2026
What is agentic search (and why cached results aren't enough)
Agentic search queries the live web at reasoning time, making it the right retrieval method for real-time signals and open-web content that RAG can't cover.
Ninad Pathak
May 12, 2026
Introducing Question and Highlights: High-Quality Answers from the Web, 100x Fewer Tokens
Two new formats for Firecrawl /scrape — question returns grounded answers from any web page, highlights returns verbatim excerpts. Both use up to 100x fewer tokens than a full scrape, with a fully managed LLM stack and prompt-injection hardening built in.
Eric Ciarla
May 08, 2026
Is Codex Web Search Stale by Default? Here's How to Fix It
Codex's built-in web search queries a stale pre-scraped cache by default. Learn how to switch to live mode and wire in Firecrawl MCP for real-time results, full-page content, and crawling.
Hiba Fathima
May 06, 2026
How to Ground Your LLM with Live Web Data (and Why It Matters)
LLM grounding injects factual, up-to-date context at query time so the model reasons over real data. Covers the search-scrape-inject pipeline with working Python code.
Ninad Pathak
May 05, 2026
Web Search in Hermes Agent: What's Built In and How to Use It
Hermes ships Firecrawl as its default web backend. Here's what web_search, web_extract, and the browser tools actually do, how they differ, and the patterns that work for long-running agent tasks.
Hiba Fathima
Apr 30, 2026
Lockdown Mode: /scrape Without Touching the Web
Lockdown Mode is Firecrawl's new cache-only scrape mode - no outbound request, zero data retention, one flag across every SDK, the CLI, and MCP.
Eric Ciarla
Apr 30, 2026
Introducing /parse: Turn any document into LLM-ready data
Upload a PDF, Word doc, or spreadsheet and get back clean markdown, a summary, or structured JSON in one call.
Eric Ciarla
Apr 28, 2026
Training Data vs. Retrieved Data vs. Live Web Data: What Data Makes Your AI Agent Smarter
Training data vs. retrieved data vs. live web data, learn when each layer matters for AI agents and how to combine them for accurate, current answers.
Ninad Pathak
Apr 28, 2026
Agent Skills Explained: How SKILL.md Files Work and Why They're Everywhere
Agent skills are reusable SKILL.md files that give AI coding agents specialist knowledge on demand. Learn how they work, why they went from 0 to 40,000 in 20 days, and how to build your own.
Ninad Pathak
May 26, 2026
Best PDF Parsers for AI and RAG Workflows in 2026
A hands-on comparison of the best PDF parsers for AI and RAG pipelines in 2026, covering speed, output quality, table handling, and LLM-readiness for each tool.
Hiba Fathima
Apr 27, 2026
4 Best Bright Data Alternatives for Web Scraping and Web Search in 2026
Comparing the top Bright Data alternatives for web scraping and SERP APIs in 2026: real pricing, feature breakdowns, and community-sourced context.
Hiba Fathima
Apr 27, 2026
Best News API for Apps and Agents in 2026
A developer's guide to the best news API available in 2026: real-time news search, article extraction, and AI-ready data pipelines for monitoring, research, and agent workflows.
Hiba Fathima
Apr 24, 2026
Hermes Agent: What It Is and How to Use It With Firecrawl
Hermes is a local-first agent framework from Nous Research that learns from past tasks, carries memory across sessions, and ships with Firecrawl as its default web backend. This guide covers what makes it different, how to install it, and how to extend it with web search, scraping, and crawling.
Bex Tuychiev
Jul 01, 2026
What Is a Web Index? How Web Indexing Powers Search and AI Agents
A web index is a pre-built snapshot of the web that powers both search engines and AI agents. Covers the four-stage pipeline, hybrid retrieval, and why index quality limits what your agent can answer.
Hiba Fathima
Apr 23, 2026
Top Web Search MCP Servers for Claude, Cursor and More
Give Claude, Cursor, or any MCP client real-time web access in minutes. We compare the top web search MCP servers (Firecrawl, Tavily, Exa, and WebSearch-MCP) with exact install commands and honest takes on where each one falls short.
Hiba Fathima
May 22, 2026
Firecrawl /search is now available on OpenRouter
Firecrawl is now a web search engine on OpenRouter. One toggle grounds every model in your account with live, full-page, markdown-ready web content.
Eric Ciarla
Apr 21, 2026
cURL Web Scraping Guide: How to Scrape Web Pages with cURL
Learn how to use cURL for web scraping, understand its basic commands, flags, use cases, limitations, and when to switch to an advanced scraping API like Firecrawl.
Ninad Pathak
Apr 20, 2026
Introducing Firecrawl web-agent: Build and Deploy Your Own Web Research Agent
A lightweight open source agent stack for web research and extraction — scaffold a full project in seconds, then fork, extend, and deploy it your way.
Eric Ciarla
Apr 16, 2026
Video
Claude Managed Agents: Full MCP Setup with Firecrawl and Linear
Learn how to set up Claude Managed Agents from scratch, connect Firecrawl and Linear as MCP tools, and automate AI news research into Linear tasks without the quick-start wizard.
Leonardo Grigorio
Apr 16, 2026
Introducing Fire-PDF: Firecrawl's New PDF Parsing Engine
Fire-PDF is our new Rust-based PDF parsing engine — 3.5-5x faster, smarter about what hits GPU, and more accurate on complex layouts.
Eric Ciarla
Apr 14, 2026
How to Extend Gemini CLI With Firecrawl Web Search
Gemini CLI's built-in web fetch can't handle JavaScript-rendered content or structured data extraction. This guide compares web fetch with Firecrawl across 8 capabilities and walks through two integration paths— Agent Skills and MCP server.
Bex Tuychiev
Apr 14, 2026
MCP vs CLI for AI Agents: Which One Should You Use in 2026?
MCP costs 4 to 32x more tokens than CLI. Same tasks, higher bill. So why are OpenAI, Google, and Microsoft all adopting it? A practical breakdown of when to use each.
Hiba Fathima
Jun 05, 2026
How Stanford's AI Playground Covers 10,000+ Domains for Real-Time LLM Grounding
AI Playground serves the Stanford community by augmenting LLM responses with real-time web data across 10,000+ domains, processing ~800 sources daily using Firecrawl's Search and Scrape endpoints.
Hiba Fathima
Apr 09, 2026
Is OpenClaw Safe? 7 Real Vulnerabilities and How to Fix Them
Seven documented OpenClaw security risks with proof and a specific fix for each one, from gateway exposure to config drift.
Bex Tuychiev
Apr 08, 2026
Firecrawl vs Playwright for Web Scraping
A side-by-side comparison of Firecrawl and Playwright for web scraping, with working code examples, a feature comparison table, and guidance on when to use each tool.
Bex Tuychiev
Apr 07, 2026
Best CLI Tools for Your AI Agents in 2026
The best CLI tools to give your AI agents real-world capabilities: web scraping, GitHub operations, database management, payments, Google Workspace, and deployments.
Hiba Fathima
Apr 06, 2026
Web Search and Deep Research for AI Agents: What It Is and How to Integrate It into Your Agentic Stack
Learn what web search and deep research mean for AI agents, why 2026 made both production-grade, and how to wire them into your stack with Firecrawl.
Bex Tuychiev
May 22, 2026
API for AI Agents: Types, Integration Patterns, and Tools
An AI agent without API access is a chatbot. Giving AI agents API access helps you turn that reasoning into action. Learn about API integration patterns for AI agents.
Ninad Pathak
Apr 02, 2026
How To Scrape A Website To Markdown For LLMs And AI Agents (In Under 5 Minutes)
Learn how to scrape a website to markdown for LLMs and AI agents using the latest Firecrawl API, MCP server, CLI, and playground workflows.
Ninad Pathak
Apr 01, 2026
Best YouTube Transcript Extractors to Try in 2026
Firecrawl, NoteGPT, SocialKit, and Kome extract YouTube transcripts via free web tools, API, CLI, MCP, or audio download, compared on features and price.
Hiba Fathima
Jul 13, 2026
Firecrawl + n8n: Bring Real-Time Web Data Into Your AI Workflows
Firecrawl is now natively integrated into n8n Cloud. Connect in one step, no API keys needed, and get 10,000 free credits when you connect through n8n.
Nicolas Camara
Mar 26, 2026
Claude Web Fetch vs Firecrawl— Which One Actually Works for Web Extraction?
Claude's web fetch tool is a quick fix for static pages, but it fails on the modern, JavaScript-heavy web. We compare Claude web fetch vs Firecrawl to see which one handles production extraction reliably.
Ninad Pathak
Mar 25, 2026
Introducing /interact — Scrape and interact with a web page
The new /interact endpoint lets you scrape a page and immediately take actions in it — click buttons, fill forms, and navigate dynamic content using AI prompts or code.
Eric Ciarla
Mar 25, 2026
Best AI Search Engines for Agents and Workflows in 2026
Not all AI search engines are built for agents. Here's a developer breakdown of the top options: Firecrawl, Exa, Tavily, Perplexity, and more — covering what each returns, what it costs, and when to use it.
Hiba Fathima
May 22, 2026
AI Agent Sandbox: How to Safely Run Autonomous Agents in 2026
An AI agent sandbox is an isolated execution environment where an agent can take actions without those actions affecting the host system. Learn how it works.
Ninad Pathak
Mar 18, 2026
AI Agents: What They Are, How They Work, and Why Web Context Is the Missing Piece
AI agents use LLMs to pursue goals across multi-step workflows. This guide covers agent architecture, the web context bottleneck, frameworks, and production best practices.
Bex Tuychiev
Jul 02, 2026
Best OpenClaw Search Providers in 2026
OpenClaw supports fourteen web search providers: Firecrawl, Brave, Exa, Gemini, Grok, Kimi, MiniMax, Tavily, Perplexity, Parallel, Ollama, Codex, DuckDuckGo, and SearXNG. Here is what each one does, how to set it up, and when to use it.
Hiba Fathima
Jul 02, 2026
Mastra Tutorial: How to Build AI Agents in TypeScript
Learn how to build AI agents and batch workflows in TypeScript with this Mastra tutorial. Covers typed tools with Zod schemas, agent configuration, and structured output using Firecrawl for web scraping.
Bex Tuychiev
Mar 17, 2026
What Is an Agent Harness? The Infrastructure That Makes AI Agents Actually Work
An agent harness is the software infrastructure surrounding an LLM that manages tool execution, memory, state persistence, and verification. Learn how it works and why it's essential for long-running AI agents.
Ninad Pathak
Apr 16, 2026
Best Claude Code Skills to Try in 2026
Firecrawl, Superpowers, Frontend Design, and 15 other Claude Code skills extend what Claude can do, from web scraping to multi-agent orchestration.
Hiba Fathima
Jul 13, 2026
Partnering with Wikipedia for a More Sustainable Web
Firecrawl has partnered with Wikimedia Enterprise to make accessing Wikipedia data faster, cleaner, and more sustainable for AI applications, with attribution built in.
Eric Ciarla
Mar 11, 2026
Video
How to Schedule Recurring Web Tasks with Claude Desktop and Firecrawl
Claude Desktop now lets you schedule recurring tasks in Cowork. Combine it with Firecrawl's MCP to automatically scrape, search, and summarize the web on any schedule: no code required.
Leonardo Grigorio
Mar 11, 2026
How to Build AI Agents with the Claude Agent SDK and Firecrawl
Learn how to build a Python dependency auditor using the Claude Agent SDK and Firecrawl MCP server, with parallel subagents, structured Pydantic output, and a color-coded terminal report.
Bex Tuychiev
Mar 10, 2026
19 Best OpenClaw Skills for Your AI Agents
A curated list of the best OpenClaw skills across web scraping, productivity, development, and more, plus a walkthrough for building and publishing your own.
Bex Tuychiev
Apr 24, 2026
Add AI-Powered Data Retrieval to Your Product with Firecrawl
Learn how to add web data retrieval to your product using Firecrawl's Python SDK. Covers four patterns with code examples - search, scrape, crawl, and agent-driven gathering.
Bex Tuychiev
Mar 03, 2026
CMS Migration: A Developer's Guide to Doing It Right in 2026
A clear, technical map to migrate a CMS from start to finish. Covers extraction, schema transformation, redirect mapping, and phased rollout with Firecrawl.
Ninad Pathak
May 06, 2026
What Are the Best ScraperAPI Alternatives for Web Scraping in 2026?
We compared five ScraperAPI alternatives based on pricing, API design, reliability, AI-readiness, and support quality to help you find the right tool for your scraping needs.
Hiba Fathima
Mar 02, 2026
Top 3 Zyte Alternatives for Web Scraping in 2026
Zyte has 15 years in the industry and a Proxyway #1 ranking, but pricing complexity and support wait times lead some teams to look elsewhere. Here are the top alternatives.
Hiba Fathima
Mar 01, 2026
Introducing PDF Parser v2: Faster Extraction with Auto Mode
Firecrawl's new Rust-based PDF parser is 3x faster, introduces three intelligent parsing modes, and automatically adapts to any document type, from clean text PDFs to complex scanned layouts.
Eric Ciarla
Feb 26, 2026
10 Best MCP Servers for Developers in 2026
The best MCP servers for developers in 2026 — covering web scraping, design, browser automation, code execution, deployment, and more. Works with Claude Code, Cursor, VS Code, Windsurf, and any MCP-compatible client.
Leonardo Grigorio
Feb 24, 2026
OpenClaw Web Search: How to Make Your Agent Actually Read the Web
OpenClaw's built-in search hands your agent links. Firecrawl hands it content. Here's how the two-tool pipeline works, when it breaks, and how to fix it.
Hiba Fathima
Apr 16, 2026
Playwright vs Puppeteer: Which Browser Automation Tool Should You Choose in 2026?
Playwright vs Puppeteer: cross-browser support, auto-wait, performance, and how Firecrawl simplifies web data extraction.
Ninad Pathak
Feb 24, 2026
How to Build a Real-Time Voice Assistant with Gemini Live API and Firecrawl
Build a voice assistant that searches the web and manages Gmail using Gemini Live's native audio mode and Firecrawl, packed into a single Python file.
Bex Tuychiev
May 06, 2026
What are the Best Bing Search API Alternatives in 2026
The Bing Search API was discontinued in August 2025. We compare Firecrawl, Exa, Tavily, Brave Search API, and SerpAPI on pricing, extraction depth, AI agent support, and search quality.
Hiba Fathima
Jun 04, 2026
Top 5 Brave Search API Alternatives in 2026
Firecrawl, Exa, Tavily, Parallel AI, and LLMLayer are the top Brave Search API alternatives, compared on pricing, quality, extraction depth, and agent support.
Hiba Fathima
Jul 13, 2026
Browser Sandbox: Secure Environments for Agents to Interact with the Web
Firecrawl Browser Sandbox gives AI agents a fully managed, isolated browser environment - zero config, pre-loaded with tools, and works alongside Firecrawl's scrape and search endpoints.
Eric Ciarla
Feb 18, 2026
Claude Code for Marketing: How Marketers Can Use It in 2026
From shipping landing pages in hours to building custom agents for SEO workflows, here's how Claude Code transformed my day-to-day as an SEO lead at Firecrawl.
Hiba Fathima
Feb 17, 2026
OpenClaw Guide: Build a Personal Agent with Internet Access Using Firecrawl
Everything you need to know about OpenClaw (formerly ClawdBot, MoltBot): what it is, how to set it up safely, and how to add live web search and scraping through Firecrawl.
Bex Tuychiev
Apr 24, 2026
Top 13 Agentic AI Trends to Watch in 2026
From CLI agents to MCP's surprising resurgence and Karpathy's verifiability framework, explore the data-backed trends reshaping how we build and deploy AI systems in 2026. Based on research from Anthropic, industry reports, and real developer discussions.
Hiba Fathima
Jun 02, 2026
11 Best AI Browser Agents in 2026
We tested the top browser agents for AI automation, web scraping, and autonomous browsing in 2026. Compare open-source frameworks, enterprise tools, and consumer browsers to find the right fit for your workflow.
Hiba Fathima
Jun 16, 2026
Firecrawl is Now an Official Claude Plugin
Firecrawl's official Claude Code plugin gives Claude direct access to live web data — scrape pages, crawl sites, search the web, and extract structured data without leaving your workflow.
Hiba Fathima
Feb 13, 2026
Best Web Extraction Tools for AI in 2026
Discover the 10 best web extraction tools for AI use cases in 2026. Compare features, pricing, and AI-readiness of top platforms including Firecrawl, Apify, Bright Data, and more.
Hiba Fathima
Feb 11, 2026
How to Set Up and Use Firecrawl MCP in Cursor
Learn how to set up and use the Firecrawl MCP server in Cursor to give your AI coding agent web scraping, search, crawling, and structured extraction capabilities.
Ninad Pathak
Mar 12, 2026
How to Choose the Right Web Scraping Tool for Accurate Data Extraction
Learn how to evaluate web scraping services for reliable data extraction. Compare managed APIs, headless browsers, and AI-powered tools to find the best fit for your needs.
Hiba Fathima
Feb 09, 2026
Branding Format v2: Improved Logo Extraction
Branding Format v2 delivers significantly improved logo extraction accuracy, better compatibility with modern site builders, and structured brand data for AI agents and developers.
Eric Ciarla
Feb 06, 2026
Video
Building Apps with Claude Opus 4.6 Agent Teams & Firecrawl Agent
Claude Opus 4.6 brings agent teams, 1M token context, and state-of-the-art coding abilities. Learn how to pair it with Firecrawl's agent endpoint to build apps that tap into live web data, with a full walkthrough of building a coupon-finding Chrome extension.
Leonardo Grigorio
Feb 06, 2026
Context Engineering vs Prompt Engineering for AI Agents
Learn what context engineering is, its difference from prompt engineering, why it matters for AI agents, and the practical techniques that make agents work in production.
Rafael Miller
Feb 05, 2026
How to Build a Web Scraping Agent With LangGraph and Firecrawl
Learn how to build a web scraping agent in Python using LangGraph and Firecrawl. The agent uses a ReAct loop to combine scraping, screenshots, structured extraction, web search, and documentation crawling based on plain English commands.
Bex Tuychiev
Feb 04, 2026
Why CLIs Are Better for AI Coding Agents Than IDEs
CLI agents offer delegation over suggestion, better context management, and deterministic automation. Learn why developers are switching from IDE-based AI tools to terminal agents like Claude Code and Gemini CLI.
Ninad Pathak
Mar 12, 2026
5 Best Deep Research APIs for Agentic Workflows in 2026
Compare the top deep research APIs for building AI agents and agentic workflows. From autonomous web research to structured extraction, find the right tool for your RAG systems, research agents, and data pipelines.
Hiba Fathima
May 22, 2026
Agent Tools: Building Effective Capabilities for AI Systems
Discover the 9 core categories of AI agent tools, from web search to code execution. Learn how to design reliable tools and orchestrate them for complex workflows.
Ninad Pathak
Jan 30, 2026
Extract Web Data at Scale With Parallel Agents
Parallel Agents let you batch process hundreds or thousands of /agent queries in a spreadsheet or JSON format with real-time streaming results.
Eric Ciarla
Jan 30, 2026
9 Best Tools for Dynamic Web Scraping in 2026
Compare nine dynamic web scraping tools with strengths, trade-offs, and use cases, from API-first services to headless browsers and no-code platforms.
Hiba Fathima
Mar 19, 2026
Introducing Firecrawl Skill and CLI: The Complete Web Data Toolkit for Agents
A single command gives AI agents the complete web data toolkit - scrape, search, and browse the web. Works with Claude Code, Codex, Gemini CLI, OpenCode, and more.
Eric Ciarla
Jan 27, 2026
Video
Building AI-Powered Apps with Firecrawl and Lovable: Access Live Web Data
Build a brand analyzer and trend tracker with Firecrawl + Lovable: prompt structure, which endpoints to use, and how to handle agent timeouts.
Leonardo Grigorio
May 06, 2026
How Credal Extracts 6M+ URLs Monthly to Power Production AI Agents
How Credal uses Firecrawl to deliver reliable web scraping at scale for enterprise AI agents that need both fresh external context and durable knowledge base ingestion.
Eric Ciarla
Jan 26, 2026
Context Layer for AI Agents: Can You Automate Context Feeding into Your Agents?
Prevent context drift by building a dedicated Context Layer for AI agents. Learn why vector databases fall short and how to automate real-time decision context ingestion using Firecrawl.
Ninad Pathak
Jan 21, 2026
Video
Building a Claude Skills Generator with Firecrawl's Agent Endpoint
Learn how we built an internal Claude Skills generator using Firecrawl's /agent endpoint. Discover why automating skill creation is a game-changer and how you can build complex AI workflows with just one API call instead of building everything from scratch.
Leonardo Grigorio
Apr 03, 2026
Top 11 Claude Code Plugins to Try in 2026
Discover the best Claude Code plugins that can transform your development workflow. From TypeScript LSP for IDE-grade code intelligence to autonomous coding with Ralph Loop, learn which plugins boost productivity and help you ship faster.
Musthaq Ahamad
Jun 05, 2026
Introducing Spark 1 Pro and Spark 1 Mini
Spark 1 Pro and Spark 1 Mini bring flexible model selection to /agent. Mini is 60% cheaper for everyday tasks, Pro delivers maximum accuracy for complex extraction.
Eric Ciarla
Jan 14, 2026
5 Best Perplexity Alternatives for AI Developers Building Research Tools in 2026
Perplexity works for conversational search, but developers building AI agents and RAG systems need structured extraction and predictable costs. Compare 5 alternatives built for programmatic workflows.
Hiba Fathima
Jun 04, 2026
Data Enrichment: A Complete Guide to Enhancing Your Data Quality
A comprehensive guide to enriching your data quality using modern tools, best practices, and real-world examples.
Bex Tuychiev
Mar 12, 2026
Firecrawl MCP in ChatGPT: Web Scraping and Search Inside Your Conversations
Learn how to set up and use the Firecrawl Model Context Protocol (MCP) server in ChatGPT to perform web scraping, crawling, and search directly within your conversations.
Ninad Pathak
Jan 13, 2026
Top 9 Browser Automation Tools for Web Testing and Scraping in 2026
Comprehensive comparison of the best browser automation frameworks including Selenium, Playwright, Puppeteer, and Cypress for web testing, data extraction, and workflow automation with implementation guides.
Bex Tuychiev
Feb 28, 2026
Best Semantic Search APIs for Building AI Applications in 2026
Compare the best semantic search APIs in 2026: Firecrawl, Exa, OpenAI Embeddings, Cohere Rerank, and Pinecone, with code examples and benchmarks.
Ninad Pathak
May 22, 2026
How to Create a Claude Code Skill: A Web Scraping Example with Firecrawl
Learn how to build a Claude Code skill that adds web scraping capabilities using Firecrawl. This tutorial covers skill structure, YAML frontmatter, triggering behavior, and building a multi-feature skill for markdown extraction, screenshots, structured data, web search, and documentation crawling.
Bex Tuychiev
Jun 16, 2026
Top 5 Exa Alternatives for AI Web Search and Data Extraction in 2026
Explore 5 Exa alternatives offering different approaches to AI web search, transparent pricing, and data extraction capabilities.
Hiba Fathima
Jun 04, 2026
Best open-source web crawlers in 2026
Ten open-source web crawlers compared: Scrapy, Crawl4AI, Playwright, Colly, Crawlee, and more. What each does best, where it breaks down, and how to pick one for your stack.
Bex Tuychiev
May 18, 2026
Scraper vs Crawler: When to Use Each (With Examples)
Learn the difference between web scraping and web crawling, when to use each approach, and build two practical projects with Firecrawl: a job listing extractor and a blog content collector.
Bex Tuychiev
Jan 03, 2026
15 Best Open-Source RAG Frameworks in 2026
Discover the top open-source retrieval-augmented generation frameworks that enhance LLM capabilities with external knowledge retrieval for more accurate and contextual AI responses.
Bex Tuychiev
Jan 02, 2026
5 Tavily Alternatives for Better Pricing, Performance, and Extraction Depth
We evaluated five Tavily alternatives based on pricing transparency, extraction capabilities, response times, and integration with AI workflows. Discover options with different pricing models and specialized features.
Hiba Fathima
Jun 04, 2026
Python Web Scraping Tutorial - Setup & Examples
Learn Python web scraping from static pages to JavaScript-rendered content. This tutorial covers Requests, BeautifulSoup, Selenium, async scraping with asyncio, and modern tools like Firecrawl.
Bex Tuychiev
Dec 26, 2025
Selenium Web Scraping with Python - Setup, Selectors, Waits, and Scaling
Learn how to scrape JavaScript-heavy websites using Selenium in Python, from setup and element locators to WebDriverWait patterns, pagination, infinite scroll, and production hardening tips.
Ninad Pathak
Feb 09, 2026
5 Best Apify Alternatives for Reliable Web Scraping in 2026
We tested five Apify alternatives based on marketplace reliability, pricing transparency, support quality, learning curve, and production-ready infrastructure to find tools that work at scale.
Hiba Fathima
Feb 24, 2026
Best Open-Source Web Scraping Libraries in 2026
Comprehensive comparison of leading web scraping tools including Firecrawl, highlighting AI-powered solutions, traditional methods, and how to choose the right library for your data extraction needs.
Bex Tuychiev
Dec 24, 2025
Introducing /agent: Gather Data Wherever It Lives on the Web
Firecrawl /agent searches, navigates, and gathers complex websites to find data in hard-to-reach places. What takes humans hours, Agent does in minutes.
Eric Ciarla
Dec 18, 2025
8 Best Web Scraping APIs in 2026
Compare the 8 best web scraping APIs of 2026 with code examples, pricing breakdowns, real user reviews, and honest pros/cons to help you choose the right tool for your needs.
Bex Tuychiev
Feb 19, 2026
How to Scrape Dynamic Websites with Headless Browsers in Python
Learn how to scrape dynamic websites using Selenium, Playwright, and Pyppeteer in Python. Includes working code examples, cost analysis, and when to use managed APIs like Firecrawl instead.
Bex Tuychiev
Dec 17, 2025
Firecrawl + Lovable - Build Web Data Apps Without Writing Code
With the new Firecrawl + Loveable integration, build apps that scrape, search, and interact with live web data - just by describing what you want in plain English.
Nicolas Camara
Dec 16, 2025
Web Scraping With JavaScript: Step-by-Step Guide
Learn web scraping with JavaScript from scratch. Start with Cheerio and Axios for static sites, discover why traditional tools fail on modern websites, and solve JavaScript rendering problems with Firecrawl. Includes working code examples and beginner project ideas.
Bex Tuychiev
Dec 12, 2025
4 Best Oxylabs Alternatives for Developers and Data Teams
We compared four alternatives to Oxylabs based on web scraping API performance, billing transparency, setup complexity, proxy management, and real user experiences.
Hiba Fathima
Mar 01, 2026
AI Data Preparation 101: A Complete Guide for AI Practitioners
Learn how to prepare data for AI applications with this step-by-step guide. Covers collection, cleaning, transformation, validation, and optimization for RAG systems, fine-tuning, and inference pipelines.
Bex Tuychiev
Mar 12, 2026
How Retell Keeps AI Phone Agents Answering from Live Documentation with Firecrawl
How Retell uses Firecrawl's web scraping API to turn customer documentation into LLM-ready knowledge bases, keeping AI phone agents accurate without maintaining scrapers.
Eric Ciarla
Dec 04, 2025
Best LLM Observability Tools in 2026
Compare 16 LLM observability tools across four categories. Find the best option for tracing, evaluation, cost tracking, and monitoring your AI applications.
Bex Tuychiev
Jun 16, 2026
Comprehensive Guide to Building AI Agents Using Google Agent Development Kit (ADK)
Learn how to build powerful multi-agent systems with Google's ADK framework that can search the web, generate images, and perform complex tasks through a simple conversational interface.
Bex Tuychiev
Dec 02, 2025
Octoparse Alternatives: 5 Tools for Faster, More Reliable Data Extraction
We evaluated popular Octoparse alternatives based on five key criteria: dynamic content handling, pricing transparency, API-first architecture, scalability for enterprise workloads, and integration with modern development tools.
Hiba Fathima
Feb 24, 2026
PHP Web Scraping for Beginners: A Step-by-Step Guide
Learn PHP web scraping from scratch with this tutorial. Master HTML fundamentals, build scrapers with Guzzle and Simple HTML DOM Parser, handle pagination, overcome JavaScript challenges with Firecrawl, and explore real-world project ideas.
Bex Tuychiev
Feb 18, 2026
Best Hands-On Resources to Learn AI Engineering in 2026
Discover 12 hands-on AI resources organized by skill level for building chatbots, RAG systems, and AI agents. Learn AI Engineering with free tutorials from OpenAI, Anthropic, LangChain, and more, organized from beginner to advanced.
Bex Tuychiev
Feb 19, 2026
Open Agent Builder - Open-Source Visual Workflow Builder for AI Agents
Learn about Open Agent Builder, an open-source visual workflow builder for AI agents. Build web scraping, research automation, and multi-step AI workflows without code using this drag-and-drop interface from Firecrawl.
Bex Tuychiev
Nov 05, 2025
List Crawling: Extract Structured Data From Websites at Scale
Learn how to extract structured data from websites using list crawling in Python. Compare BeautifulSoup, Scrapy, and Firecrawl for scraping product listings, job boards, and directories with practical code examples.
Bex Tuychiev
Feb 18, 2026
Introducing Firecrawl v2.5 - The World's Best Web Data API
Firecrawl v2.5 delivers the highest quality and most comprehensive web data available, powered by our new Semantic Index and custom browser stack.
Eric Ciarla
Oct 30, 2025
Building E-Commerce Intelligence Application with GLM Coding Plan
Build smarter, code faster. Integrate Claude Code with the $3 GLM-4.6 plan to quickly vibe-code a customer review analytics app. This app will scrape, analyze, and visualize insights in just minutes.
Abid Ali Awan
Oct 26, 2025
Open Lovable Tutorial: Clone Any Website as a Modern React App
Learn how to use Open Lovable to clone any website into a production-ready React app with TypeScript and Tailwind CSS.
Bex Tuychiev
Oct 24, 2025
Building AI Agents with OpenAI Agent Builders & Firecrawl
Building multi-step AI workflows just got easier, here's how I used OpenAI's new Agent Builder to create a complete Investment Research Agent from scratch, without writing a single line of code.
Abid Ali Awan
Oct 20, 2025
Turn Any Documentation Site Into an AI Agent with LangGraph and Firecrawl
Build a complete documentation agent from scratch using LangGraph's ReAct pattern and Firecrawl's web scraping. Learn agentic RAG, token streaming, conversation memory, and deploy a production-ready Streamlit app that turns any docs into an intelligent chatbot.
Bex Tuychiev
Oct 17, 2025
Top 15 Python Projects to Build in 2025: From Beginner to Production
Explore a range of Python projects tailored for beginners to advanced developers, empowering you to progressively improve your Python skills, AI automation skills, and build and deploy real-world applications.
Abid Ali Awan
Oct 16, 2025
Best Chunking Strategies for RAG (and LLMs) in 2026
Compare seven chunking strategies for RAG systems using real benchmark data from NVIDIA and Chroma. Learn when to use recursive splitting, semantic chunking, page-level chunking, late chunking, and LLM-based approaches with practical code examples and honest trade-offs.
Bex Tuychiev
Feb 24, 2026
Best Vector Databases in 2026: A Complete Comparison Guide
Compare 18 vector databases with real performance benchmarks, honest trade-offs, and decision frameworks for choosing by scale, use case, and infrastructure.
Bex Tuychiev
May 27, 2026
11 Essential Python Libraries Every Data Analyst Should Know
The 11 Python libraries for data analytics covering data extraction, analysis, visualization, machine learning, and dashboards, each with a practical code example and real-world use cases.
Abid Ali Awan
Jun 05, 2026
10 AI Projects You Can Build with Firecrawl Now
Build 10 AI projects with Firecrawl's web scraping API: RAG systems, AI agents, price trackers, and more. Includes step-by-step tutorials, GitHub repos, and deployment guides for beginner to advanced developers.
Abid Ali Awan
Oct 02, 2025
Mastering Firecrawl Search Endpoint: Web Search and Data Extraction in One API Call
Use Firecrawl's /v2/search endpoint to combine web search and full content extraction in a single API call. This guide walks through filtering by source and category, image search with size operators, time-based filters, and a research agent built with LangGraph.
Bex Tuychiev
May 04, 2026
11 AI Agent Projects You Can Build Today (With Guides)
Build AI agents that reason, plan, act, and use tools to deliver results, from no/low-code platforms to advanced multi agent framework.
Abid Ali Awan
Sep 18, 2025
Web Scraping for Beginners: A Step-by-Step Guide
Learn how to collect data from websites using Python in this beginner's guide.
Bex Tuychiev
Mar 19, 2026
Best Web Search APIs for AI Applications in 2026
Find the best web search API for your AI project. We compare top web search APIs including Firecrawl, Exa, Tavily, SerpAPI, and more - with pricing, features, and use cases.
Dania Durnas
Jun 04, 2026
How to Use Firecrawl's Scrape API: Complete Web Scraping Tutorial
Learn how to scrape websites using Firecrawl's /scrape endpoint. Master JavaScript rendering, structured data extraction, and batch operations with Python code examples.
Bex Tuychiev
May 04, 2026
Mastering Firecrawl's Crawl Endpoint: A Complete Web Scraping Guide
Use Firecrawl's /v2/crawl endpoint to scrape an entire site in one job. This guide covers URL control, performance tuning, async delivery via watcher() and webhooks, debugging incomplete crawls, and a RAG agent built on top of crawled pages with LangChain.
Bex Tuychiev
May 06, 2026
Fine-Tune OpenAI GPT-OSS 20B on the Dermatology Dataset
Learn how to fine-tune OpenAI's GPT-OSS 20B on a dermatology Q&A dataset created with the Firecrawl web search API, with a step-by-step workflow from setup to training, evaluation, and inference.
Abid Ali Awan
Sep 05, 2025
How to Generate a Sitemap Using Firecrawl's /map Endpoint: A Complete Guide
Learn how to generate XML and visual sitemaps using Firecrawl's /map endpoint. Step-by-step guide with Python code examples, performance comparisons, and interactive visualization techniques for effective website mapping.
Bex Tuychiev
Sep 03, 2025
Why Firecrawl Beats Octoparse for AI Web Scraping
Compare web scraping tools for AI developers. Firecrawl's Fire Engine outperforms Octoparse with superior dynamic content handling, API-first design, and LLM-ready outputs.
Eric Ciarla
Aug 23, 2025
We just raised our Series A and shipped /v2
How we got here. What we're building. Why the web's knowledge should be on tap for AI.
Caleb Peffer
Aug 19, 2025
How Engage Together Uses Firecrawl to Map Anti-Trafficking Resources at Scale
How Engage Together uses Firecrawl's /extract API to collect data on anti-trafficking programs across communities, replacing a process that once required dozens of interns per region.
Eric Ciarla
Aug 17, 2025
How to Create a Dermatology Q&A Dataset with OpenAI Harmony & Firecrawl Search
A step by step guide on collecting dermatology data from the web using Firecrawl, processing it with Harmony prompt style, generating a structured Q&A dataset using GPT-OSS 120B, and publishing it to Hugging Face with checkpointing for reliability.
Abid Ali Awan
Aug 15, 2025
How Dub Builds AI Affiliate Landing Pages with Firecrawl
How Dub uses Firecrawl to power their AI page builder, turning any company website into an affiliate program landing page in seconds.
Eric Ciarla
Aug 13, 2025
Web Scraping with n8n: 8 Powerful Workflow Templates
Learn how to build robust web scraping automations with n8n workflow templates that extract data from any website without coding using Firecrawl's AI-powered engine.
Bex Tuychiev
Mar 27, 2026
5 Easy Ways to Access GLM-4.5
Discover how to access GLM-4.5 models locally, through chat applications, via the official API, and using the LLM marketplaces API for seamless integration into your workflows.
Abid Ali Awan
Aug 08, 2025
Building AI Applications with Kimi K2: A Complete Travel Deal Finder Tutorial
Learn how to build and deploy a Travel Deal application using Kimi K2, Groq Cloud, Firecrawl API, and Gradio. Complete tutorial with code examples and deployment guide.
Abid Ali Awan
Aug 05, 2025
Building a Medical AI Application with Grok 4
Combining the power of real-time search, web scraping, and advanced AI to build a medical prescription analyzer.
Abid Ali Awan
Jul 29, 2025
Introducing Firecrawl Observer, Our Open-Source Website Monitoring Tool
We built a complete, self-hostable website monitoring tool. Get visual diffs, AI-powered analysis, and instant notifications for any change, on any website.
Eric Ciarla
Jul 24, 2025
Top 10 Tools for Web Scraping
Explore the best AI, no-code, Python, and browser automation tools for webscraping.
Abid Ali Awan
Jul 23, 2025
Building a PDF RAG System with LangFlow and Firecrawl
Build a PDF RAG system with LangFlow and Firecrawl: collect PDFs at scale, index them in Chroma DB, and query them through a Streamlit chat interface.
Bex Tuychiev
May 11, 2026
How Zapier Powers AI Chatbots with Web Knowledge Using Firecrawl
How Zapier integrated Firecrawl into Zapier Chatbots to let customers connect public websites and help centers as knowledge sources, without writing scraping code.
Eric Ciarla
Jul 21, 2025
FireGEO: Complete SaaS Template for GEO Tools
Skip 4-6 months of SaaS development with FireGEO's open-source Next.js starter kit. Pre-built auth, billing, and GEO tools included.
Eric Ciarla
Jul 16, 2025
LangFlow Tutorial: Building Production-Ready AI Applications With Visual Workflows
Learn how to build AI applications visually using LangFlow's drag-and-drop interface. This tutorial covers creating RAG systems, multi-agent workflows, and custom components without extensive coding, plus deploying your AI solutions as production-ready APIs.
Bex Tuychiev
Jul 06, 2025
Open Researcher, our AI Agent That Uses Firecrawl Tools During Research
We built a research agent using Anthropic's interleaved thinking and Firecrawl. No orchestration needed.
Eric Ciarla
Jul 01, 2025
LangGraph Tutorial: Build a Startup Idea Validator with Interactive UI
Learn how to create a powerful startup validation agent that analyzes market landscapes, community sentiment, and technical feasibility using LangGraph's agent framework with a responsive Streamlit interface.
Bex Tuychiev
Jun 27, 2025
Announcing Fireplexity: Our Open Source AI Answer Engine
Build your own AI-powered answer engine with real-time web search and intelligent synthesis.
Eric Ciarla
Jun 24, 2025
Announcing Firestarter, our open source tool that turns any website into a chatbot
Spin up a fully functional RAG chatbot from any website URL using Firecrawl and Upstash—clean markdown in, OpenAI-compatible API out, all in under a minute.
Eric Ciarla
Jun 18, 2025
Video
Firecrawl Map: The Cheat Code for Web Scraping
Use the Firecrawl /map endpoint to instantly list every URL on a site before deciding what to scrape or crawl.
Richard Oliver Bray
Jun 18, 2025
How to Use Firecrawl with n8n for Web Automation
Learn how to integrate Firecrawl's web scraping capabilities with n8n's workflow automation platform without dealing with the complexity of traditional web scraping.
Bex Tuychiev
Mar 27, 2026
How Fire Enrich Works, Our Open-Source AI Data Enrichment Tool
Learn how Fire Enrich uses specialized AI agents and Firecrawl to transform email lists into rich company datasets with industry, funding, and tech data.
Eric Ciarla
Jun 11, 2025
How Answer HQ Powers AI Customer Support for Businesses with Firecrawl
How Answer HQ uses Firecrawl to power their website import feature, letting small businesses connect their web content to an AI support assistant without building scraping infrastructure.
Eric Ciarla
Jun 05, 2025
Video
Announcing /search: Discover and scrape the web with one API call
Search the web and get LLM-ready page content for each result in one simple API call. Perfect for agents, devs, and anyone who needs web data fast.
Eric Ciarla
Jun 03, 2025
Video
Generating Images from Website Content with Imagen 4 & Gemini 2.5 Flash
A technical guide to combining Firecrawl, Google's Gemini 2.5 Flash, and Imagen 4 (via Fal.ai) in a Next.js application to transform website content into unique images.
Dev Digest
May 23, 2025
Building Multi-Agent Systems With CrewAI - A Comprehensive Tutorial
Learn how to create powerful multi-agent systems using CrewAI's role-based architecture to build a functional ChatGPT clone with specialized AI workers.
Bex Tuychiev
Jan 26, 2026
Introducing Templates: Ready to use Firecrawl examples
A library of reusable playground setups, code snippets, and repos to help you quickly implement Firecrawl for any use case.
Eric Ciarla
May 13, 2025
Web Scraping Change Detection with Firecrawl
Learn how to build a wiki monitoring system that tracks changes on web pages and intelligently identifies which content has been updated using Firecrawl's change detection capabilities.
Bex Tuychiev
May 02, 2025
MCP vs. A2A Protocols: What Developers Need to Know About AI's New Plumbing
Understanding the distinction between Model Context Protocol (MCP) and Agent2Agent Protocol (A2A) - two emerging standards for connecting AI to the outside world and enabling AI systems to collaborate.
Caleb Peffer
Apr 25, 2025
Fine-tuning Llama 4 on a Custom Dataset With Transformers And Firecrawl
Learn how to fine-tune Llama 4 on a custom dataset using Unsloth and Firecrawl to improve model performance for specific tasks.
Bex Tuychiev
Apr 24, 2025
The best open source frameworks for building AI agents in 2026
Ten open source agent frameworks compared: LangGraph, CrewAI, AutoGen, Google ADK, Dify, OpenAI Agents SDK, Mastra, Smolagents, Semantic Kernel, and Haystack. Stars, downloads, and best-fit use cases for 2026.
Bex Tuychiev
Jun 05, 2026
The Best Pre-Built Enterprise RAG Platforms in 2025
Explore the top enterprise Retrieval-Augmented Generation platforms of 2025, comparing features, security capabilities, and integration options to help you select the ideal solution for your organization's AI needs.
Bex Tuychiev
Apr 22, 2025
How Botpress Populates AI Chatbot Knowledge Bases at Scale with Firecrawl
How Botpress uses Firecrawl to power knowledge base creation for AI chatbots, replacing in-house HTML parsing with reliable, instant web content import.
Eric Ciarla
Apr 21, 2025
Integrations Day: Launch Week III - Day 7
Firecrawl now connects with over 20 platforms including Discord, Make, Langflow, and more. Discover what's new on Integration Day.
Eric Ciarla
Apr 20, 2025
Firecrawl MCP Upgrades: Launch Week III - Day 6
Major updates to the Firecrawl MCP server, now with FIRE-1 support and Server-Sent Events for faster, easier web data access.
Eric Ciarla
Apr 19, 2025
Developer Day: Launch Week III - Day 5
Launch Week III Day 5 is all about developers. We're shipping big improvements to our Python and Rust SDKs, plus a new dark theme for your favorite code editors.
Eric Ciarla
Apr 18, 2025
Announcing LLMstxt.new: Launch Week III - Day 4
Turn any website into a clean, LLM-ready text file in seconds with llmstxt.new — powered by Firecrawl.
Eric Ciarla
Apr 17, 2025
Announcing FIRE-1, Our Web Action Agent: Launch Week III - Day 2
Firecrawl's new FIRE-1 AI Agent enhances web scraping capabilities by intelligently navigating and interacting with web pages.
Eric Ciarla
Apr 15, 2025
Introducing Change Tracking: Launch Week III - Day 1
Firecrawl's enhanced Change Tracking feature now provides detailed insights into webpage updates, including diffs and structured data comparisons.
Eric Ciarla
Apr 14, 2025
Firecrawl Editor Theme: Launch Week III - Day 0
Our official Firecrawl Editor Theme provides a clean, focused coding experience optimized for everyone.
Eric Ciarla
Apr 13, 2025
How to Build MCP Servers in Python: Complete FastMCP Tutorial for AI Developers
Learn to build custom MCP servers in Python using FastMCP. Step-by-step tutorial covering tools, resources, prompts, debugging, and deployment for AI applications.
Bex Tuychiev
Jan 21, 2026
Top 7 AI-Powered Web Scraping Solutions in 2026
Discover the most advanced AI web scraping tools that are revolutionizing data extraction with natural language processing and machine learning capabilities.
Bex Tuychiev
Apr 14, 2026
Announcing Deep Research API
Firecrawl's new Deep Research API enables autonomous, AI-powered web research on any topic.
Nicolas Camara
Mar 27, 2025
Fine-tuning Gemma 3 on a Custom Web Dataset With Firecrawl and Unsloth AI
Learn how to efficiently fine-tune Google's Gemma 3 language model on your custom dataset using Firecrawl for data collection and Unsloth AI for optimization.
Bex Tuychiev
Mar 26, 2025
16 Best MCP Servers You Can Add to Cursor For 10x Productivity
Discover the top 16 Model Context Protocol (MCP) servers that can supercharge your development workflow in Cursor and other AI-powered IDEs.
Bex Tuychiev
Apr 09, 2026
Building an Open-Source Project Monitoring Tool with Firecrawl and Streamlit
Learn how to create a tool that monitors trending GitHub repositories and sends notifications to Slack using Firecrawl and Streamlit.
Bex Tuychiev
Mar 19, 2025
Video
Converting Entire Websites into Agents with Firecrawl's LLMs.txt Endpoint and OpenAI Agents SDK
Learn how to transform any website into an interactive conversational agent by combining Firecrawl's LLMs.txt endpoint with OpenAI Agents SDK.
Bex Tuychiev
Mar 17, 2025
Video
Building a Local Deep Research Application with Firecrawl and Streamlit
Learn to build a web research tool that explores sources, synthesizes information, and provides comprehensive answers with citations using Firecrawl's new Deep Research endpoint and Streamlit.
Bex Tuychiev
Mar 12, 2025
Modern Tech Stack for Retrieval Augmented Generation (RAG)
Learn about the essential components and tools for building effective RAG systems that enhance LLM capabilities with external knowledge retrieval, including when to build from scratch versus using existing solutions.
Bex Tuychiev
Mar 10, 2025
Video
How to Build a Client Relationship Tree Visualization Tool in Python
Build an application that discovers and visualizes client relationships by scraping websites with Firecrawl and presenting the data in an interactive tree structure using Streamlit and PyVis.
Bex Tuychiev
Mar 07, 2025
Video
LLM API Engine: How to Build a Dynamic API Generation Engine Powered by Firecrawl
Build a dynamic API generation engine that transforms web data into structured APIs using natural language instead of code.
Bex Tuychiev
Feb 26, 2025
Video
Building a Clone of OpenAI's Deep Research with TypeScript and Firecrawl
Build an open-source alternative to OpenAI's Deep Research using TypeScript, Firecrawl, and LLMs.
Bex Tuychiev
Feb 24, 2025
How to Create Custom Instruction Datasets for LLM Fine-tuning
A comprehensive guide to creating instruction datasets for fine-tuning LLMs, including best practices and a practical code documentation example.
Bex Tuychiev
Feb 18, 2025
Fine-tuning DeepSeek R1 on a Custom Instructions Dataset
Learn how to fine-tune DeepSeek R1 language models using custom instruction datasets.
Bex Tuychiev
Feb 18, 2025
How Replit Powers Replit Agent with Always-Fresh Web Data Using Firecrawl
How Replit uses Firecrawl to keep Replit Agent up to date with the latest API documentation and web content, with clean structured data on every request.
Eric Ciarla
Feb 17, 2025
Building an Intelligent Code Documentation RAG Assistant with DeepSeek and Firecrawl
A guide to building a documentation assistant that uses DeepSeek and RAG to intelligently answer questions about any documentation website.
Bex Tuychiev
Feb 10, 2025
Automated Data Collection - A Comprehensive Guide
A comprehensive guide to building robust automated data collection systems using modern tools and best practices.
Bex Tuychiev
Feb 02, 2025
Building an AI Resume Job Matching App With Firecrawl And Claude
Build an AI-powered job matching system that automatically scrapes job postings and matches them to your resume using Claude, Firecrawl, and Streamlit.
Bex Tuychiev
Feb 01, 2025
Scraping Company Data and Funding Information in Bulk With Firecrawl and Claude
Learn how to scrape company and funding data from Crunchbase using Firecrawl and Claude.
Bex Tuychiev
Jan 31, 2025
How to Build a Bulk Sales Lead Extractor in Python Using AI
Learn how to build an AI-powered sales lead extraction tool in Python that automatically scrapes company information from websites.
Bex Tuychiev
Jan 12, 2025
Building a Trend Detection System with AI in TypeScript: A Step-by-Step Guide
Build an automated trend detection system in TypeScript that monitors content, analyzes it with AI, and sends Slack alerts.
Bex Tuychiev
Jan 11, 2025
How to Build an Automated Competitor Price Monitoring System with Python
Learn how to build an automated price monitoring system in Python to track and compare competitor prices across e-commerce sites.
Bex Tuychiev
Mar 19, 2026
How Stack AI Feeds Enterprise AI Agents with Reliable Web Data Using Firecrawl
How Stack AI uses Firecrawl to ingest website content into enterprise AI agent workflows, integrating into their data pipeline in under 15 minutes.
Eric Ciarla
Jan 03, 2025
BeautifulSoup4 vs. Scrapy - A Comprehensive Comparison for Web Scraping in Python
A comprehensive comparison of BeautifulSoup4 and Scrapy to help you choose the right Python web scraping tool.
Bex Tuychiev
Dec 24, 2024
22 Python Web Scraping Projects: From Beginner to Advanced
A comprehensive guide to 22 Python web scraping projects that progress from beginner to advanced skill levels.
Bex Tuychiev
Jan 29, 2026
How to Deploy Python Web Scrapers
Learn how to deploy Python web scrapers using GitHub Actions, Heroku, PythonAnywhere and more.
Bex Tuychiev
Dec 16, 2024
Why Companies Need a Data Strategy for Generative AI
Learn why a well-defined data strategy is essential for building robust, production-ready generative AI systems, and discover practical steps for curation, maintenance, and integration.
Eric Ciarla
Dec 15, 2024
Building an Automated Price Tracking Tool
Learn how to build an automated price tracker in Python that monitors e-commerce prices and sends alerts when prices drop.
Bex Tuychiev
Dec 09, 2024
Evaluating Web Data Extraction with CrawlBench
An in-depth exploration of CrawlBench, a benchmark for testing LLM-based web data extraction.
Swyx
Dec 09, 2024
How Cargo Powers GTM Workflows with Reliable Web Data from Firecrawl
How Cargo uses Firecrawl to let GTM teams instantly analyze webpage content for classification, personalization, and enrichment — without writing scraping code.
Eric Ciarla
Dec 06, 2024
Web Scraping Automation: How to Run Scrapers on a Schedule
Learn how to automate web scraping in Python using free scheduling tools to run scrapers reliably in 2025.
Bex Tuychiev
Dec 05, 2024
Video
How to Create an llms.txt File for Any Website
Generate an llms.txt file for any website with Firecrawl's free generator — the structured AI-readable format Google's Lighthouse now checks for.
Eric Ciarla
May 22, 2026
Getting Started with OpenAI's Predicted Outputs for Faster LLM Responses
A guide to leveraging Predicted Outputs to speed up LLM tasks with GPT-4o models.
Eric Ciarla
Nov 05, 2024
Launch Week II Recap
Recapping all the exciting announcements from Firecrawl's second Launch Week.
Eric Ciarla
Nov 04, 2024
Launch Week II - Day 7: Introducing Faster Markdown Parsing
Our new HTML to Markdown parser is 4x faster, more reliable, and produces cleaner Markdown, built from the ground up for speed and performance.
Eric Ciarla
Nov 03, 2024
Launch Week II - Day 6: Announcing Mobile Scraping and Screenshots
Interact with sites as if from a mobile device using Firecrawl's new mobile device emulation.
Eric Ciarla
Nov 02, 2024
Launch Week II - Day 5: Announcing New Actions
Capture page content at any point and wait for specific elements with our new Scrape and Wait for Selector actions.
Eric Ciarla
Nov 01, 2024
Launch Week II - Day 4: Advanced iframe Scraping
We are thrilled to announce comprehensive iframe scraping support in Firecrawl, enabling seamless handling of nested iframes, dynamically loaded content, and cross-origin frames.
Eric Ciarla
Oct 31, 2024
Launch Week II - Day 2: Introducing Location and Language Settings
Specify country and preferred languages to get relevant localized content, enhancing your web scraping results with region-specific data.
Eric Ciarla
Oct 29, 2024
Launch Week II - Day 1: Announcing the Batch Scrape Endpoint
Our new Batch Scrape endpoint lets you scrape multiple URLs simultaneously, making bulk data collection faster and more efficient.
Eric Ciarla
Oct 28, 2024
Getting Started with Grok-2: Setup and Web Crawler Example
A detailed guide on setting up Grok-2 and building a web crawler using Firecrawl.
Nicolas Camara
Oct 21, 2024
Video
OpenAI Swarm Tutorial: Create Marketing Campaigns for Any Website
A guide to building a multi-agent system using OpenAI Swarm and Firecrawl for AI-driven marketing strategies
Nicolas Camara
Oct 12, 2024
Video
Using OpenAI's Realtime API and Firecrawl to Talk with Any Website
Build a real-time conversational agent that interacts with any website using OpenAI's Realtime API and Firecrawl.
Nicolas Camara
Oct 11, 2024
How to Scrape Job Boards: Structured Job Data with Firecrawl and Python
Scrape any company career page into clean structured JSON with one Firecrawl schema, then rank the roles against a resume with an LLM.
Bex Tuychiev
Jun 19, 2026
Video
Build a Full-Stack AI Web App in 12 Minutes
Build a Full-Stack AI Web App in 12 minutes with Cursor, OpenAI o1, V0, Firecrawl & Patched
Dev Digest
Feb 09, 2026
How to Use OpenAI's o1 Reasoning Models in Your Applications
Learn how to harness OpenAI's latest o1 series models for complex reasoning tasks in your apps.
Eric Ciarla
Sep 16, 2024
Handling 300k requests per day: an adventure in scaling
Putting out fires was taking up all our time, and we had to scale fast. This is how we did it.
Gergő Móricz (mogery)
Sep 13, 2024
How Athena Intelligence Powers Enterprise AI Analysts with Web Data from Firecrawl
How Athena Intelligence uses Firecrawl to ingest web content into their AI-native analytics platform, giving enterprise analysts an AI coworker grounded in current public data.
Eric Ciarla
Sep 10, 2024
Launch Week I Recap
A look back at the new features and updates introduced during Firecrawl's inaugural Launch Week.
Eric Ciarla
Sep 02, 2024
Launch Week I / Day 7: Crawl Webhooks (v1)
New /crawl webhook support. Send notifications to your apps during a crawl.
Nicolas Camara
Sep 01, 2024
Launch Week I / Day 6: LLM Extract (v1)
Extract structured data from your web pages using the extract format in /scrape.
Nicolas Camara
Aug 31, 2024
Launch Week I / Day 5: Real-Time Crawling with WebSockets
Our new WebSocket-based method for real-time data extraction and monitoring.
Eric Ciarla
Aug 30, 2024
Launch Week I / Day 4: Announcing Firecrawl /v1
Our biggest release yet - v1, a more reliable and developer-friendly API for seamless web data gathering.
Eric Ciarla
Aug 29, 2024
Launch Week I / Day 3: Introducing the Map Endpoint
Our new Map endpoint enables lightning-fast website mapping for enhanced web scraping projects.
Eric Ciarla
Aug 28, 2024
Launch Week I / Day 2: 2x Rate Limits
Firecrawl doubles rate limits across all plans, supercharging your web scraping capabilities.
Eric Ciarla
Aug 27, 2024
Launch Week I / Day 1: Introducing Teams
Our new Teams feature, enabling seamless collaboration on web scraping projects.
Eric Ciarla
Aug 26, 2024
How to Use Prompt Caching and Cache Control with Anthropic Models
Learn how to cache large context prompts with Anthropic Models like Opus, Sonnet, and Haiku for faster and cheaper chats that analyze website data.
Eric Ciarla
Aug 14, 2024
Building Knowledge Graphs from Web Data using CAMEL-AI and Firecrawl
A guide on constructing knowledge graphs from web pages using CAMEL-AI and Firecrawl
Wendong Fan
Aug 13, 2024
How Gamma Supercharges Onboarding with Firecrawl
How Gamma uses Firecrawl to power Gamma Sites, letting users transform any URL into a polished website or presentation — with clean markdown on every request.
Eric Ciarla
Aug 08, 2024
How to Use OpenAI's Structured Outputs and JSON Strict Mode
A guide for getting structured data from the latest OpenAI models.
Eric Ciarla
Aug 07, 2024
Announcing Fire Engine for Firecrawl
The most scalable, reliable, and fast way to get web data for Firecrawl.
Eric Ciarla
Aug 06, 2024
Firecrawl July 2024 Updates
Discover the latest features, integrations, and improvements in Firecrawl for July 2024.
Eric Ciarla
Jul 31, 2024
Firecrawl June 2024 Updates
Discover the latest features, integrations, and improvements in Firecrawl for June 2024.
Nicolas Camara
Jun 30, 2024
Build a 'Chat with website' using Groq Llama 3
Learn how to use Firecrawl, Groq Llama 3, and Langchain to build a 'Chat with your website' bot.
Nicolas Camara
May 22, 2024
Using LLM Extraction for Customer Insights
Using LLM Extraction for Insights and Lead Generation using Make and Firecrawl.
Caleb Peffer
May 21, 2024
Extract website data using LLMs
Learn how to use Firecrawl and Groq to extract structured data from a web page in a few lines of code.
Nicolas Camara
May 20, 2024
Build an agent that checks for website contradictions
Using Firecrawl and Claude to scrape your website's data and look for contradictions.
Eric Ciarla
May 19, 2024